Chỉ mục(index) trong cơ sở dữ liệu (Phần 2)
Bài đăng này đã không được cập nhật trong 8 năm
Ở phần trước, chúng ta đã tìm hiểu một cách khái quát về cấu trúc của một chỉ mục, đồng thời cũng đề cập tới ưu điểm hay 1 vài trường hợp khiến cho chỉ mục không thực sự hiệu quả như mong muốn. Ở bài viết này, chúng ta sẽ đi vào những trường hợp cụ thể thường gặp nhất trong việc truy vấn có sử dụng chỉ mục, phát hiện ra các vấn đề và các biện pháp phù hợp để hạn chế việc sử dụng chỉ mục không hiệu quả. Trong bài viết sẽ đề cập chủ yếu tới các câu truy vấn có xuất hiện mệnh đề WHERE có sử dụng các cột đánh chỉ mục vì có thể nói đây là mệnh đề được sử dụng vô cùng phổ biến trong hầu hết các câu truy vấn và liên quan chặt chẽ đến vai trò của chỉ mục. Trước tiên, bạn nên cần biết sơ qua về một số khái niệm sau để thuận tiện cho việc tìm hiểu:
- INDEX UNIQUE SCAN: chỉ thực hiện duyệt cây. Oracle database sử dụng thao tác này nếu có một ràng buộc duy nhất chắc chắn rằng các tiêu chí tìm kiếm sẽ chỉ khớp với duy nhất một phần tử.
- INDEX RANGE SCAN: thực hiện duyệt cây và duyệt tiếp các nút lá theo danh sách liên kết đôi để tìm tất cả các phần tử khớp với yêu cầu tìm kiếm. Đây là thao tác được thực hiện nếu có thể có nhiều phần tử khớp với các tiêu chí tìm kiếm.
- TABLE ACESS BY INDEX ROWID: truy xuất vào các dòng trong bảng dữ liệu với ROWID. Thao tác này được thực hiện sau khi tìm được ROWID của các bản ghi phù hợp từ các thao tác INDEX SCAN trước đó (UNIQUE và RANGE).
- TABLE ACCESS FULL: Quét toàn bộ bảng. Đây là những thao tác mô tả quá trình tra cứu chỉ mục cơ bản của hệ quản trị cơ sở dữ liệu. Tùy vào mỗi câu truy vấn, hệ quản trị cơ sở dữ liệu sẽ lựa chọn ra thao tác tối ưu nhất cho câu truy vấn đó.
I. Toán tử bằng
Toán tử so sánh bằng được sử dụng thường xuyên nhất trong các toán tử SQL. Việc tạo ra và sử dụng chỉ mục không phù hợp ảnh hưởng nhiều đến hiệu năng, đồng thời mệnh đề WHERE bao gồm nhiều điều kiện thì dễ cho kết quả không mong muốn.
1.1. Khóa chính
Chúng ta bắt đầu với mệnh đề Where đơn giản nhất: chứa khóa chính. Thông thường, CSDL tự động tạo một chỉ mục index cho khóa chính. Ví dụ như sau:
SELECT first_name, last_name
FROM employees
WHERE employee_id = 123;
Mệnh đề Where ở đây sẽ không truy xuất nhiều bản ghi, vì ràng buộc khóa chính đảm bảo sự duy nhất của giá trị employee_id. CSDL không cần duyệt theo danh sách liên kết trên các nút lá - nó chỉ cần duyệt qua cây chỉ mục là đủ. Chúng ta có thể xem kế hoạch thực thi của câu truy vấn này:
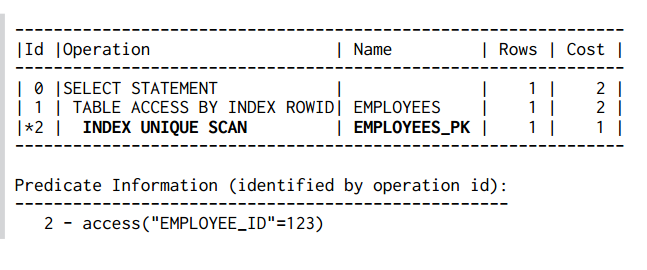
Như vậy, việc sử dụng khóa chính với toán tử bằng tức là chúng ta gián tiếp sử dụng một chỉ mục được ngầm định sẵn có khi tạo bảng và thao tác được lựa chọn chỉ là INDEX UNIQUE SCAN.
1.2. Chỉ mục kết hợp (concatenated index)
Trong trường hợp, khóa chính gồm nhiều cột, cơ sở dữ liệu tạo một chỉ mục kết hợp cho toàn bộ cột trong khóa chính - được gọi là chỉ mục kết hợp. Thứ tự cột của chỉ mục kết hợp có sự ảnh hưởng lớn đến tính hiệu quả hay khả năng sử dụng của chỉ mục đó. Xét ví dụ sau: Lấy ra tên của nhân viên thông qua employee_id và subsidiary_id với employee_id và subsidiary_id là khóa chính của bảng được sắp xếp theo thứ tự đó trong chỉ mục:
SELECT first_name, last_name
FROM employees
WHERE employee_id = 123
AND subsidiary = 30;
Và kết quả là:
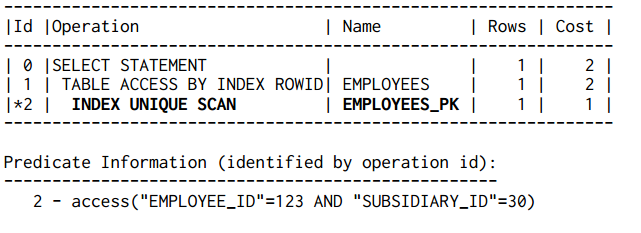
Khi một câu truy vấn chứa đầy đủ khóa chính, CSDL có thể dùng phép duyệt chỉ mục duy nhất (INDEX UNIQUE SCAN) mà không quan tâm đến số lượng cột nằm trong chỉ mục. Tuy nhiên, khi truy vấn không chứa đầy đủ khóa chính thì khác biệt hoàn toàn:
SELECT first_name, last_name
FROM employees
WHERE subsidiary = 20;
Và kết quả là:
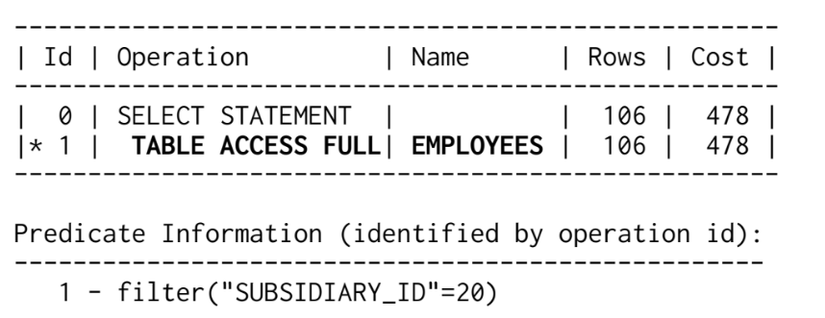
Kế hoạch thực thi chỉ ra rằng CSDL sẽ không sử dụng chỉ mục. Thay vào đó là thực hiện quét toàn bộ bảng (FULL TABLE SCAN). Từ ví dụ ở trên ta thấy CSDL sẽ không dùng chỉ mục nếu truy vấn sử dụng một cách tùy ý cột đơn trong chỉ mục kết hợp. Cấu trúc của chỉ mục kết hợp sẽ àm sáng tỏ điều đó. Một chỉ mục kết hợp là một chỉ mục có cấu trúc B-tree (cây cân bằng), cũng giống như các chỉ mục khác, nó sẽ sắp xếp các dữ liệu được đánh chỉ mục. Việc sắp xếp dữ liệu này dựa trên thứ tự các cột được định nghĩa trong chỉ mục kết hợp. Đầu tiên CSDL sắp xếp các bản ghi theo cột thứ nhất, khi có 2 bản ghi cùng giá trị ở cột thứ nhất thì sẽ sắp xếp theo cột thứ 2, cứ như vậy cho đến hết các cột của chỉ mục kết hợp.
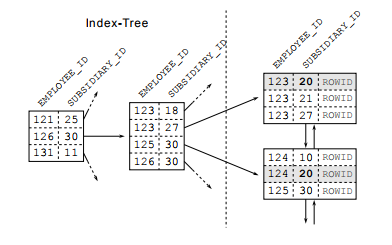
Chúng ta có thể tận dụng một điều chắc chắn rằng cột đầu tiên trong chỉ mục kết hợp luôn hữu dụng cho việc truy vấn. Nếu ta đặt subsidiary_id lên vị trí đầu tiên trong chỉ mục:
CREATE UNIQUE INDEX employees_pk ON employees(subsidiary_id, employee_id)
SUBSIDIARY_ID trở thành thuộc tính đầu tiên cho việc sắp xếp dữ liệu. Bảng kế hoạch thực thi dưới đây xác nhận việc thực thi truy vấn có sử dụng chỉ mục. Cột SUBSIDIARY_ID không mang tính duy nhất nên CSDL phải duyệt thêm trên các nút lá để tìm ra bản ghi phù hợp: sử dụng phép quét vùng chỉ mục (INDEX RANGE SCAN).

Nhận xét chung: CSDL có thể sử dụng chỉ mục kết hợp khi tìm kiếm trên cột đầu tiên của chỉ mục kết hợp. Cho dù giải pháp dùng chỉ mục kết hợp khá hiệu quả trong câu truy vấn SELECT, thế nhưng chỉ mục đơn có 1 cột vẫn được ưa thích hơn. Điều này không chỉ tiết kiệm bộ nhớ, mà còn tránh việc quá tải cho chỉ mục thứ 2. Số lượng chỉ mục càng ít, hiệu năng của các lệnh INSERT, DELETE và UPDATE càng tốt.
II. Tìm kiếm theo khoảng
2.1. Lớn hơn, nhỏ hơn và BETWEEN
Xét ví dụ sau:
SELECT first_name, last_name, date_of_birth
FROM employees
WHERE date_of_birth >= TO_DATE(?, 'YYYY-MM-DD')
AND date_of_birth <= TO_DATE(?, 'YYYY-MM-DD')
Chỉ mục trên DATE_OF_BIRTH chỉ được quét trong phạm vi được chỉ định. Việc quét bắt đầu từ ngày đầu tiên và kết thúc ở lần thứ hai. Chúng ta không thể thu hẹp phạm vi quét index được nữa. Các điều kiện bắt đầu và điều kiện dừng sẽ kém rõ ràng nhất nếu có cột thứ hai trở nên được đưa vào:
SELECT first_name, last_name, date_of_birth
FROM employees
WHERE date_of_birth >= TO_DATE(?, 'YYYY-MM-DD')
AND date_of_birth <= TO_DATE(?, 'YYYY-MM-DD')
AND subsidiary_id = ?
Ở đây, để có thể tối ưu nhất có thể, chúng ta nên sử dụng một chỉ mục kết hợp cho 2 cột date_of_birth và subsidiary_id. Khi đó, thứ tự cột trong chỉ mục sẽ quyết định đến hiệu quả của chỉ mục sử dụng. Trong trường hợp này, ta nên sử dụng chỉ mục mà có cột subsidiary_id đứng trước. Ta sẽ đi đến lý giải cụ thế như sau: Để minh họa, chúng ta tìm kiếm tất cả nhân viên của chi nhánh số 27 có ngày sinh từ ngày 1 tháng 1 đến ngày 9 tháng 1 năm 1971. • Trường hợp 1: date_of_birth đứng trước, subsidiary_id đứng sau:
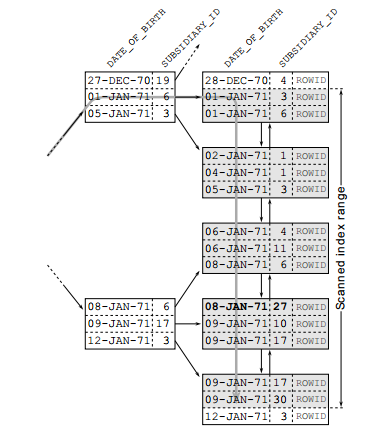
Chúng ta thấy index này được sắp xếp theo ngày sinh trước tiên. Chỉ khi hai nhân viên ra đời trong cùng một ngày thì subsidiary_id được sử dụng để sắp xếp các bản ghi này. Tuy nhiên, câu truy vấn bao gồm một phạm vi ngày. Thứ tự của subsidiary_id vì thế không có ích trong suốt quá trình di chuyển cây vì trên các nút nhánh, hầu như sẽ không có những ngày sinh trùng nhau. Do đó date_of_birth là điều kiện duy nhất giới hạn phạm vi index được quét. Nó bắt đầu từ nút lá đầu tiên phù hợp với phạm vi ngày và kết thúc ở nút lá cuối cùng - tất cả năm nút lá thể hiện trong hình.
• Trường hợp 2: subsidiary_id đứng trước, date_of_birth đứng sau:
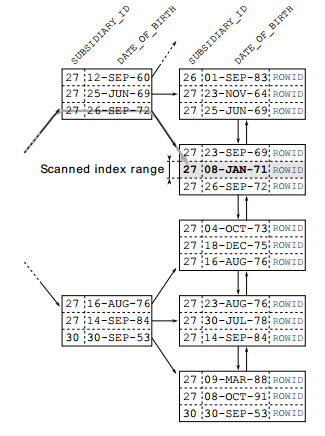
Trong trường hợp đảo ngược thứ tự các cột trong index, hình ảnh có vẻ hoàn toàn khác. Sự khác biệt là toán tử bằng giới hạn cột chỉ mục đầu tiên với một giá trị. Trong phạm vi cho giá trị này (subsidiary_id 27) chỉ mục được sắp xếp theo cột thứ hai - date_of_birth. Do đó việc lọc các bản ghi trên các nút nhánh sẽ phụ thuộc vào cả 2 trường, chính vì vậy giúp cho khoảng quét ở các nút lá được giới hạn tốt hơn
Từ đây, ta có thể rút ra một nguyên tắc như sau: index for equality first—then for ranges (index cho điều kiện bằng trước, cho điều kiện khoảng sau). Đối với toán tử between, mọi thứ cũng tương tự như trên.
2.2. Toán tử LIKE
Toán tử LIKE thường xuyên kéo theo tác động không lường trước tới hiệu suất truy vấn bởi vì có thể tồn tại từ khóa tìm kiếm mà hạn chế việc sử dụng index hiệu quả. Điều này có nghĩa là nhiều từ khóa tìm kiếm có thể sử dụng index rất hiệu quả nhưng một số từ khóa khác thì không. Vị trí của kí tự đại diện sẽ tạo ra sự khác biệt trong truy vấn. Một biểu thức LIKE có thể chứa hai loại vị từ sau: (1) phần trước kí tự đại diện có tư cách làm vị từ truy cập; (2) Phần kí tự còn lại có tư cách làm vị từ lọc. Chúng ta có thể hiểu đơn giản rằng vị từ truy cập (access predicates) là các điều kiện bắt đầu và dừng cho một truy cứu trên index, chúng xác định phạm vi index được quét. Vị từ lọc (filter predicates) được áp dụng trong suốt quá trình di chuyển nút lá, chúng không làm giảm phạm vi index được quét, mà chỉ mang ý nghĩa là chọn lọc những bản ghi phù hợp.
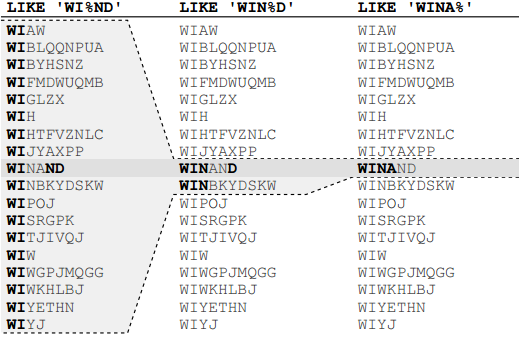
Hình ảnh trên mô tả những khoảng quét mà từng câu truy vấn có toán tử LIKE thực hiện. Chúng khác nhau về vị trí đặt kí tự “%”. Cả ba lựa chọn cùng một hàng, nhưng phạm vi được index quét - và do đó hiệu suất là rất khác nhau. Ta có thể nhận thấy rằng việc đặt càng nhiều kí tự trước kí tự “%” thì phạm vi quét càng được thu hẹp bởi càng nhiều kí tự đứng trước thì tính chọn lọc càng cao. Vậy khi kí tự “%” đứng đầu chuỗi thì sao? Ta hoàn toàn có thể đoán được rằng tính chọn lọc là không hề có, cho nên sẽ không hề có một khoảng quét nào được giới hạn. Cũng giống như việc bạn tìm kiếm trong danh bạ điện thoại tên một người nào đó mà chỉ biết những chữ cái đứng cuối, bạn sẽ phải soát từ đầu đến cuối, và việc sắp xếp theo thứ tự bảng chữ cái là điều vô nghĩa. Và chắc chắn nó sẽ là thao tác TABLE ACCESS FULL.
Kết luận:
- Ở bài viết này, chúng ta đã tìm hiểu được một số điều khá cơ bản về sử dụng chỉ mục khi có toán tử bằng cũng như việc tìm kiếm theo khoảng thường gặp.
- Phần tiếp theo, chúng ta sẽ nói đến những vấn đề khác như chỉ mục một phần, sử dụng chỉ mục trên các cột có các giá trị NULL, hay những điều kiện mờ trên các cột sử dụng chỉ mục.
- Bạn đọc có thể tìm đọc cuốn SQL Performance Explained - Markus Winand để có thể tìm hiểu kĩ hơn những vấn đề bài viết đề cập tới.
All rights reserved
