Thiết kế partition sai, hệ thống Core banking bị treo CPU 99% và tôi đã xử lý bằng chấm nhẹ như thế nào?
Bài đăng này đã không được cập nhật trong 3 năm
Lần đầu tiên tối ưu Core banking của tôi đó là nhiệm vụ tối ưu Cơ sở dữ liệu Core banking sử dụng phần mềm ORACLE FLEXCUBE của ngân hàng X (kỷ niệm rất đẹp nhưng mục tiêu của bài viết chỉ là chia sẻ phương án kỹ thuật nên tôi không nêu tên cụ thể). Core banking FLEXCUBE này sử dụng cơ sở dữ liệu Oracle phiên bản 10g. Tại thời điểm tôi tiếp nhận dự án, hiệu năng của cơ sở dữ liệu có vấn đề nghiêm trọng liên quan đến một bảng lưu trữ dữ liệu lịch sử. Dữ liệu của bảng này ngày một tăng trưởng, ảnh hưởng lớn đến chiến lược thực thi và thời gian xử lý của các câu lệnh có làm việc với bảng. Đội dự án họp nhau lại để cùng tìm phương án tối ưu, sau nhiều cuộc họp đã đi tới thống nhất rằng: bảng này cần thực hiện PARTITION. Mặc dù hiện tại kỹ thuật PARTITION đã được tôi áp dụng với hàng trăm cơ sở dữ liệu, nhưng thời điểm gần 10 năm trước, kỹ thuật này vẫn còn khá mới với team dự án chúng tôi.
1. Giải thích nhanh về kỹ thuật PARTITION và tại sao nó có thể tăng tốc hàng nghìn lần nếu thiết kế đúng
Bạn hãy hình dung: ngôi nhà của bạn có một TỦ SÁCH và nhiệm vụ của bạn cần thiết kế làm sao khi chúng ta tìm kiếm thông tin một quyển sách và lấy ra được quyển sách đó với thời gian ngắn nhất. Thông thường sẽ có 2 cách:
Cách thứ nhất: Các quyển sách được xếp chồng lên nhau một cách lộn xộn, không có bất kỳ nguyên tắc, quy củ gì cả. Cách thứ hai: Chúng ta chia nhỏ tủ sách thành các ô riêng biệt, mỗi ô sẽ chưa một loại sách đặc thù (sách văn học, sách kinh tế, sách lịch sử…)
Nếu bây giờ chúng ta cần tìm tất cả quyển sách kinh tế và có tên bắt đầu bằng chữ H.
Bạn hãy tưởng tượng với hai cách thiết kế tủ sách bên trên, cách nào sẽ đem lại thời gian tìm kiếm nhanh hơn nhé.
- Cách 1: Quyển sách mà bạn tìm có thể ở bất kỳ chỗ nào trong đống “hổ lốn” sách
- Cách 2: Quyển sách mà bạn tìm chắc chắn chỉ ở trong “ô sách được dán nhãn Kinh tế”
Đây chính là ý tưởng chính của kỹ thuật Partition, và việc làm tăng hiệu năng câu lệnh, bản chất là do “số lượng block cần tìm kiếm” đã được khoanh vùng, do đó khối lượng cần thực hiện của câu lệnh đã giảm đi rất nhiều.
2. Thiết kế Partition sai và bài học khiến hệ thống tải cao vút CPU 99%.
Quay trở lại ví dụ thiết kế tủ sách bên trên. Người dùng thường xuyên tìm kiếm với phong cách dạng như sau:
SELECT * FROM TUSACH WHERE LOAISACH='KINH TẾ' AND TENSACH LIKE '%H'
Tại ví dụ bên trên, chúng ta thực hiện "PARTITION" (phân loại đầu vào sách) dựa trên LOẠI SÁCH:
- Khi đi tìm sách kinh tế, chúng ta chỉ cần tìm kiếm trong một "vùng không gian" hẹp hơn rất nhiều (so với tìm toàn bộ không gian của tủ sách).
- Trường hợp này hiệu năng của câu lệnh được cải thiện rất nhiều.
 Nhưng giả sử, tôi lựa chọn một phương án PARTITION khác:
Nhưng giả sử, tôi lựa chọn một phương án PARTITION khác: - Tôi quyết định sẽ phân loại và chia tủ sách của mình theo năm xuất bản
 Trong trường hợp này nêu bạn muốn tìm sách thuộc loại KINH TẾ thì sao ?
Quyển sách KINH TẾ có thể nằm trong bất kỳ một ngăn tủ nào bên trên:
Trong trường hợp này nêu bạn muốn tìm sách thuộc loại KINH TẾ thì sao ?
Quyển sách KINH TẾ có thể nằm trong bất kỳ một ngăn tủ nào bên trên: - Sẽ có quyển sách KINH TẾ xuất bản vào năm 2013, 2014, cũng có thể có quyển sách xuất bản vào năm 2022
Như vậy trong trường hợp này, việc bạn phân chia sách theo năm xuất bản KHÔNG ĐEM LẠI bất kỳ giá trị nào về mặt hiệu năng cả. Ngược lại công sức tìm kiếm thực tế CÒN TĂNG LÊN. Trong bài toán tối ưu Core banking mà tối thực hiện, đội dự án ban đầu đã quyết định lựa chọn sai TIÊU CHÍ để thực hiện PARTITION (đơn giản là chọn nhầm CỘT để thực hiện PARTITION). Rất may việc thực hiện PARTITION được triển khai thử nghiệm trên môi trường UAT. Nếu áp dụng ngay trên PRODUCTION, chắc các sếp CIO, CTO của ngân hàng sẽ phải đứng ngồi không yên vì khách hàng gọi phàn nàn tới tấp mất.
3. Các dự án hiện nay có được áp dụng PARTITION nhiều không?
Gần như tất cả các hệ thống Core banking, Core chứng khoán, hệ thống CRM, ERP trọng yếu mà tôi thực hiện tối ưu đều áp dụng kỹ thuật PARTITION.
Để thực hiện PARTITION một bảng chúng ta có nhiều cách, nhưng cách phổ biến nhất đó là "PARTITION BY RANGE".
Nếu bạn muốn biết chi tiết về các kỹ thuật khác, bạn có thể tham gia chương trình Coaching Tối ưu cơ sở dữ liệu thực chiến của tôi, tôi sẽ chia sẻ tất cả những tải nghiệm dự án của mình với nhóm học viên đặc quyền này.
Kỹ thuật này cực kỳ hữu dụng nếu các bảng chứa dữ liệu được tổ chức và tìm kiếm theo các trường thông tin dạng NGÀY THÁNG. Tại các đơn vị tài chính, các dữ liệu lịch sử giao dịch thường là các TABLE lớn và được sắp xếp và tìm kiếm theo ngày tháng, do đó các bạn có thể áp dụng phương án PARTITION BY RANGE cho những trường hợp này và mang lại hiểu qua rất cao.
Trong các dự án của tôi, đối với đơn vị tài chính (ngân hàng, chứng khoán), bảng chủ yếu được chia partition theo các THÁNG (mỗi một tháng sẽ vào 1 PARTITION riêng biệt).
Đối với cơ sở dữ liệu của đơn vị viễn thông, dữ liệu tăng trưởng rất nhanh và nhiều, do đó những bảng này có thể được PARTITION theo NGÀY, thậm chí chia theo tiêu chí GIỜ.
Bạn có thể xem thông tin các dự án mà tôi đã trực tiếp tối ưu tại đây https://wecommit.com.vn/du-an/
4. Bảng như thế nào thì nên cân nhắc thiết kế dạng PARTITION?
Các table có dung lượng lớn hơn 2GB, chúng ta đều nên cân nhắc thực hiện partition. Ngoài ra, một yếu tố vô cùng quan trọng mà bạn phải có trước khi quyết định áp dụng kỹ thuật partition: Phải chọn được PARTITION KEY. Việc lựa chọn PARTITION KEY chính là yếu tố then chốt mang lại hiệu quả của kỹ thuật Partition. Hãy quay lại ví dụ tìm kiếm sách trong tủ sách bên trên. Chúng ta quyết định chia tủ sách ban đầu thành các ô riêng biệt theo “Loại sách”, tại đây “Loại sách” chính là “PARTITION KEY”.
5. Demo đánh giá hiệu năng giữa bảng NON-PARTITION và bảng được thực hiện PARTITION
5.1. Môi trường thực hiện đánh giá
- Tôi tạo hai bảng có số lượng cột, số lượng bản ghi giống hệt nhau. Khác biệt giữa hai bảng chỉ nằm ở chỗ: một bảng được thiết kế PARTITION, còn một bảng không được thiết kế PARTITION
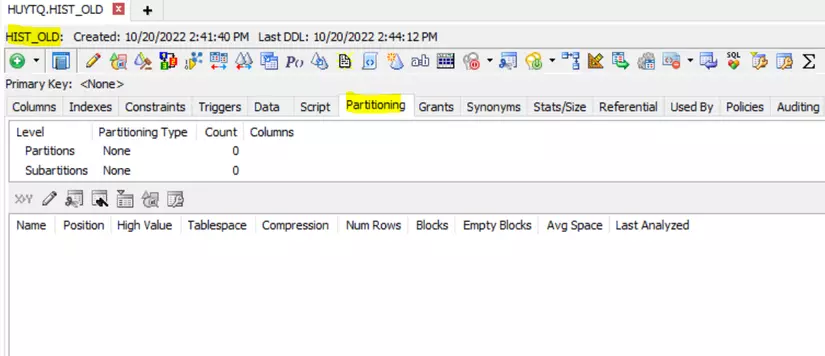
- Bảng HIST_OLD là bảng không được thiết kế PARTITION
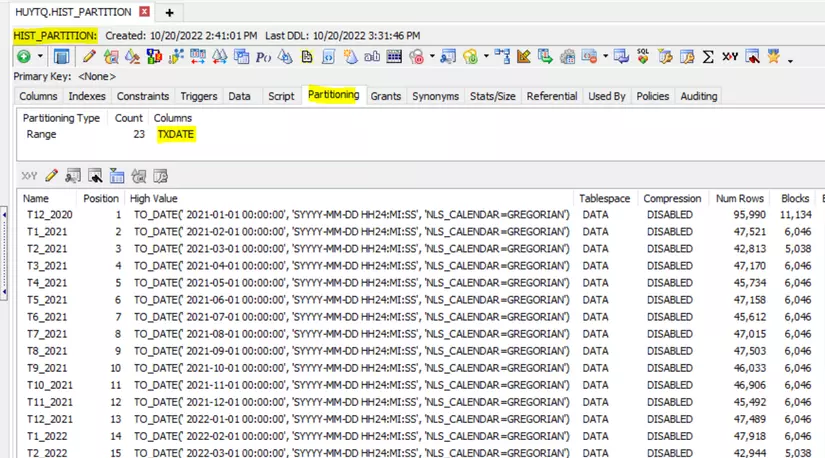
- Bảng HIST_PARTITION là bảng được thiết kế PARTITION. Bảng này sử dụng cột TRXDATE để làm tiêu chí PARTITION (thuật ngữ gọi là PARTITION KEY)
Hai bảng này đều có số lượng bản ghi là 1100016
select count(*) from HIST_OLD
1100016
select count(*) from HIST_PARTITION
1100016
Câu lệnh sẽ sử dụng chung cho việc đánh giá hiệu năng
SELECT *
FROM <Tên_Table>
WHERE txdate > TO_DATE ('01-01-2021', 'dd-mm-yyyy')
AND txdate < TO_DATE ('01-02-2021', 'dd-mm-yyyy')
AND first_name LIKE 'K%'
5.2. Đánh giá hiệu năng của bảng khi không áp dụng thiết kế PARTITION
SELECT *
FROM hist_old
WHERE txdate > TO_DATE ('01-01-2021', 'dd-mm-yyyy')
AND txdate < TO_DATE ('01-02-2021', 'dd-mm-yyyy')
AND first_name LIKE 'K%'
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
| 0 | SELECT STATEMENT | | 1867 | 1314K| 33159 (1)| 00:06:38 |
|* 1 | TABLE ACCESS FULL| HIST_OLD | 1867 | 1314K| 33159 (1)| 00:06:38 |
Câu lệnh thực thi ước lượng mất 6 phút 38s Chi phí để thực chiện câu lệnh này là 33159.
5.3. Đánh giá hiệu năng của bảng khi áp dụng thiết kế PARTITION
SELECT *
FROM hist_partition
WHERE txdate > TO_DATE ('01-01-2021', 'dd-mm-yyyy')
AND txdate < TO_DATE ('01-02-2021', 'dd-mm-yyyy')
AND first_name LIKE 'K%'
---------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
| 0 | SELECT STATEMENT | | 1637 | 1152K| 1641 (1)| 00:00:20 | | |
| 1 | PARTITION RANGE SINGLE| | 1637 | 1152K| 1641 (1)| 00:00:20 | 2 | 2 |
|* 2 | TABLE ACCESS FULL | HIST_PARTITION | 1637 | 1152K| 1641 (1)| 00:00:20 | 2 | 2 |
Khi thiết kế sử dụng partition, thời gian thực hiện câu lệnh chỉ còn ước tính 20s** (giảm 95% - thuật tuyệt vời)** Chi phí để thực hiện câu lệnh lúc này là 1641 (giảm 95% so với không sử dụng partition)
5.4. Nếu kết hợp Index với Partition thì chuyện gì sẽ xảy ra?
Nội dung này tôi sẽ chia sẻ độc quyền với:
- Các bạn thuộc nhóm học viên đặc quyền
- Nếu bạn chưa phải là học viên của tôi, nhưng vẫn muốn biết các kiến thức chuyên sâu, bạn có thể tham gia nhóm Zalo sau để nhận mật khẩu cho các bài viết "đặc quyền": Nhóm Zalo Tư Duy - Tối Ưu - Khác Biệt
6. Link bài viết gốc
Link bài gốc: https://wecommit.com.vn/partition-table-thiet-ke-sai-anh-huong-the-nao/
7. Nếu bạn muốn xem toàn bộ các nội dung tôi từng chia sẻ về tối ưu SQL, tối ưu cơ sở dữ liệu từ trước đến nay
Link toàn bộ danh sách những bài viết của tôi: https://wecommit.com.vn/tong-hop-link-cac-bai-viet-hay-tren-trang-wecommit-com-vn/
8. Thông tin tác giả
Tác giả: Trần Quốc Huy - Founder & CEO Wecommit Facebook: https://www.facebook.com/tran.q.huy.71 Email: huy.tranquoc@wecommit.com.vn Youtube: Trần Quốc Huy Số điện thoại: 0888549190
All rights reserved
