
[Handbook CV with DL - Phần 3] Bài toán phân loại hình ảnh - Image Classification với Keras
Bài đăng này đã không được cập nhật trong 7 năm
Xin chào tất cả các bạn. Tiếp tục với series về các ứng dụng Deep Leanring cho Computer Vision và chúng ta đang dừng lại ở bài toán phân loại hình ảnh trong phần 2. Hôm nay chúng ta tiếp tục tìm hiểu thêm một số mạng nâng cao hơn ứng dụng trong phân loại hình ảnh và cách sử dụng một thư viện đơn giản hơn Tensorflow đó là Keras. OK chúng ta băt đầu thôi nào.
Training mô hình với Keras.
Load data và khai báo biến
Đã có khá là nhiều những bài viết trên Viblo đã viết về Keras như một Framework tiêu biểu cho Deep Learning. Các bạn có thể tìm đọc các bài viết khác giới thiệu chi tiết hơn về Framework này. Trong phần này chúng ta sẽ thử cùng nhau tìm hiểu cách triển khai một mạng nơ ron với Keras và áp dụng trong một bài toán rất kinh điển đó là nhận dạng chữ số viết tay với tập dữ liệu MNIST đã được làm quen ở phần trước đó. Tập dữ liệu MNIST cũng được cài đặt sẵn trong Keras giống như trong Tensorflow. Chúng ta cũng cần phải định nghĩa một số tham số liên quan trọng quá trình training như số epochs - tức số lần mạng nơ ron chạy qua toàn bộ tập dữ liệu, batch_size - tức là số lượng dữ liệu được đưa vào trong một batch, số lượng classes của dữ liệu ... Số lượng batch_size các bạn lựa chọn tuỳ thuộc vào dung lượng RAM hay GPU các bạn sở hữu, về cơ bản thì batch_size càng lớn thì đòi hỏi lượng thông tin lưu trên RAM càng nhiều nhưng đổi lại thời gian training sẽ được giảm đi. Số lượng epochs có thể được lựa chọn tuỳ ý các bạn. Số lượng epochs càng nhiều thì thuật toán training càng lâu và dễ dẫn đến hiện tượng overfitting. Thế nên nó thường được kết hợp với khái niệm early stopping để thu được một mô hình tốt nhất trong quá trình training, tránh hiện tượng overfitting. Chúng ta khai báo các tham số của mạng như sau:
import tensorflow as tf
batch_size = 128
no_classes = 10
epochs = 50
image_height, image_width = 28, 28
Sau đó để load tập dữ liệu trong Keras chúng ta sử dụng câu lệnh sau:
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
Do chúng ta sử dụng mô hình CNN2D để huấn luyện mạng nên cần thiết phải reshape dữ liệu về dưới dạng mảng hai chiều bằng đoạn code sau:
x_train = x_train.reshape(x_train.shape[0], image_height, image_width, 1)
x_test = x_test.reshape(x_test.shape[0], image_height, image_width, 1)
input_shape = (image_height, image_width, 1)
Sau đó chúng ta convert dữ liệu sang định dạng float bằng các câu lệnh sau:
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
Việc tiếp theo cần làm đó là chuẩn hoá lại dữ liệu giống như bài viết trước chúng ta cũng đã làm:
x_train /= 255
x_test /= 255
Và cuối cùng thì để sử dụng softmax và cross-entropy loss thì cũng giống như các bài trước chúng ta cần phải chuyển đổi về dạng one-hot encoding.
y_train = tf.keras.utils.to_categorical(y_train, no_classes)
y_test = tf.keras.utils.to_categorical(y_test, no_classes)
Chúng ta thấy rằng trong Keras định nghĩa các dữ liệu tường mình hơn rất nhiều, các dữ liệu được lưu trực tiếp trong bộ nhớ chứ không còn các khái niệm về Placeholder giống như trong Tensorflow nữa. Việc viét code của chúng ta gần với Python thuần hơn từ đó giúp chúng ta dễ tiếp cận hơn. Bây giờ hãy thử tìm hiểu một số cách xây dựng mô hình CNN với Keras nhé.
Định nghĩa model CNN
Trong phần này chúng ta sẽ sử dụng một vài lớp CNN và lớp fully connected để thực hiện các ví dụ trên tập MNIST. Chúng ta khởi tạo một mô hình với hai lớp CNN theo sau bởi pooling và dropout và cuối cùng là lớp dense layer (fully connected). Layer đầu tiên có 64 filter, layer tiếp theo có 128 filter và sử dụng kernel size = 3 cho tất cả các filter đó. Việc áp dụng max_pooling sau mỗi lớp CNN được sử dụng để tránh hiện tượng overfitting. Chúng ta định nghĩa mô hình trong hàm sau:
def simple_cnn(input_shape):
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv2D(
filters=64,
kernel_size=(3, 3),
activation='relu',
input_shape=input_shape
))
model.add(tf.keras.layers.Conv2D(
filters=128,
kernel_size=(3, 3),
activation='relu'
))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(rate=0.3))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(units=1024, activation='relu'))
model.add(tf.keras.layers.Dropout(rate=0.3))
model.add(tf.keras.layers.Dense(units=no_classes, activation='softmax'))
model.compile(loss=tf.keras.losses.categorical_crossentropy,
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
return model
Mô hình của chúng ta cần phải thực hiện complied với các thông số khác như hàm loss sử dụng để tối ưu là gì, thuật toán tối ưu là gì (optimizer) và metrics để đánh giá hiệu quả là gì. Đối với bài toán phân loại như đã nói ở các phần trước đó chúng ta có thể sử dụng hàm loss là cross-entropy và được tối ưu bằng thuật toán Adam và sử dụng độ đo accuracy để làm metrics đánh giá mạng.
Sau khi định nghĩa mô hình chúng ta có thể khai báo mô hình đơn giản như sau:
simple_cnn_model = simple_cnn(input_shape)
Sau đó chúng ta sẽ sủ dụng dữ liệu training và dữ liệu testing để huấn luyện mạng cũng như đánh giá hiệu năng của thuật toán như sau:
simple_cnn_model.fit(x_train, y_train, batch_size, epochs, (x_test, y_test))
train_loss, train_accuracy = simple_cnn_model.evaluate(
x_train, y_train, verbose=0)
print('Train data loss:', train_loss)
print('Train data accuracy:', train_accuracy)
Chúng ta không cần phải khởi tạo session giống như trong Tensorflow mà sử dụng trực tiếp với Keras API luôn. Lúc quá trình trianing kết thúc chúng ta có thể sử dụng trực tiếp mô hình này để đánh giá:
test_loss, test_accuracy = simple_cnn_model.evaluate(
x_test, y_test, verbose=0)
print('Test data loss:', test_loss)
print('Test data accuracy:', test_accuracy)
Chúng ta thu được kết quả như sau:
Loss for train data: 0.0171295607952
Accuracy of train data: 0.995016666667
Loss for test data: 0.0282736890309
Accuracy of test data: 0.9902
Các bạn có thể thấy việc training mô hình với Keras tường minh và đơn giản hơn rất nhiều so với việc dùng Tensorflow và đây xứng đáng là một framework đáng học cho các bạn mới học về DL và các bạn muốn thử nghiệm mô hình DL một cách nhanh chóng trong thực tế. Phần tiếp theo chúng ta sẽ tìm hiểu một vài tập dữ liệu phổ biến khác thường được sử dụng trong bài toán phân loại hình ảnh. Các bạn có thể sử dụng nó để luyện tập thêm nhé.
Một số tập dữ liệu phổ biến
CIFAR-10 dataset
Tập dữ liệu CIFAR - Canadian Institute for Advanced Research (CIFAR) là tập dữ liệu bao gồm có 60000 ảnh trong đó 50000 cho training và 10000 cho testing. Số lượng class là 10 với kích thước 32x32 một ảnh. Tập dữ liệu này là một tập hợp các loại xe ô tô. Giúp chúng ta có thể luyện tập được với các dữ liệu dạng vật thể. Sau đây là một vài hình ảnh minh hoạ của tập dữ liệu này

Ngoài ra còn có một tập dữ liệu khác đó là CIFAR-100 chứa lượng ảnh tương tự như CIFAR-10 nhưng với số lượng class là 100 (chỉ 600 ảnh trong 1 class). Cả hai tập dữ liệu này đều được tích hợp sẵn trong module tf.keras.datasets các bạn có thể lấy ra luyện tập nếu muốn.
Fashion-MNIST dataset
Tập dữ liệu này được thiết kế dưới tư tưởng của tập dữ liệu MNIST và nó được xem là một tập dữ liệu dễ cũng giống như MNIST vậy. Chính vì thế mà nó có thể được sử dụng để thay thế các thí nghiệm trên tập MNIST . Sau đây là một số lượng dữ liệu visualize của tập dữ liệu này sau khi đã áp dụng phương pháp giảm chiều dữ liệu PCA.
Về kích thước ảnh, số lượng ảnh thì tập dữ liệu này giống như tập MNIST. Các bạn có thể xem thông tin chi tiết của tập dữ liệu này tại đây
ImageNet dataset và các competition
ImageNet là một tập dữ liệu rất nổi tiếng trong lĩnh vực computer vision. Nó thực sự là một tập dữ liệu khổng lồ với 14,197,122 ảnh và 1000 class. Nó là tập dữ liệu được sử dụng để tổ chức các competition hàng năm và là một tập dữ liệu tiêu chuẩn để đo benchmark cho các thuật toán phân loại hình ảnh mới được ra đời. Vào năm 3013 khi Alexnet là một Deep Learning model đã dành chiến thắng tại competition Imagenet và kể từ đó đến nay chỉ có các Deep Learning model dành chiến thắng tại cuộc thi này. Top 5 error rate của các mạng này được mô tả trong hình sau.
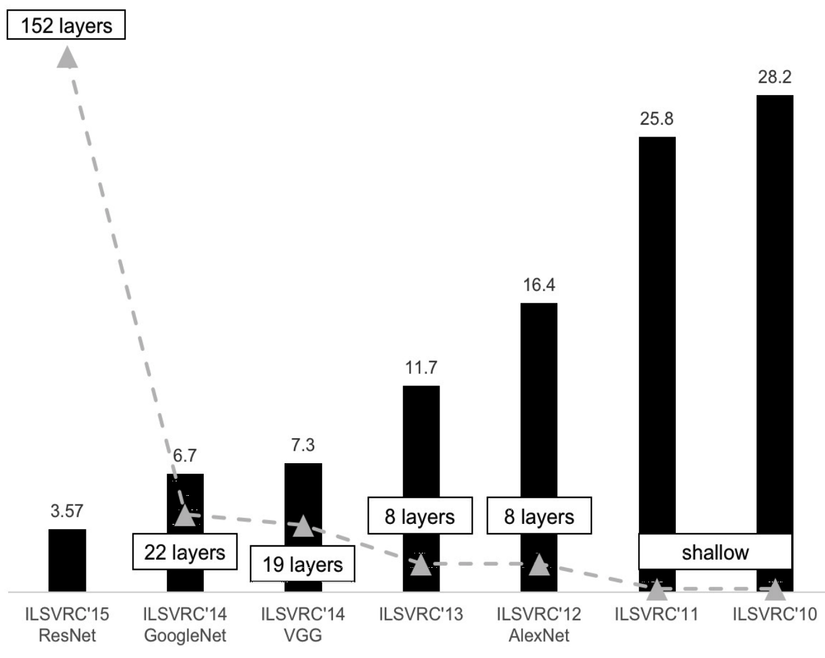
Chúng ta thấy rằng độ chính xác càng ngày càng được cải thiện qua từng năm theo đó là độ sâu của các mạng nơ ron được sử dụng. Chúng ta sẽ cùng nhau tìm hiểu kĩ hơn về các mạng này trong các phần tiếp theo nhé
Các kiến trúc mạng phổ biến cho Image Classification
Alexnet
Là người đầu tiên đặt nền móng cho các kiến trúc mạng nơ ron sử dụng CNN - Krizhevsky cha đẻ của Alexnet đã chiến thắng cuộc thi Imagenet năm 2013 với error rate khoảng 15.4% tốt hôn hẳn so với các phương pháp được sử dụng trước đó. Kiến trúc này sử dụng 5 layer CNN sử dụng để phân loại 1000 class (mặc dù Imagenet có đến 22000 class nhưng trong competition chỉ sử dụng 1000 class để làm độ đo). Điểm đặc biệt của Alexnet không chỉ nằm ở các lớp CNN mà còn là việc sử dụng các activation ReLU được chứng minh là cho tốc độ training hiệu quả hơn so với các activation khác trước đó. Kiến trúc của mô hình này được mô tả trong hình sau:
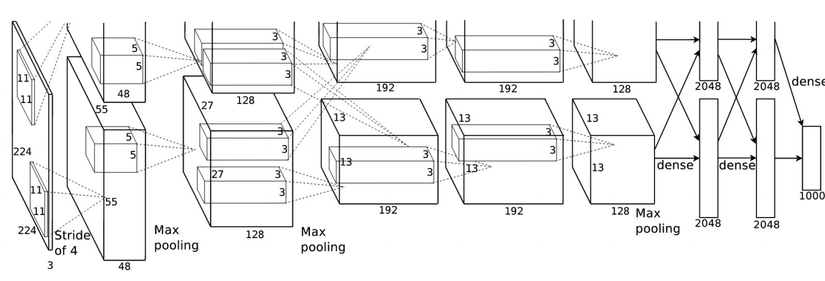
Trong paper này cũng đề cập đến các kĩ thuật về data augmentation giống như các kĩ thuật chuyển dổi hình ảnh (xoay ảnh, lật ảnh, thêm noise, thay đổi độ sáng, tối của ảnh) đồng thời sử dụng Stochastic Gradient Descent để tối ưu với các tham số của SGD được lựa chọn rất kĩ lưỡng cho quá trình training. Các giá trị momentum và weight decay của SGD được tác giả fix cứng trong quá trình training. Trong paper tác giả đề cập đến một kĩ thuật có tên là Local Response Normalization (LRN), về tư tưởng có thể hiểu sau mỗi bước thực hiện filter thì tác giả sẽ normalization trên từng pixel để tránh giá trị quá lớn của filter trước khi đưa vào hàm kích hoạt. Tuy nhiên trong các nghiên cứu gần đây khái niệm này không được áp dụng vì nó thực sự không tỏ ra hiệu quả. Mạng Alexnet có chứa tổng cộng 60 triệu tham số.
VGG-16 model
VGG là một chuẩn thiết kế mạng Deep Learning của Visual Geometry Group thuộc đại học Oxford. Mô hình này rất đơn giản và có độ sâu hơn so với kiến trúc Alexnet, VGG có hai biến thể đó là VGG-16 và VGG-19. Tất cả các lớp CNN trong mô hình này đều có kích thước 3x3 filter với stride, padding 1 và max pooling 2D. Chính điều này làm giảm số lượng các tham số của mạng nơ ron. Kiến trúc của VGG được mô tả trong hình sau:
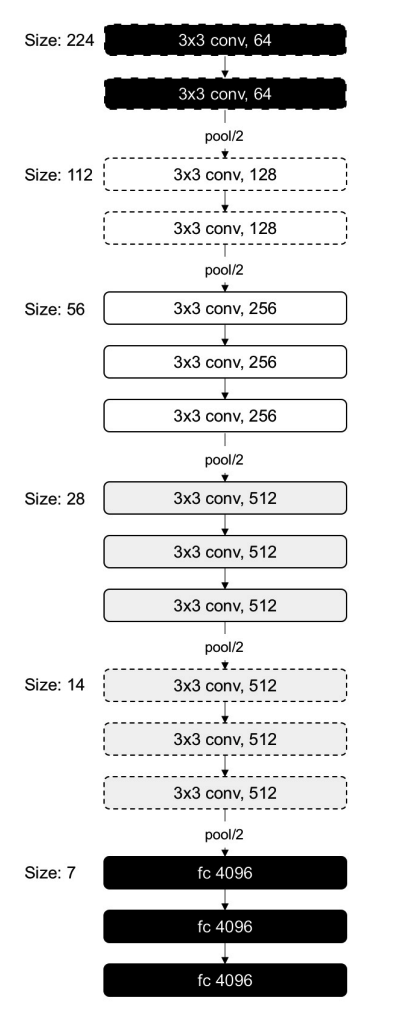
Kiến trúc này có đến 138 triệu tham số và là kiến trúc có số lượng tham số lớn trong các mạng đề cập tại bài viết này. Mặc dù nhiều tham số như vậy như tính đồng nhất (uniformity) của các tham số trong mạng VGG là khá tổt Càng đi sâu vào trong mạng thì kích thước của ảnh càng nhỏ đi và theo đó là số lượng các filter của mạng lại tăng lên
Google Inception-V3 model
Inception-V3 có thể được coi là một trong những bước ngoặt trong lịch sử của Deep Leanring và là một phương pháp thiết kế mạng nơ ron xuất phát từ Google. Nó đã chiến thắng cuộc thi Imagenet năm 2014 và được thiết kế để hướng đến cải thiện về tốc độ và độ kích thước của mô hình. Số lượng tham số của InceptionV3 giảm 12 lần so với Alexnet. Tư tưởng của Inception là xây dựng kiến trúc mạng lớn bằng việc kết hợp nhiều kiến trúc mạng con (micro-architecture). Mỗi một hidden layer được kết hợp một vài biểu diễn higher-level của hình ảnh. Trong mỗi layer chúng ta có thể sử dụng vài loại kernels khác nhau thay vì chỉ sử dụng một loại kernels. Average pooling được sử dụng với một số kích thước khác nhau khi tiến hành concatenate các layer trên lại với nhau. Một điểm đặc biệt của Inception đó là các tham số của kernel có thể được học trong quá trình training. Sử dụng một vài kernels, mô hình có thể tự định nghĩa được các đặc trưng nhỏ giống như các thông tin trừu tượng hoá. Đặc biệt lớp convolution 1x1 làm giảm đặc trưng và tốc độ tính toán từ đó giúp cho quá trình inference được nhanh hơn. Dưới đây chúng ta cũng xem một module inception đơn giản nhất với một vài lớp convolution với các kernel size khác nhau và lớp pooling
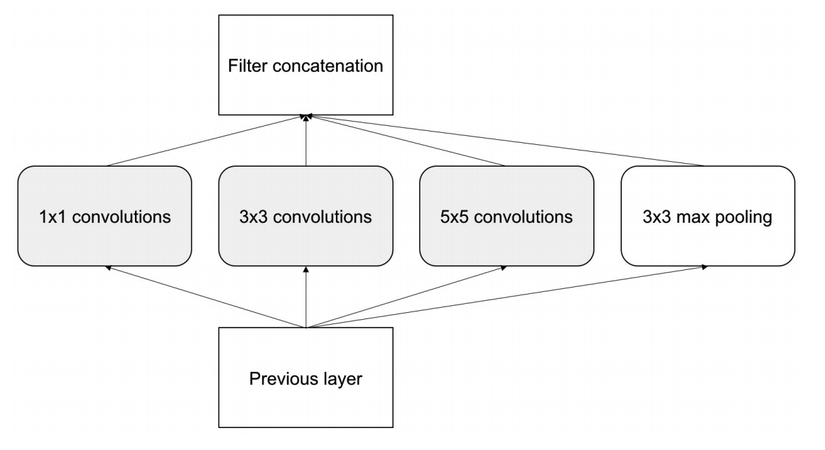
Các tính toán trong các inception module được thực hiện song song không giống như việc thực hiện tuần tự ở mô hình VGG hay Alexnet. Output đầu ra của mỗi inception module là rất lớn do được concatnate nên một filter 1x1 được sử dụng để giảm chiều dữ liệu. Khi có filter 1x1 được add vào thì inception module trở thành cấu trúc như sau:
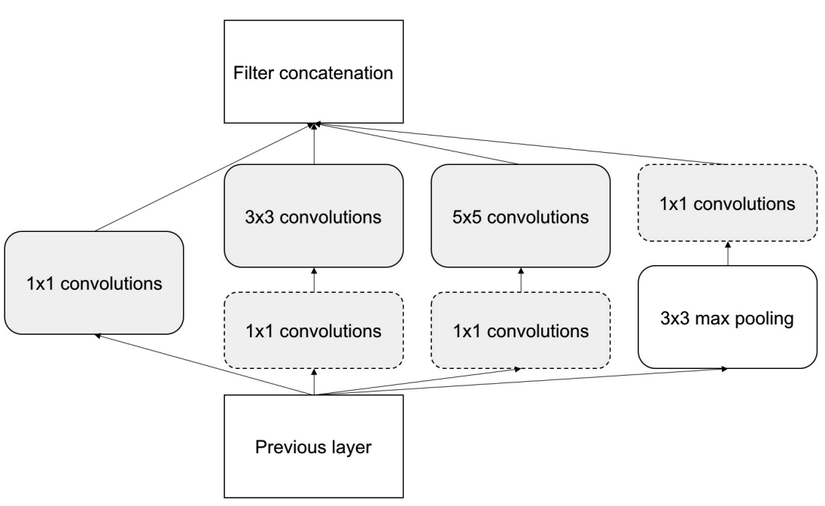
Sau khi kết hợp tất cả các lớp Inception lại chúng ta thu được mô hình tổng quát như sau:
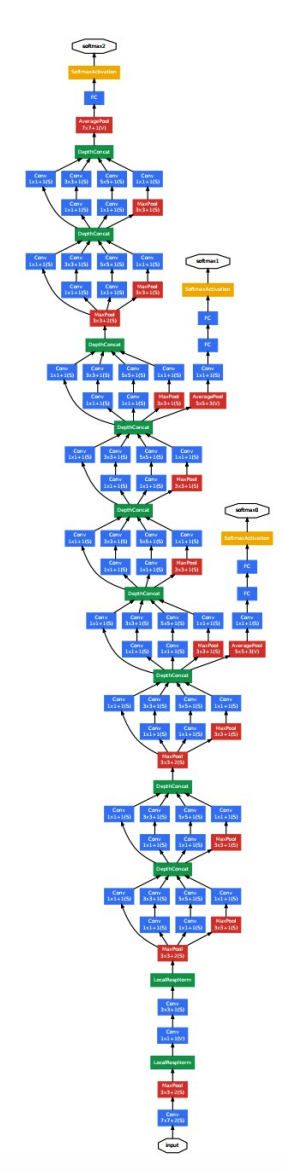
Ở đây sử dụng 9 module inception với tổng cộng khoảng 100 lớp ẩn.
Microsoft ResNet-50
ResNet là mạng đã chiến thắng trong cuộc thi Imagenet năm 2015. ResNet có cấu trúc gần giống VGG với nhiều stack layer làm cho model deeper hơn. Không giống VGG, resNet có depth sâu hơn như 34,55,101 và 151 . Tuy nhiên việc stack rất nhiều layer trong khi thiết kế một mạng Deep Learning cũng nảy sinh nhiều vấn đề. Vấn đề đầu tiên khi tăng model deeper hơn gradient sẽ bị vanishing (biến mất ) hoặc explodes (bùng nổ). Vấn đề này có thể giải quyết bằng cách thêm Batch Normalization nó giúp normalize output giúp các hệ số trở nên cân bằng hơn không quá nhỏ hoặc quá lớn nên sẽ giúp model dễ hội tụ hơn. Vấn đề thứ hai đó chính là degradation, Khi model deeper thì độ chính xác accuracy bắt đầu bão hòa (saturated) thậm chí là giảm. Như hình vẽ sau đây.
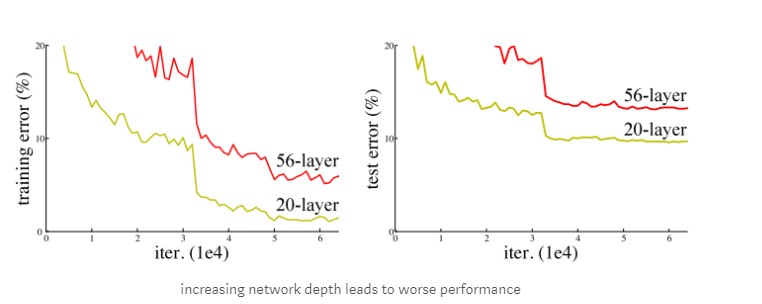
Khi stack nhiều layer hơn thì training error lại cao hơn ít layer như vậy vấn đề không phải là do overfitting. Vấn đề này là do model không dễ training hay khó học hơn, thử tượng tượng một training một shallow model, sau đó chúng ta stack thêm nhiều layer , các layer sau khi thêm vào sẽ không học thêm được gì cả (identity mapping) nên accuracy sẽ tương tự như shallow model mà không tăng. Resnet đã giải quyết vấn đề này bằng cách lan truyền trực tiếp đạo hàm tới các layer sâu hơn thông qua các residual block như sau:
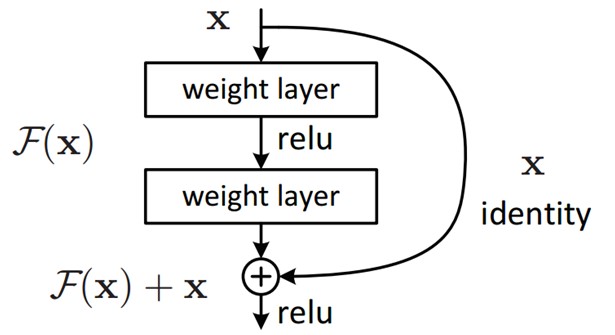
ResNet có architecture gồm nhiều residual block, ý tưởng chính là skip layer bằng cách add connection với layer trước. Ý tưởng của residual block là feed foword qua một số layer conv-max-conv, ta thu được sau đó add thêm vào $ H(x) = F(x) + x$ . Model sẽ dễ học hơn khi chúng ta thêm feature từ layer trước vào.
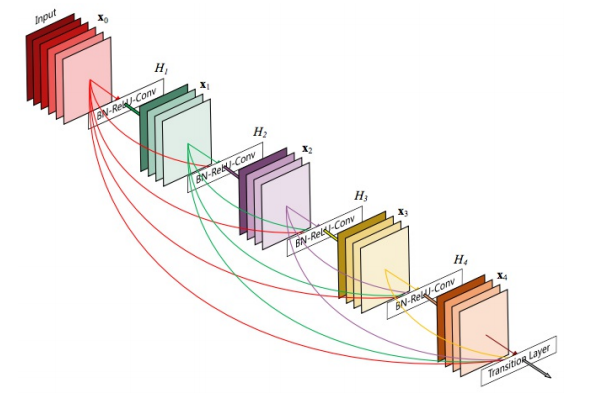
DenseNet
Densenet là một trong những biến thể mở rộng của Resnet. Tuy nhiên trong Resnet chúng ta có thể thấy rằng layer trước sẽ được merge vào layer tiếp theo thông qua phép cộng. Trong Densenet thì sử dụng phép concatenation để thực hiện việc đó. Densenet thực hiện kết nối tất cả các layer với layer trước đó và kết nối layer hiện tại với các layer tiếp theo sau. Chính vì thế Densenet cho một số ưu điểm hơn so với các mạng trước đó như
- Accuracy : Densenet training tham số ít hơn 1 nửa so với Resnet nhưng có same accuracy so trên ImageNet classification dataset.
- erfitting : DenseNet resistance overfitting rất hiệu quả.
- ảm được vashing gradient.
- dụng lại feature hiệu quả hơn.
Trên đây chúng ta đã cùng nhau điểm qua các mạng phổ biến dược sử dụng trong bài toán Image Classification. Chúng ta có thể thực hành các mạng này để thấy được sự khác biệt về mặt kết quả tuy nhiên trong thực tế, việc sử dụng kết hợp nhiều phương pháp khác nhau thường sẽ cho hiệu quả tốt hơn. Phần kế tiếp chúng ta sẽ cùng nhau tìm hiểu một vài kĩ thuật thường sử dụng trong tiền xử lý hình ảnh khi áp dụng Deep Learning. Chúng ta tiếp tục nhé.
Data Augmentation
Như các bạn đã biết, một bài toán về Deep Learning đòi hỏi một lượng lớn về dữ liệu và không phải trong thực tế lúc nào cũng có đầy đủ lượng dữ liệu cho chúng ta. Thế nên việc làm phoing phú dữ liệu là một việc làm cần thiết. Thuật ngữ đó được gọi là Data augmentation. Data augmentation giúp chúng ta tăng kích thước của tập dữ liệu lên nhanh chóng đồng thời thay đổi, thêm mới các tính chất vào trong dữ liệu hiện tại giúp cho độ phong phú của dữ liệu trở nên dồi dào hơn. Kĩ thuật này đặc biệt hữu ích khi các tập dữ liệu của chúng ta là nhỏ. Sau đây chúng ta sẽ tìm hiểu một vài kĩ thuật trong số đó áp dụng cho dữ liệu dạng hình ảnh (image).
- Flipping : lật ảnh theo chiều dọc hay theo chiều ngang
- Random Cropping - cắt ra ngẫu nhiên một thành phần trong hình ảnh gốc để làm dữ liệu mới
- Shearing - thay đổi góc nhìn của hình ảnh, hình dạng của hình ảnh thông qua các giải thuật transform
- Rotation: xoay ảnh theo một góc nào đó
- Whitening: chỉ giữ lại các thành phần quan trọng trong ảnh thông qua giải thuật Principal Component Analysis
- Normalization - là một phương pháp chuẩn hóa hình ảnh theo giá trị trung bình và độ lệch chuẩn
- Channel shifting: thay đổi các kênh màu làm cho mô hình dễ dàng học được các đặc trưng từ ảnh hơn
Đối với Keras các bạn có thể tìm thấy tất cả các kĩ thuật này ở trong thư viện ImageDataGenerator. Chúng ta có thể sử dụng đoạn code sau để load dữ liệu với việc augmentation ảnh .
generator_train = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1. / 255,
horizontal_flip=True,
zoom_range=0.3,
shear_range=0.3,)
Kết luận
Vậy là chúng ta đã tìm hiểu nốt phần thứ ba trong series các bài viết về các bài toán Computer Vision ứng dụng công nghệ Deep Learning và đây cũng là bài thứ 2 chúng ta cùng nhau tìm hiểu về Image Classification. Đây cũng là bài toán phổ biến nhất trong những bài toán về AI thường được gặp trong thực tế. Bài tiếp theo mình sẽ nói về các kĩ thuật trong Deep learning gắn liền với các bài toán thực tế hơn. Rất hi vọng được các bạn đón nhận. Hẹn gặp lại các bạn trong các bài viết tiếp theo.
All rights reserved
