Deploy ứng dụng Machine learning lên Web server. Phần 7: Ứng dụng CNN trong nhận diện cảm xúc
Bài đăng này đã không được cập nhật trong 7 năm
Demo
Demo: https://tradersupport.club/admin/emotion_recognition
Code: https://github.com/hung96ad/face_classification
Giới thiệu CNN
Convolutional neural network (CNN) là 1 mạng thuộc lớp deep neural networks, thường được ứng dụng chủ yếu trong Computer vision. Ngoài ra còn được ứng dụng trong NLP cho kết quả khá tốt (có thể tham khảo tại đây)
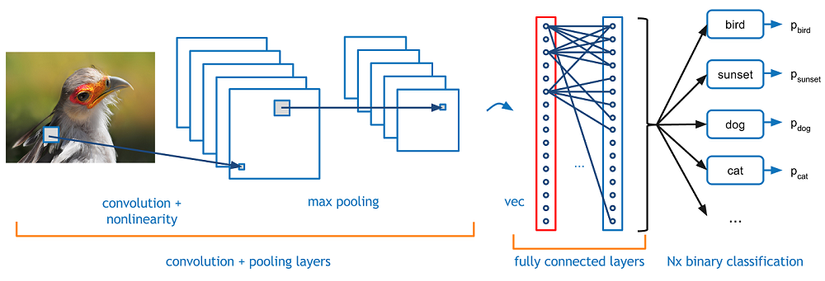
Convolution
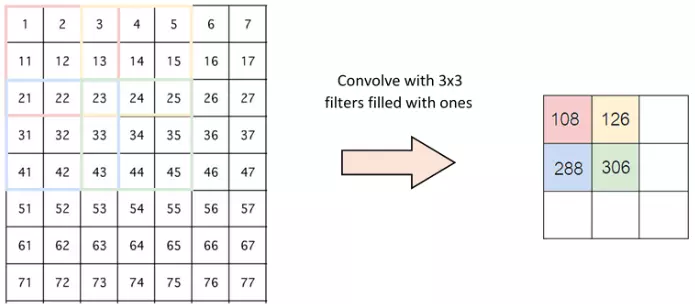
Tư tưởng chính của CNN là trích chọn ra đặc trưng về mặt hình học của bức ảnh thông qua việc "nhân chập" 1 ma trận vuông thường cỡ 3x3, 5x5, 7x7 (gọi là filter matrix).
Ví dụ như sau:
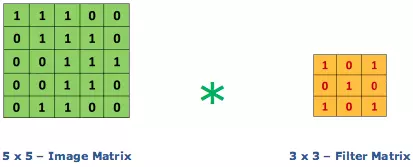
Với việc "nhân chập" với filter matrix trên ta sẽ làm nổi lên những đặc trưng có dạng tương tự như chữ X.
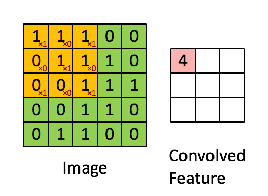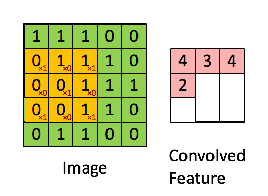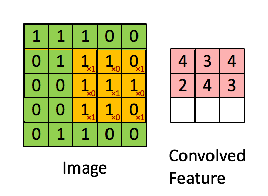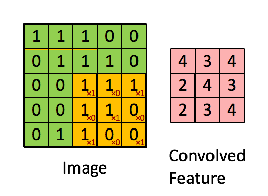
Cụ thể về tích chập 2 chiều các bạn có thể tham khảo thêm tại đây.
Việc huấn luyện CNN chủ yếu là luyện làm sao bộ trọng số của filter matrix hợp lý để có thể trích chọn ra đặc trưng của dữ liệu "tốt nhất".
Sau bước này ta đã thấy số chiều được giảm đi m-1 (m là số chiều của filter matrix) với strides=(1,1).
Tuy nhiên như vậy vẫn chưa đủ vì 1 bức ảnh thông thường kích thước vẫn còn rất lớn không thể đem đi cho vào một mô hình nào để nhận dạng được vì vậy ta cần các bước tiếp theo là pooling
Pooling
Mục đích chính của Pooling đó là làm giảm số chiều (parameter) và vẫn giữ được thông tin quan trọng của bức ảnh vừa "nhân chập" xong.
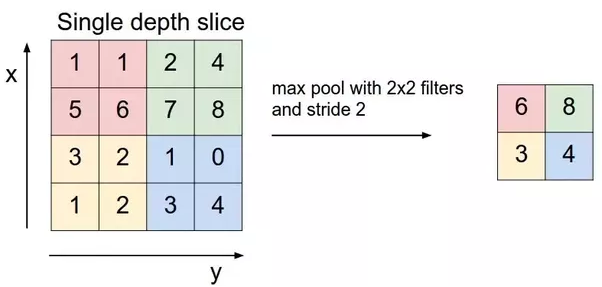
Một số loại Pooling thường sử dụng như:
- Max Pooling
- Average Pooling
- Sum Pooling
Fully Connected
Layer này được dùng để dàn phẳng ma trận vừa thu được sau bước Pooling để được 1 vector.
Vector này sẽ được đem đi để phân lớp. Thường sẽ là hàm softmax (xác xuất để vào lớp x nào đó là lớn nhất).
Một số khái niệm khác
Activation
Lớp này là để tạo ra không gian nonlinear hơn. Điều muốn nhấn mạnh ở đây là nó thật sự không mang weights nào để quá trình học cập nhật cả. Nó chỉ chuyển đổi các giá trị hiện tại sang một miền giá trị khác.
Actiovation là 1 hàm nonlinear thường là ReLU do:
- Bắt buộc là hàm nonlinear vì nếu là hàm linear thì nhiều lớp cũng chẳng có tác dụng gì cả vì sẽ tồn tại 1 phép biến đổi từ lớp này sang lớp kia.
- Hàm ReLU tính toán đơn giản, nhanh và giảm khả năng mất gradient.
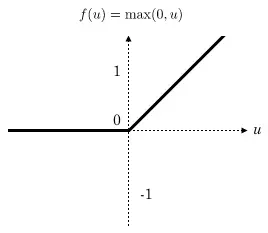
Strides
Strides là số bước trượt pixcel của filter matrix.
Ví dụ: strides = (2,2) tức là ta sẽ trược 2 pixcel sang từ trái qua phải và 2 pixcel từ trên xuống dưới cho đến khi nào không trượt được nữa thì thôi.
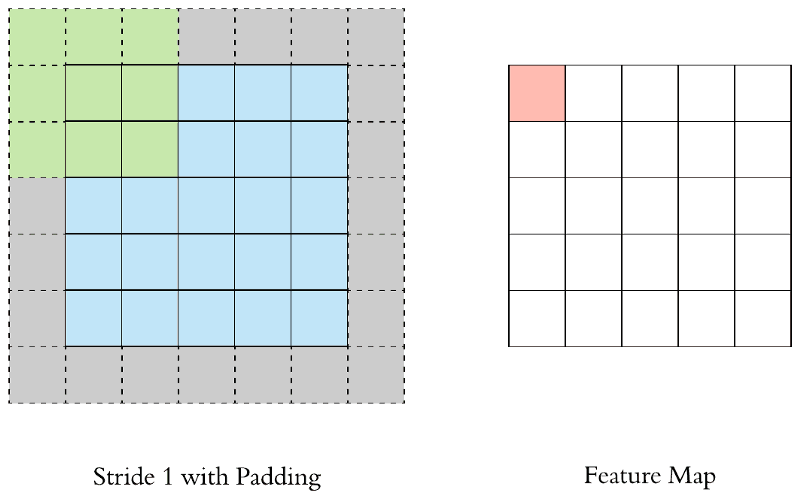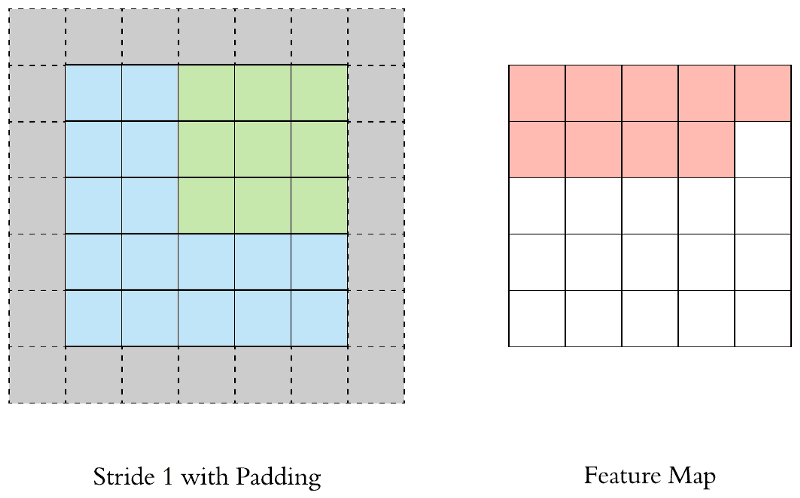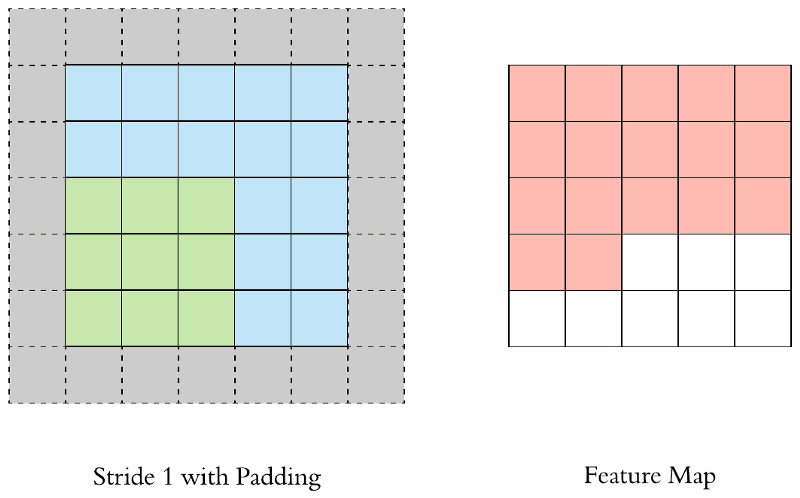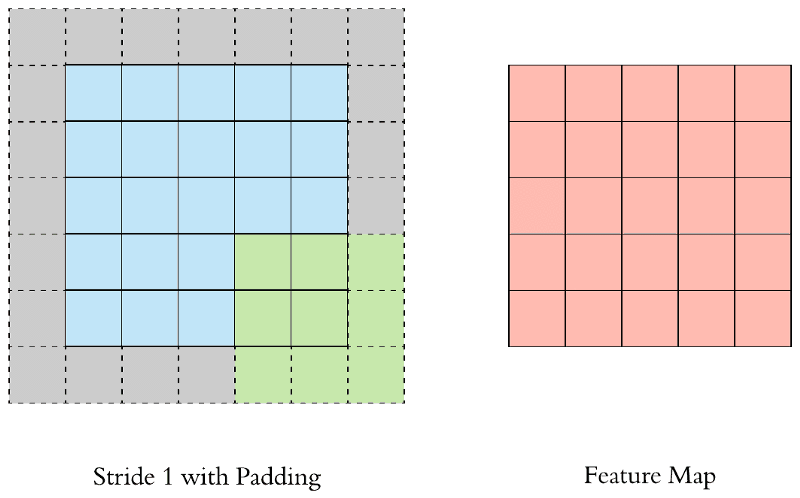
Padding
Như các bạn thấy thì thường sau convolution ta nhận được ma trận với kích thước giảm xuống.
Tuy nhiên trong một số trường hợp thì ta lại không mong muốn số chiều này giảm xuống như vậy vì ảnh có thể bị mất dữ liệu. Như ví dụ trên strides=(2,2) việc mất dữ liệu có thể là rất cao dẫn tới việc mô hình nhận dạng của ta không còn được chính xác nữa (underfitting).
Vì vậy người ta mới nghĩ ra 1 kĩ thuật là padding để không làm giảm số chiều sau việc nhân chập đó là padding.
Cụ thể là bạn bị mất bao nhiêu pixcel thì chỉ cần bọc chúng bằng 1 cái bao khác thôi thường sẽ là các bao bằng 0 ở quanh để không làm xuất hiện thêm các đặc trưng mới của ảnh.
Separable Convolutions
Về mặt toán học thì đây là phương pháp đó là tách 1 ma trận ra thành tích của 2 vector.
Layer đặc biệt có tác dụng trong detect các cạnh về chiều dọc hoặc ngang.
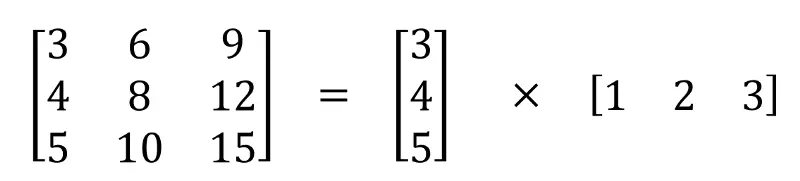
Chi tiết các bạn tham khảo tại đây
Batch Normalization
Về lý thuyết toán thì layer này có tác dụng trong 2 việc đó là:
- Tránh gradient tiến về 0 sẽ chẳng biết là đi lên hay xuống.
- Gradient quá lớn khiến các tham số không thể tối ưu được (loss sẽ nhảy lung tùng).
Cụ thể là nó giúp chuẩn hóa dữ liệu về 1 khoảng nào đó ví dụ (1,100).
Các bạn xem video sau để hiểu rõ hơn nhé:
Dropout
Cái tên đã nói lên tất cả layer này dùng để ẩn 1 số unit trong hidden trong quá trình trainning để tránh việc overfitting.
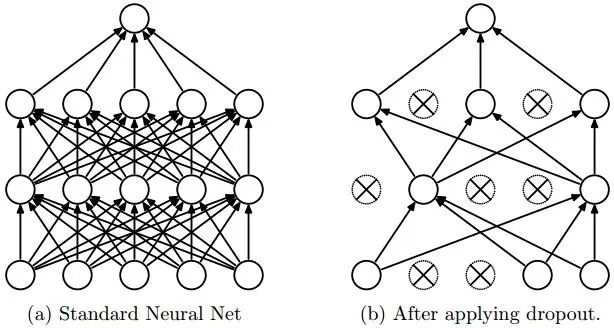
Việc này thì mình chưa rõ cơ sở lý thuyết là gì nhưng theo mình hiểu gì là giả định với việc ẩn đi 1 số unit trong quá trình trainning sẽ tránh được việc mô hình quá fit với dữ liệu train để tránh overfitting.
Cái này thì dựa vào thực nghiệm chứ không biết được có nên cho vào model hay không.
Hyperparameter
Là một chiến lựa trên kĩ thuật Heristic (mình hay gọi là quy tắc vàng dựa vào kinh nghiệm) thường được chọn thủ công để tìm ra được các parameter chấp nhận được trong quá trình huấn luyện.
Chẳng hạn như: learning rate, trọng số khi ensemble model,...
Ensemble learning
Trong thống kê và ML, phương pháp này được dùng để tổng hợp nhiều mô hình để có kết quả chính xác hơn.
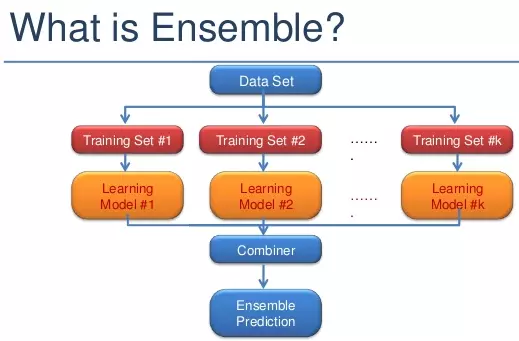
Phương pháp này được lấy ý tưởng tương tự như suy nghĩ của chúng ta vậy, đó là đông người bảo nó đúng thì nó là đúng (tổng xác xuất ảnh A được phân vào lớp X đúng khi nhiều model cho kết quả như vậy).
Có 2 kĩ thuật ensemble chính:
- Voting
- Tổng hợp có trọng số (lựa chọn trọng số mỗi model thế nào để cho được kết quả tốt là 1 bài toán NP-hard)
Tuy nhiên kĩ thuật này lại dễ bị overfitting do kết quả quá tốt so với tập test.
Build model
Model base mình tham khảo chủ yếu tại đây: https://github.com/oarriaga/face_classification
Code của mình: https://github.com/hung96ad/face_classification
Model như sau:
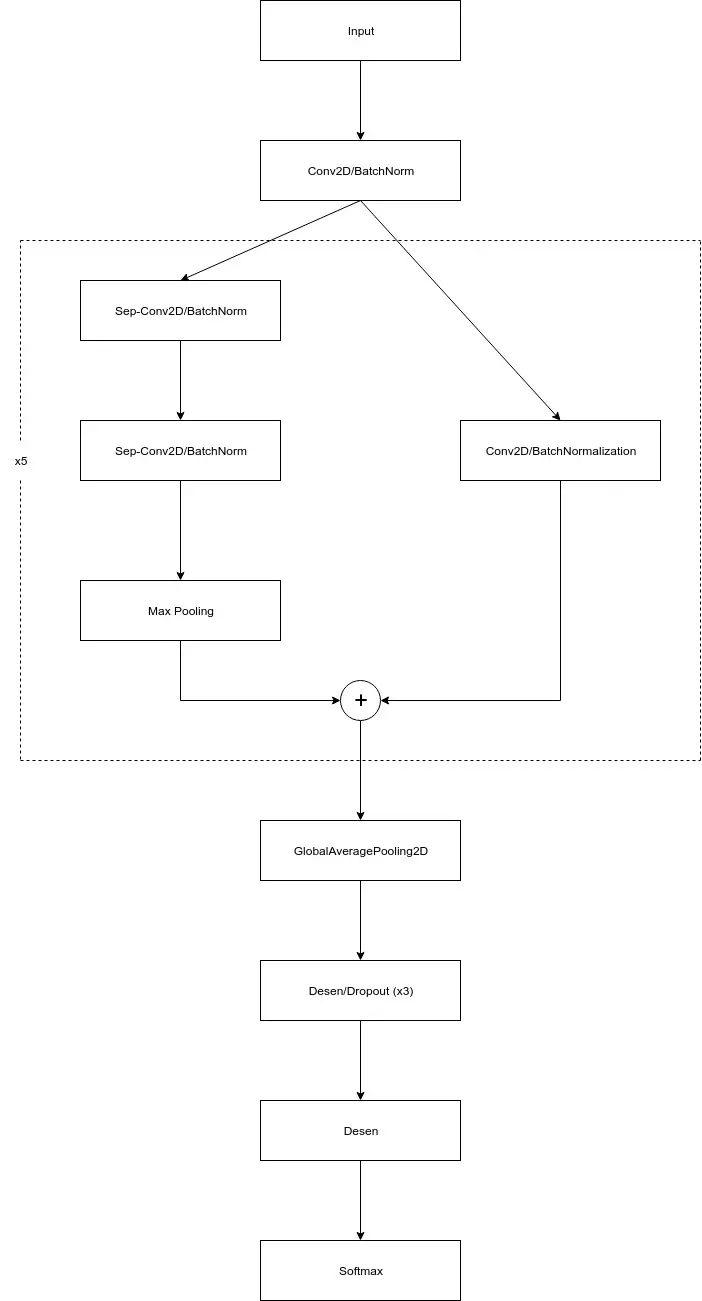
def detect_emotion_model(input_shape, num_classes, l2_regularization=0.01, rate_dropout=0.3):
regularization = l2(l2_regularization)
# base
img_input = Input(input_shape)
x = Conv2D(8, (3, 3), strides=(1, 1), kernel_regularizer=regularization,
use_bias=False)(img_input)
x = BatchNormalization()(x)
x = Activation('relu')(x)
for i in range(1,6):
filters = 8*pow(2,i)
residual = Conv2D(filters, (1, 1), strides=(2, 2),
padding='same', use_bias=False)(x)
residual = BatchNormalization()(residual)
x = SeparableConv2D(filters, (3, 3), padding='same',
kernel_regularizer=regularization,
use_bias=False)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = SeparableConv2D(filters, (3, 3), padding='same',
kernel_regularizer=regularization,
use_bias=False)(x)
x = BatchNormalization()(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)
x = layers.add([x, residual])
x = Dropout(rate_dropout)(x)
# Output
x = GlobalAveragePooling2D()(x)
x = Dense(128, activation='relu')(x)
x = Dropout(rate_dropout)(x)
x = Dense(64, activation='relu')(x)
x = Dropout(rate_dropout)(x)
x = Dense(32, activation='relu')(x)
x = Dropout(rate_dropout)(x)
x = Dense(num_classes, activation='relu')(x)
output = Activation('softmax', name='predictions')(x)
model = Model(img_input, output)
return model
Train thử thì accuracy trên tập validation (theo tỷ lệ 2-8) được 0.64.
Model bạn có thể tải tại đây
Random model
Nghe có vẻ ngu ngu nhưng mà về mặt lý thuyết thì cũng chẳng rõ là bao nhiêu units, hidden, có sử dụng bias, Batch Normalization, Dropout hay không để có được mô hình là "tốt".
Tất cả dựa vào thực nghiệm nên mình mới nảy ra ý tưởng là cho sinh model ngẫu nhiên xem thế nào. Không ngờ kết quả tốt hơn thật  .
.
def random_model(input_shape, num_classes, l2_regularization=0.01):
activations = ['softmax', 'elu', 'selu', 'softplus', 'softsign', 'relu', 'tanh', 'sigmoid', 'linear']
rate_dropout = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6]
len_rate = len(rate_dropout)
len_activations = len(activations)
use_bias = [False, True]
regularization = l2(l2_regularization)
num_layers = randrange(2, 9, 1)
# base
img_input = Input(input_shape)
x = Conv2D(8, (3, 3), strides=(1, 1), kernel_regularizer=regularization,
use_bias=False)(img_input)
x = BatchNormalization()(x)
x = Activation(activations[randrange(0, len_activations,1)])(x)
# module
for i in range(num_layers):
filters = randrange(2, 8, 1) * 8
kernel_size = randrange(3, 8, 2)
kernel_size = (kernel_size, kernel_size)
stride = randrange(1, 3, 1)
strides_random = (stride, stride)
use_bias_random = use_bias[randrange(0, 2, 1)]
residual = Conv2D(filters, kernel_size, strides=strides_random,
padding='same', use_bias=use_bias_random)(x)
if use_bias[randrange(0, 2, 1)]:
residual = BatchNormalization()(residual)
x = SeparableConv2D(filters, kernel_size,
padding='same',
kernel_regularizer=regularization,
use_bias=use_bias_random)(x)
if use_bias[randrange(0, 2, 1)]:
x = BatchNormalization()(x)
x = Activation(activations[randrange(0, len_activations,1)])(x)
x = SeparableConv2D(filters, kernel_size,
padding='same',
kernel_regularizer=regularization,
use_bias=use_bias_random)(x)
if use_bias[randrange(0, 2, 1)]:
x = BatchNormalization()(x)
x = MaxPooling2D(kernel_size, strides=strides_random,
padding='same')(x)
x = layers.add([x, residual])
if use_bias[randrange(0, 2, 1)]:
x = Dropout(rate_dropout[randrange(0, len_rate, 1)])(x)
# Output
x = Conv2D(num_classes, (3, 3),
activation = activations[randrange(0, len_activations, 1)],
padding='same')(x)
if use_bias[randrange(0, 2, 1)]:
x = GlobalAveragePooling2D()(x)
else:
x = GlobalMaxPooling2D()(x)
output = Activation('softmax', name='predictions')(x)
model = Model(img_input, output)
return model
Kết quả đạt được là accuracy: 0.693
Các bạn có thể tải model đã train tại đây: https://drive.google.com/open?id=1V-4m9cgLKJmIZk5wTlwd86ePrQP515Z1
Kết quả
Chạy thử model detect face mình may kết quả vẫn đúng.

Do tập dữ liệu là tập fer2013 chủ yếu data là người châu Âu nên khi detect mặt mình (người châu Á) có chút thay đổi nên khả năng nhận diện sai khả khá cao.
Nếu muốn cải thiện model thì các bạn có thể train với tập dữ liệu là người châu Á tại đây.
Kết luận
Trên đây là những hiểu biết cá nhân của mình có thể có nhiều chỗ mình hiểu chưa được đúng mong mọi người góp ý để series hoàn thiện hơn.
Face detection mình dùng opencv haar cascade nên nhiều lúc bắt face không được chính xác cho lắm đặc biệt là ảnh có nhiều face.
Nếu bạn nào có model dectection face tốt hơn thì comment nhé!
Thank you!
Bài tiếp theo: Hướng dẫn triển khai với mô hình với Docker.
Reference
- https://github.com/oarriaga/face_classification
- https://www.kaggle.com/c/challenges-in-representation-learning-facial-expression-recognition-challenge/data
- https://medium.com/@RaghavPrabhu/understanding-of-convolutional-neural-network-cnn-deep-learning-99760835f148
- https://keras.io/
- https://machinelearningcoban.com/2018/10/03/conv2d
- https://towardsdatascience.com/a-basic-introduction-to-separable-convolutions-b99ec3102728
- https://viblo.asia/p/ung-dung-convolutional-neural-network-trong-bai-toan-phan-loai-anh-4dbZNg8ylYM#_convolution-1
- https://ereka.vn/post/chia-se-ve-mang-noron-tich-chap-convolutional-neural-networks-or-convnets-52790224348847566
- https://viblo.asia/p/dropout-trong-neural-network-E375zevdlGW
- https://towardsdatascience.com/batch-normalization-in-neural-networks-1ac91516821c
- https://stackoverflow.com/questions/9782071/why-must-a-nonlinear-activation-function-be-used-in-a-backpropagation-neural-net
- https://stats.stackexchange.com/questions/126238/what-are-the-advantages-of-relu-over-sigmoid-function-in-deep-neural-networks
- https://arxiv.org/pdf/1408.5882.pdf
- https://www.kairos.com/blog/60-facial-recognition-databases
All rights reserved
