
A discussion of SSD Intuition
Bài đăng này đã không được cập nhật trong 6 năm
Mục tiêu bài viết: Mang tính thảo luận Đối tượng: begginers về Object Detection
I . Intuition
Puzzle 1: Tìm táo.
Tưởng tượng bạn muốn có một AI program có khả năng xác định vị trí của quả táo trong ảnh, biết mỗi bức chỉ chưa một quả , và kích thước các quả trong các bức gần bằng nhau. Như sau:
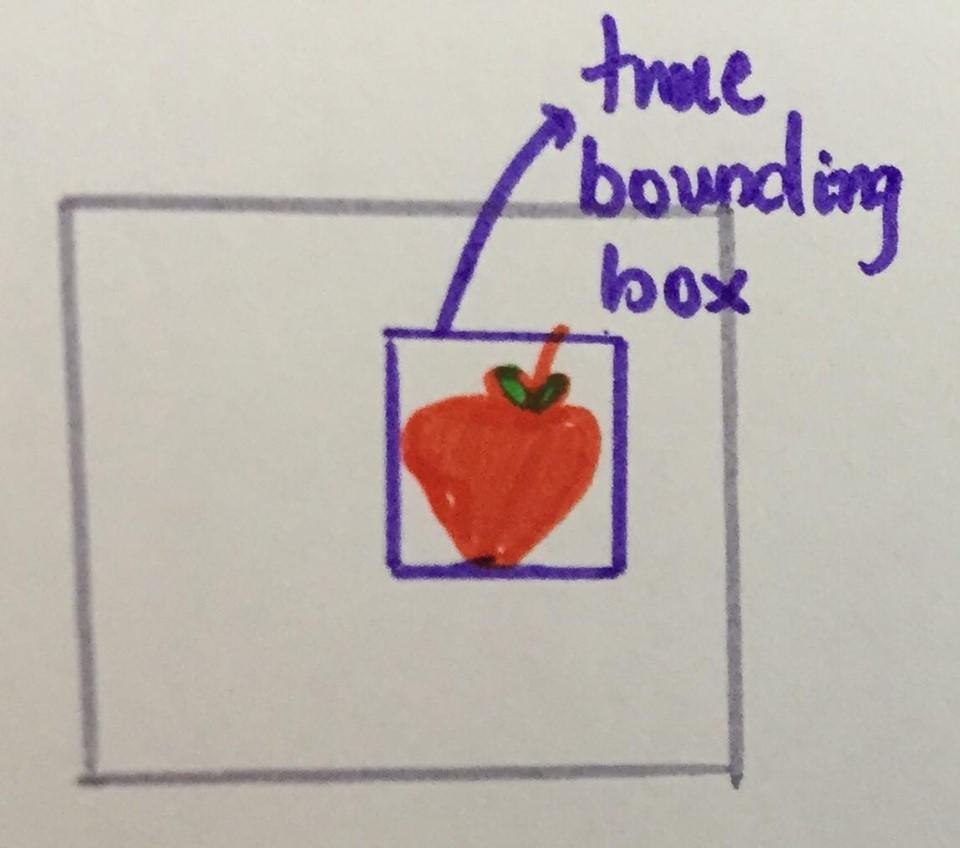
Vị trí của vậy được diễn tả với bounding box, một hình chữ nhật bao sát vật đó.
Khá đơn giản đúng không? Bạn có thể giải bài này như một bài regression thông thường: 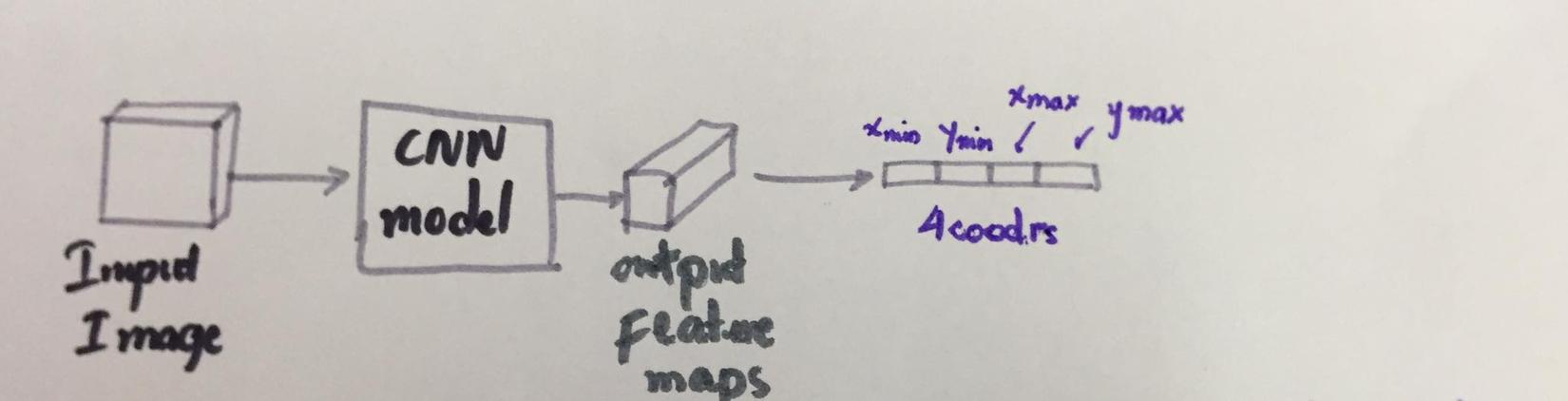
Puzzle 2: Tìm một vật :
Giả sử bạn cần tìm [chó, táo, pizza, chuối] trong các bức ảnh, biết mỗi bức ảnh chỉ có một vật, và kích cỡ các vật khá tương đồng.
Bài này khó hơn một chút rồi đúng không, nhưng chúng ta có thể chia nhỏ bài này ra thành hai bài nhỏ. Đấy là classification và regression: thay vì chỉ tìm vị trí của vật, ta còn xác định xem đó là vật gì.
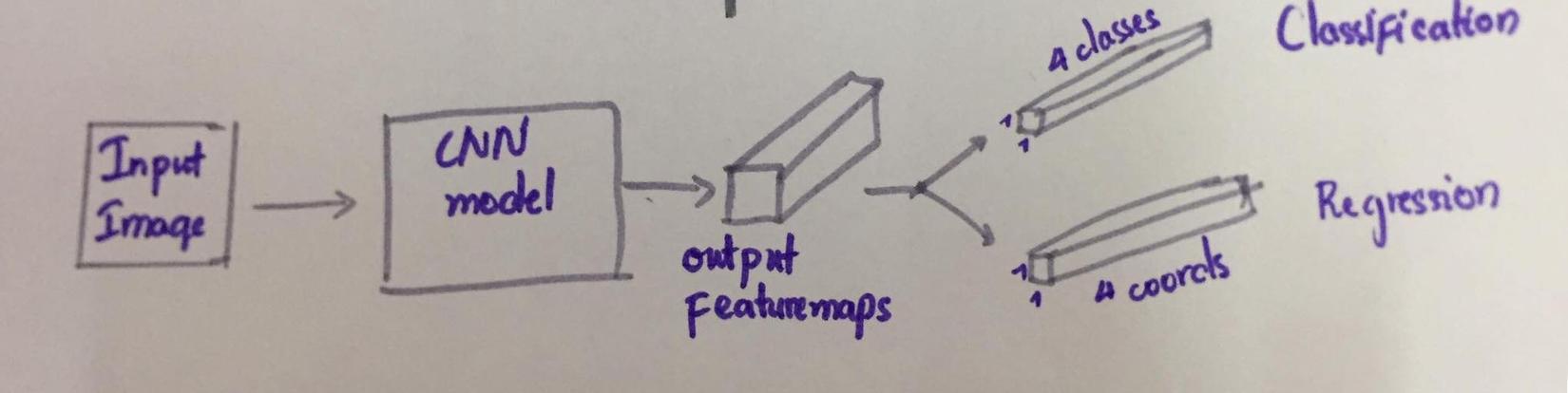
Puzzle 3: Tìm nhiều vật
Vẫn giả sử bạn cần tìm [chó, táo, pizza, chuối] trong các bức ảnh, nhưng bây giờ mỗi bức có thể có nhiều vật, mặc dù các vật vẫn sẽ có kích thước gần bằng nhau (chó to bằng táo =)) ). Phức tạp hơn rồi đúng không?
Khó khăn đầu tiên của bài này là ta không biết mỗi ảnh có bao nhiêu vật. Mỗi vật sẽ gắn với 4 coordinates ( để xác định vị trí của vật ) và như vậy ít nhất chúng ta đã không thể xác định được output size của bài regression. Ngoài ra, chúng ta cũng không thể predict class của các vật trong ảnh như cách chúng ta làm trong hai puzzles trên.
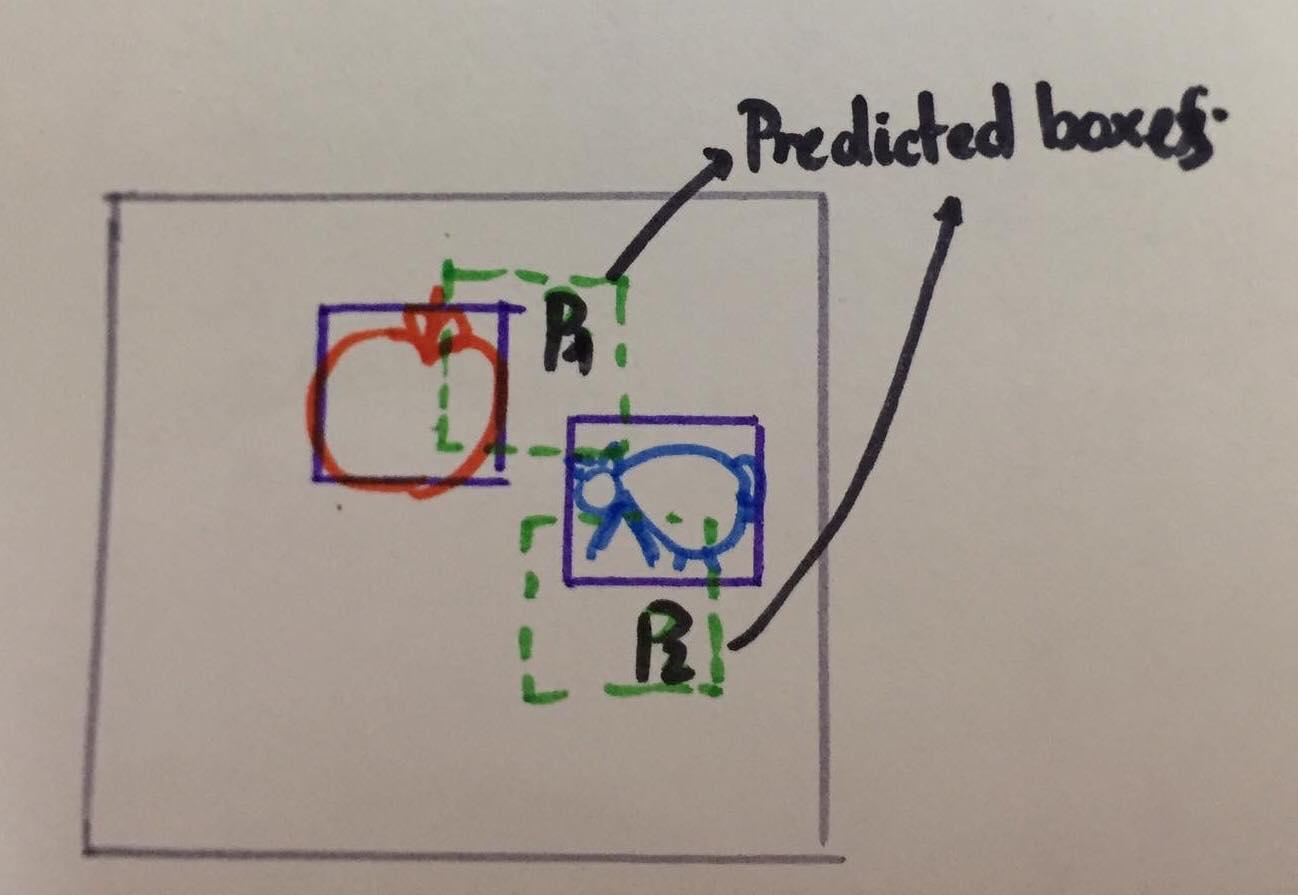
Khó khăn thứ 2
Nhìn hình ta thấy, giả sử model của tôi predict boxes P1, P2 (prediction box) như trên hình. Vậy true label của nó sẽ là box nào? Ta không thể biết được P1, P2 đang cố gắng predict chó hay táo, và vì thế ta không biết vật nào có thể give feed back cho P1, P2. Bạn có thể thử cách : P1 gần hơn với táo vì thế PP đang cố predict táo và vị trí của nó. Nhưng trong training, P1 có thể chạy tùm lum bất cứ đâu, nó không cố định, lúc thì model cho ra P1 ở vị trí này, predict vật này, lúc sẽ ở vị trí khác, predict vật khác:
Có một trick mà ta có thể dùng cho hai khó khăn trên: anchor box (default box/ prior box)
Idea là: chúng ta tạo ra một lượng boxes (cùng kích cỡ ) cho mỗi bức ảnh, ( size và vị trí của các box đó đều được định trước, tạm gọi là default/ prior boxes), giống như một sự ước lượng trước xem vật ở vị trí nào và ước lượng đó có thể đúng hoặc sai.
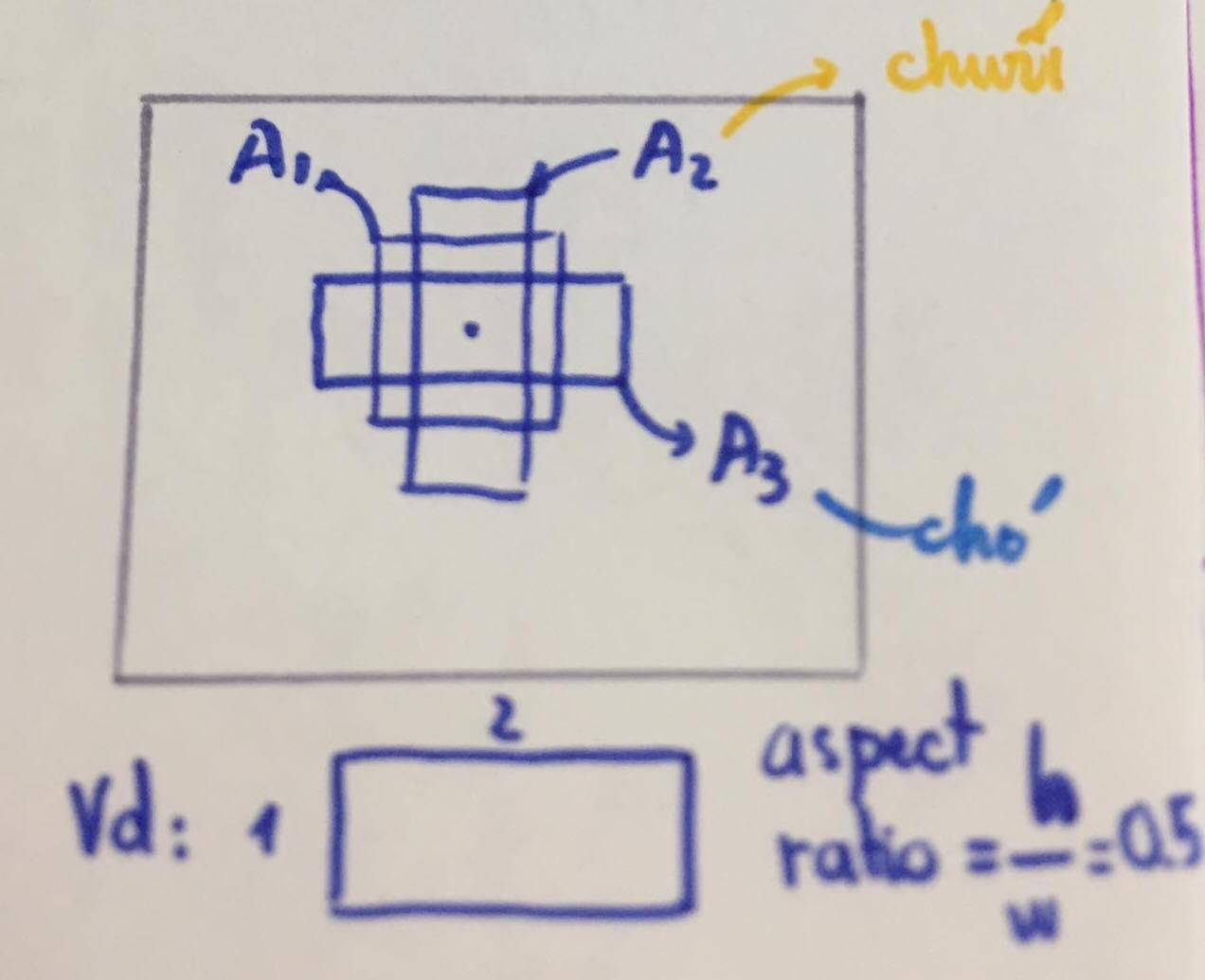
Giả sử ảnh có 8 default boxes, thì ta sẽ output 8 prediction boxes, mỗi box associate (liên kết) với một default box . Vd: default box 3 liên kết với prediction box 3, thì default box 3 sẽ chịu tránh nhiệm nói cho pred_box 3 biết nó đang phải predict vật gì, ở đâu (labeling anchor boxes)
 Như ở hình trên default box 3 giống với true bounding box của táo hơn là của chó. Như vậy prediction box P3 tương ứng với default box A3 sẽ chịu trách nhiệm predict táo và vị trí (bounding box) của táo. Các default box khác, như A2 không giống hay gần với bất cứ true bounding box nào, thì prediction box tương ứng với nó sẽ predict back ground class.
Như ở hình trên default box 3 giống với true bounding box của táo hơn là của chó. Như vậy prediction box P3 tương ứng với default box A3 sẽ chịu trách nhiệm predict táo và vị trí (bounding box) của táo. Các default box khác, như A2 không giống hay gần với bất cứ true bounding box nào, thì prediction box tương ứng với nó sẽ predict back ground class.
Như vậy: output size của model đã được xác định, trong trường hợp này là 8 *(1+4+ 4) (problem 1 solved) ( 8: default boxes, 1: back ground class, 4 object classes, và 4 coordinates). Và giờ ta có thể biết P1, P2 predict vật gì và vị trí của vật đó (dựa vào default boxes tương ứng) (problem 2 solved).
Tuy nhiên, vấn đề chưa hết ở đây.
- T giả sử các vật cùng size nhưng không cùng “aspect ratios”, và giả sử các vật overlap với nhau, thì default box sẽ không biết được prediction box tương ứng của nó nên predict cho vật nào:
![]()
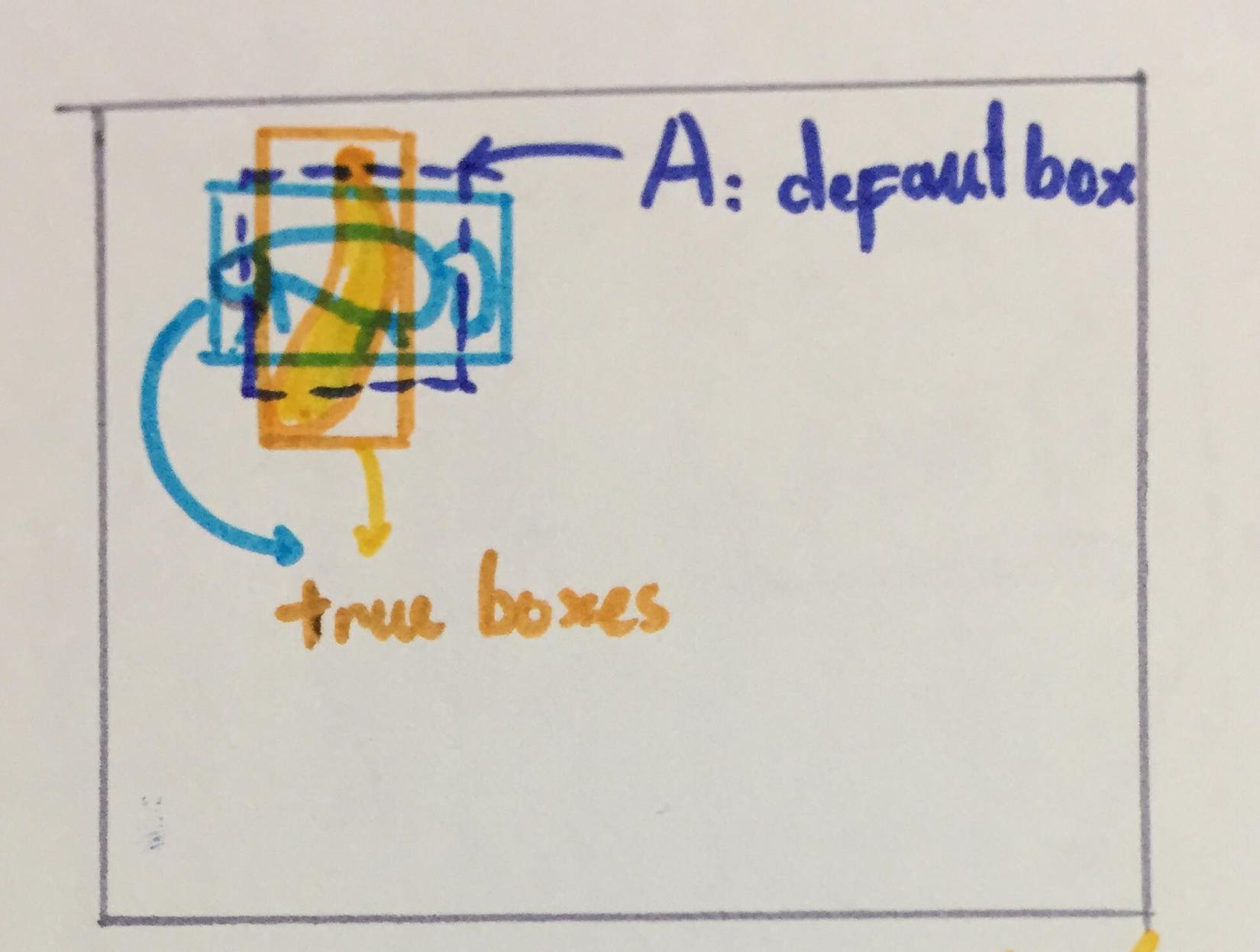
Vấn đề này có thể được giải quyết bằng cách tạo vài default boxes, ở cùng một vị trí, với các aspect ratios khác nhau, để prediction boxes tương ứng của chúng có thể predict nhiều vật khác nhau ở cùng một vị trí.
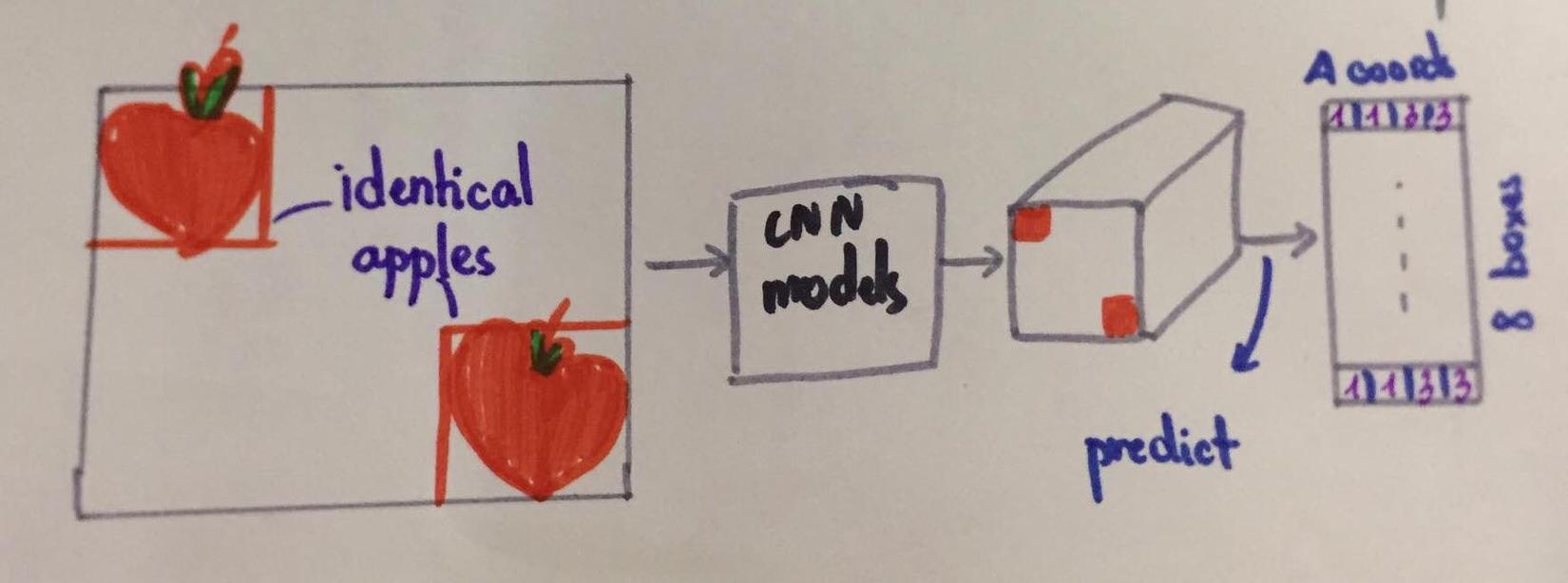
- Vấn đề này nghiêm trọng hơn: Giả sử hai quả táo trong hình là giống nhau, nhưng ở vị trí khác nhau:
Khi make prediction cho coordinates của 2 quả táo, như hình trên ta dùng a convolutional layer. Mà đặc điểm của conv_operation là weight sharing. như vậy nếu 2 quả táo giống nhau, nhưng ở vị trí khác nhau thì khi các filters đi qua chúng, sẽ cho output (4 coordinates) giống nhau. (hãy tưởng tượng hai quả táo là hai bức ảnh nhỏ giống hệt nhau, vì tất nhiên khi đưa qua convolutional layers sẽ cho ra out put giống hệt nhau. (same in, same out). Như vậy model sẽ predict vị trí tuyệt đối của hai quả táo này là như nhau => predict sai.
Một giải pháp là thay vì predict vị trí tuyệt đối của vật (absolute coordinates) ta predict vị trí tương đối(relative position) của nó so với cái cố định sẵn. Cái cố định sẵn đó chính là default box. Vậy vị trí của hai default box tương ứng với hai quả táo là khác nhau, khi model output the same relative position của hai quả táo đó, thì absolute coordinate prediction của chúng vẫn khác nhau.
Một trong những option ta có thể chọn để biểu diễn ralative position của prediction box hoặc true bounding box so với default box là offset. Offset ( lệch ), có thể nhận giá trị âm, khác với distance, vd như sau:
 Ở ví dụ trên, tôi đã đơn giản hóa công thức của offset cho mục đích minh họa, ở trong paper, công thức sẽ phức tạp hơn.
Ở ví dụ trên, tôi đã đơn giản hóa công thức của offset cho mục đích minh họa, ở trong paper, công thức sẽ phức tạp hơn.
Puzzle 4: như puzzle 3, nhưng các vật có kích thước khác nhau
(có vẻ gần với thực tế hơn nhiều rồi =)))
Như ở trên, để labeling a default box A ( tức là để xem prediction box tương ứng (correspond ) với A) sẽ predict cho vật và ground truth box B nào, ta sẽ xem box A "giống" với box B nào nhất.
Nhưng khi các vật có kích cỡ khác nhau mà các default box A chỉ có một scale, thì rất khó để xem box A sẽ giống với box B1 hơn hay B2 hơn trong hình sau:
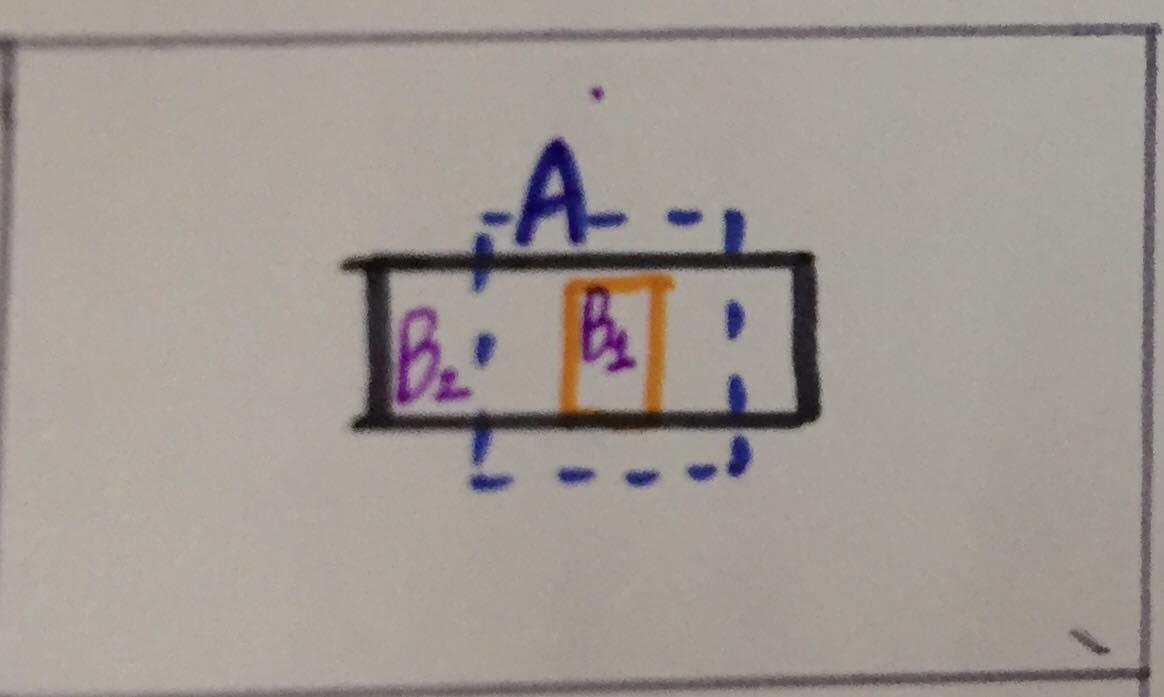
Vì vậy, một ý tưởng có thể giải quyết điều này là thay vì chỉ có một scale kèm với vài aspect ratios, ta sẽ định trước nhiều default boxes với scales khác nhau tại mỗi vị trí trên ảnh: (Paper sẽ có cách sử lý khác ở phần này, ta sẽ cùng tìm hiểu sau khi đi chi tiết vào paper)
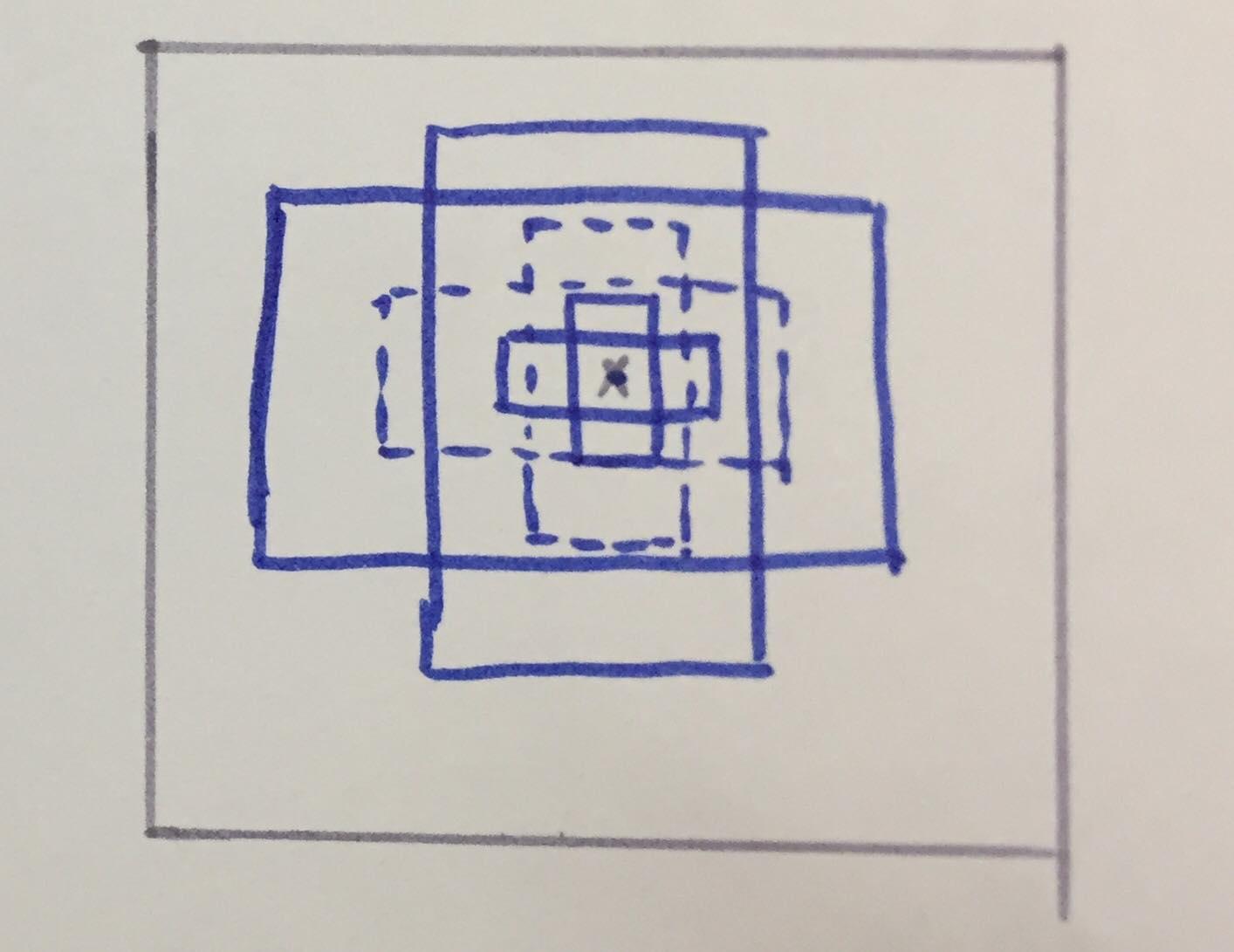
Tuy nhiên, còn một vấn đề khác khi các vật có nhiều kích cỡ : nếu như ta chỉ sử dụng feature maps của một layer của model để predict boxes thì sẽ xảy ra 2 trường hợp không tốt sau:
TH1: giả sử model có 50 conv_layers. Nếu dùng layer quá thấp để extract feature và make prediction thì sẽ gây khó khăn cho việc predict các vật có kích thước lớn. Lý do là càng layer ở cao, thì càng extract more abstract features cộng với việc receptive field trên input image của mỗi unit trên các high level feature maps lớn hơn nhiều receptive field của mỗi unit ở low- level feature maps. Hãy thử tưởng tượng bạn muốn program classify và tìm một quả táo với một cái nhà, trên một ảnh . Hình ảnh của quả táo gắn với nhiều feature đơn giản trong khi nhà gắn với feature high level và phức tạp hơn nhiều. Hơn nữa nhà to, cần information của gần như toàn bộ ảnh, trong khi táo nhỉ, chỉ cần một góc info là được:
TH2: Nếu dùng high-level feature maps để predict các vật và vị trí của chúng thì sẽ gâp khó khăn trong việc predict các vật nhỏ. Vd: feature maps của conv layer thứ 50 sẽ chỉ chứa high-level activated features (vd: số ô của sổ, mái ngói) mà mất nhiều detailed information (vd: cái lá hay đường cong của quả táo)
Như vậy để cân bằng, ta chọn nhiều feature maps cho prediction hay vì một cái. Chi tiết về paper và cách implement paper sẽ được đề cập ở phần sau.
All rights reserved
