
Deep Learning cho những máy tính thiếu RAM
Bài đăng này đã không được cập nhật trong 6 năm
RAM - Random Memory Access: Bộ nhớ truy xuất ngẫu nhiên, là nơi chứa và cung cấp tài nguyên cho các tiến trình đang được xử lí trên máy tính. Nếu bạn đang bắt đầu tìm hiểu về Deep Learning, hoặc đã có những kinh nghiệm nhất định trong lĩnh vực này, thì chắc chắn rằng bạn sẽ ít nhất một lần trong đời (nếu không phải bây giờ thì sẽ là sau này  ), bạn sẽ bắt gặp trường hợp: Không có đủ bộ nhớ (RAM) để train mô hình của bạn - Out of Memory.
), bạn sẽ bắt gặp trường hợp: Không có đủ bộ nhớ (RAM) để train mô hình của bạn - Out of Memory.
Khi đó, bạn sẽ xử lí tình huống chớ trêu này như thế nào?
Blog lần này mình sẽ chia sẻ một số cách giúp tối ưu quá trình sử dụng RAM của mô hình Deep Learning. Hi vọng có thể giúp được phần nào cho các bạn 
Let's get started!

1. Neural Network sử dụng bộ nhớ như thế nào?
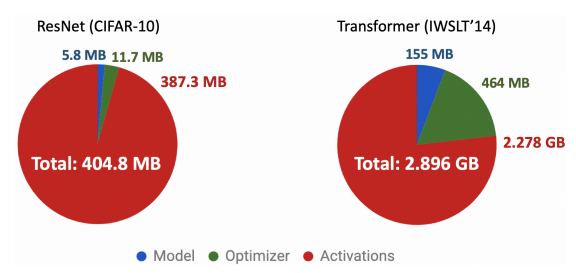
Trước hết để tối ưu được RAM sử dụng cho các mạng Neural sử dụng trong Deep Learning. chúng ta cần nắm được: Các mạng Neural ấy sử dụng RAM như thế nào? Thông thường, một mạng Neural sẽ tiêu tốn memory cho 3 phần chính: Model memory, Optimizer memory và Activation memory (đương nhiên là còn 1 vài loại nữa mà mình không nêu thôi :3 ). Các bạn có thể quan sát 2 biểu đồ dưới đây của 2 mạng ResNet và Transformer :
-
Model Memory
Model memory là tổng hợp bộ nhớ được sử dụng để lưu các tham số (parameter) của mô hình. Parameter ở đây bao gồm các trọng số của kernel (đối với mạng neural tích chập - convolution neural network), các node của lớp đầu vào (input layer), lớp ẩn (hidden layer) và lớp đầu ra (output layer), bias, ...
Model memory chiếm bộ nhớ nhỏ nhất trong 3 lọai memory (quan sát biểu đồ) và bạn hoàn toàn có thể thay đổi model memory nếu bạn thay đổi kiến trúc mô hình mạng neural của bạn.
-
Optimizer Memory
Optimizer memory thì thường lớn gấp 2 đến 3 lần model memory. Optimizer memory ở đây là phần memory được sử dụng lưu các giá trị đạo hàm trong quá trình thực hiện Gradient Descent để cập nhật trọng số.
Có thể hiểu cụ thể hơn như thế này: Khi một mạng Neural thực hiện training, quá trình lan truyền xuôi (forward) sẽ được thực hiện trước, sau đó tiến hành lan truyền ngược (back-propagation) nhắm cập nhật lại trọng số cho mô hình. Đây được gọi là quá trình "học" của mô hình (nền tảng của Trí tuệ nhân tạo)
Quá trình đó diễn ra như sau:
Optimizer memory là lưu lại các giá trị gradient và momentum lúc đó (Vì thường chả có mô hình nào dùng hàm optimizer chỉ sử dụng thuần Gradient Descent cả)
-
Activation Memory
Activation memory chiếm dụng RAM nhiều nhất (gấp 300-400 lần Optimizer memory, còn Model memory thì thôi chắc không cần so sánh nữa  ) ! Vậy nó lưu trữ những gì?
) ! Vậy nó lưu trữ những gì?
Hãy ngước lại lên trên nhìn vô cái gift vẫn đang chạy đều đặn. Đó là quá trình học của mô hình. Vậy nếu Optimizer memory lưu trữ gradient, lưu trữ momemtum thì Activation memory sẽ lưu trữ tất tần tật những gì còn lại. Đó là các giá trị các node, các giá trị trọng số, các cập nhật, ... Nhiều phết nhỉ
2. Thử một số phương pháp
Năng lượng không tự sinh ra cũng không tự mất đi mà chỉ chuyển từ dạng này sang dạng khác hay truyền từ vật này sang vật khác
Định luật bào toàn năng lượng có vẻ không liên quan ở đây, nhưng có 1 tư tưởng mà chúng ta cần để ý: Muốn tăng cái này thì cái khác sẽ giảm. Với vấn đề Out-of-memory này thì : Muốn tối ưu model theo memory thì sẽ phải đánh đối một đại lượng khác. Hãy thử một số cách đánh đổi sau đây.
-
Cung cấp thêm bộ nhớ (đơn giản nhất
 )
)
Thiểu RAM thì mua thêm RAM, cái này đơn giản mà. Chính xác! Nếu bạn không muốn thay đổi mô hình của bạn vì sợ ảnh hưởng lẫn các phần khác, hoặc đơn giản là: bạn có tiền mà, vậy blog này của mình cũng không giúp ích được nhiều rồi  .
.
Vậy với phương pháp này, chúng ta đánh đổi "tiền" lấy RAM.
Tuy nhiên, phương pháp này cũng không phải là là luôn có thể thực hiện nếu bạn có tiền. Hãy xét các trường hợp sau:
- Ví dụ:
- Bạn dùng laptop và laptop của bạn chỉ có thể nâng max được 32 GB RAM, tuy nhiên model của bạn cần 33 GB RAM để chạy được hoàn tất

- Bạn sử dụng Google Colab để train model (vì muốn tận dụng GPU free), tuy nhiên RAM max mà Colab cung cấp cho bạn chỉ có 12 GB thậm chí cả khi bạn tiến hành "switch to a high-RAM runtime" thì bạn cũng chỉ nâng RAM lên được 25.51 GB và model bạn cần 26GB RAM

- Bạn tham gia săn tiền thưởng bằng cách join các challenge trên Kaggle và Kaggle cho bạn max 16GB RAM nếu bạn sử dụng CPU và max 13 GB RAM nếu bạn sử dụng GPU nhưng model của bạn lại quá lớn và cần nhiều RAM hơn thế @@
- Bạn cần phát triển model ứng dụng trên các bo mạch, chip điện tử có RAM cực kì hạn chế ?
- ...
- Bạn dùng laptop và laptop của bạn chỉ có thể nâng max được 32 GB RAM, tuy nhiên model của bạn cần 33 GB RAM để chạy được hoàn tất
Trong tất cả các trường hợp đó, việc mua thêm RAM là bất khả thi và bạn nên kéo xuống dưới để đọc tiếp các phần khác trong blog này 
-
Nén mô hình mạng
Việc nén mô hình của bạn lại nhỏ hơn (Compression model) chắc chắn sẽ giúp đỡ một phần cho bộ nhớ của bạn rồi, đặc biệt là cho model memory.
Kỹ thuật chính được sử dụng ở đây là Pruning: Tiến hành cắt tỉa mạng neural. Việc cắt bỏ ở đây là loại bỏ các kết nối dư thừa (có trọng số xấp xỉ 0).
Một kỹ thuật nén khác là Quantization. Để dễ hình dung, quantization liên quan đến việc kết hợp các trọng số với nhau bằng cách phân cụm chúng hoặc làm tròn chúng để có thể biểu diễn cùng một số lượng liên kết/kết nối nhưng với ít bộ nhớ hơn.
Các bạn có thể đọc thêm các blog tiếng Việt khác về việc nén model tại đây.
Với việc nén model lại, thứ các bạn đánh đổi ở đây là accuracy của mô hình. Nghe không muốn đánh đổi tí nào nhỉ, lại còn là đánh đổi phần memory có vẻ ít nhất nữa chứ. Tuy nhiên việc nén model lại có nhiều công dụng hơn bạn nghĩ, hãy thử đọc bài viết này để hiểu thêm nhá.
-
Small Batch Training
Batch-size là là một siêu tham số (hyper parameter) xác định số lượng mẫu cần xử lý trước khi cập nhật các tham số (parameter) của mô hình. Nhắc lại quá trình "học" của mô hình thì việc cập nhật trọng số có thể thực hiện sau khi tính toán 1 node, hoặc một số node hoặc tất cả các node của input layer. Số lượng node được chọn để cập nhật trọng số chính là batch-size.
- Chúng ta có :
- Batch Gradient Descent. Batch Size = Size of Training Set
- Stochastic Gradient Descent. Batch Size = 1
- Mini-Batch Gradient Descent. 1 < Batch Size < Size of Training Set
Thông thường, với dữ liệu nhỏ, việc chọn bacth size = toàn bộ tập train sẽ cho kết quả cập nhật tốt nhất, tuy nhiên, việc bộ dữ liệu nhỏ là không thể với thời đại của Big Data như này.
Việc chọn batch size nhỏ có thể không là tốt tuyệt đối, tuy nhiên nó lại giúp mô hình tận dụng được khả năng của GPU và tất nhiên : Giảm bộ nhớ cho RAM 
Do đó, một đề xuất cho bạn nếu bạn đang bị tràn RAM khi train mô hình, việc đầu tiên không phải mua RAM hay cắt tỉa mô hình gì cả, hãy thử giảm Batch size của mô hình xuống - so easy. (Batch size thường được chọn có dạng 2^n để fit vừa với RAM)
-
Gradient Checkpointing
Phía trên đã có khá nhiều phương pháp giảm model memory, optimizer memory rồi nhỉ, bây giờ hãy thử một phương pháp cố gắng đi giảm memory lớn nhất: Activation memory.
Dùng lại cái hình này một chút: Đây là mô hình học thông thường - hay nói cách khác là cách cập nhật trọng số của một mô hình
Ok, giờ hãy cố nghĩ ra một cách nào đó, giúp tiết kiệm RAM nhưng vẫn đảm bảo mô hình được cập nhật trọng số một cách chính xác
Tada:
Chắc nhiều người sẽ nghĩ ra được cách như này nhỉ ^^ (Các bạn giỏi ghê). Và vấn đề về RAM đã được giải quyết. Dễ dàng ghê!
Tuy nhiên, vấn đề đánh được đem ra đánh đổi với memory ở đây là thời gian thực hiện train mô hình. Hãy cùng nhìn lại một chút và so sánh giữa 2 phương pháp:
- 2 mô hình:
- Cập nhật bình thường : Yêu cầu về bộ nhớ : O(n), Yêu cầu về số lượng tính toán : O(n)
- Cập nhật tối ưu RAM : Yêu cầu về bộ nhớ : O(1), Yêu cầu về số lượng tính toán : O(n^2)
Để trung hòa 2 mô hình này, chúng ta sử dụng Gradient Checking. Điểu này được hiểu như nào? Chúng ta tiến hành đặt các mốc (checkpoint) trong mô hình. Ví dụ :
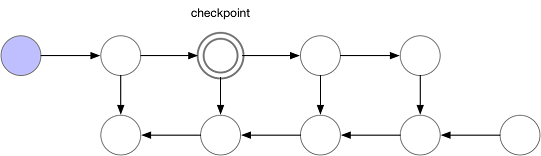
And surprise, hãy xem thử khi đó quá trình cập nhật trọng số sẽ được diễn ra như thế nào
Với phương pháp Gradient Checking, mô hình sẽ chỉ có yêu cầu về bộ nhớ: O(căn n) và yêu cầu về số lượng tính toán: O(n)
-
Online Learning
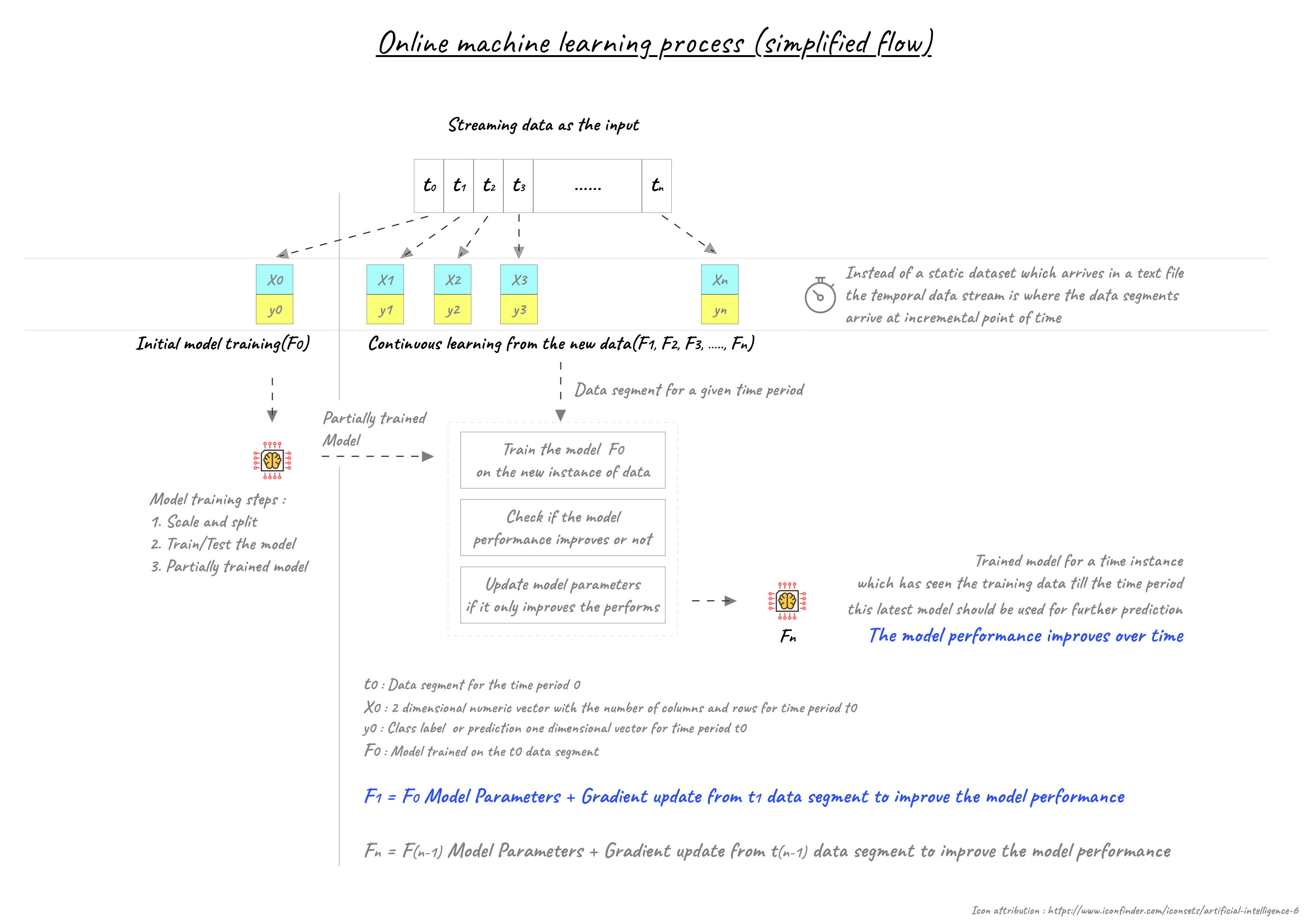
Nếu các bạn không muốn động chạm gì đến model hay cắt tỉa gì cả, hãy thử tiếp cận theo hướng của Online Learning với Data Stream. Nếu các bạn muốn hiểu sâu hơn, hãy đọc các bài viết cụ thể hơn về Online Learning, nhưng về cơ bản, ý tưởng có thể áp dụng để tối ưu RAM ở đây là: Chia nhỏ dữ liệu và train từng phần. Hãy nhìn ảnh bên dưới để rõ hơn quá trình nha:
3. Một số thứ hay ho khác
-
Thay đổi format dữ liệu
Nếu các bạn thấy mớ lí thuyết trên quá lằng nhằng, và các phương pháp quá khó hiểu. Đặc biệt, dữ liệu của bạn là dạng bảng , thì chúc mừng bạn, mình có ở đây một đoạn code có thể giúp ích rất lớn cho bạn.
Với các dữ liệu dạng bảng, việc lưu trữ dữ liệu có thể sử dụng một số kiểu dữ liệu không phù hợp, từ đó gây tốn bộ nhớ, ý tưởng ở đây là xét lại khoảng giá trị của các giá trị trong bảng, rồi fit vào các kiểu dữ liệu nhỏ hơn. Dưới đây là code (nếu không có gì quá đặc biệt trong dataset của bạn, các bạn có thể sử dụng trực tiếp code mà không cần quan tâm gì cả )
import numpy as np
def reduce_mem_usage(df):
""" iterate through all the columns of a dataframe and modify the data type
to reduce memory usage.
"""
start_mem = df.memory_usage().sum() / 1024**2
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum() / 1024**2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
Các bạn có thể đọc chi tiết hơn về ý tưởng phương pháp này thêm tại đây hoặc đây nữa !
-
Data Generator
Về kĩ thật này chắc cũng đã khá quen thuộc với nhiều người rồi, nhưng đây là một kĩ thuật khá hay giúp sử dụng RAM một cách hợp lí.
Đầu tiên cần hình dung Data Generator là làm gì? Khi tiến hành thực hiện train model, thường cách xử lí đơn giản nhất là : Load tất cả dữ liệu, tiến hành tiền xử lí, chia tập train-test-validation và cuối cùng run() và lưu trọng số lại. Một luồng xử lí cực kì clear và dễ hiểu. Tuy nhiên, không phải lúc nào bạn cũng có thể load tất cả data vào RAM của bạn, đặc biệt là khi bạn còn không có đủ RAM nữa, (load tất cả data cũng có thể khiến việc tiền xử lí tất cả dữ liệu 1 lúc diễn ra lâu hơn), đó là lúc cần Data Generator.
Data Generator tiến hành chia từng dữ liệu vào các thư mục con, sau đó, load dữ liệu từng phần trong quá trình train. Các bạn hoàn toàn có thể code một Generator theo ý mình và chắc chắn nó sẽ sử dụng RAM hợp lí theo ý bạn.
Còn nếu bạn lười, thật may cho bạn, Keras đã có sẵn ImageDataGenerator mà bạn có thể sử dụng bất cứ lúc nào (nhớ là dữ liệu dạng ảnh nhá )

Ngoài ra các bạn cũng có thể tìm hiểu thêm về keyword Yield hoặc đọc thêm về các ví dụ custom hàm datagenerator tại đây
4. Kết luận
Blog đợt này có vẻ hơi dài nhỉ . Hi vọng các bạn có thể đủ kiên nhẫn để đọc đến những dòng này.
Trên đây là tất cả những phương pháp mà mình đã từng dùng cũng như đã tìm hiểu được (sau khá nhiều trường hợp đau đầu vì không biết kiếm đâu thêm RAM), hi vọng có thể có 1 vài cái gì đó hữu ích cho trường hợp của các bạn. Hẹn gặp các bạn ở blog tiếp theo 
5. Tài liệu tham khảo
https://arxiv.org/pdf/1904.10631
https://medium.com/analytics-vidhya/data-streams-and-online-machine-learning-in-python-a382e9e8d06a
https://medium.com/tensorflow/fitting-larger-networks-into-memory-583e3c758ff9
https://machinelearningmastery.com/large-data-files-machine-learning/
https://machinelearningmastery.com/how-to-load-large-datasets-from-directories-for-deep-learning-with-keras/
https://pythontips.com/2013/09/29/the-python-yield-keyword-explained/
(và các link tham khảo mình chèn trong bài viết - nhiều link quá )
All rights reserved
