Chuyện anh thợ xây P3: Chuyện cái bộ đếm view
Bài đăng này đã không được cập nhật trong 3 năm
Một hai ba năm anh có đánh rơi nhịp nào không?

Một ngày bạn được giao nhiệm vụ ngồi đếm số như này: Cứ có bao nhiêu lượt vào xem bài viết thì lại tăng cái bộ đếm view thêm 1 đơn vị. Ồ dễ quá ha, chắc ngồi code 5 phút là xong. Sếp sòng gì mà giao cái đề bài dễ đến thằng trẻ con mới học code nó cũng làm được vậy trời?
Một bài toán rất đơn giản nhưng được áp dụng cực kỳ phổ biến trong mọi hệ thống. Nào là đếm view, đếm like, đếm comment, đếm click,... đếm mọi thứ. Tất nhiên mình sẽ bỏ qua vấn đề ghi data raw kiểu 1 click thì nó của user nào vào lúc nào,... vì nó là việc trong phần 2 của series này rồi nhé. Trong bài viết này chúng ta sẽ chỉ quan tâm tới cái bộ đếm và chỉ bộ đếm mà thôi.
Thế nhưng liệu nó có thật sự đơn giản hay không? Chúng ta hãy cùng xem xét.
First things first
Và mình vẫn là Minh Monmen, anh thợ xây lười biếng mấy tháng trời để tập trung làm 1 trong 3 công việc to tát nhất cuộc đời của 1 thằng đàn ông: lấy vợ. Nhưng thôi bỏ qua mấy cái râu ria ấy đi và quay trở lại vấn đề chính của chúng ta nào: cái bộ đếm. Vậy thì cái bộ đếm này nó như thế nào mà được mình nhét hẳn 1 phần riêng biệt vào series Write-heavy application của mình thế?
Trước khi ngụp lặn trong code và số liệu thì hãy điểm lại một chút kiến thức cũ trong series không lại quên:
- P1 - BUILD a write heavy application: Làm quen với ứng dụng write-heavy và những cách sắp xếp code để tăng performance
- P2 - Batch operation và công nghệ bê gạch: Xử lý ứng dụng write-heavy bằng batch operation
Nếu bạn nào chưa đọc 2 phần trên thì hãy trở lại đọc trước đã nhé. Việc nắm được lối tư duy phát triển vấn đề và xử lý vấn đề từ đầu rất quan trọng và giúp các bạn hiểu được những kết quả test của mình và tại sao mình lại test như vậy. Trong bài viết này thì mình sẽ nêu rõ cho các bạn sự khác nhau giữa 2 loại hình dữ liệu sẽ dẫn tới những cách xử lý khác nhau và thiết kế khác nhau như nào.
Ok chưa? Let's go!
Toàn bộ source code của quá trình test được public ở repo này: https://github.com/minhpq331/write-heavy-application
Insert vs update operation
Điều đầu tiên phải nhắc đến ở đây chính là sự khác biệt căn bản giữa 2 operation chúng ta thường dùng hàng ngày là insert và update. Vì chúng ta đang làm việc với write-heavy application, tức là những ứng dụng thiên về write data, do đó những yếu tố ảnh hưởng lớn nhất đến performance của write operation cần được nhắc đến.
Khác biệt về cơ chế hoạt động
Để các bạn có thể hiểu hơn về sự khác biệt giữa 2 operation này (theo hướng performance) thì mình sẽ đề cập thêm 1 chút về cơ chế hoạt động của database (mà cụ thể mình đang xài là Mongodb) theo cách đơn giản nhất có thể nhé.
Đầu tiên là cách mà Mongodb processing 1 query:
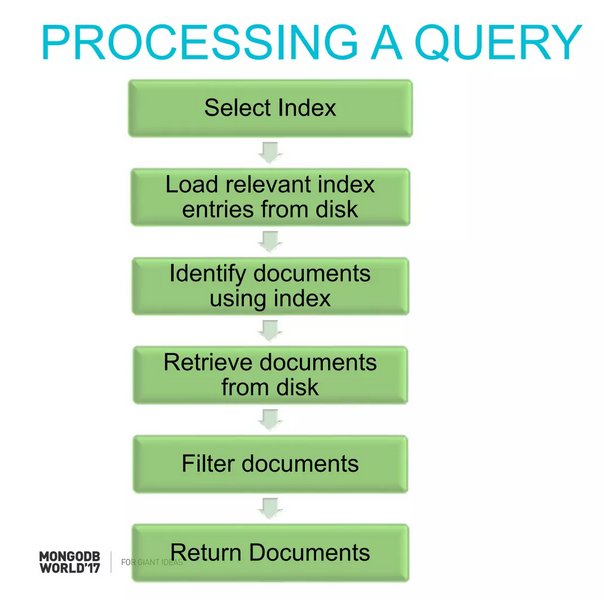
Vậy thì trong 6 bước này, đâu sẽ là bước chậm nhất và ảnh hưởng lớn nhất đến performance? Chúng ta hãy cùng nhớ lại 1 bức ảnh về latency tại các level của 1 phần mềm mình đã đề cập trong bài viết Performance Optimization 105: Database bottleneck - Đuổi bắt kẻ tội đồ:
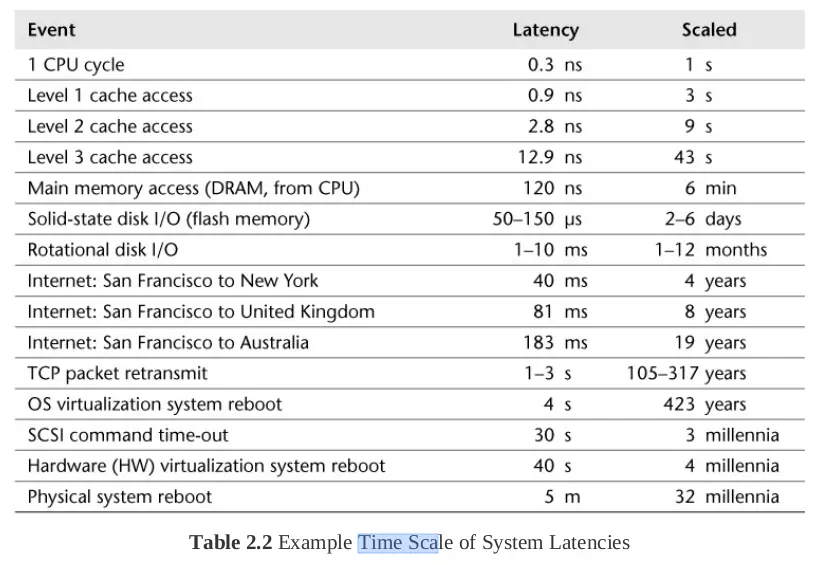
Okay, nếu chúng ta nhìn thấy tại level RAM thì latency vẫn còn tương đối nhỏ (120 nanosecond) thì khi tới level của disk thì latency đã tăng lên tới hàng ngàn lần (SSD ở mức microsecond) thậm chí cả trăm ngàn lần (HDD ở mức milisecond). Đây cũng chính là thứ gây ảnh hưởng nhất tới câu query của chúng ta với database. Trong 6 bước mà mình liệt kê ra ở trên thì những bước sau có (thể) có sự tham gia của việc access disk là:
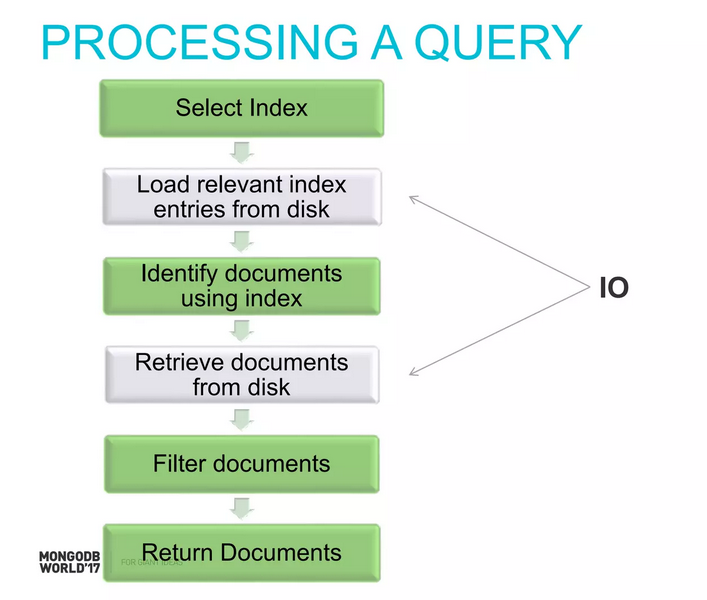
Vậy là có 2 bước có thể cần access disk là load index from disk và load document from disk. Tuy nhiên chúng ta đều biết Mongodb có 1 cơ chế cache trên memory với vùng nhớ được gọi là Working Set. Vùng nhớ này sẽ lưu lại index và những document thường được truy cập (frequently accessed documents). Nếu như RAM của database đủ lớn thì có rất nhiều query không cần sử dụng disk IO trong 2 operation trên. Với hầu hết các database thì khi sizing chúng ta đều cố gắng thiết kế lượng RAM đủ để đảm bảo toàn bộ index có thể nằm trên memory. Còn đâu data size thì rất lớn rồi phải chứa trên disk chứ không thể fit hết trên RAM được. Tức là Working Set (only indexes) < RAM < Data Size.
Nếu các bạn đã có tìm hiểu về cơ chế write operation của MongoDB (mà cụ thể là storage engine WiredTiger) thì sẽ biết là các operation write của chúng ta đều được MongoDB "lưu tạm" vào 1 vùng nhớ trên RAM trước khi định kỳ flush xuống disk. Điều này làm cho chúng ta có thể tạm thời bỏ qua thời gian chờ đợi ghi data xuống disk khi thực hiện write operation (bởi vì bản chất là mình chỉ chờ nó sửa data trong RAM thôi chứ có chờ nó xuống disk đâu). Khi đó thì sự khác biệt rõ rệt nhất về thời gian giữa insert và update document chính là thời gian load document from disk đã được đề cập ở trên.
Thật ra là việc update hay chậm nhất là chỗ các bạn chưa đánh index được cái query tìm kiếm bản ghi phục vụ update, nhưng cái lỗi cơ bản này thì... cơ bản quá, nên mình không nhắc đến nữa nhé. Coi như các bạn đang update đều bằng tìm kiếm primary key đi.
Conflict dữ liệu và cơ chế lock
Oh, một yếu tố khác cũng khá quan trọng cần phải đề cập đến là việc update 1 bản ghi có sẵn chắc chắn sẽ xảy ra việc tranh chấp dữ liệu nếu như có nhiều client cùng muốn update chung 1 bản ghi. Thằng A muốn update bản ghi thành X, thằng B muốn update bản ghi thành Y mà lại cùng lúc đấy thì chắc chắn sẽ phải có cơ chế để sắp xếp thằng A trước B sau, hoặc 1 thằng thành công 1 thằng thất bại,... đúng không? Thông thường các database sẽ xử lý vấn đề tranh chấp này theo hướng locking for update, cụ thể với mongodb mới nhất thì thường là document lock, tức là bản ghi nào đang được update thì sẽ bị khóa. Hồi xưa còn có mấy chế độ kiểu collection lock tức là lock cả bảng luôn cơ nhưng giờ thì ít xài hơn rồi.
Điều này thường không xảy ra với insert data nếu như các bạn không set các ràng buộc dữ liệu đặc biệt.
Vậy thì locking sẽ ảnh hưởng gì đến performance? Tất nhiên là nó làm giảm performance đi kha khá rồi, và chúng ta cũng phải thiết kế query update sao để tránh conflict hết sức có thế, nếu không thì cái query update đó của chúng ta sẽ phải chờ đợi lock hoặc tệ hơn là fail luôn.
Talk is cheap, show me the code!
Ok, không dông dài nữa, chúng ta bắt tay vào code luôn xem nó ra làm sao. Trong 2 bài viết trước thì chúng ta đã hiểu bản chất cái bottleneck của chúng ta thường không phải đến từ DB mà là đến từ code và framework, sau đó chúng ta cũng đã tối ưu được luồng insert bằng cách sử dụng batch operation rồi. Vậy thử tận dụng luôn những kết quả đã có ở bài trước vào đây xem thế nào nhé.
Mình tạo thêm 1 file express-counter.js để phụ trách handle 3 trường hợp đếm dạng sync, async và bulk giống như đã thực hiện ở bài số 2 như sau (source code đầy đủ có thể tìm thấy ở repo: https://github.com/minhpq331/write-heavy-application)
// express-counter.js
const Bulker = require('./bulk');
const counterBulker = new Bulker(
INCREASE_BULK_SIZE,
INCREASE_BULK_TIMEOUT,
async (items) => {
await db.collection('counters').bulkWrite(
items.map((item) => ({
updateOne: {
filter: { _id: Number(item.id) },
update: { $inc: { value: 1 } },
upsert: true,
},
}))
);
}
);
app.post('/increase_sync', async (req, res) => {
const body = req.body;
await db
.collection('counters')
.updateOne({ _id: body.id }, { $inc: { value: 1 } }, { upsert: true });
res.send('Ok');
});
app.post('/increase_async', async (req, res) => {
const body = req.body;
db.collection('counters').updateOne(
{ _id: body.id },
{ $inc: { value: 1 } },
{ upsert: true }
);
res.send('Ok');
});
app.post('/increase_bulk', async (req, res) => {
const body = req.body;
counterBulker.push(body);
res.send('Ok');
});
Đây là script test với k6.io:
import http from 'k6/http';
import { check, sleep } from 'k6';
export default function () {
let res = http.post(
`http://localhost:3000/${__ENV.ENDPOINT}`,
JSON.stringify({
id: Math.floor(Math.random() * 1000),
title: 'My awesome test',
description: 'This is a test',
}),
{ headers: { 'Content-Type': 'application/json' } }
);
check(res, { 'status was 200': (r) => r.status == 200 });
}
Chỗ này các bạn để ý 1 chút cái trường id được mình truyền lên theo dạng random từ 0->999 để giả lập request update được phân bố đều trên 1000 bản ghi có id khác nhau. Tại sao lại phải làm như thế thì mình sẽ giải thích ở phía dưới sau khi có kết quả test.
Ok, chạy test với 3 endpoint (kết hợp với empty POST) trên mình được các kết quả sau:
| No. | Framework | Test | Http time (s) | Additional time (s) | Http RPS | Ops RPS | avg(ms) | min(ms) | max(ms) | p95(ms) | Mongo CPU |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 16 | Express | Empty POST | 26.8 | 3731 | 26.75 | 1.83 | 172.52 | 36.43 | |||
| 17 | Express | Increase Sync | 52.9 | 1891 | 52.82 | 16.2 | 176.84 | 72.11 | 50.00% | ||
| 18 | Express | Increase Async | 38.5 | 11 | 2598 | 2020 | 38.43 | 8.93 | 175.7 | 54.52 | 200.00% |
| 19 | Express | Increase Bulk | 29.1 | 1 | 3442 | 3322 | 29.01 | 1.18 | 118.79 | 44.84 | 22.00% |
Kết quả empty POST này sẽ khác với empty POST ở các bài trước do mình thay đổi post body để giống với request increase (thêm trường id nữa nên sẽ chậm hơn các bài trước 1 chút)
Kết quả này nói lên điều gì?
- Về mặt cảm nhận thì tổng thể thời gian thực thi hết lệnh update thấp hơn thời gian thực thi insert 1 chút. Thời gian này không đáng kể mấy trong bài test với HTTP request và ta có thể lý giải 1 phần là vì câu lệnh update ngắn gọn hơn so với câu lệnh insert nên tiết kiệm được network tới DB.
- Mongo CPU tăng kha khá trong các case
asyncvàbulk(là 2 case mà các command vào DB bị dồn cục) nên việc thực thi đồng thời các câu lệnh update (trong đó có tranh chấp data do trùng ID) sẽ chậm và tốn tài nguyên hơn thực thi insert rất nhiều. Điều này phù hợp với lý thuyết conflict dữ liệu mà mình đã đề cập ở trên. - Bulk operation vẫn đóng vai trò quyết định trong việc giảm tải cho phía code nodejs (chỉ số HTTP RPS vẫn gần đạt so với việc không làm gì ở Empty POST).
Mặc dù kết quả đạt được về mặt tốc độ vẫn rất khả quan, tuy nhiên nếu xem xét tải của Mongo theo CPU thì lại đáng lo ngại. Việc update liên tục vào 1 bản ghi tại 1 thời điểm sẽ là điểm yếu của thiết kế này. Giả sử nếu bạn làm 1 trang báo, và 1 bài báo về phốt của hoa hậu X với diễn viên Y nào đó quá hot và truy cập quá nhiều thì sao?
Giảm số query dựa vào việc gộp chung các update
Với các hệ thống tính counter như thế này thì có 1 điều đặc biệt chúng ta có thể làm để giảm triệt để số query update db với bulkwrite chính là tính trước dữ liệu. Thay vì 3 lần update 1 bản ghi có id là X để cộng 1 view mỗi lần thì chúng ta gộp lại thành 1 query cộng 3 view luôn. Tiện quá phải không? Chỉ mất thêm tý công code như này thôi:
const Bulker = require('./bulk');
const counterReduceBulker = new Bulker(
INCREASE_BULK_SIZE,
INCREASE_BULK_TIMEOUT,
async (items) => {
await db.collection('counters').bulkWrite(
_.toPairs(_.countBy(items, 'id')).map(([id, count]) => ({
updateOne: {
filter: { _id: Number(id) },
update: { $inc: { value: count } },
upsert: true,
},
}))
);
}
);
app.post('/increase_reduce_bulk', async (req, res) => {
const body = req.body;
counterReduceBulker.push(body);
res.send('Ok');
});
Ở đây thì mình xài luôn vài function lodash cho nó tiện, nhưng bản chất là các bạn đếm trước xem trong 1 list item kia có bao nhiêu thằng có id trùng nhau rồi gộp lại trước khi update vào db. Lúc này mình bắt đầu thay đổi cả script test (bằng việc random id từ 0->9 thay vì 0->999) để các bạn thấy rõ sự khác biệt trong 2 case nhé:
import http from 'k6/http';
import { check, sleep } from 'k6';
export default function () {
let res = http.post(
`http://localhost:3000/${__ENV.ENDPOINT}`,
JSON.stringify({
id: Math.floor(Math.random() * 10), // <- Chỉ random id từ 0->10
title: 'My awesome test',
description: 'This is a test',
}),
{ headers: { 'Content-Type': 'application/json' } }
);
check(res, { 'status was 200': (r) => r.status == 200 });
}
Kết quả test đây:
| No. | Framework | Test | Http time (s) | Additional time (s) | Http RPS | Ops RPS | avg(ms) | min(ms) | max(ms) | p95(ms) | Mongo CPU |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 16 | Express | Empty POST | 26.8 | 3731 | 26.75 | 1.83 | 172.52 | 36.43 | |||
| 19 | Express | Increase Bulk | 29.1 | 1 | 3442 | 3322 | 29.01 | 1.18 | 118.79 | 44.84 | 22.00% |
| 20 | Express | Increase Bulk Reduce (1000) | 27.9 | 1 | 3580 | 3460 | 27.88 | 2.59 | 122.21 | 42.18 | 7.00% |
| 21 | Express | Increase Bulk Reduce (10) | 27 | 1 | 3697 | 3571 | 27.01 | 2 | 110.04 | 38.59 | 0.70% |
Việc mình có tính toán trước khi update db đã giảm số query update cần thực hiện do đó cải thiện đáng kể load của database (từ 22% xuống 7%). Và phương pháp này sẽ càng hiệu quả hơn nếu như hệ thống của bạn có pattern tương tác dạng hot-cold, tức là traffic đổ vào 1 số bài viết cực kỳ hot thì việc gộp query đếm càng hiệu quả hơn. Với các hệ thống có traffic dàn trải trên nhiều bài viết, thì chúng ta vẫn phải đối mặt với nhiều query update db và sẽ phải tính toán thêm cho hiệu quả.
TIP tối ưu: Các bạn hoàn toàn có thể tăng bulk size và bulk timeout lên với các case update counter thế này cho phù hợp với việc gộp query update. Khác với insert chờ lâu gây tốn memory của ứng dụng thì update operation hoàn toàn có thể chờ lâu hơn rất nhiều mà không tốn quá nhiều memory (ví dụ các bạn chỉ cần push vào bulker 1 cái id view thôi chẳng hạn). Thêm nữa việc update counter thường không quá critical nên hoàn toàn có thể delay thêm được.
Bonus point: Deadlock và cách phòng tránh trong bài toán counter
Với mongodb thì bulkwrite KHÔNG PHẢI là 1 transaction mà các command trong đó được thực hiện một cách độc lập (có thể có thứ tự hoặc không do mình set khi chạy bulkwrite). Thế nên mặc dù có rất nhiều command đồng thời update 1 row nhưng mình không gặp trường hợp nào update lỗi do lock hoặc bị dính deadlock. Tuy nhiên với các hệ db dạng SQL như MySQL hay PostgreSQL thì lại không như vậy đâu nhé.
Kể cả khi bạn đã tính trước query update trùng giống như mình mới làm ở trên thì cũng vẫn sẽ gặp deadlock đối với trường hợp chạy nhiều instance và dùng 1 transaction để update nhiều bản ghi. Ví dụ có 2 transaction sau được 2 instance A, B cùng chạy đồng thời:
-- Transaction 1
BEGIN;
UPDATE counters SET value = value + 1 where id = 1; -- Đã process
UPDATE counters SET value = value + 4 where id = 2; -- Đã process
UPDATE counters SET value = value + 2 where id = 3; -- Chờ lock
COMMIT;
-- Transaction 2
BEGIN;
UPDATE counters SET value = value + 3 where id = 3; -- Đã process
UPDATE counters SET value = value + 2 where id = 1; -- Chờ lock
UPDATE counters SET value = value + 3 where id = 4;
COMMIT;
Lúc này nếu như transaction 1 đã khóa row có id = 1 rồi và transaction 2 đã khóa row có id = 3 thì sẽ xảy ra deadlock khi 2 thằng cố claim lock row mà thằng còn lại đã khóa (trans 1 sẽ cố claim id = 3 còn trans 2 sẽ cố claim id = 1). Chờ nhau forever dẫn đến 1 transaction sẽ fail (Database như Postgres tự detect deadlock và cho fail).
Một cách khá đơn giản có thể tránh được deadlock trong trường hợp này là sort row trước khi update. Ví dụ như tất cả các transaction đều được sắp xếp theo thứ tự tăng dần của id, vậy thì deadlock sẽ không xảy ra giữa các transaction này nữa (bởi vì sẽ không bao giờ có chuyện 2 transaction khóa row của nhau nữa mà lúc nào cũng sẽ có 1 transaction được thực hiện trước hoàn toàn)
-- Transaction 1
BEGIN;
UPDATE counters SET value = value + 1 WHERE id = 1;
UPDATE counters SET value = value + 4 WHERE id = 2;
UPDATE counters SET value = value + 2 WHERE id = 3;
COMMIT;
-- Transaction 2
BEGIN;
UPDATE counters SET value = value + 3 WHERE id = 1; -- Transaction này sẽ đứng chờ từ đây cho tới khi transaction 1 finish
UPDATE counters SET value = value + 2 WHERE id = 3;
UPDATE counters SET value = value + 3 WHERE id = 4;
COMMIT;
Tổng kết
Một vài key note để các bạn nhớ về bài viết này:
- Để update nhanh thì phần "tìm document" phải nhanh trước đã. Điều kiện update phải được index
- Bulk operation kết hợp với tính toán trước khi update rất hiệu quả với hệ thống có traffic tập trung vào key hot
- Nếu traffic có dạng phân tán, hãy tìm cách delay để giảm số query update
- Luôn đề phòng Deadlock khi thực hiện bulk update nhiều bản ghi
Như các bạn đã thấy, từ đầu series tới giờ mình chưa hề đả động tới kiến trúc gì cao siêu, chưa dùng thêm hệ thống job, worker, caching,... nào để tối ưu ứng dụng write-heavy của mình. Tất cả mới chỉ là optimize lại code và luồng xử lý 1 chút mà thôi. Có rất nhiều bạn khi được giao làm những tác vụ dạng này đã nghe tip nọ tut kia vẽ ra nào là queue, nào cronjob, redis, kafka,... cho những hệ thống thậm chí cả ngày chỉ có vài ba cái update. Thật sự là bị over-engineering kinh khủng. Vẽ ra một hệ thống phức tạp đồng nghĩa với việc sẽ cần nhiều thời gian maintain, nhiều case phải xử lý và nhiều lỗi tiềm ẩn hơn mà các bạn chưa thể nhận ra được.
Qua vài viết này nói riêng và series Write-heavy application này của mình nói chung, hy vọng các bạn đã có 1 cái nhìn khách quan, thực tế với số liệu cụ thể, kiểm chứng được về câu hỏi: Đâu mới là thứ cần tối ưu trong một write-heavy application. Như anh em thấy đấy, database thì còn lâu mới chậm nếu anh em biết dùng đúng cách phải không?
Hãy giữ một hệ thống đơn giản, hiểu sâu và rõ được phần nào mới là phần chậm chạp, phần nào mới là cần tối ưu trước khi làm bất kỳ hệ thống nào bạn nhé.
All rights reserved
