Chuyện anh thợ xây P1: BUILD a write-heavy application
Bài đăng này đã không được cập nhật trong 4 năm
Khi bạn sinh ra đã có máu kiến trúc sư nhưng dòng đời lại xô đẩy làm anh thợ xây quèn.

Đây là câu nói mà mình vẫn thường tự bảo với bản thân khi làm việc tại vị trí của một Solution Architect. Thật ra trong thực tế thì chuyên môn của anh kiến trúc sư và anh thợ xây căn bản là khác nhau, ít khi anh kiến trúc sư làm được việc của anh thợ xây và ngược lại. Nhưng đó là chuyện của ngành xây dựng. Vậy còn ngành IT thì sao? Liệu 2 nghề này nó có khác nhau nhiều tới vậy không? Liệu một anh dev quèn nếu muốn trở thành Solution Architect thì sẽ thế nào?
Solution Architect, Software Architect, System Architect,... mặc dù có những khía cạnh công việc rất khác nhau nhưng cũng cực kỳ dễ gây nhầm lẫn khi công việc của họ có nhiều điểm đan xen nhau. Các bạn có thể nghĩ mình đang bị nhầm lẫn giữa Solution và Technical Architect khi nói muốn trở thành Solution Architect. Nhưng mà mình không nhầm đâu. Mình muốn trở thành Solution Architect, tức là người đưa ra cả giải pháp về business chứ không chỉ là thuần giải pháp công nghệ. Vì vậy công việc của mình sẽ thường xuyên tham gia vào việc định hướng business và tìm giải pháp cho sản phẩm nữa.
~> Anh thợ xây đó phải học rất nhiều thứ. Rất nhiều có nghĩa là phải tìm hiểu rất nhiều khía cạnh của sản phẩm, từ flow của người dùng cho tới business, rồi thiết kế backend ra sao, client tương tác thế nào,... Dù biết là nếu xin vào những công ty lớn có khi chẳng cần học nhiều mảng thế mà chỉ cần tập trung 1 vài thứ là có đất diễn rồi thế nhưng đã trót đi làm công ty nhỏ thì phải tự nhủ bản thân phải cố gắng thôi vì làm gì có người mà role nọ role kia.
Nhưng thôi, hãy dừng chuyện lan man nghề nghiệp và quay trở lại với câu chuyện chính trong bài viết của hôm nay, một câu chuyện thuần túy về công nghệ: BUILD a write-heavy application.
First things first
BUILD a write-heavy application - hay còn gọi là xây dựng (đừng nhầm với thiết kế nhé) những ứng dụng nặng phần ghi dữ liệu - nghe rất đao to búa lớn nhưng chỉ là cái tên hoành tráng cho vui vậy thôi. Chứ thật ra ở vào tầm cỡ nhỏ xíu như mình thì vẫn chưa có cái gì để mà gọi là write-heavy cả. Nó chỉ là những ứng dụng thông thường có lượng write nhiều hơn so với read một chút, hoặc là khi mình cảm thấy ứng dụng của mình nó write chậm quá thì gọi là write-heavy vậy thôi. Các bạn đừng ném đá nhé.
Thật ra sau nhiều năm đi làm thì mình có cảm giác anh em dev có vẻ quen với việc xây dựng các hệ thống read-heavy hơn thì phải. Cũng bởi 1 phần là ứng dụng read-heavy thường gặp nhiều hơn, giải pháp nhiều hơn, hướng dẫn nhiều hơn,... nên cũng quen thuộc hơn. Giờ cứ bảo API read mà chậm 1 phát thì auto nghĩ ngay tới cache chẳng hạn. Còn xây dựng write-heavy thì còn khá lúng túng, nhất là write-heavy nó cũng có khá nhiều usecase phải xem xét cụ thể.
Người ta thường nói: code mà đi trước là code ngu, tức là code mà không thiết kế cẩn thận, không tính toán trước sau từ sớm thì giống như nhắm mắt mà bước đi vậy, dễ vướng bụi rậm với sa xuống cống ngầm lắm. Tuy nhiên hãy thử cùng mình khám phá góc nhìn bottom-up mới lạ này xem sao. Trong chuỗi bài viết này mình sẽ cùng các bạn tìm hiểu về vài cách xây dựng hệ thống write-heavy từ những viên gạch nhỏ nhất chứ không phải từ bản thiết kế. Mình là Minh Monmen, rất hân hạnh đóng vai chàng thợ xây trực tiếp fuho xách vữa và học đòi làm kiến trúc sư trong bài viết này.

Toàn bộ source code dùng để test trong bài viết này đều có trong repo write-heavy-application của mình.
Ngôi nhà với dữ liệu dạng log
Hãy bắt đầu với 1 bài toán rất cơ bản: Logging.
Nghe rất quen thuộc đúng không? Những ứng dụng chứa log là những ứng dụng write gần như nhiều nhất hệ thống. Cũng có nhiều giải pháp cho vấn đề logging rồi, nào là stack ELK, EFK, Graylog,...
Nếu mà đã có nhiều ông lớn làm ngon như vậy rồi, thì chúng ta còn nói chuyện gì ở đây nữa nhỉ? Thật ra cái mình muốn nói ở đây không phải cụ thể là những ứng dụng ghi log, mà là những ứng dụng có data dạng log, tức là dữ liệu dạng append-only (chỉ thêm không sửa), phát sinh từ các action của hệ thống. Những data này mình thường tự lưu bằng những cơ sở dữ liệu quen thuộc (để dễ bề tích hợp với business của mình) chứ không hay lưu vào những hệ thống chuyên log (có thể là chỉ có mình hay làm thế). Vì vậy nên việc đảm bảo ứng dụng chịu được tải thì cũng là vấn đề mà mình phải tự giải quyết.
Một ví dụ điển hình cho hệ thống kiểu này chính là hệ thống event tracking mà gần như công ty nào cũng cần đến. Những giải pháp tracking bên ngoài như Google Analytic, FB Analytic, Mixpanel,... nhiều khi làm chúng ta bị phụ thuộc quá nhiều vào bên thứ ba và rất khó để có thể custom theo nhu cầu cụ thể của mình. Nếu tự làm thì có thể control được nhiều thứ từ raw data, ý nghĩa, sai số,... mà những ứng dụng bên thứ ba khó có thể cover hết được. Hãy thử start bằng 1 hệ thống event tracking đơn giản:
Mô tả chức năng:
- Hệ thống ghi nhận event từ client truyền lên qua HTTP request và lưu trữ vào Database
- Các event có tính chất immutable (không bị sửa hay xóa)
- Event sample:
{
"event_name": "click",
"data": {
"something": "important"
},
"timestamp": 1632404556
}
Okay, thôi bỏ qua mấy cái bài viết thiết kế hệ thống Google Analytic triệu người dùng tỷ event các thứ đi. Hãy bắt đầu với 1 bài toán rất cơ bản như này thôi: Nhận event qua HTTP và lưu nó vào DB.
Nghe giống chiếc API CRUD mà ai cũng làm được đúng không? Nhưng khác với CRUD khi nói tới write heavy các bạn tự nhiên sẽ có 1 cảm giác chậm không hề nhẹ ở DB đúng chứ? Rồi sẽ ngồi research xem DB nào chậm DB nào nhanh các thứ. Nhưng thật may mắn vì hôm nay mình là anh thợ xây, nên thứ mình quan tâm chỉ là gạch với vữa - tức là code ấy. Nếu ở đây mình tạm thời bỏ qua việc chọn kiến trúc, chọn công nghệ, chọn DB,... lằng nhằng mà ốp luôn stack mình hay dùng là Express (Node) + MongoDB thì nó sẽ ra sao nhỉ?
Phiên bản code thiếu nhi
Bỏ qua những tính toán phức tạp, sau 5 phút mình đã có đoạn code thiếu nhi dưới đây:
...
const mongoClient = new MongoClient(MONGO_URI, {
useUnifiedTopology: true,
maxPoolSize: 100,
});
const db = mongoClient.db(MONGO_DB_NAME);
const app = express();
app.use(bodyParser.json());
app.post('/insert_sync', async (req, res) => {
const body = req.body;
await db.collection('logs').insertOne(body);
res.send('Ok');
});
mongoClient.connect((err) => {
if (err) {
console.error(err);
process.exit(1);
}
app.listen(PORT, () => {
console.log(`Application is listening at http://localhost:${PORT}`);
});
});
Game là dễ, đoạn code này đã đáp ứng được tính năng mà mình mong muốn. Ơ mây zing gút chóp. Mình đã xây xong căn nhà đơn sơ vách đất cho các bạn rồi đó. Về cơ bản là chúng ta đã có căn nhà che nắng che mưa rồi.
Code thiếu nhi thì cũng phải kiểm tra đàng hoàng
Tuy nhiên, dù lúc là dev xây nhà có buông thả tới đâu thì bản tính devops cẩn thận của mình cũng bắt mình phải có bước kiểm tra lại đàng hoàng. Thói quen của mình là sẽ mang búa ra đập thử xem nhà có chắc chắn không. Thường thì mình sẽ dùng wrk hoặc apachebench cho các case đơn giản. Tuy nhiên hôm nay mình sẽ phá lệ chạy thử bằng k6.io để test thử nhiều kịch bản cho dễ.
Bài học đầu tiên về benchmark của mình đó là tất cả các kết quả đều là tương đối. Tức là giá trị tuyệt đối của từng kết quả không nói lên nhiều điều vì ở từng điều kiện khác nhau, từng phần cứng khác nhau, từng dữ liệu khác nhau thì kết quả tuyệt đối nó sẽ khác nhau. Do đó việc benchmark chỉ đem lại kết luận khi đặt kết quả chung hệ quy chiếu và so sánh chúng với nhau.
Hãy cùng list ra 1 vài kịch bản test nền tảng để so sánh và lý do mình lựa chọn kịch bản đó:
| No | Name | Detail | Description |
|---|---|---|---|
| 1 | Empty GET | GET / |
Framework overhead |
| 2 | Empty POST | POST / + data |
Client network + server parser overhead |
| 3 | Sync Raw Insert | for + sync insert | Library (mongodb driver) capacity sync |
| 4 | Group Raw Insert | for + sync insert + async 100 | Library capacity mix sync and async |
Trên đây là 4 kịch bản cơ bản được mình sử dụng để làm giá trị base khi so sánh với các bài test xử lý khác nhau của ứng dụng. Tại sao lại có thể ra 4 kịch bản này thì hãy xuất phát từ kiến trúc sau:

Mặc dù kiến trúc này quá là đơn giản đi, tuy nhiên khi có vấn đề phát sinh (ví dụ performance không đáp ứng được yêu cầu) thì cũng cần phải có 1 phương pháp bài bản để xác định đâu mới là root cause. Liệu rằng performance kém là do DB chậm, framework kém, hay là network kém, hay là mình code kém, hay thậm chí là lib kém? Đây là những thứ mà chúng ta phải kiểm tra một cách đàng hoàng.
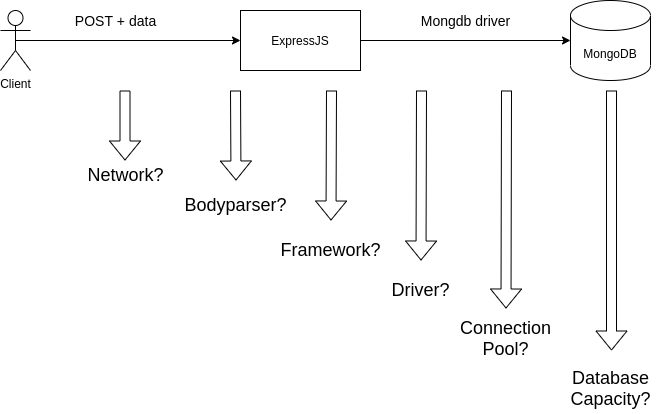
Từ đây các bạn có thể thấy ý nghĩa của các bài test như sau:
- Kịch bản 1 được dùng để xác định Framework overhead, cũng chính là request nhẹ nhất mà framework phải xử lý. Đây sẽ là mức trần tốc độ cho API của bạn. Bạn sẽ không thể trông mong API của mình có tốc độ 6k rps nếu như tốc độ của request empty này chỉ có 5k rps.
- Kịch bản 2 được dùng để xem xét yếu tố client network và khả năng parse request của server. Mình sẽ sử dụng chính data thật để post lên server (nhưng không xử lý gì cả mà response ngay) để xác định giới hạn tối đa mà server có thể xử lý khi nhận cùng lượng data với request thật. Đây là giá trị để mình tối ưu API và hướng đến.
- Kịch bản 3 được dùng để đánh giá khả năng thực hiện command tuần tự của library (mongodb driver) nếu bỏ qua các yếu tố về http framework và client network.
- Kịch bản 4 được dùng để mô phỏng việc có 100 user cùng lúc request tới server (100 cmd đồng thời). Thường dùng trong việc test connection pool với mongodb.
Chi tiết về cách xử lý của 4 kịch bản này có trong file express-insert.js và raw-insert.js nhé. Các bạn có thể tham khảo thêm README.md để biết cách chạy 4 kịch bản test này như thế nào.
Sau khi đã xác định được những kịch bản so sánh rồi, chúng ta bắt tay vào benchmark thử request của chúng ta với k6.io
// ENDPOINT=insert_sync k6 run --vus 100 --iterations 100000 k6_scripts/insert.js
import http from 'k6/http';
import { check, sleep } from 'k6';
export default function () {
let res = http.post(
`http://localhost:3000/${__ENV.ENDPOINT}`,
JSON.stringify({
title: 'My awesome test',
description: 'This is a test',
}),
{ headers: { 'Content-Type': 'application/json' } }
);
check(res, { 'status was 200': (r) => r.status == 200 });
}
Đây là 1 file script test với k6.io, bên trong chỉ định gọi POST http request tới 1 endpoint từ biến môi trường.
Để chạy file này, mình sẽ sử dụng lệnh: ENDPOINT=insert_sync k6 run --vus 100 --iterations 100000 k6_scripts/insert.js. Đây là lệnh tạo 100k request tới server với endpoint /insert_sync và chia làm 100 kết nối đồng thời.
Đây là kết quả thu được từ bài test này và 4 kịch bản trên (tạo 100k request với 100 connection đồng thời)
| No. | Framework | Test | Http time (s) | Additional time (s) | Http RPS | Ops RPS | avg(ms) | min(ms) | max(ms) | p95(ms) | Mongo CPU |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Express | Empty GET | 18.2 | 5498 | 18.14 | 0.28 | 69.61 | 26.91 | |||
| 2 | Express | Empty POST | 24.8 | 4026 | 24.79 | 1.72 | 121.99 | 30.66 | |||
| 3 | Raw | Insert Sync | 38.2 | 2620 | 52.00% | ||||||
| 4 | Raw | Insert Group | 12.1 | 8264 | 135.00% | ||||||
| 5 | Express | Insert Sync | 50.9 | 1962 | 50.9 | 20.14 | 246.78 | 73.77 | 36.00% |
Những con số này nói lên những điều gì? Công sức test của bạn sẽ đổ sông đổ bể khi bạn không thể giải thích những kết quả mà mình nhìn thấy. Tới đây các bạn hãy thử dừng đọc, dùng 5 phút xem kỹ lại các bài test và suy nghĩ xem những kết quả phía trên đây của mình có ý nghĩa gì trước nhé. Đây là 1 cách để luyện tập mindset tối ưu rất hiệu quả đó.
5 phút bắt đầu...
Okay, trong điều kiện ở chiếc laptop asus của mình là:
- Chip i5 2 core 4 thread (có thể tính là tương đương 4vCPU trên cloud)
- 12GB RAM
- SSD Samsung EVO 850 256GB
- 1 process node duy nhất (dùng tối đa 100% x 1vCPU), cả 5 bài test đều full CPU
Thì kết quả thu được khi benchmark bằng k6.io sẽ có ý nghĩa như sau (lưu ý kết quả rps của k6.io thường thấp hơn wrk / ab nên cũng đừng thấy lạ):
- Express trên máy mình xử lý được tối đa 5498 rps (empty GET). ~> Đây là mức trần của 1 instance express. Hay chúng ta còn hay dùng để biết về framework overhead
- Với empty POST có cùng data như bài test, số request giảm xuống chỉ còn 4026 rps ~> 1 phần performance đã tiêu tốn cho network và bodyParser. Đây là mức cao nhất đối với việc xử lý request insert log mà mình hướng đến.
- Bài test số 3 là bài test xử lý insert data một cách tuần tự, hết bản ghi này tới bản ghi khác, do đó ở đây code của mình sẽ chỉ sử dụng đúng 1 connection duy nhất cho việc insert vào mongodb. Tốc độ insert của 1 connection tuần tự với mongo native driver ở đây đo được là 2620 rps.
- Bài test số 4 là bài test mình không chờ xử lý tuần tự toàn bộ mà trigger 100 async command rồi dùng Promise.all để chờ 100 command này hoàn thành mới tiếp tục. Tốc độ xử lý là 8264 rps. ~> Làm như này là mình có thể tận dụng được 100 connection trong connection pool mình đã mở tới mongodb. Thế nhưng thay vì tốc độ tăng lên 100 lần như chúng ta nghĩ (kiểu con đường có 100 làn xe) thì ở đây tốc độ chỉ tăng khoảng 3 lần. Chỗ này thay vì giới hạn của 1 connection thì chúng ta đã chạm tới giới hạn xử lý về CPU của library. Đây là lý do vì sao mặc định mongodb driver chỉ cần mở 5 connection trong pool thôi và việc mở nhiều connection cũng không làm tăng tốc độ xử lý với những request có thời gian xử lý ngắn (kiểu insert) như này. Tăng connection trong pool chỉ có tác dụng khi thời gian chạy 1 request rất lâu.
Đó là những kết luận về RPS. Hãy tiếp tục xem phần Req time (s) là thời gian dùng để hoàn thành insert 100k bản ghi nhé:
- Bài test số 2 có thời gian 24.8s. ~> Tức là thời gian dùng để truyền dữ liệu từ client ~> server và thời gian để parse dữ liệu của framework là 24.8s. Đây là thời gian rất khó thay đổi. Để giảm được thời gian cho quá trình này thường phải giảm kích thước data (khá khó với yêu cầu đẩy dữ liệu lên) hoặc thay đổi framework
- Bài test số 3 và 4 có thời gian tương ứng để xử lý là 38.2s và 12.1s. ~> Đây là thời gian để insert 100k bản ghi vào db, nơi chúng ta có thể rút ngắn được. Tuy nhiên vì rút ngắn thời gian mà đánh đổi sẽ là tài nguyên mà DB tiêu thụ. Các bạn có thể thấy CPU của mongo từ 52% đã tăng lên 130%. Do đó về cơ bản là mình bắt hệ thống chịu tải nặng hơn để giảm thời gian xử lý. Đây là 1 con dao 2 lưỡi.
- Bài test số 5 chính là code của chúng ta. Với việc xử lý tuần tự request và tạo 100 req đồng thời. Tổng thời gian xử lý là 50.9s và trung bình CPU của mongo là 36%. Bài test số 5 này có thể coi là kết hợp của bài test số 2 (upload data) và bài test số 4 (insert group). Tuy nhiên tổng thời gian thực hiện của bài số 5 (50.9s) lại lớn hơn tổng thời gian của bài số 2 (24.8s) và bài số 4 (12.1s). Tại sao vậy?

Giả thuyết về việc không chờ đợi
Các bạn có thể thấy trên kết quả test phần latency của bài test số 5 khá tệ. Điều này cũng khá dễ hiểu khi mặc dù mình luôn chạy 100 request đồng thời tuy nhiên mỗi request phải đợi việc insert vào db xong mới return kết quả và request tiếp theo mới được gửi đến. Ở đây anh thợ xây nông dân là mình đã có suy nghĩ: chạy đồng bộ thì chậm là phải rồi, ta thử tận dụng tính năng tuyệt vời của JS là async xem sao?.

Chắc cũng sẽ nhiều người nghĩ giống mình, chỉ cần có yếu tố write vào hệ thống là sẽ nghĩ ngay tới việc chạy bất đồng bộ, return trước kết quả cho client rồi xử lý sau. Liệu điều này có thật sự cải thiện điều gì không? Chúng ta hãy cùng test thử với đoạn code này:
app.post('/insert_async', async (req, res) => {
const body = req.body;
// await db.collection('logs').insertOne(body);
db.collection('logs').insertOne(body);
res.send('Ok');
});
Ở đây thay vì gọi await thì chúng ta chỉ gọi hàm insert bất đồng bộ, sau đó return ngay cho client và để server tự xử lý nốt. Hãy thử xem kết quả:
| No. | Framework | Test | Http time (s) | Additional time (s) | Http RPS | Ops RPS | avg(ms) | min(ms) | max(ms) | p95(ms) | Mongo CPU |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 | Express | Insert Sync | 50.9 | 1962 | 50.9 | 20.14 | 246.78 | 73.77 | 36.00% | ||
| 6 | Express | Insert Async | 42.3 | 8.5 | 2361 | 1968 | 42.28 | 3.97 | 177.93 | 64.02 | 35.00% |
Ồ, thời gian ghi nhận được ở k6.io cho bài test async này chỉ là 42.3s, chúng ta đã có 1 chút sự cải thiện với tốc độ 2361 rps và latency giảm đáng kể. Thế nhưng cho tới khi k6.io dừng request thì process chạy node vẫn tiếp tục xử lý và full CPU trong khoảng 8.5s nữa (là cột Additional time) rồi mới dừng. Cùng với việc tài nguyên cho mongodb và process node gần như không thay đổi nên lượng công việc mà server phải xử lý là không thay đổi gì.
Từ kết quả này chúng ta có được 1 vài kết luận:
- Chuyển qua async request chỉ giảm được 1 chút latency cho client
- Load của server không khác gì so với trường hợp sync
- Mặc dù request tới và return ngay nhưng tốc độ http request vẫn không thể đạt được như bài test số 2 vì phải chia sẻ CPU cho quá trình insert DB
Ở đây dù mình biết CPU của process node đang là điểm đáng quan ngại nhất, tuy nhiên liệu chúng ta có thể tối ưu code để đạt được chí ít là tốc độ ngang với bài test 2 + 4 hay không? Dù sao nó cũng chỉ có 2 nhiệm vụ là nhận 100k request và insert 100k bản ghi thôi mà? Tại sao chạy đồng thời thì lại lâu hơn chạy riêng biệt?
Hay là chờ đợi 1 chút để xử lý nhanh hơn?
Để kiểm tra giả thuyết tiếp theo về việc chạy đồng thời chậm hơn việc nhận request và insert bản ghi riêng biệt, mình đã dùng tiếp 1 đoạn code sau:
const items = [];
function add(item) {
items.push(item);
if (items.length === 100000) {
let chunk = [];
for (let i = 0; i < items.length; i++) {
await (async function (item) {
chunk.push(db.collection('logs').insertOne(item));
if (i % 100 === 0) {
await Promise.all(chunk);
chunk = [];
}
})(items[i]);
}
}
}
app.post('/insert_group', async (req, res) => {
const body = req.body;
add(body)
res.send('Ok');
});
Đoạn code này làm nhiệm vụ nhận request, insert data vào 1 mảng. Cho tới khi toàn bộ 100k request được thực hiện xong thì bắt đầu chạy insert 100k bản ghi đó vào DB với 100k câu lệnh insert được chạy tuần tự 100 câu một.

Các bạn đừng nhầm đoạn code này với bulkWrite operation nhé. Bulkwrite là 1 command, dùng 1 connection gửi 100 bản ghi, còn ở đây mình đang chạy 100 command, dùng 100 connection và mỗi command 1 bản ghi giống khi bạn handle request bình thường thôi.
Kết quả thu được như sau:
| No. | Framework | Test | Http time (s) | Additional time (s) | Http RPS | Ops RPS | avg(ms) | min(ms) | max(ms) | p95(ms) | Mongo CPU |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | Express | Empty POST | 24.8 | 4026 | 24.79 | 1.72 | 121.99 | 30.66 | |||
| 4 | Raw | Insert Group | 12.1 | 8264 | 135.00% | ||||||
| 6 | Express | Insert Async | 42.3 | 8.5 | 2361 | 1968 | 42.28 | 3.97 | 177.93 | 64.02 | 35.00% |
| 7 | Express | Insert Group | 25.1 | 12.3 | 3982 | 2673 | 25.07 | 1.36 | 102.99 | 31.21 | 135.00% |
Ô kê con dê, các bạn đã thấy giờ kết quả bài test số 7 chính là tổng của 2 bài 2 và 4 rồi. Tốc độ tổng thể (Ops RPS) của bài test này là 2673 rps, nhanh hơn so với 1968 rps của bài số 6. Thay vì nhận request và insert db đồng thời thì ta đã chờ nhận hết request rồi mới tiến hành insert db 1 lượt. Nhờ việc tập trung CPU để xử lý 1 tác vụ mà tốc độ toàn bộ quá trình được cải thiện đáng kể. Đối với process node mà nói khi luôn full CPU thì quá trình càng nhanh thì càng tiết kiệm tài nguyên CPU (nhưng sẽ phải hy sinh 1 ít memory)
Mặc dù vẫn là từng ấy công việc (chưa có giảm bớt chút nào) nhưng chỉ cần sắp đặt khác một chút thì kết quả cũng thay đổi đáng kể đúng không?
Tổng kết
Well, nhiêu đó thôi đã không lại tẩu hỏa nhập ma. Qua bài viết này mình rút ra ba điều:
- Hóa ra DB không hề chậm (chưa tới lúc chậm), code của chúng ta mới chậm
- Làm nhiều việc cùng lúc sẽ không hiệu quả
- Đợi chờ 1 cách đúng đắn không làm chậm quá trình mà còn làm nó nhanh hơn
Bài viết đầu tiên của series tới đây là kết thúc. Nhưng đây mới chỉ là khởi đầu thôi, vì chúng ta chưa có đi tới đâu cả, chỉ là khởi động một chút, tìm hiểu một chút về chính những dòng code mà mình vẫn dùng hàng ngày xem nó có performance ra sao, được cấu tạo bởi những phần nào, mình có thể tác động vào phần nào. Bài viết này cũng là để các bạn làm quen với công cụ test và các kịch bản test performance được dùng trong quá trình tối ưu. Toàn bộ code của bài test có thể tham khảo tại đây: https://github.com/minhpq331/write-heavy-application
Hiện tại kết quả tốt nhất để handle toàn bộ 100k request và insert vào DB mà chúng ta thu được là với thời gian 37.4s (25.1 + 12.3) bằng việc ngồi chờ post toàn bộ 100k request sau đó mới insert lần lượt vào DB. Tuy nhiên đâu phải lúc nào chúng ta cũng ngồi chờ hết toàn bộ request rồi mới xử lý như vậy? Trong bài viết số hai về buffer chúng ta sẽ tiếp tục với câu chuyện xây nhà này, nhưng sẽ cố gắng tối ưu thêm thời gian từng thành phần xem có chỗ nào giảm được tiếp không nhé.
Hẹn gặp lại các bạn trong bài viết sau.
P/S: À phần 2 có luôn đây: Chuyện anh thợ xây P2: batch operation và công nghệ bê gạch
All rights reserved
