Performance Optimization 105: Database bottleneck - Đuổi bắt kẻ tội đồ
Bài đăng này đã không được cập nhật trong 5 năm
Hành trình đuổi bắt giáo sư Moriarty của thế giới bottleneck: database.
Nếu bài viết trước bạn đã được đóng vai chàng thám tử Sherlock Holmes và cùng chàng rong ruổi trên những cung đường truy bắt tội phạm rồi thì ở bài viết này, mình sẽ tiếp tục cùng các bạn theo chân nhân vật phản diện vĩ đại nhất, kẻ thù không đội trời chung của Sherlock Holmes: Giáo sư James Moriarty aka Database bottleneck.
Cuộc chiến không hồi kết này rút cục sẽ ra sao? Liệu mọi chuyện có kết thúc tại thác Reichenback không hay Moriarty sẽ mãi là bóng ma ám ảnh service của chúng ta mãi?

First things first
Tất nhiên, người kể cho các bạn câu chuyện này không ai khác sẽ lại là mình, đốc tờ Minh Watmen (Watson + Monmen). Câu chuyện này sẽ được đăng trên cuốn hồi ký dài kỳ Performance Optimization Guideline của mình, và các bạn hãy đừng quên upvote + clip lại câu chuyện này để rút ra kinh nghiệm cho bản thân và thẩm thấu dần nhé.
Rà lại 1 chút về lịch sử, thì đây đã là câu chuyện thứ 5 trong series này rồi. Đừng quên đọc những câu chuyện trước của mình để có thể hiểu được toàn bộ những gì mình nói nha.
-
Performance Optimization 102: Scalability và câu chuyện về ảo tưởng distributed
-
Performance Optimization 103: Nghệ thuật tìm kiếm bottleneck
-
Performance Optimization 104: Trinh sát ứng dụng với monitoring
-
Performance Optimization 105: Database bottleneck - Đuổi bắt kẻ tội đồ <~ YOU ARE HERE
Câu chuyện này sẽ mô tả về chuyến hành trình truy vết tên tội phạm được mệnh danh: Kẻ giật dây vĩ đại nhất mọi thời đại - Database. Trong trường hợp các bạn chưa biết, thì có tới 96,69% những ứng dụng chúng ta viết ra có liên hệ với 1 loại database nào đó. Và nó cũng chính là kẻ tội đồ thường xuyên làm ứng dụng của chúng ta giật, lag, chậm, chết,...
Do đó nếu giờ ứng dụng của bạn chạy chậm, hãy kiểm tra database trước tiên.
Nếu ứng dụng của bạn hay chết, hãy kiểm tra database trước tiên.
Nếu cần phải làm gì đó để tối ưu ứng dụng của bạn, hãy nghĩ đến database trước tiên.
Bởi vì tội ác của database bottleneck là cực kỳ kinh khủng, mình sẽ không thể nào kể hết lại cho các bạn trong 1 bài viết được. Các bạn sẽ phải tìm hiểu hắn 1 cách lâu dài và có hệ thống, làm sao để hiểu hắn, suy nghĩ như hắn, hiểu được động cơ hành động của hắn,... để có thể giăng lưới bắt hắn.
Ở đây mình sẽ chỉ động 1 chút vào bề nổi của tảng băng chìm này, xen lẫn những lần mà mình cùng bạn mình (Sherlock) chạm mặt hắn.
Đủ kích thích chưa? Bắt đầu nào.
Tam đại tội liên quan tới Database
Nguồn gốc của tội ác
Đầu tiên hãy điểm qua tuổi thơ của hắn 1 chút, về nguyên nhân sâu xa và gốc rễ của mọi tội ác do database bottleneck gây ra: I/O.
Vâng tất nhiên mọi lỗi lầm, mọi rắc rối mà database gây ra cho chúng ta cũng chỉ xoay quanh công việc chính của nó: I/O operation. Tại sao I/O operation lại chậm đến vậy? Chúng ta lại cùng xem chiếc bảng huyền thoại về latency của các loại operation trong cuốn System Performance - Enterprise and the Cloud:
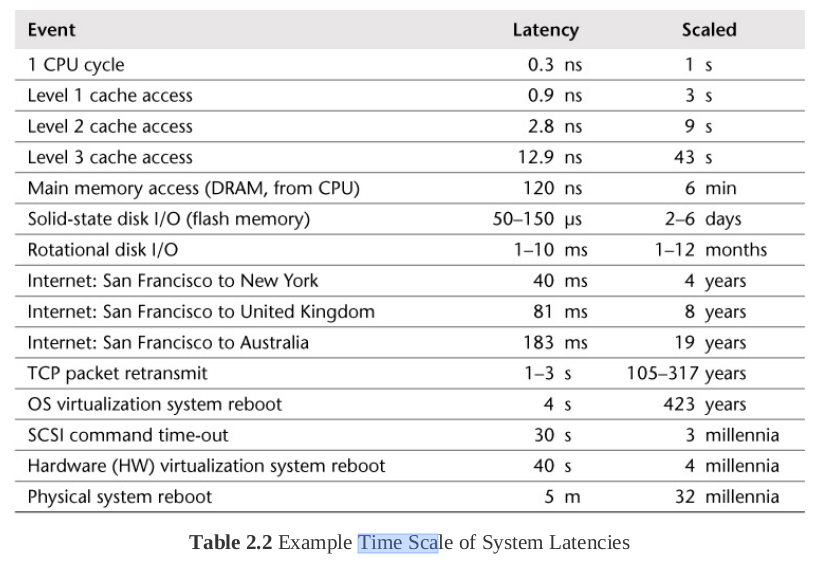
Chắc hẳn là ai cũng đã quen với chiếc bảng này và hiểu thời gian dành cho 1 I/O operation nó lớn như thế nào so với tốc độ tính toán của CPU rồi đúng không? Vậy tức là chúng ta làm sao để operation của chúng ta càng ở những hàng ngang phía trên thì càng tốt.
Vậy so sánh giữa các loại I/O operation thì sao? Hãy cùng xem tiếp chiếc bảng này:

Mặc dù không tới mức hơn nhau cả trăm ngàn tới triệu lần nhưng nó cũng nói lên 1 nguyên tắc đơn giản trong IO là Sequence latency < Random latency. Tuy nhiên tấm hình này mình trưng ra cho vui thôi, tối ưu ở chỗ này thì là các bạn đi quá sâu xuống tầng tối ưu cho database chứ không phải tối ưu ứng dụng sử dụng database nữa rồi. Hãy quay trở lại với tấm hình phía trên và đưa ra kết luận:
Phương pháp tối ưu performance có tầm ảnh hưởng lớn nhất là tối ưu IO operation
Sau khi nắm rõ được nguồn gốc này, chúng ta hãy cùng tới hiện trường vụ án xem sao? Đây sẽ là những action và thao tác cụ thể khi các bạn rơi vào những hoàn cảnh éo le này và cách trả lời câu hỏi khổ sở nhất của anh em: Phải làm gì tiếp theo?
Tội ác đầu tiên: Giết CPU
Đây hiển nhiên là tội ác lớn nhất và cũng là thứ dễ phát hiện ra nhất rồi. High CPU chính là thứ thường xuyên giết chết database của các bạn nhất, mà là chết tới mức sập luôn cơ.
Con đường dẫn đến tội ác này thì sẽ có mấy cái:
- High CPU do phần user busy cao khi CPU phải xử lý nhiều bản ghi, join, count, sum, sorting,...
- High CPU do phần iowait khi query phải tương tác với disk nhiều.
Nguyên nhân thường gặp nhất dẫn đến tình trạng này thì lại là vấn đề mà ai cũng biết là Query thiếu index. Trên mạng cũng cơ man nào là sách vở báo chí blog article nói về chuyện index cho database rồi, vậy mà chẳng hiểu sao các developer của chúng ta vẫn cả tin dễ dụ mà query thiếu index. Mình không chỉ gặp nhiều mà là rất rất nhiều trường hợp người ta query database 1 cách tùy tiện, từ những anh em mới ra trường cho tới những developer lão làng đều có thể dính.
Vậy thì làm sao để tránh? Chỉ có thay đổi mindset của developer thôi. Luôn luôn có 1 mindset về performance khi thao tác với database là bước đầu tiên. Nhưng đừng bị ám ảnh quá là được. Tối ưu cái cần thiết và quan trọng là đủ.
Mặc dù tội ác này rất dễ phát hiện (thông qua monitoring), tuy nhiên nó lại có quá nhiều nguyên nhân, do đó mình sẽ đưa ra luôn 1 vài bước để các bạn truy vết tội ác này:
Xác định loại CPU bị chiếm dụng (user busy, iowait). Bước này cho các bạn cái nhìn sơ bộ về loại query khiến CPU cao.
Nếu là iowait thì hãy nghĩ tới:
- Write query: 1 query có thể nhỏ nhưng số lượng nhiều
- Read query thiếu index: 1 query làm DB phải đọc nhiều bản ghi
- Read query lấy nhiều field lớn: Select * có text field nặng chẳng hạn
Nếu là user busy thì hãy nghĩ tới:
- Count, sum query: Query có chứa count, sum, aggregate function,...
- Sort query, random query: Query chứa sort với điều kiện where rộng, sort random,...
- Transform query: Query biến đổi field, tạo temp field từ các field có sẵn
- Join query: Query có nhiều join
- Read query kiểu scan all: Query filter thiếu index
Xem xét current operation: Bước này thường được làm KHI CPU ĐÃ CAO, tức là khi bạn nhìn thấy có vấn đề xảy ra ấy. Đơn giản là vào database dashboard refresh vài lần list current query bạn cũng có thể nhìn thấy 1 vài query nổi lên. Lúc này có thể thấy ngay 1 vài query đang có thời gian thực thi rất lâu.
Có thể bạn sẽ nhầm lẫn những query nhìn rất bình thường là nạn nhân của kẻ thủ ác thật sự nhưng vì mình đã có hình dung trước về thủ phạm từ tính chất của CPU load ở trên, do đó hãy tập trung tìm các loại query khớp với đặc điểm vừa phân tích.
Kiểm tra slowlog: Bước này làm cả khi có có sự cố (mà bạn không thể phát hiện thông qua current operation), cả trong hoạt động monitor hàng ngày. Để làm điều này thì các bạn phải cấu hình việc ghi slowlog từ trước.
Tùy thuộc vào tính chất của query mà người ta sẽ set level slow phù hợp. Với 1 vài hệ thống web, api mình đã từng làm, thì có thể set thời giam slowlog vào khoảng 50-100ms. Với các hệ thống analytic có query phức tạp và tính toán trên nhiều bản ghi thì mình có thể set slowlog tới 1-3s.
TIPs: Với các hệ thống dev hoặc sản phẩm mới deploy thì các bạn nên set time slowlog nhỏ (5-10ms) để ghi nhận sớm những query có vấn đề bởi các hệ thống mới chạy thường chưa có nhiều data, phải set time slowlog nhỏ thì mới có thể nhìn thấy các query bị slow tiềm ẩn. Còn lên production thì set slowlog nhỏ có thể không cần thiết và giảm hiệu năng của database.
Explain query: Sau khi có 1 số query nghi ngờ rồi, mặc dù các bạn đã có thể nghĩ ngay ra giải pháp để khắc phục nhưng bước explain query sẽ vẫn đóng vai trò trong việc khẳng định nghi ngờ của các bạn là đúng, cũng như giúp các bạn khắc phục đúng chỗ có vấn đề. Thông thường đây là bước để kiểm tra việc sử dụng index thông qua query plan.
Kiểm tra thread: Trong 1 số trường hợp cá biệt, 1 query có thể chiếm toàn bộ CPU của DB và khiến mọi query khác bị chậm lại. Lúc này việc kiểm tra current operation không phản ánh query nào là nặng nhất, thì các bạn sẽ phải viện tới việc soi thread. Ví dụ trong Mysql hay Postgres mình hay dùng lệnh pidstat để kiểm tra thread nào của DB chiếm nhiều CPU nhất, sau đó dùng thread_id để tìm query trong current operation.
Tội ác thứ hai: bóc lột disk IO
Tất nhiên là tội ác này có thể dẫn tới cái đầu tiên. Khi disk IO busy thì CPU bị chiếm dụng bởi iowait sẽ tăng và đó là cái dễ nhìn thấy. Tuy nhiên trong 1 số trường hợp mặc dù CPU utilization khá thấp, nhưng disk IO tới hạn sẽ gây ra high load, latency của query tăng.
Khi gặp trường hợp CPU load cao, disk IOPS cao, thì thứ mà các bạn nên để ý tìm kiếm sẽ là:
- Scan all query: Xảy ra trên các bảng lớn nhiều bản ghi. Dễ phát hiện ra trên slowlog.
- Write query: Xảy ra trên các bảng nhiều index. Thằng này khá khó tìm, vì có thể lẩn tránh được slowlog. Các bạn sẽ phải tự dựa vào các thống kê query insert, update,... để tìm kiếm thằng này.
Chỗ này mình sẽ nói thêm 1 chút là do thời nay hầu hết anh em đều dùng disk của cloud chứ không phải bare-metal, thêm nữa disk iops của cloud lại thường đi theo dung lượng. Ví dụ:
Block storage standard HDD của GCP có tốc độ write 1.5 iops/GB, tức là với 1 instance thông thường 100GB thì tốc độ write sẽ là 150 iops. Nếu instance đó dùng block SSD với 30 iops/GB thì tốc độ sẽ là 3000 iops.
Do đó anh em cũng hết sức để ý để tính thông số iops mà cloud cung cấp nhé. Đừng vì tiết kiệm chọn disk có dung lượng thấp mà tốc độ nghèo nàn quá nhưng cũng đừng mù quáng mà nghĩ rằng query cứ chậm là do disk IO.
Fun fact: Mình đã chạy hệ thống notification (là hệ thống có lượng write nhiều và phức tạp nhất) bằng database mongo với khoảng 10 triệu record được insert/update 1 ngày chỉ với 1 chiếc VM 2 core CPU + block storage 100 GB HDD 150 iops của GCP trong 6 tháng liền. Sau đó mãi mới được đổi sang 100GB SSD đó các bạn ạ =))). Hệ thống này KHÔNG DÙNG CACHE khi read write.
Sad fact: Sau khi dùng thử cloud ssd của gcp, aws, digitalocean, azure thì thằng azure làm mình confuse nhất về tốc độ disk của nó. Mình đã có 1 thời gian khổ sở vì không thể hiểu được tại sao VM tạo trên azure lại có disk chậm tới mức khó tin và làm những việc rất đơn giản dễ dàng trên những thằng khác như cài đặt rancher trở nên khó khăn và lắm lỗi lầm. etcd là một loại database rất nhạy cảm với disk io và khi cài trên azure thì liên tục cảnh báo luôn. Hơi hãi.
Caution!!!: Vài cloud thường đi kèm cho chúng ta 1 cái boot disk khoảng 10-20GB không tính phí, sau đó ta sẽ gắn data disk 100-200GB vô. Nhưng thường cái boot disk này chậm vãi linh hồn, nên các bạn hãy chắc chắn mình cài database lên phần data disk đính kèm thêm chứ đừng nhầm sang boot disk nhé. Mình dính mấy bận do cài package database mặc định nó cài vô các thư mục trong boot disk, xong dùng chậm như rùa luôn.
Disk IO chính là thứ mình thường xuyên theo dõi trong phần monitoring DB. Vì cloud đã cung cấp sẵn cho các bạn thông số tốc độ ổ cứng, do vậy bạn có thể dễ dàng dựa vào biểu đồ IO của disk để xem khi nào thì tốc độ ổ cứng của bạn đã tới hạn.
Vậy khi nó cao hay tới hạn rồi thì làm thế nào?
Kiểm tra lại cách query trước tiên. Hãy để ý tìm kiếm 2 loại query thường gây ra disk IO cao ở trên. Nếu gặp case đơn giản là query quên index thì có thể dễ dàng khắc phục bằng cách thêm index. Tuy nhiên nếu gặp case thứ 2, tức là nhiều query write nhỏ, hoặc query write trên các bảng rất nhiều index thì các bạn phải xem lại design của mình và tìm các giải pháp khác (mà mình sẽ nói qua ở cuối bài).
Nâng cấp ổ cứng với iops cao hơn. Thật ra nói điều này trong 1 series về tối ưu performance thì không đúng lắm. Nhưng trên thực tế thì disk IO thường là phần gây ra bottleneck nhất, và trong nhiều trường hợp thì lựa chọn 1 ổ cứng có tốc độ cao hơn (như chuyển từ HDD sang SSD) là một lựa chọn hợp lý và khắc phục điểm nghẽn hiện tại nhanh hơn nếu việc tối ưu application phải sử dụng những giải pháp phức tạp và tốn thời gian.
Benchmark disk trước khi dùng và khi có vấn đề. Trái ngược với cloud disk, nếu các bạn phải tự quản lý bare-metal disk thì sẽ gặp khá nhiều case disk gặp lỗi và làm iops không đạt con số mong muốn. Trước khi cài đặt database lên những thằng này, hãy chắc chắn disk của nó đúng con số mà chúng ta kỳ vọng và đáp ứng được operation của database. Tool mình hay dùng để kiểm tra tốc độ disk là fio.
Tội ác thứ ba: biến RAM thành bù nhìn
Khác với disk, giá thành của việc sử dụng RAM là cao hơn kha khá. Do đó mình sẽ không tùy tiện bảo các bạn nâng cấp hay đắp thêm RAM giống như chiếc ổ cứng nữa. Hãy cùng tối ưu việc sử dụng RAM thật sự nào!
Đầu tiên mình phải nói những tội ác liên quan đến RAM của database rất khó phát hiện. Nếu các bạn nghĩ chỉ đơn giản là nhìn vào biểu đồ monitor RAM, thấy nó chiếm 50% tức là RAM đang dùng ít và chưa có vấn đề thì là các bạn đã quá ngây thơ rồi. Giáo sư tội ác Moriarty biết cách giấu những tội ác liên quan đến RAM rất hiệu quả và có thể lừa cả những người nhiều kinh nghiệm nhất.
Vậy làm thế nào để các bạn biết database của mình gặp vấn đề về RAM?
Nguyên tắc đơn giản thôi: Capacity planning. Việc planning cho hệ thống giờ thực sự trở thành điểm cốt lõi để nhận ra việc memory của các bạn bị thiếu.
Đầu tiên hãy điểm qua một số công việc cơ bản mà RAM phải làm:
- Cache index
- Bộ nhớ hoạt động cho thao tác tính toán, sort,...
- Chứa các bản ghi kết quả từng query
- Cache active data
- Buffer data trước khi ghi xuống disk
- Buffer cho các connection tới DB ...
Đại khái là RAM sẽ làm rất nhiều thứ. Các bạn có thể đọc thêm về cách cách từng loại DB dùng memory bằng việc search google với cú pháp sau: How <db-name> use memory. Hiểu biết về cách các loại DB dùng RAM là bắt buộc để các bạn tuning config và tối ưu performance khi sử dụng DB đó.
Đầu tiên mình nói đến yếu tố chung nhất, hay gặp nhất mà có impact lớn nhất chính là việc RAM sẽ phải cache lại index trên các table. Các bạn cũng biết index là cuốn mục lục của database, thường được truy cập nhất và cũng gánh vác trọng trách cáng đáng tốc độ của cả database rồi. Vậy thì nếu mà db phải đọc index từ disk thì hậu quả nó sẽ như thế nào. Chính vì vậy mà việc đảm bảo toàn bộ (hoặc phần lớn) index được lưu trên RAM là yêu cầu cơ bản nhất khi lên planning phần cứng cho DB.
Ví dụ với MongoDB:
Default working set (lưu index + active data) trong config của MongoDB là 50% RAM. Nghĩa là với 1 server 16GB RAM thì dung lượng cache khả dụng cho Mongo sẽ là 8GB.
Nếu tổng size index của các bạn vượt quá 8GB thì chỗ thừa sẽ được lưu dưới disk (dù total RAM vẫn thừa 8GB nữa) và... boom!
Các bạn có thể nhìn con số 50% RAM vẫn còn to và sẽ ít gặp trong các môi trường dev, staging - khi các bạn có ít data. Nhưng với việc index vô tội vạ của nhiều anh em thì lên production nó rất nhanh chóng đầy, đây chính là 1 trong những tradeoff của việc tối ưu query bằng index mà các bạn thường bỏ qua. Đánh index hiệu quả và tiết kiệm là từ khóa để xử lý tình huống này.
Một case khác với trường hợp bottleneck về RAM, chính là việc các bạn query sort kết quả nhưng không hiệu quả hoặc filter còn quá nhiều bản ghi, dẫn đến RAM không thể chứa số bản ghi cần xử lý và phải đẩy xuống disk. Đây cũng là điều mà các bạn phải lưu tâm khi tạo ra các index support cho query chứa order.
Tổng kết lại về RAM, anh em hãy tìm hiểu những điều sau:
- Hiểu được cách DB dùng RAM: bao nhiêu % để cache, bao nhiêu % cho index,... Monitor total RAM usage sẽ không phản ánh cụ thể cái này, do đó 50% RAM usage có thể đã là bottleneck, mà 95% RAM usage có thể vẫn là normal.
- Tính được size index: Nằm trong khâu capacity planning để biết RAM từng nào là đủ hay thiếu, index nào là cần thiết và index nào là thừa.
- Hiểu về hot data: Mình có thể dùng rất ít RAM cho những database chứa lượng dữ liệu rất lớn là bởi vì mình định hình được cái gì là hot data và cần RAM bao nhiêu để lưu nó. Ví dụ mình có 1 time-series data dạng hot-cold partition. Mặc dù data có thể lên tới vài trăm triệu record, tổng lượng index cỡ vài chục GB nhưng mình có thể chỉ cần db có 16GB RAM để lưu được index cho hot partition là đủ.
- Hiểu về write buffer: Hiểu rằng thiếu RAM có nghĩa là các operation sẽ cần phải ghi xuống disk sớm hơn và nhanh chóng làm quá tải disk IO.
Đối phó với các vấn đề database
Dưới dây là danh sách tổng hợp những cách ứng phó cơ bản với hội database. Cũng bởi vì tên giáo sư này quá biến hóa, quá khó lường nên các bạn sẽ thấy danh sách này nó hơi lộn xộn 1 chút. Các bạn sẽ phải tự tìm những mảnh ghép phù hợp với hệ thống của mình để có cách giải quyết phù hợp.
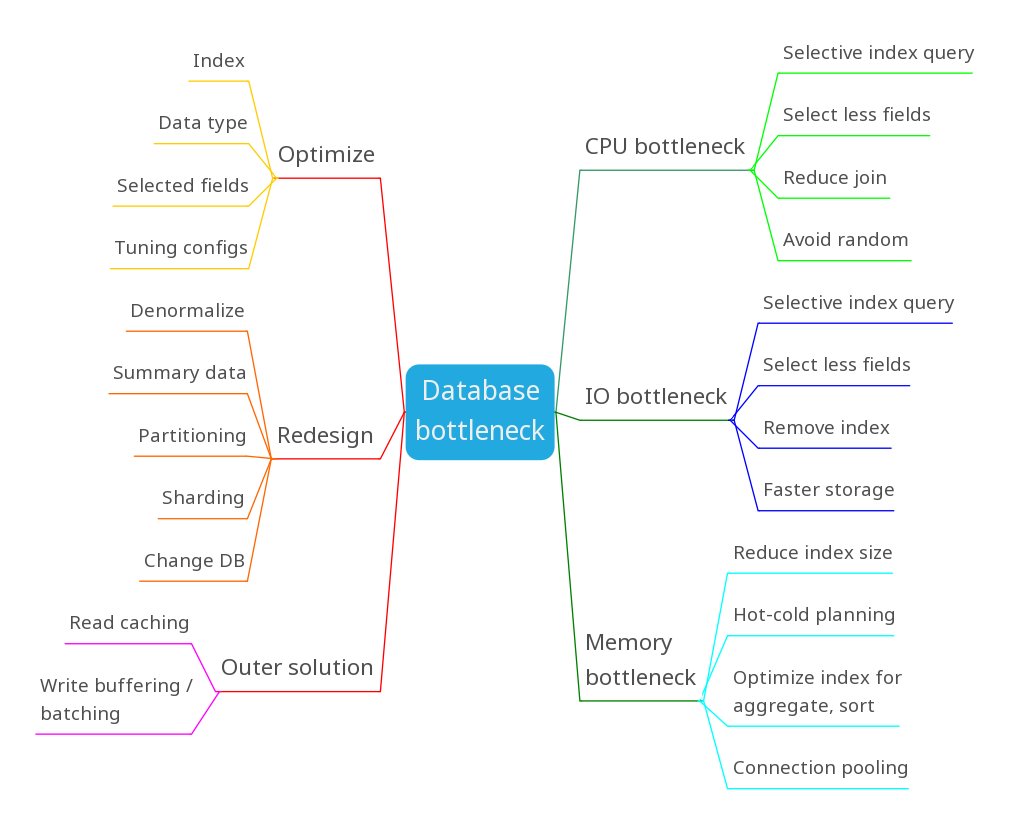
Sơ đồ này gồm 2 nửa, nửa màu xanh bên phải nói về con đường từ triệu chứng tới giải pháp và nửa màu đỏ bên trái là đi từ việc phân loại giải pháp. Nửa màu xanh mình đã đề cập hết ở các phần trên luôn rồi, do đó mình sẽ giải thích thêm 1 chút về nửa màu đỏ nhé:
Trong hệ Optimize những cái đã có sẵn, các bạn sẽ làm được những điều sau:
- Thêm index cho phù hợp với query, giảm index thừa.
- Sửa data type để tiết kiệm bộ nhớ, tiết kiệm io và index hiệu quả hơn.
- Lựa chọn field query cần thiết để tiết kiệm memory, băng thông và io.
- Tuning configs để database dùng hiệu quả phần cứng hơn. (như tối ưu số luồng CPU, dung lượng RAM, buffer size,...)
Đến hệ Redesign lại database thì có những điều sau:
- Denormalize để giảm thiểu join và việc phải đọc nhiều tại các vùng nhớ khác nhau.
- Lưu summary data để hạn chế các query nặng, các query aggregate thường xuyên.
- Partitioning để tách database ra các phân vùng hot-cold (nhưng vẫn trên cùng 1 node)
- Sharding để tách database ra các phân vùng equal trên nhiều db node
- Change database: Đây là giải pháp cuối cùng, khi đã làm hết tất cả mọi thứ tối ưu khác. Choose the right tool to do the right job.
Các giải pháp trong Outer solution là các giải pháp được implement dưới tầng ứng dụng (mặc dù DB cũng tự nó có cache và buffer nhưng mình không nói ở đây). Tức là sẽ dùng các giải pháp bên ngoài DB để cải thiện bottleneck liên quan tới DB:
- Read caching: Giảm số query read db bằng cách cache lại kết quả.
- Write buffering / batching: Giảm số query write db bằng cách tính trước hoặc gom nhóm data.
Trong 2 bài viết tiếp theo mình sẽ đi sâu hơn về 2 phương pháp bên ngoài database này. Còn ở đây sẽ dừng lại ở việc listing nhé.
Tổng kết
Nếu ai đó viết lại toàn bộ những kỹ thuật tối ưu database thì chắc chắn sẽ là những cuốn sách rất dài. Và đúng là có những cuốn sách đang làm điều đó rồi. Do đó trong bài viết ngắn ngủi này, mình sẽ chỉ đưa ra hướng tiếp cận từ mặt thực nghiệm và con đường để các bạn tìm hiểu tiếp mà thôi bởi mỗi loại DB sẽ có những cách tối ưu khác nhau. Điều quan trọng nhất mà bài viết này muốn truyền tải cho bạn chính là:
- Dấu hiệu của vấn đề database?
- Tôi cần nhìn vào đâu để biết điều đó?
- What to do next?
Bài viết đến đây cũng dài, hy vọng rằng các bạn đã có thêm 1 chút kiến thức nào đó để khi gặp các vấn đề về db thì còn có lơ mơ 1 cái hướng xử lý nào đó mà tìm hiểu. Cám ơn các bạn đã đọc tới đây và hãy cổ vũ mình viết tiếp bài viết tiếp theo: Caching optimization - Con đường lắm chông gai bằng việc upvote và clip bài viết này nhé.
Bai.
All rights reserved
