
Scene Text Recognition sử dụng mô hình Transformer
Bài đăng này đã không được cập nhật trong 6 năm
Introduction
Bài toán nhận dạng văn bản với hình dạng bất kì là bài toán có rất nhiều thách thức bởi vì có rất nhiều biến thể trong nó như là hình dạng, kiểu văn bản, màu sắc và hình nền, ... Thuật toán tốt nhất hiện nay điều chỉnh ảnh đầu vào thành một ảnh bình thường, sau đó đưa vào mô hình nhận dạng. Nút thắt cổ chai ở đây là việc điều chỉnh ảnh đầu vào(ví dụ xoay văn bản ban đầu với hình dạng bất kì thành hình dạng thẳng), nếu làm không đủ tốt điều này có thể làm cho mô hình không hiệu quả. Với mô hình mà mình sắp giới thiệu đây sẽ loại bỏ đi phần đấy, và tất cả những gì mà mô hình cần đó là không gian attention. Vì vậy tác giả đã đưa ra một mô hình đơn giản nhưng khá là hiệu quả đó là mô hình nhận dạng văn bản sử dụng mô hình Transformer. Khác với các mô hình Transformer trước đó, chỉ sử dụng mạng decoder của transformer để giải mã convolutional attention. Trong mô hình này, tác giả sủ dụng mạng CNN để trích xuất ra feature maps được thay thế như là một lớp word embedding trong mô hình transformer. Điều này có thể làm cơ chế mô hình transformer sử dụng tối đa sức mạnh của attention.
Trước khi đi vào mô hình này, mình khuyên bạn đọc nên tìm hiểu qua về mô hình transformer, vì để hiểu được bài viết này thì bạn đọc phải hiểu được cơ chế hoạt động của mô hình transformer  . Bạn đọc quan tâm có thể xem bài viết về transformer rất hay ở đây của tác giả Nguyễn Việt Anh.
. Bạn đọc quan tâm có thể xem bài viết về transformer rất hay ở đây của tác giả Nguyễn Việt Anh.
Model
Mô hình sẽ gồm 2 phần chính là trích xuất đặc trưng và mô hình transformer.
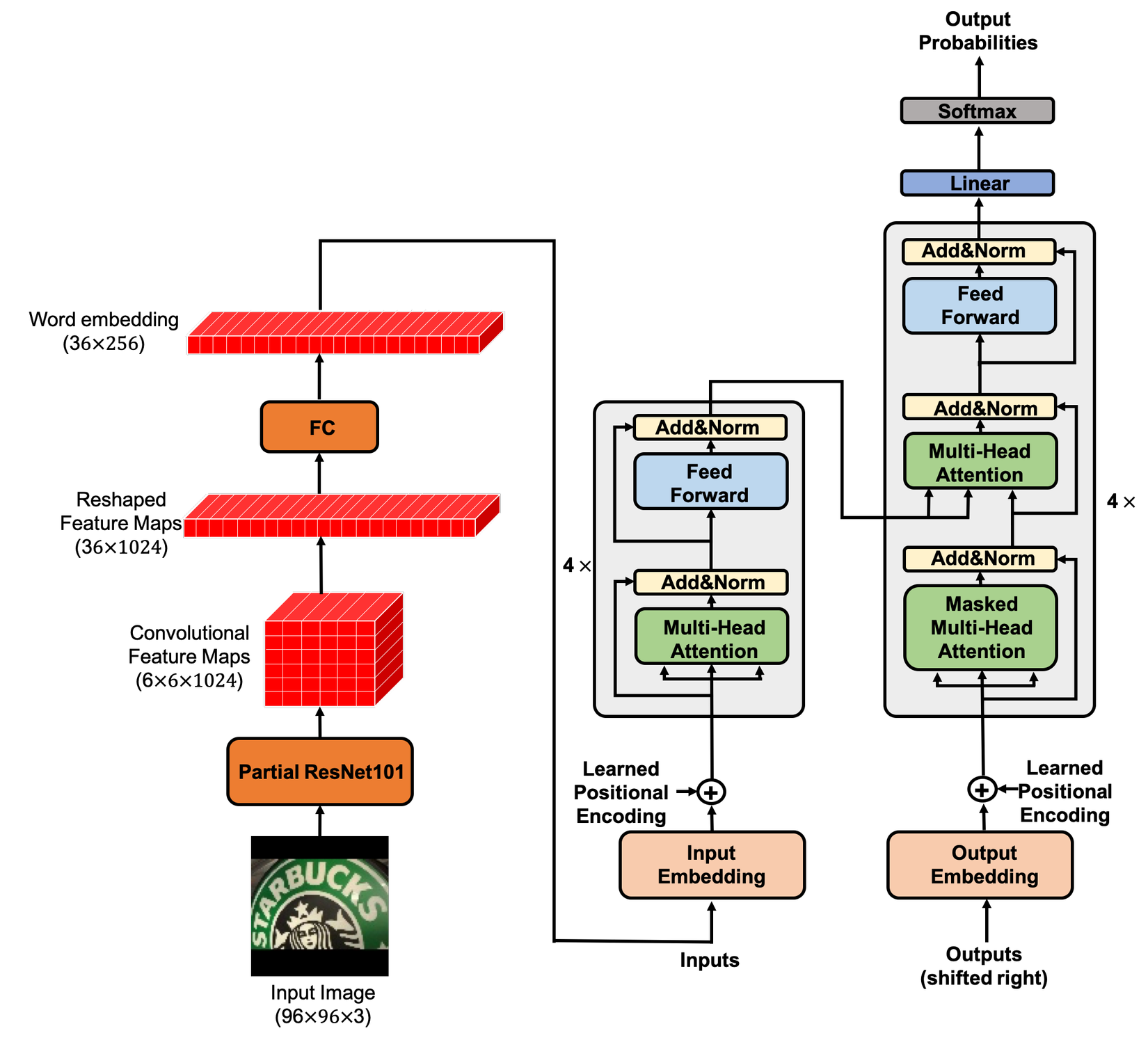
Hình 1: Mô hình Scene Text Recognition via Transformer
Trong mô hình này, tác giả sử dụng kết quả đầu ra của phần thứ 1 thay thế word embedding của transformer và cho vào mạng encoder.Mình sẽ đi sâu vào từng phần :
Feature Extractor Module
Mô hình sử dụng một số lớp CNN để trích xuất đặc trưng, cụ thể tác giả đã sử một 4 lớp đầu tiên của mạng ResNet-101. Mô hình được biểu diễn dưới hình sau:
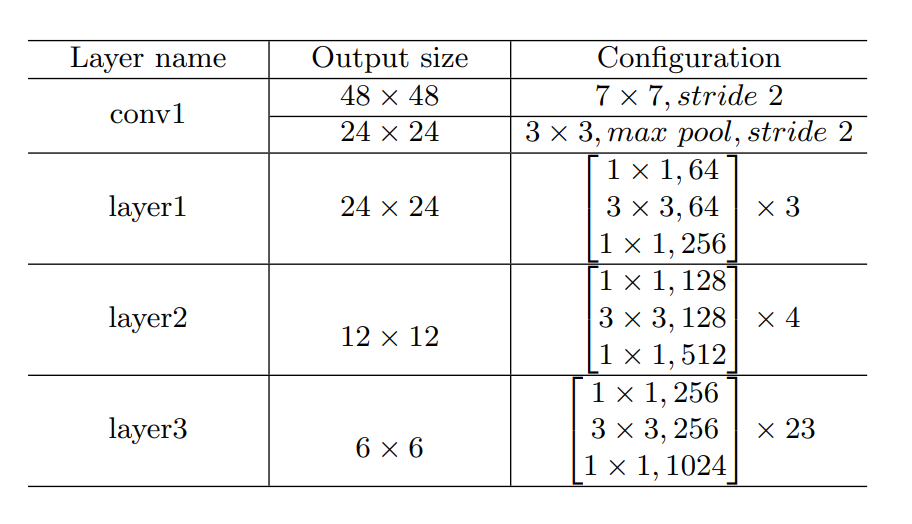
Hình 2: Trích xuất dữ liệu từ 4 lớp đầu tiên của Resnet-101
Để đưa vào mô hình transformer dữ liệu được trích xuất có số chiều là 2 bởi Feature Extractor xuống 1 chiều. Việc làm này có thể sẽ làm mất đi không gian dữ liệu dừ ảnh ban đầu nhưng may thay, mô hình transformer có thể học được tốt từ không gian dữ liệu này.
Để hiểu rõ hơn về cách hoạt động cũng như để dễ dàng hơn trong việc cài đặt mô hình này, mình sẽ nói sơ qua những sự biến đổi này như sau : Nhận ảnh đầu vào là ảnh RGB với kích thước được resize về 96 x 96, sau đó đưa qua mạng ResNet-101 ( để xem sự thay đổi dữ liệu qua từng lớp bạn đọc xem hình 2 ). Đầu ra sẽ là dữ liệu có kích thước 6x6x1024. Sau đó ta đưa về một ma trận có kích thước 36x1024, rồi ta đưa qua một lớp kết nối đầy đủ( Fully connection layer) để chuyển đổi kích thước dữ liệu thành 1 tensor có kích thước 36x256. Cuối cùng, đưa nó vào của mô hình Encoder trong Transformer.
Transformer Module
Mô hình Transformer ra đời là một bước đột phá mới trong thế giới NLP (Natural language processing). Với cơ chế tận dụng tối đa sức mạnh của attention, Transformer đã vượt xa các mô hình RNN dựa trên attention. Khác với mô hình RNN với attention, Transformer đã tận dụng tối đa ngữ nghĩa của tất cả các từ trong câu, từ đó giúp mô hình hiệu quả hơn.Mô hình Transformer có cấu trúc gồm 2 phần đó là Encoder và Decoder:
Encoder
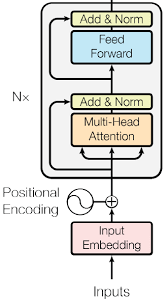
Hình 3: mô hình Encoder trong Transformer
Trong mô hình này, Encoder có cấu trúc gồm 4 lớp giống nhau, mỗi lớp sẽ có 2 sub-layers. Sub-layer thứ nhất có một cơ chế multi-head self-attention(để hiểu rõ về multy-head self-attention bạn đọc vào bài viết mình giới thiệu ở đầu bài nhé), sub-layer thứ hai là một mạng kết nối đầy đủ feed-forward.
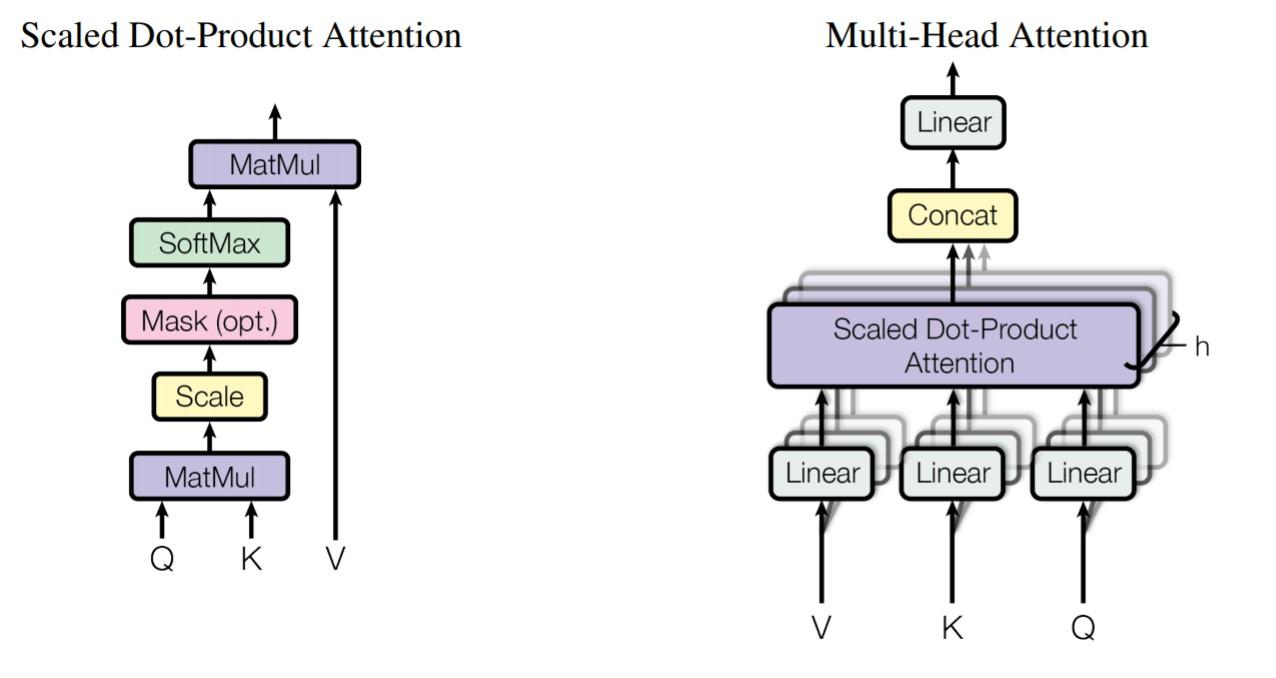
Hình 4: Multi-head self-attention
Decoder
Decoder cũng có cấu trúc gồm 4 lớp giống nhau. Bên cạnh 2 sub-layer trong mỗi lớp của Encoder thì Decoder thêm vào đó là một sub-layer khác, để thực hiện multi-head attention có sự góp mặt đầu ra của Encoder. Cả Encoder và Decoder đều sử dụng Residual block , skip connections trong Transformers cho phép thông tin đi qua sub-layer trực tiếp. Thông tin này được cộng với attention của nó và sau đó thực hiện Normalization.
Mô hình Transformer không chứa các lớp Recurrent và Convolution, nó cộng thêm Position Encodings sau khi qua lớp Embedding, do đó Position Encodings này phải có số chiều giống đầu ra của lớp Embedding.
Result
Thật ngạc nhiên khi kết quả của mô hình này vượt xa các mô hình state-of-art trước đó, sau đây là hình ảnh mình lấy từ paper gốc, họ so sánh giữa là paper có độ chính xác tốt nhất hiện nay với các dataset khác nhau:
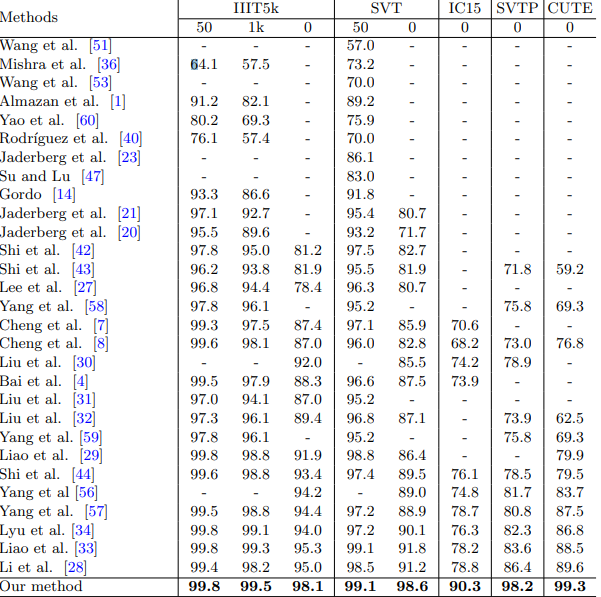
Hình 5: Kết quả so sánh giữa các mô hình và với các dataset khác nhau.
Conclusions
Trong quá trình tìm hiểu về các mô hình nhận dạng văn bản, mình đã đọc bài báo này, thấy rất hay và muốn chia sẻ tới các bạn. Trong quá trình viết còn nhiều điều sai sót mong các bạn góp ý để mình có thể hoàn thiện bài viết tốt hơn.
Nếu bạn nào muốn hiểu thêm về code và muốn implement lại mô hình này , bạn có thể tham khảo code tại đây.Chúc các bạn thành công 
Notes
Các từ mình ghi đậm là các keyword trong mô hình Transformer, nên điều này có thể sẽ khó hiểu nếu bạn đọc chưa tìm hiểu về mô hình Transformer. Vì vậy, mình khuyến khích các bạn tìm hiểu thêm về mô hình Transformer trước khi xem bài viết này nhé. Link bài viết mình đã để trên phần Introduction.
Reference
All rights reserved
