[Apache Kafka] Kiến trúc consumer retry trong Apache Kafka
Bài đăng này đã không được cập nhật trong 4 năm
Trong bài viết này, tôi muốn giải thích các vấn đề có thể gặp phải trong quá trình xử lý message của Kafka và cách đối phó. Trước khi đi xa hơn, kiến thức căn bản về Kafka là cần thiết.
Căn bản về Apache Kafka
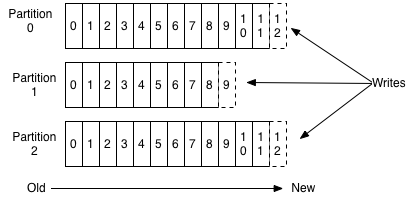
Apache Kafka là platform streaming phân tán nổi tiếng. Nó được dùng để xây dựng các pipeline dữ liệu real-time, nhưng bởi tính persistence (bền bỉ) của các topic, nó cũng có thể sử dụng như kho lưu trữ streaming message để xử lý dữ liệu lịch sử. Để có thể cải thiện tính mở rộng (scalability), topic của Kakka bao gồm các partition (phân vùng). Đi vào chi tiết hơn, một partition đại diện cho một file chỉ-có-thêm vào (append-only). Sử dụng một cấu trúc dữ liệu đơn giản nên throughput (thông lượng) rất cao. Cấu trúc bên trong topic cũng có ý nghĩa rất quan trọng — chúng ta chỉ có thể consume các message từ một topic partition từng cái một (one by one) theo thứ tự.
Cấu trúc thứ tự (sequential anatomy) của một topic partition được trình bày như hình dưới:
Các vấn đề khi xử lý message
Sự hiện thực hóa (implementation) của một consumer — xử lý message ngay lập tức ngay khi nhận từ Kafka topic rất đơn giản (straightforward). Không may thay, hiện thực cực kỳ phức tạp mà xử lý message có thể thất bại (fail) bới vì nhiều lý do khác nhau. Một số trong đó là các vấn đề thương xuyên (permanent problems), như lỗi về ràng buộc cơ sở dữ liệu (failure on the database constraint) hoặc định dạng message không hợp lệ. Một số khác, như tính tạm thời không có sẵn (temporary unavailability) của hệ thống phụ thuộc (dependent system) liên quan tới xử lý (handling) message, có thể được giải quyết (resolved) trong tương lai. Trong những trường hợp đó, thử lại (retry) quá trình xử lý message có thể là giải pháp hiệu quả (valid solution).
Logic retry căn bản
Cách căn bản nhất (simplest form), chúng ta có thể retry xử lý message vô thời hạn (indefinitely) với một số delay cố định giữa các lần retry tiếp theo (subsequent retries). Pseudo-code ví dụ của consumer có thể giống như sau:
Logic retry non-blockingTrong các hệ thống streaming, như Kafka, chúng ta không thể skip các message và quay lại xử lý chúng sau. Một khi chúng ta dịch pointer (con trỏ), còn được gọi là offset trong Kafka, của message hiện tại chúng ta không thể trở lại. Để cho đơn giản, cho rằng offset của consumer được ghi nhớ chỉ sau khi xử lý hiện tại thành công. Trong trường hợp này chúng ta không thể lấy message tiếp theo trừ khi xử lý hiện tại thành công. Nếu xử lý một message bị lỗi liên tục, nó sẽ ngăn hệ thống xử lý các message tiếp theo. Hiển nhiên chúng ta muốn tránh những kịch bản (scenario) như vậy bởi vì sự thất bại của việc xử lý message không có nghĩa message sau cũng vậy. Hơn nữa, sau một thời gian dài, ví dụ 1 giờ, quá trình message lỗi có thể thành công bởi những lý do khác nhau. Một trong số đó là khi hệ thống mà chúng ta phụ thuộc vào, đã hoạt động trở lại. Chúng ta phải làm sao để cải thiện sự hiện thực ngờ nghệch (naive) này? Khi xử lý message lỗi, ta có thể publish một copy của message vào một topic khác và đợi message tiếp sau. Gọi topic mới này là ‘retry_topic’. Cosumer của ‘retry_topic’ sẽ nhận message từ Kafka và sẽ đợi thới thiểm điểm xác định (predefined time), ví dụ 1 giờ, trước khi xử lý message. Các này, ta có thể trì hoãn nỗ lực xử lý message mà hề có bất kỳ tác động tới consumer của ‘main_topic’. Nếu quá trình trong consumer của ‘retry_topic’ lỗi, ta chỉ cần từ bỏ và lưu message vào ‘failed_topic’ cho các xử lý thủ công sau này về vấn đề này. Code cosumer của ‘main_topic’ có thể giống như sau:
Và code của consumer ‘retry_topic’: Logic retry non-blocking linh hoạtCác tiếp cận nêu trên có thể ổn, tuy nhiên vẫn còn một số điểm cần cải thiện. Hệ thống ta phụ thuộc vào có thể ngưng hoạt động lâu hơn chúng ta dự đoán. Để giải quyết vấn đề này, ta nên thử lại nhiều lần trước khi quyết định bỏ cuộc. Để tránh flooding (làm tràn) hệ thống ngoài (external system) hoặc lạm dụng (overusing) CPU bởi vì logic retry, ta có thể tăng khoảng thời gian (the interval) cho những lần thử tiếp theo. Cải thiện logic nào!
Cho rằng ta muốn áp dụng chiến lược retry sau:
- Mỗi 5 phút — 2 lần
- Sau đó 30 phút — 3 lần
- Sau đó 1 giờ — chỉ một lần duy nhất
- Sau đó bỏ qua message
Ta có thể trình bày nó theo thứ tự các giá trị: 5m, 5m, 30m, 30m, 30m, 1h. Cũng có nghĩa rằng ta sẽ thử lại tối đa 6 lần, bới vì chuỗi có 6 thành phần.
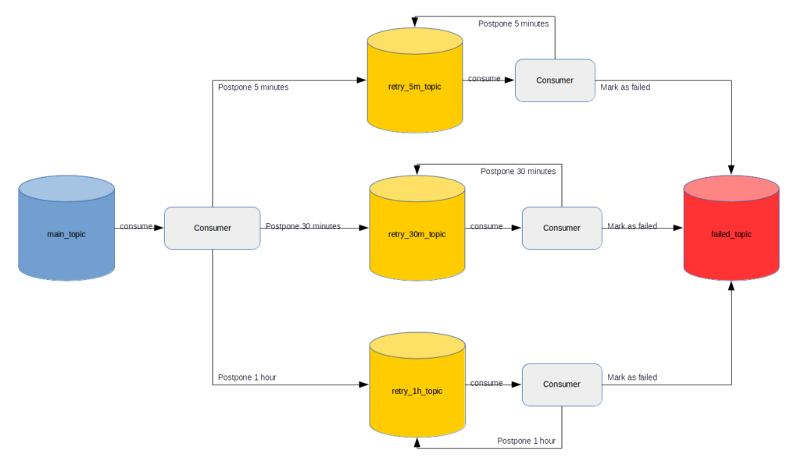
Giờ ta tạo thêm 3 topic riêng biệt cho logic xử lý retry, mỗi topic có một giá trị delay:
- ‘retry_5m_topic’ — dành cho thử lại sau 5 phút
- ‘retry_30m_topic’ — dành cho thử lại sau 30 phút
- ‘retry_1h_topic’ — dành cho thử lại sau 1 giờ Thuật toán điều hướng message tương tự như cách tiếp cận trước. Nó chỉ mở rộng thêm từ 1 thành 3 giá trị delay và cho phép thử lại với số lần định nghĩa trước.
Cùng xem xét scenario sau. Khi một message mới được ghi vào topic ‘main_topic’. Nếu quá trình message này lỗi, chúng ta thử lại một lần sau 5 phút, vì 5m là giá trị đầu trong Chuỗi Thử lại (Retries Sequence). Làm sao làm được vậy? Chúng ta nên tạo một message mới tới ‘retry_5m_topic’ bao gồm message cũ và thêm 2 fields mới:
- ‘retry_number’ với giá trị 1
- ‘retry_timestamp’ với giá trị bằng phép toán hiện tại + 5 phút
Điều này có nghĩa rằng consumer ‘main_topic’ giao trách nhiệm của lỗi quá trình message cho thành phần (component) khác. Consumer ‘main_topic’ sẽ không bị nghẽn (blocked) và có thể tiếp nhận message tiếp theo. Consumer ‘retry_5m_topic’ sẽ nhận message tạo ra (published) bởi consumer ‘main_topic’ ngay lập tức. Nó sẽ đọc giá trị ‘retry_timestamp’ từ message và đợi tới khoảnh khắc (moment) đó, ngừng thread lại. Sau khi thread thức dậy, nó sẽ cố xử lý message một lần nữa. Nếu thành công, ta có thể xử lý message có sẵn (available) tiếp theo. Nếu không thì ta sẽ thử một lần nữa vì Retries Sequence có 6 thành phần và lần thử lại này là lần đầu tiên. Việc ta phải làm là sao chép (clone) lại message, tăng giá trị ‘attempt_number’ (sẽ là 2) và đặt ‘retry_timestamp’ giá trị bằng hiện tại + 5 phút (bởi vì giá trị thứ 2 trong Retries Sequence là 5m). Message đã sao chép sẽ được published vào ‘retry_5m_topic‘ một lần nữa. Bạn có thể để ý rằng mỗi thất bại của xử lý message, phiên bản sao chép của message sẽ được định hướng (routed) thới một trong các topic ‘retry_5m_topic’, ‘retry_30m_topic’ hoặc ‘retry_1h_topic’. Điều quan trọng là không được lẫn các message vào một topic với giá trị thuộc tính ‘retry_timestamp’ được tính toán khác về giá trị delay.
Nếu ta đạt tới thành phần cuối cùng trong Retries Sequence, nghĩa là nó là lần thử cuối cùng. Giờ là lúc phải nói “dừng lại”. Chúng ta sẽ ghi message tới ‘failed_topic’ và coi message này là chưa được xử lý. Ai đó sẽ phải xử lý nó thủ công hoặc ta cứ quên nó đi.
Bức ảnh bên dưới có thể giúp bạn hiểu về flow của message:
Tổng kết
Như bạn có thể đã chú ý, phần hiện thực của trì hoàn xử lý message trong một số trường hợp thất bại, không phải thứ tầm thường để làm. Luôn ghi nhớ rằng:
- Các message chỉ có thể được consume từ các topic partitions theo thử tự
- Không thể bỏ qua và quay lại sau được
- Nếu bạn muốn trì hoãn một số message, bạn có thể publish lại vào các topics riêng rẽ. Mỗi cái với một giá trị delay khác nhau.
- Xử lý message thật bại có thể đạt được bằng cách clone message và publish nó và một trong các retry topic với thông tin được update về số lần thực hiện và mốc thời gian retry tiếp theo
- Các consumer của các retry topic nên ngừng thread cho đến khi chạm mốc thời gian xử lý message
- Message trong các retry topic sẽ được sắp xếp một cách tự nhiên theo thứ tự tăng tiến (chronological order), sắp xếp bởi field ‘retry_timestamp’.
Nguồn: https://blog.pragmatists.com/retrying-consumer-architecture-in-the-apache-kafka-939ac4cb851a
All rights reserved
