Hàng đợi thông điệp Apache Kafka
Bài đăng này đã không được cập nhật trong 4 năm
Hôm nay tạm gác lại mấy chủ đề liên quan đến NoSQL, mình sẽ viết về một thứ khá hay ho, đó là hàng đợi thông điệp phân tán
Khái niệm
Hệ thống hàng đợi thông điệp là hệ thống xử lý dữ liệu động bao gồm các thành phần được kết nối với nhau và làm việc chung theo một chuỗi xử lý hướng tới một trạng thái cuối cùng mà người dùng mong muốn. Dữ liệu động có thể xuất phát từ nhiều nguồn phát sinh như log, dữ liệu sự kiện… Một số hệ thống hàng đợi xử lý luồng dữ liệu liên tục và ghi vào hệ thống dữ liệu tĩnh để thực hiện lưu trữ.
Mô hình triển khai
Hàng đợi thông điệp có thể được triển khai theo mô hình phân tán, phân chia và đồng bộ được thiết kế để đảm bảo việc xử lý dữ liệu lớn khi đọc ghi dữ liệu, giảm độ trễ trong quá trình truyền tải dữ kiệu.
Apache Kafka
Apache Kafka là hệ thống truyền thông điệp phân tán, độ tin cậy cao, dễ dàng mở rộng và có thông lượng cao. Kafka cung cấp cơ chế offset (có thể hiểu như tương tự như chỉ số của một mảng) để lấy thông điệp một cách linh hoạt, cho phép các ứng dụng xử lý có thể xử lý lại dữ liệu nếu việc xử lý trước đó bị lỗi. Ngoài ra, cơ chế “đăng kí” theo dõi cho phép việc lấy thông điệp ra gần như tức thời ngay khi dữ liệu đi vào hàng đợi. Kafka được thiết kế hỗ trợ tốt cho việc thu thập dữ liệu thời gian thực. Apache Kafka là hệ thống lưu trữ thông điệp được phát triển tại LinkedIn. Kafka có những đặc điểm sau đây :
- Tốc độ nhanh: Với một máy đơn cài đặt Kafka có thể xử lý số lượng dữ liệu từ việc đọc và ghi lên tới hàng trăm megabyte trong một giây từ hàng ngàn máy khách.
- Khả năng mở rộng: Kafka được thiết kế cho phép dễ dàng được mở rộng và trong suốt với người dùng (nghĩa là không có thời gian chết – ngừng hoạt động trong khi thêm một nút máy chủ mới vào cụm). Khi Kafka chạy trên một cụm, luồng dữ liệu sẽ được phân chia và được vận chuyển tới các nút trong cụm, do đó cho phép trung chuyển các dữ liệu mà có khối lượng lớn hơn nhiều so với sức chứa của một máy đơn.
- Độ tin cậy: Dữ liệu vào hàng đợi sẽ được lưu trữ trên ổ đĩa và được sao chép tới các nút khác trong cụm để ngăn ngừa việc mất dữ liệu, như vậy Kafka đảm bảo tính chịu lỗi cao.
Khi so sánh với các hệ thống truyền thông điệp truyền thống lâu đời như RabbitMQ [8]. Trong kết quả chạy thử nghiệm của LinkedIn cùng một cấu hình với RabbitMQ, Kafka cho thấy lượng dữ liệu đọc và ghi cao hơn nhiều so với RabbitMQ. Ngược lại, lượng tài nguyên mà Kafka chiếm dụng lại ít hơn nhiều. Do đó Kafka thích hợp hơn cho các ứng dụng xử lý thời gian thực với lượng dữ liệu lớn.
Kiến trúc tổng quát
Kafka sử dụng mô hình truyền thông public-subscribe, bên pulbic dữ liệu được gọi là producer bên subscribe nhận dữ liệu theo topic được gọi là consumer. Kafka có khả năng truyền một lượng lớn dữ liệu trong thời gian thực, trong trường hợp bên nhận chưa nhận dữ liệu vẫn được lưu trữ sao lưu trên một hàng đợi và cả trên ổ đĩa bảo đảm an toàn. Các thành phần chính của Kafka như sau:
- Topic: là “chủ đề”, thông thường các dữ liệu liên quan hoặc tương tự được nhóm trong các chủ đề. Mỗi chủ đề có thể được coi là một nguồn dữ liệu riêng biệt. Dữ liệu được truyền trong kafka theo topic, khi muốn truyền dữ liệu khác nhau hay truyền dữ liệu cho các ứng dụng khác nhau ta sẽ tạo ra các topic.
- Partition: mỗi topic sẽ được phân chia thành nhiều partition. Partition là nơi lưu trữ dữ liệu cho 1 topic, trên mỗi partition, dữ liệu sẽ được lưu theo một thứ tự bất biến và được gán cho một id gọi là offset, được hiểu như chỉ số của một mảng. Offset trên mỗi partition là độc lâp. Một partition có thể được sao chép trên hiều máy khác nhau trong một cụm kaffka
- Broker: Kafka chạy trên một cụm bao gồm một hoặc nhiều máy (node), mỗi máy được gọi là một broker. Broker là nơi lưu trữ các partition, một broker có thể lưu trữ nhiều partition.
- Producer: sẽ viết dữ liệu tới broker. Cụ thể hơn, producer có nhiệm vụ chọn message nào để đưa vào topic nào, nhiệm vụ này rất quan trọng giúp cho Kafka có khả năng mở rộng tốt.
- Consumer: sẽ đọc dữ liệu từ broker. Kafka là hệ thống sử dụng mô hình truyền thông public-subscribe nên mỗi một topic có thể đc xử lý bởi nhiều consumer khác nhau, miễn là consumer đấy subcribe topic đấy.
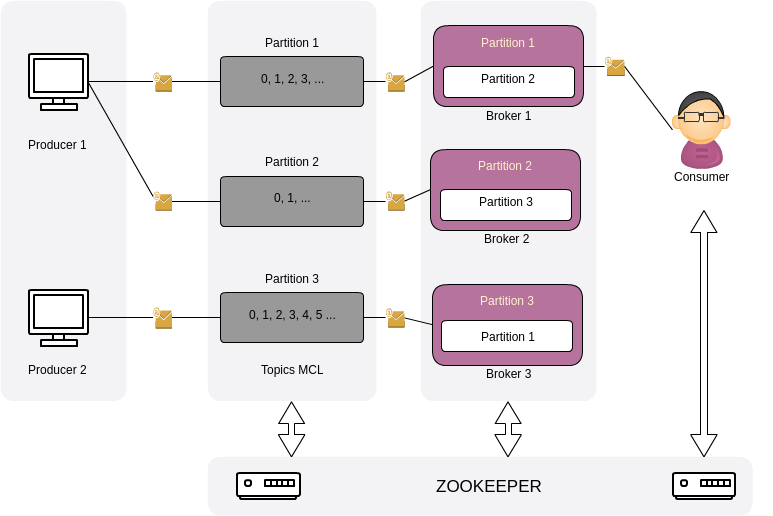 Hình trên mô tả kiến trúc của Kafka khi chạy trên một cụm với 3 broker, với một topic tên là MCL được chia thành 3 partition, mỗi partition sẽ có một bản sao chép ở một broker khác để phục vụ cơ chế sao lưu, khắc phục lỗi.
Mỗi partition sẽ có 1 broker làm vai trò trưởng nhóm (leader), những broker còn lại có lưu trữ partition đó được gọi là nút theo dõi (follower), chỉ có nhiệm vụ sao lưu dữ liệu. Mỗi partition được cấu hình tham số nhân bản (replication factor). Trong hình 2, replication factor = 2, nghĩa là mỗi partition sẽ được lưu trữ trên 2 broker.
Chỉ số (0, 1, 2...) trên mỗi partition là offset của mỗi partition chứ không phải offset của topic.
Một điểm lưu ý nữa của Apache Kafka, đó là nền tảng Apache Kafka được xây dựng kết hợp với nền tảng Apache Zookeeper. Zookeeper đóng vai trò cung cấp các dịch vụ lõi của hệ thống phân tán như: dịch vụ quản lý cấu hình hệ thống, bầu trưởng nhóm (leader election), định danh (naming), lưu trữ các thông tin chung metadata như thông tin về topic, partition của topic, danh sách broken, vị trí dữ liệu offset mà consumer đã đọc đến… Zookeeper được Kafka để bầu tự động leader cho các partition, quản lý danh sách nút máy chủ hoạt động và quản lý danh sách các topic.
Hình trên mô tả kiến trúc của Kafka khi chạy trên một cụm với 3 broker, với một topic tên là MCL được chia thành 3 partition, mỗi partition sẽ có một bản sao chép ở một broker khác để phục vụ cơ chế sao lưu, khắc phục lỗi.
Mỗi partition sẽ có 1 broker làm vai trò trưởng nhóm (leader), những broker còn lại có lưu trữ partition đó được gọi là nút theo dõi (follower), chỉ có nhiệm vụ sao lưu dữ liệu. Mỗi partition được cấu hình tham số nhân bản (replication factor). Trong hình 2, replication factor = 2, nghĩa là mỗi partition sẽ được lưu trữ trên 2 broker.
Chỉ số (0, 1, 2...) trên mỗi partition là offset của mỗi partition chứ không phải offset của topic.
Một điểm lưu ý nữa của Apache Kafka, đó là nền tảng Apache Kafka được xây dựng kết hợp với nền tảng Apache Zookeeper. Zookeeper đóng vai trò cung cấp các dịch vụ lõi của hệ thống phân tán như: dịch vụ quản lý cấu hình hệ thống, bầu trưởng nhóm (leader election), định danh (naming), lưu trữ các thông tin chung metadata như thông tin về topic, partition của topic, danh sách broken, vị trí dữ liệu offset mà consumer đã đọc đến… Zookeeper được Kafka để bầu tự động leader cho các partition, quản lý danh sách nút máy chủ hoạt động và quản lý danh sách các topic.
Topic
Mỗi topic sẽ có tên do người dùng đặt và có thể coi mỗi topic như là một hàng đợi của thông điệp (mỗi dòng dữ liệu). Các thông điệp mới do một hoặc nhiều producer đẩy vào, sẽ luôn luôn được thêm vào cuối hàng đợi.
Bởi vì mỗi thông điệp được đẩy vào topic sẽ được gán một offset tương ứng (ví dụ: thông điệp đầu tiên có offset là 1, thông điệp thứ hai là 2,..) nên consumer có thể dùng offset này để điều khiển quá trình đọc thông điệp. Nhưng cần lưu ý là bởi vì Kafka sẽ tự động xóa những thông điệp đã quá cũ ( thông điệp đẩy vào đã quá hai tuần hoặc xóa bởi vì bộ nhớ cho phép để chứa thông điệp đã đầy) vì vậy sẽ gặp lỗi nếu truy cập vào các thông điệp đã bị xóa.
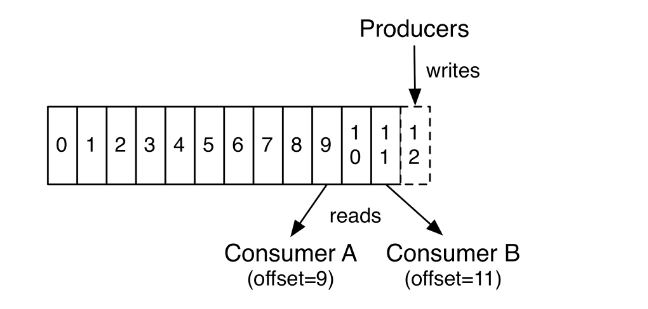 Ở trên mô tả 1 topic có duy nhất một partition. Trên thực tế một topic có rất nhiều partition, khi một thông điệp được đẩy vào topic, mặc định nó sẽ được gắn một chuỗi số bất kì. Thông điệp được đẩy vào topic nào phụ thuộc vào giá trị băm của chuỗi số đó, điều này đảm bảo số lượng thông điệp trên mỗi partition là tương tự nhau. Bởi vì tại một thời điểm, một partition chỉ được đọc bởi một consumer duy nhất, vậy với việc tăng số lượng partition sẽ tăng số lượng dữ liệu được đọc lên tương đương với việc song song hóa được việc đọc. Ngoài ra, offset chính là định danh duy nhất cho mỗi thông điệp ở trong partition chứ không phải trong toàn bộ topic, vì vậy để consumer đọc chính xác thông điệp, chúng ta cần cung cấp địa chỉ của thông điệp có dạng (topic, partition, offset).
Ở trên mô tả 1 topic có duy nhất một partition. Trên thực tế một topic có rất nhiều partition, khi một thông điệp được đẩy vào topic, mặc định nó sẽ được gắn một chuỗi số bất kì. Thông điệp được đẩy vào topic nào phụ thuộc vào giá trị băm của chuỗi số đó, điều này đảm bảo số lượng thông điệp trên mỗi partition là tương tự nhau. Bởi vì tại một thời điểm, một partition chỉ được đọc bởi một consumer duy nhất, vậy với việc tăng số lượng partition sẽ tăng số lượng dữ liệu được đọc lên tương đương với việc song song hóa được việc đọc. Ngoài ra, offset chính là định danh duy nhất cho mỗi thông điệp ở trong partition chứ không phải trong toàn bộ topic, vì vậy để consumer đọc chính xác thông điệp, chúng ta cần cung cấp địa chỉ của thông điệp có dạng (topic, partition, offset).
Partition
 Với mỗi partition, tùy thuộc vào người dùng cấu hình sẽ có một số bản sao chép nhất định để đảm bảo dữ liệu không bị mất khi một node trong cụm bị hỏng , tuy nhiên số lượng bản sao không được vượt quá số lượng broker trong cụm, và những bản sao đó sẽ được lưu lên các broker khác. Broker chứa bản chính của partition gọi là broker “leader”. Những bản sao chép này có tác dụng giúp hệ thống không bị mất dữ liệu nếu có một số broker bị lỗi, với điều kiện số lượng broker bị lỗi không lớn hơn hoặc bằng số lượng bản sao của mỗi partition. Ví dụ một partition có hai bản sao được lưu trên 3 broker sẽ không bị mất dữ liệu nếu có một broker bị lỗi. Còn một điều quan trọng nữa phải lưu ý, do các phiên bản sao chép này không nhận dữ liệu trực tiếp từ producer hay được đọc bởi consumer, mà nó chỉ đồng bộ với paritition chính vì vậy nó không làm tăng khả năng song song hóa việc đọc và ghi.
Với mỗi partition, tùy thuộc vào người dùng cấu hình sẽ có một số bản sao chép nhất định để đảm bảo dữ liệu không bị mất khi một node trong cụm bị hỏng , tuy nhiên số lượng bản sao không được vượt quá số lượng broker trong cụm, và những bản sao đó sẽ được lưu lên các broker khác. Broker chứa bản chính của partition gọi là broker “leader”. Những bản sao chép này có tác dụng giúp hệ thống không bị mất dữ liệu nếu có một số broker bị lỗi, với điều kiện số lượng broker bị lỗi không lớn hơn hoặc bằng số lượng bản sao của mỗi partition. Ví dụ một partition có hai bản sao được lưu trên 3 broker sẽ không bị mất dữ liệu nếu có một broker bị lỗi. Còn một điều quan trọng nữa phải lưu ý, do các phiên bản sao chép này không nhận dữ liệu trực tiếp từ producer hay được đọc bởi consumer, mà nó chỉ đồng bộ với paritition chính vì vậy nó không làm tăng khả năng song song hóa việc đọc và ghi.
Producer
Producer có nhiệm vụ đẩy dữ liệu vào một hoặc nhiều topic. Người dùng có thể quyết định liệu những thông điệp (mỗi dòng của dữ liệu) nào sẽ cùng thuộc vào một partition thông qua một chuỗi khóa đính kèm với thông điệp. Nếu không producer sẽ gán một khóa ngẫu nhiên và quyết định đích đến của thông điệp dựa trên giá trị băm của khóa.
Consumer
Consumer có nhiệm vụ kéo dữ liệu từ một topic chỉ định về. Tùy thuộc vào mục đích sử dụng, Kafka cung cấp hai hàm API như sau: High Level Consumer: API này hướng tới những ứng dụng không quan tâm về việc điều khiển việc đọc thông điệp (mỗi dòng của dữ liệu), người dùng chỉ có thể đọc từ thông điệp cũ nhất hoặc đọc từ thông điệp mới nhất. API này luôn lưu lại offset của thông điệp được lấy về mới nhất của mỗi partition vào Zookeeper. Simple Consumer: Việc sử dụng API này tương đối phức tạp hơn API trên nhưng nó cho phép điều khiển việc đọc một cách linh hoạt dựa trên offset. Do đó, API này cho phép ứng dụng có thể xử lý lại thông điệp nếu gặp lỗi trong quá trình xử lý trước đó.
All rights reserved
