Tổng quan về Apache Kafka - Hệ thống xử lý dữ liệu thời gian thực phân tán
Bài đăng này đã không được cập nhật trong 2 năm
1. Giới thiệu về Apache Kafka
- Apache Kafka là một hệ thống xử lý dữ liệu thời gian thực mã nguồn mở được tạo ra tại LinkedIn và sau đó đã được chuyển giao phát triển bởi Apache Software Foundation. Nó đã trở thành một phần quan trọng của cơ sở hạ tầng cho các ứng dụng xử lý dữ liệu lớn và phân tán. Bài viết này sẽ trình bày về các khía cạnh quan trọng của Apache Kafka, cách nó hoạt động và lý do tại sao nó trở thành một công cụ quan trọng cho việc quản lý dữ liệu và xây dựng các ứng dụng có tính mở.
- Apache Kafka ra đời để giải quyết các thách thức liên quan đến xử lý dữ liệu thời gian thực, lưu trữ log và chia sẻ dữ liệu giữa các ứng dụng trong môi trường phân tán và có sự mở rộng.
- Apache Kafka thường được ứng dụng trong nhiều lĩnh vực như:
- Trong lĩnh vực Logistic: Khi thường xuyên phải sử dụng và xử lý số lượng đơn hàng không lồ mỗi ngày đến từ những nền tảng thương mại điện tử Ecommerce lớn đặc biệt là trong lúc các chương trình khuyến mại diễn ra.
- Trong lĩnh vực Y học: Triển khai xây dựng những cảm biến theo dõi tình trạng của bệnh nhân bao gồm các thông số như nhịp tim, huyết áp hay thần kinh, ... giám sát sức khỏe người bệnh và đưa ra phác đồ điều trị kịp thời.
- Trong Marketing: Lưu trữ dữ liệu về hành vi người dùng mạng xã hội và các công cụ tìm kiếm, những trình duyệt từ đó tạo ra các quảng cáo phù hợp.
- Ưu điểm của Apache Kafka
- Khả năng chịu tải cao: Hệ thống Kafka có thể tăng cường khả năng xử lý bằng cách thêm các broker mới vào cluster.
- Đảm bảo tính nhất quán: Sử dụng mô hình nhất quán dựa trên log-based để lưu trữ sự kiện -> đảm bảo dữ liệu không bị mất và luôn tuân theo thứ tự gửi.
- Độ tin cậy cao: Kafka đảm bảo tính sẵn sàng và tin cậy cao ngay cả khi một số broker gặp sự cố, dữ liệu vẫn có thể truy cập thông qua các broker khác.
- Xừ lý dòng sự kiện: Kafka hỗ trợ xử lý dòng sự kiện theo thời gian thực, giúp ứng dụng theo dõi và phản ứng nhanh chóng đối với các sự kiện quan trọng.
- Nhược điểm của Apache Kafka
- Phức tạp trong việc triển khai và quản lý.
- Yêu cầu nguồn tài nguyên đáng kể.
- Khả năng quản lý dữ liệu cũ hạn chế.
- Quá tải trong việc lưu trữ sự kiện không cần thiết.
2. Kiến trúc của Apache Kafka
Kiến trúc cơ bản của Apache Kafka bao gồm các yếu tố quan trọng sau:
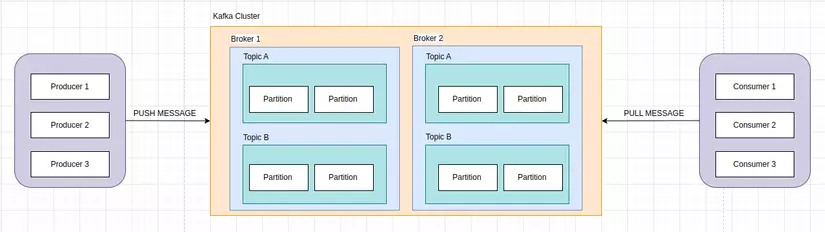
- Cluster: Một tập hợp các máy chủ Brokers bao gồm ít nhất 1 Broker nhưng thường là nhiều Broker hoạt động cùng nhau. Cluster Kafka có vai trò quan trọng trong việc cung cấp tính mở rộng, tính nhất quán và độ tin cậy cho việc xử lý dữ liệu thời gian thực.
- Broker: Là thành phần cốt lõi của Apache Kafka, đại diện cho máy chủ xử lý và lưu trữ dữ liệu Kafka. Một cụm Kafka thường bao gồm nhiều Broker và mỗi Broker có thể xử lý sản xuất Producer và tiêu thụ Consumer dữ liệu. Broker chịu trách nhiệm quản lý và lưu trữ các Partition của các chủ đề Topics.
- Topic: Dữ liệu trong Apache Kafka được phân loại thành các chủ đề Topic. Mỗi Topic là một luồng dữ liệu độc lập và có thể được coi là một danh sách các tin nhắn liên quan. Producer gửi dữ liệu tới các Topic và Consumer đọc dữ liệu từ các Topic. Topic cho phép các ứng dụng chỉ quan tâm đến các loại dữ liệu cụ thể mà nó muốn tiêu thụ.
- Partition: Mỗi Topic có thể được chia thành nhiều phân vùng. Partition là một phần nhỏ của chủ đề và đóng vai trò quan trọng trong việc phân tán dữ liệu và tăng hiệu suất. Mỗi Partition được lưu trữ trển một Broker và dữ liệu được đọc và ghi vào từng Partition một.
- Producer: Producer là thành phần của Apache Kafka cho phép ứng dụng gửi dữ liệu tới các Topic. Producer sử dụng giao thức Kafka để kết nối với Broker và đưa dữ liệu vào các Partition của các chủ đề.
- Consumer: Là thành phần cho phép ứng dụng lấy dữ liệu từ các Topic Kafka. Consumer cũng sử dụng giao thức Kafka để kết nối với Broker và đọc dữ liệu từ các Partition. Có thể có nhiều Consumer đọc từ cùng 1 Topic và Kafka đảm bảo rằng mỗi tin nhắn chỉ được đọc bởi 1 Consumer.
- ZooKeeper: Là một hệ thống quản lý tập trung được sử dụng để quản lý và duy trì trạng thái của các Broker trong một cụm Kafka. Nó chịu trách nhiệm trong việc theo dõi và quản lý các Broker giúp Kafka hoạt động ổn định và đảm bảo tính nhất quán.
Kiến trúc này cho phép Apache Kafka xử lý và lưu trữ dữ liệu thời gian thực một cách hiệu quả, đảm bảo độ tin cậy và tính nhất quán của dữ liệu và hỗ trợ khả năng mở rộng để đối phó với các tải công việc lớn.
3. Apache Kafka trong hệ thống
Kafka được xây dựng dựa vào mô hình subcribe - publish nên tương tự với hệ thống message.
- Kafka hoạt động dưới dạng một hệ thống phân tán gồm nhiều máy chủ broker, mỗi broker chịu trách nhiệm lưu trữ một phần dữ liệu và có thể mở rộng bằng cách thêm các broker mới.
- Dữ liệu trong Kafka được phân chia thành các Topic, mỗi Topic đại diện cho một loại dữ liệu cụ thể. Mỗi chủ đề trong Kafka được chia thành các phân đoạn Partition và mỗi Partition chứa một phần dữ liệu và được lưu trữ trên một số Broker. Tương ứng với mỗi bản ghi Partition được gán một số offset duy nhất thể hiện vị trí của bản ghi trong Partition. Consumer sử dụng offset để theo dõi dữ liệu đã đọc.
- Những người tạo ra dữ liệu gửi nó tới Kafka gọi là Producer. Producer gửi các bản ghi dữ liệu tới các Topic cụ thể trong Kafka.
- Consumer là người sử dụng dữ liệu từ Kafka. Consumer đăng ký để theo dõi một hoặc nhiều Topic và nhận dữ liệu từ chúng.
- Kafka hỗ trợ sao lưu dữ liệu trên nhiều broker để đảm bảo tính sẵn sàng và bảo mật. Mỗi partition có thể có nhiều bản sao được lưu trữ trên các broker khác nhau.
- Khi có dữ liệu được gửi đến Kafka, nó sẽ được lưu trữ trong các partition tương ứng. Consumers có thể đọc dữ liệu thông qua các partition này theo offset và thực hiện xử lý tùy theo nhu cầu.
Ứng dụng của Kafka
- Stream processing: Kafka thích hợp cho việc xử lý luồng dữ liệu nhanh chóng. Dữ liệu đến từ nhiều nguồn và có thể được xử lý ngay khi nó đến, cho phép các ứng dụng thời gian thực như phát hiện sự kiện, phân tích hành vi người dùng và đưa ra phản hồi tức thì.
- Hệ thống IoT: Kafka có khả năng xử lý lưu lượng dữ liệu lớn từ các thiết bị IoT. Nó cho phép thu thập, lưu trữ và xử lý dữ liệu từ hàng triệu thiết bị đồng thời, giúp tạo ra các ứng dụng IoT như theo dõi và điều khiển từ xa, thu thập dữ liệu cảm biến và giám sát thiết bị.
- Phân tích sự kiện và Log: Kafka thường được sử dụng để lưu trữ và phần tích log hệ thống, sự kiện ứng dụng giúp giám sát và phân tích hiệu suất hệ thống, xác định vấn đề, thực hiện các tác vụ bảo trì và debug.
- Chuyển đổi ngôn ngữ lập tình: Kafka có thể được sử dụng để chuyển đổi dữ liệu giữa các ứng dụng viết bằng các ngôn ngữ lập trình khác nhau. Bằng cách đẩy dữ liệu vào Kafka trong một ngôn ngữ và đọc dữ liệu từ Kafka bằng ngôn ngữ khác → có thể tích hợp và kết nối các thành phần của hệ thống với nhau.
4. Kiến trúc Pub - Sub Messaging với Apache Kafka
Apache Kafka là một giải pháp mạnh mẽ cho kiến trúc Publish-Subscribe (Pub-Sub), giúp các ứng dụng xử lý dữ liệu thời gian thực có thể trao đổi thông tin một cách hiệu quả và đáng tin cậy. Dưới đây là quy trình hoạt động cơ bản của Kafka trong mô hình Pub-Sub:
- Kafka Producer gửi message đến Topic
- Kafka Broker lưu trữ tất cả các message trong các partition được định cấu hình topic cụ thể đó, đảm bảo rằng các message được phân phối cân bằng giữa các partition. Ví dụ, Kafka sẽ lưu trữ một message trong partition đầu tiên và message thứ 2 trong partition thứ 2 nếu producer gửi hai message và có hai partition.
- Kafka Consumer subscribes một topic cụ thể.
- Sau khi Consumer subscribes vào một topic, Kafka cung cấp offset hiện tại của topic cho Consumer và lưu nó trong Zookeeper.
- Consumer sẽ liên tục gửi request đến Kafka để pull về các message mới.
- Kafka sẽ chuyển tiếp tin nhắn đến Consumer ngay khi nhận được từ Producer.
- Consumer sẽ nhận được message và xử lý nó.
- Kafka Broker nhận được xác nhận về message được xử lý.
- Kafka cập nhật giá trị offset hiện tại ngay khi nhận được xác nhận. Ngay cả trong khi máy chủ outrages, consumer có thể đọc được message tiếp theo một cách chính xác, bởi Zookeeper quản lý các offset.
- Quy trình này lặp lại cho đến khi consumer dừng việc subcribes lại.
Kafka đảm bảo tính nhất quán và độ tin cậy trong việc trao đổi thông tin giữa producer và consumer, và với khả năng mở rộng mạnh mẽ, nó là một công cụ quan trọng trong kiến trúc Pub-Sub cho các ứng dụng dữ liệu thời gian thực.
5. Tương lai Apache Kafka
Tương lai của Apache Kafka là tiếp tục phát triển và thúc đẩy các tính năng mới và cải tiến để đáp ứng các nhu cầu ngày càng phức tạp trong lĩnh vực xử lý dữ liệu thời gian thực. Dưới đây là một số xu hướng và tiềm năng về tương lai của Apache Kafka:
- Tích Hợp Với Các Công Cụ Phân Tích Dữ Liệu Mới: Apache Kafka sẽ tiếp tục cải thiện tích hợp với các công cụ phân tích dữ liệu như Apache Spark, Apache Flink, và Apache Beam để hỗ trợ các tác vụ phân tích và xử lý dữ liệu phức tạp.
- Cải Thiện Hiệu Suất Và Khả Năng Mở Rộng: Apache Kafka sẽ tiếp tục tối ưu hóa hiệu suất của mình để xử lý được tải công việc ngày càng lớn và tăng cường khả năng mở rộng, bao gồm cả khả năng tự động mở rộng.
- Bảo Mật Tăng Cường: Một ứng dụng quan trọng của Apache Kafka là trong các tình huống yêu cầu bảo mật dữ liệu. Vì vậy, tương lai của Kafka bao gồm cải thiện bảo mật, bao gồm quản lý quyền truy cập và mã hóa dữ liệu.
- Khả Năng Xử Lý Dữ Liệu Liên Tục: Apache Kafka có thể sẽ phát triển khả năng xử lý dữ liệu liên tục (stream processing) để hỗ trợ các ứng dụng xử lý dữ liệu thời gian thực ngày càng phức tạp.
- Mở Rộng Sử Dụng Trong Các Lĩnh Vực Mới: Kafka có tiềm năng để mở rộng sử dụng của nó vào các lĩnh vực mới, như IoT (Internet of Things), trí tuệ nhân tạo (AI), và nhiều lĩnh vực khác.
Apache Kafka là một công cụ quan trọng và sẽ tiếp tục phát triển để đáp ứng nhu cầu ngày càng tăng của việc xử lý dữ liệu thời gian thực và phân phối trong các ứng dụng và hệ thống phân tán.
All rights reserved
