1 ngày làm analytic: Đo lường CCU theo thời gian thực
!!! WARNING: Toàn bộ những thứ dưới đây được thực hiện trong MỘT (01) ngày !!!
Đừng làm theo vì sẽ thấy hối hận !!!
NHƯNG NÊN ĐỌC
Truyền thuyết kể rằng, vào một ngày chủ nhật đẹp trời, Minh Monmen đột nhiên nảy ra ý tưởng sẽ hay ho thế nào nếu mình dựng một chiếc dashboard để kiểm tra CCU của hệ thống theo thời gian thực. Một ý tưởng vô cùng fancy nếu không nói tới việc tại sao lại phải bày vẽ làm những thứ mà rất nhiều thằng khác ĐÃ LÀM RỒI và LÀM NGON HƠN như Google Analytics, Firebase Analytics,... Tất cả việc của chúng ta cần làm chỉ là cắm nó vào và mọi thứ đã sẵn sàng.

But no, vốn là một người sẵn tính đa nghi, mình không tin tưởng lắm vào các công cụ, và chỉ coi GA các kiểu là một loại tham chiếu thôi. Và quan trọng hơn, mình cần hoàn toàn kiểm soát được con số mà mình tạo ra, hiểu nó có những sai số gì, nó có ý nghĩa thế nào, tại sao nó lại như vậy,... Thay vì nhắm mắt gật đầu với một con số vô năng nào đó và tự hỏi bản thân về ý nghĩa thật sự của chúng.
Don't Reinvent The Wheel, Unless You Plan on Learning More About Wheels
Đây là tiêu đề 1 bài viết mình đọc được trên codinghorror.com về việc không phát minh lại bánh xe khi những người khác đã thực hiện nó rất tốt rồi. Vậy nên nếu bạn là 1 coder thuần túy và không quan tâm tới bí ẩn sau những con số, bạn có thể bỏ đi, bởi vì mọi việc phía sau đây mình làm đều là reinvent the wheel
First things first
Trước khi trở lại câu truyện xe pháo, xin dành 1 phút để kỷ niệm sự hiện diện của tác giả Minh Monmen, người mặc dù thực hiện code chỉ trong 1 ngày nhưng lại mất tới 5 ngày để ghi chép lại quá trình khám phá của mình trên con đường đến với những tri thức (cũ). Nghề nghiệp hay tình trạng sức khỏe, hôn nhân, giới tính của tác giả thì nguyễn y vân nên sẽ không được đề cập tiếp ở đây.
Chắc chắn bài viết này sẽ rất dài và có khi còn phải tách ra làm mấy phần khác nhau, nên để cho các bạn có thêm động lực thì mình sẽ tổng kết trước 1 số điều mà mình đã học được sau 1 ngày cặm cụi thiết kế hệ thống đo CCU này:
- Hiểu được đo lường CCU rất khó (of course).
- Có cơ hội thực hành 2 yếu tố mà mình ấp ủ từ lâu: siêu nhanh và siêu thực (tức là không thực tế =))).
- Thuật toán đếm gần đúng siêu nhanh siêu nhẹ: Hyperloglog
- In-memory caching (kiểu nghiêm túc)
- Batch processing (kiểu xịn xò)
- Sử dụng tài nguyên đúng cách (kiểu tiết kiệm 1 cách tởm lợm)
- Cuối cùng là kết luận: Công nghệ KHÔNG làm ứng dụng của bạn chạy nhanh hơn. BẠN mới là người làm điều đó. ...
Và rất nhiều điều khác mà mình không chỉ học được để làm hệ thống này, mà còn để áp dụng cho rất nhiều bài toán khác mà mình cũng đang đau đầu. Có như vậy mới biết Thiết kế lại cái bánh xe giúp mình không những biết đi xe, mà còn giúp xe biết đi mình nữa.
Còn đây là những kiến thức bạn cần chuẩn bị để tiếp cận với bài viết này:
- CCU
- Golang (vì nhiều phần implement sử dụng golang nên biết thì sẽ tốt hơn)
- Time series data: dữ liệu chuỗi thời gian
- Probabilistic data: dữ liệu ước lượng
- Redis
- Prometheus, grafana (dùng để thu thập dữ liệu và biểu diễn đồ thị)
- Lòng dũng cảm và ham học hỏi (đây là thứ cần thiết nhất)
Tạm thế, nhào vô.
Mấy dòng kiến thức cơ bản
Nếu đã bắt tay bắt chân vào làm web, app thì tất nhiên ai cũng sẽ ít nhất 1 lần được nghe tới CCU, tên tường gọi là kon ku, hay Concurrent Users, tức là số user đồng thời đối với một hệ thống. Định nghĩa thì nó chỉ nôm na và đơn giản như vầy.
Định nghĩa thì đơn giản như vậy nhưng tính CCU thế nào, và CCU có ý nghĩa ra sao với bạn lại lại một câu chuyện hoàn toàn khác. Không có một công thức chính xác nào có thể áp dụng cho toàn bộ các hệ thống bởi vì mỗi cách đo CCU lại cho bạn 1 ý nghĩa khác nhau. Ví dụ:
- Với các hệ thống thời gian thực như game, chat,... và các user mở 1 connection lâu dài tới server như socket,... thì CCU có thể được đo bằng cách đếm số lượng connection tới server tại 1 thời điểm. Con số này có thể dùng để cho bạn biết khả năng chịu tải của hệ thống, tính toán giới hạn, lên plan phần cứng,...
- Với các hệ thống web bình thường không sử dụng connection lâu dài kiểu web tin tức, web bán hàng,... thì CCU có thể được đo bằng cách đếm số lượng client request tới server trong 1 khoảng thời gian. Con số này cũng nói lên 1 phần lượng traffic mà bạn cần đáp ứng, tuy nhiên tùy vào từng hệ thống cụ thể thì nó cần phải kết hợp với số request được tạo tới hệ thống, tính chất từng request,... thì bạn mới có cái nhìn chính xác hệ thống của mình.
Trong bài viết này, mình sẽ đề cập tới kiểu tính CCU cho phần lớn các hệ thống web, app hiện tại là không sử dụng connection lâu dài mà dựa vào HTTP request của user.
Làm sao để tự tính được CCU
Thông thường với các hệ thống analytic bình thường bạn sẽ dễ dàng theo dõi được các chỉ số như DAU, MAU, tổng số request trong 1 khoảng thời gian,... và bạn hoàn toàn có thể dùng các chỉ số này để ước lượng CCU. Tuy nhiên những con số này chỉ dừng lại ở mức ước lượng. Bạn có thể biết 1 ngày bạn có 100K active user, nhưng số user này đâu có phân bố đồng đều? CCU của bạn khi đó có thể chỉ tập trung vào 1 số thời điểm hot mà thôi.
Và tất nhiên là không phải bạn cứ muốn tự tính CCU là có thể tính được đâu nhé. Hệ thống của các bạn phải đáp ứng được đủ 1 số điều kiện ở cả phía client và server.
Client
Để có thể đo đếm được CCU thì client phải làm một cái gì đó để phía server ghi nhận người dùng hiện tại đang active. Đó có thể là:
- 1 request khởi tạo session
- hoặc 1 request ping (ví dụ 1 phút lại ping server 1 lần)
- hoặc 1 request thực hiện 1 action nào đó như đọc, ghi dữ liệu
- Cao cấp hơn là client tự ghi nhận thời gian user còn trên app hay web (mà có thể gửi sau tới server)...
Cơ chế phổ biến nhất và chính xác nhất thường được các loại app, web sử dụng là tạo ra 1 request ping riêng biệt tới server. Request này có thể chỉ có ý nghĩa ping, cũng có thể chứa thêm nhiều thông tin được đóng gói khác. Nhưng quan trọng là nó được client gọi để báo cho server biết là user đang active trên app.
Request ping có thể được gọi định kỳ 10s, 20s, 60s hay vài phút 1 lần tùy vào đặc điểm phiên làm việc của từng app.
Server
Có 2 cách đo đạc CCU phía server:
- 1 là tracking riêng biệt request ping. Nếu client đã hỗ trợ ping tới server định kỳ thì việc duy nhất phía server cần làm đó là theo dõi request này.
- 2 là khi request ping chuyên biệt không khả dụng, thì cần có 1 lớp middleware để can thiệp vào mọi endpoint (hoặc phần lớn endpoint) của hệ thống. Đây chỉ là cách để khắc phục việc client không có request ping chuyên biệt, sẽ tạo ra nhiều sai số.
Bởi vì ứng dụng của mình chưa hỗ trợ ping request, nên mình đã xem xét và sử dụng cách thứ 2 sau khi nhận thấy kiến trúc hệ thống của mình phù hợp với cách làm này.
Khó khăn chồng chất
Vạn sự khởi đầu nan, gian nan bắt đầu nản. Sau khi bắt tay vào thực hiện thì mình đã vấp phải những khó khăn cả về mặt số liệu và cả về mặt công nghệ như sau:
Xác định 1 CCU
Trông vậy mà đây lại là 1 câu hỏi rất khó trả lời. Khi nào thì bạn tính 1 CCU? Đó có phải là khi có 1 user nào đó login vào trang web của bạn? Hay là tính cả user chưa đăng nhập? Vậy 1 user dùng 2 tab thì tính là mấy CCU? Hay thậm chí là các request từ bot google, facebook, bên thứ 3,... vào hệ thống cũng tính 1 CCU?
Lúc làm mới thấy việc làm sao để xác định 1 CCU thôi cũng confuse rồi. Và lại 1 lần nữa là câu hỏi này cũng không có đáp án mà việc trả lời ra sao hoàn toàn tùy thuộc vào hệ thống của bạn có hỗ trợ không, giả định của bạn về business và cách bạn chấp nhận con số kết quả.
Bởi vì mình không control được phần thông tin của client, do vậy mình đã chấp nhận sử dụng những thông tin mà mình có sẵn về 1 client trong từng request sau:
- User ID: Có được từ session/token của user
- Client IP: Có được từ tầng proxy/gateway bên ngoài
- User Agent: Có được từ request header
Sau khi kết hợp 3 thông tin này lại, mình có được 1 cách định danh 1 CCU gần đúng.
Tại sao lại gần đúng? Bởi vì sẽ có khá nhiều case 1 client gọi request có token/không token, hoặc 1 client mở nhiều tab khác nhau, hoặc 1 IP chứa nhiều client riêng biệt, hoặc nhiều client có chung user-agent...
1 CCU tồn tại trong bao lâu
1 CCU được ghi nhận sẽ tồn tại trong bao lâu?
Đó là câu hỏi chúng ta phải trả lời tiếp theo đối với các hệ thống không có connection lâu dài. User chỉ tương tác với hệ thống của chúng ta qua các request riêng lẻ, vì vậy CCU chỉ có ý nghĩa khi chúng ta gắn nó với một khoảng thời gian nào đó. Ví dụ: Trong 1 phút, số người cùng truy cập vào hệ thống là 1000 người - tức là trong 1 phút đã có 1000 user khác nhau truy cập vào hệ thống.
Việc lựa chọn timeframe là 1 phút, 3 phút hay 10s, 20s,... phụ thuộc hoàn toàn vào cách các bạn hiểu về hệ thống của mình. Ví dụ với các hệ thống có tương tác qua request với tần suất lớn thì timeframe sẽ giảm và ngược lại.
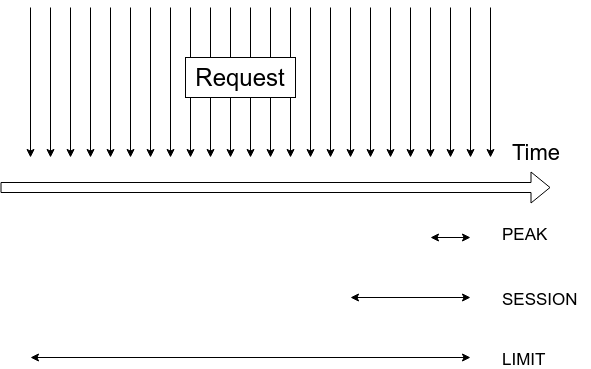
Ở đây mình định nghĩa hệ thống của mình gồm 3 mức: (cái này hoàn toàn là do mình tự phịa ra và không dựa trên 1 học thuyết nào cả nên chỉ mang tính tham khảo cho các bạn)
- Mức PEAK: Là mức thời gian nhỏ nhất (sử dụng làm mức time base để đếm). Mình lấy theo giá trị khoảng thời gian dài nhất giữa 2 request từ client. Có ý nghĩa liên quan tới số request trong 1 thời điểm peak xuất phát từ bao nhiêu client và được gọi là Peak CCU. Ví dụ app của mình định kỳ 1 phút lại gọi 1 request gì đó tới server thì thời gian dài nhất giữa 2 request của client sẽ là 1 phút. Tuy nhiên con số này có thể không chính xác khi không xuất hiện những request định kỳ, hoặc client xử lý 1 tác vụ nào đó mà KHÔNG CẦN gọi tới server.
- Mức SESSION: Là mức thời gian trung bình. Mình lấy theo giá trị quanh ngưỡng thời gian trung bình 1 session của user. Con số này có ý nghĩa xem xét trong khoảng thời gian 1 session thì có bao nhiêu user đã xuất hiện. Mình gọi con số này là Session CCU. Thông thường thì con số này sẽ phản ánh chính xác CCU hơn khi nó bao quát cả những user đã truy cập vào app nhưng không phát sinh tác vụ nào liên quan tới server hoặc không được thể hiện qua CCU thời điểm. Ví dụ app của mình có thời lượng Time On App trung bình là 5 phút thì mình sẽ lấy 5 phút để làm mức thời gian đo Session CCU
- Mức LIMIT: Là mức thời gian dài nhất còn xem xét để tính CCU. Mức thời gian này thường được linh động tùy theo yêu cầu, tuy nhiên mình thường đặt ở mức 3~>6 lần Mức SESSION. Mục tiêu là xem xét lưu lượng truy cập vào hệ thống 1 cách tổng quát trong time frame đủ dài để đánh giá chất lượng và giới hạn của các chiến dịch push lôi kéo người truy cập. Ví dụ sử dụng 2 lần peak CCU liên tiếp thì liệu lần peak sau sẽ giúp hệ thống có bao nhiêu traffic mới hay chỉ toàn các traffic cũ? Khoảng thời gian này cũng không nên dài quá vì nó sẽ bị pha loãng và làm mượt số trong thời gian dài. Mình thường chọn khoảng thời gian từ 15~>30 phút cho mức time LIMIT và gọi con số này là Limit CCU
Đếm unique CCU
Sau khi đã có cách định danh 1 CCU và thời gian tính CCU rồi, vậy ta làm cách nào để đếm unique CCU khoảng thời gian đó? Đếm unique với số ít có thể là bài toán đơn giản, nhưng khi số request lên tới hàng chục, hàng trăm ngàn request trong 1 khoảng thời gian ngắn thì để tìm được số unique CCU trong đó lại không phải bài toán dễ dàng và nhanh chóng.
Ý tưởng đầu tiên nảy đến trong đầu khi động tới bài toán này chính là sử dụng redis set. Redis Set là 1 kiểu dữ liệu của Redis cho phép lưu trữ 1 mảng ko lặp lại các phần tử. Ta có thể dễ dàng thêm phần tử và đếm số phần tử của 1 set với những command có độ phức tạp O(1).
Thế nhưng sử dụng Redis Set với dạng dữ liệu string như trên có khá nhiều nhược điểm:
- Tốc độ union thấp (độ phức tạp O(n) với n là số phần tử của mọi tập hợp). Điều này khiến quá trình tính toán cho các khoảng thời gian lớn hơn chậm hơn rất nhiều (ví dụ tính số unique CCU trong 5 phút bằng cách kết hợp 5 key CCU của từng phút)
- Sử dụng rất nhiều ram do dữ liệu được lưu dưới dạng string set. Mặc dù ta có thể tiết kiệm bằng cách convert lại giá trị
user_id-client_ip-user_agentthành chuỗi hash ngắn hơn, nhưng số lượng ram cần thiết để lưu trữ data cho CCU vẫn rất lớn.
May mắn thay, nếu bạn đã đọc bài viết trước của mình về Analytic cho người nông dân: Bài toán đếm số thì mình đã có đề cập 1 thuật toán sinh ra để xử lý công việc này. Đó chính là Hyperloglog.
Hyperloglog là thuật toán tính toán gần đúng các giá trị khác nhau trong tập hợp, thuật toán này có độ chính xác cao mà vẫn giữ được dung lượng dữ liệu nhẹ nhàng, hỗ trợ nhiều operation liên quan tới đếm phần tử trong 1 hoặc nhiều tập hợp. Và quan trọng nhất là nó rất nhanh. Superfast nếu chúng ta tổ chức dữ liệu hợp lý.
Nhắc lại nhẹ 1 chút kiến thức từ bài viết trước. Chi tiết về hyperloglog các bạn có thể google thêm nhé. Còn ở đây tạm thời biết vậy đã. Mình có thể lưu lại dữ liệu CCU chính xác đến từng phút trong 1 hệ thống vài chục triệu request mỗi ngày chỉ với 10MB ram.
Để phục vụ việc đo lường realtime thì mình đã sử dụng hyperloglog trên redis với kiểu dữ liệu Redis Hyperloglog được built-in trên redis từ phiên bản 2.8.9. Bạn có thể xem thêm về cách redis implement hyperloglog trong bài viết này: Redis new data structure: the HyperLogLog.
Tích hợp với các hệ thống sẵn có
Đây là phần tương đối khoai sắn khi trong 1 thời gian ngắn (1 ngày) để mình có thể tích hợp được việc đếm CCU vào hệ thống vốn đã phức tạp hiện tại. Để cho đơn giản thì mình có thể mô tả hệ thống của mình như sau:
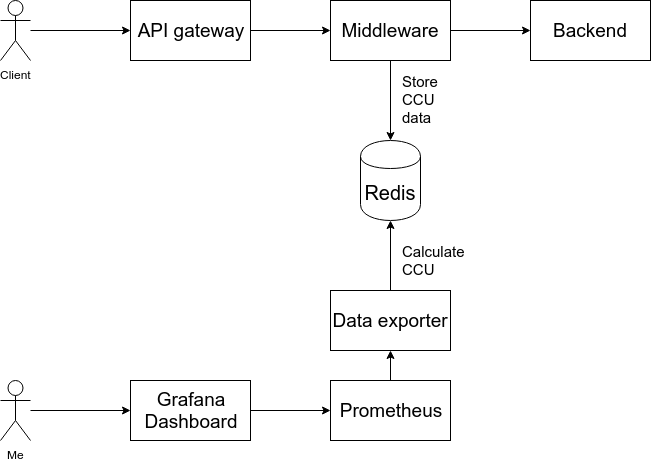
Giờ mình sẽ can thiệp vào lớp middleware để can thiệp vào các request. Việc này chứa đựng nhiều rủi ro liên quan tới performance của hệ thống vì middleware là lớp ảnh hưởng tới mọi request từ client. Và thực tế khi thực hiện thì mình đã test được performance của tầng middleware của mình giảm 1 nửa.
Một điểm thuận lợi không hề nhẹ là bên mình đã có sẵn hệ thống monitor bằng Prometheus + Grafana. Do vậy việc của mình lúc này chỉ gồm việc thu thập dữ liệu từ middleware và export dữ liệu ra Prometheus là có thể xem chart được trên Grafana rồi.
Bắt tay vào thực hiện
Nói dông dài như vậy là để các bạn hiểu được bản chất của việc solve problem trong lập trình. Thời gian ta mất để thực hiện giải 1 bài toán thì rất nhanh (như mình chỉ cần 1 ngày), nhưng thời gian ta mất để có đủ kiến thức giải quyết bài toán ấy thì không hề ít chút nào. Toàn bộ những kiến thức trên mình đã mất nhiều tháng thực hiện các dự án liên quan tới tracking, analytic, xây dựng kiến trúc hệ thống, monitoring,... mới có được. Mình đã rất cố gắng chắt lọc để bài viết có thể súc tích và dễ hiểu nhất có thể. Các bạn hãy tiếp tục theo dõi nhé.
Action plan
Đây là những step mình đã làm để thu thập dữ liệu:
- Khi có 1 request tới hệ thống, tạo ra định danh CCU bằng việc kết hợp thông tin:
user_id-client_ip-user_agent. - Để có 1 cái nhìn sâu hơn về chỉ số CCU, mình parse user-agent để nhận diện thiết bị mà người dùng sử dụng. Cụ thể là phân loại sơ bộ client thành
ios,android,web_pc,web_mobile,other. - Tạo ra 1 bộ key trên redis tương ứng với Mức PEAK, ở đây là từng phút để lưu hyperloglog, ta gọi là bucket. Mỗi loại client sẽ có 1 bucket riêng.
- Thêm định danh CCU vào bucket tương ứng bằng lệnh PFADD
Hết phần data collector. Tiếp phần data exporter.
- Định kỳ Prometheus sẽ gọi tới endpoint của data exporter để lấy metrics.
- Tương ứng với 3 khoảng thời gian: PEAK, SESSION, LIMIT sẽ có 3 metric tương ứng. Data exporter sẽ tính 3 metric này bằng cách sử dụng lệnh PFCOUNT

Hết phần data exporter. Cuối cùng là dùng Grafana để vẽ chart. Cái này easy quá thôi không nói =)))
Chấp nhận 1 user có sai số
Oops, trong quá trình run thử mình phát hiện ra có rất nhiều các trường hợp gây sai số cho mình khi định danh 1 CCU:
- Các request từ bên thứ 3.
- Các request từ 1 client nhưng tới public API và private API sẽ khác nhau về việc chứa hay không chứa token.
- Các request từ 1 user login nhiều tài khoản với các định danh giống nhau.
- ...
Rất nhiều thứ làm ảnh hưởng tới việc xác định 1 request có được coi là từ 1 CCU mới không. Chính vì vậy để khắc phục hạn chế này thì mình đã tách thành 2 bộ chỉ số riêng biệt là:
- CCU đo bằng unique user (chỉ sử dụng logged-in user với định danh là
user_idđể đếm) - CCU đo bằng unique session (sử dụng định danh
IP + user-agent + user_idđể đếm)
Nhờ có 2 chỉ số này, mình có một cái nhìn tổng quát và chính xác hơn về lượng user trong hệ thống, cả về khía cạnh số user (chính xác hơn nhưng thiếu guest) và session (kém chính xác hơn nhưng tổng quát hơn)
Chấp nhận cả hệ thống có sai số
Sự hy sinh tiếp theo là về tính chuẩn xác của dữ liệu. Như mình đã đề cập ở trên, nếu tính CCU bằng Redis Set thì sẽ cho số chính xác hơn. Tuy nhiên để tiết kiệm bộ nhớ, cũng như tăng tốc độ trong việc union giữa các bucket thì mình đã chấp nhận sử dụng Redis Hyperloglog để tính toán.
Với tỷ lệ sai số khá thấp (<2%) thì việc sử dụng Hyperloglog có lợi ích vượt trội hơn trong trường hợp này. Chỉ với 10MB Ram mình có thể lưu toàn bộ dữ liệu CCU của hệ thống thay vì vài trăm MB như sử dụng redis set.
Chấp nhận... à mà thôi không chấp nhận
Cuối cùng là sự hy sinh về performance. Như mình đã nói thì vấn đề performance là 1 rủi ro rất lớn cho hệ thống mà mình phải chấp nhận. Ở lần implement đầu tiên, với mỗi request tới mình đã:
- Parse user-agent để phân loại request
- Call
PFADD2 lần để thêm định danh vào bucket tương ứng.
Mặc dù việc parse user-agent và call redis được chạy hoàn toàn async, tức là phản hồi lại cho user xong mới thực hiện, tuy nhiên kết quả benchmark middleware của mình đã sụt giảm như sau:
------ Before implement ------
Requests per second: 17332.91 [#/sec] (mean)
Time per request: 5.515 [ms] (mean)
------ After implement ------
Requests per second: 7644.02 [#/sec] (mean)
Time per request: 10.027 [ms] (mean)
Đó quả là 1 sự hy sinh hơi lớn đúng không? Hy sinh 1 nửa performance chỉ để phục vụ việc đo đạc. Vì vậy nên mình không chấp nhận mà tiếp tục tìm cách tối ưu thêm. Sau quá trình test đi test lại vài tiếng đồng hồ (vụ tối ưu này mới lâu này) thì mình đã tìm ra thủ phạm khiến cho ứng dụng của mình phải hy sinh nhiều performance như vậy:
- Việc parse user-agent để phân loại request thường khá chậm do phải check qua nhiều loại regex khác nhau. (~1ms/op)
- Call
PFADDmặc dù có độ phức tạp O(1) và đã sử dụng redis pipeline (có tác dụng như bulk command) nhưng vẫn tiêu tốn rất nhiều tài nguyên và network. Thậm chí ảnh hưởng cả tới tốc độ của operation chính (cũng dùng redis)
Giờ hãy cùng phân tích xem chúng ta có thể làm gì với 2 vấn đề này.
Vấn đề đầu tiên là cải thiện tốc độ của việc parse user-agent. Xuất phát từ việc user agent của app hay web là lặp lại giữa các request của 1 user, thậm chí là giữa các user có thiết bị giống nhau. Do vậy mình đã nghĩ tới giải pháp cache in-memory, tức là dùng các biện pháp lưu trữ biến toàn cục để cache lại kết quả parse user agent.
Tất nhiên là mình không dở hơi mà đi tự nghĩ ra trò cache in-memory này. Trước giờ mình chỉ quen với dùng redis như 1 lớp cache. Bây giờ đến cả redis còn đang chậm vãi xoài thì đành phải kiếm cách khác. Thật tình cờ trong 1 buổi sáng lướt tin tức đâu đó thì mình đã đọc được 2 bài blog về các thư viện in-memory cache của Golang: The State of Caching in Go và Introducing Ristretto: A High-Performance Go Cache. Vậy là mình quyết định sử dụng ristretto. Quá trình benchmark của mình đều cho thấy mức độ sử dụng RAM ở mức thấp và tốc độ phản hồi ấn tượng. Done 1 việc.
Vấn đề thứ 2 là cải thiện luồng ghi thông tin vào redis bằng PFADD command. Với việc mỗi request tới hệ thống lại phải gọi 2 command trên thì khả năng connection tới redis làm chậm hệ thống đã xảy ra. Mình có đi research rất nhiều chỗ, rồi cả các list awesome này nọ nhưng cũng chưa nghĩ ra cách gì khả dĩ. Sau đó mình tạm gác nó lại để đi tìm hiểu vấn đề khác trước.
Nhưng đúng vào lúc mình đang tìm hiểu về khả năng thread-safe của thư viện redis trên golang thì có 1 comment trong issue đã khai sáng mình: https://github.com/go-redis/redis/issues/166#issuecomment-149360999.
Ý tưởng ở đây là sử dụng cơ chế giống như buffer / flush để xử lý. Mà ở đây là sử dụng 1 thư viện rất là cũ kỹ và còn được archive luôn của facebook là Muster để xử lý internal batching. Tức là những request tới redis sẽ được mình push vào 1 cái batch nội bộ process. Định kỳ 1s hoặc 10000 request thì mình sẽ flush cái batch nội bộ trên xuống redis bằng redis pipeline. Việc này tiết kiệm được rất rất nhiều tài nguyên và tránh làm nghẽn client redis của mình.
Wow, quả là 1 phát kiến đáng giá tới mức sững sờ. Mình đã thử implement chiếc thư viện trên và đây là kết quả:
------ Before implement ------
Requests per second: 17332.91 [#/sec] (mean)
Time per request: 5.515 [ms] (mean)
------ After implement #1 ------
Requests per second: 7644.02 [#/sec] (mean)
Time per request: 10.027 [ms] (mean)
------ After implement #2 ------
Requests per second: 16592.69 [#/sec] (mean)
Time per request: 6.027 [ms] (mean)
Tôi sẽ để đây và không nói gì cả.
Thành quả
Bỏ qua phần râu ria liên quan tới việc mình viết chiếc data exporter hay làm 1 cái graph grafana đơn giản với các metric:
- Concurrent Session (PEAK, SESSION, LIMIT) by (device type)
- Concurrent User (PEAK, SESSION, LIMIT) by (device type)
- User TOA (time on app) by (device type)
thì mình đã thành công trong việc implement việc đo CCU theo thời gian thực trên toàn hệ thống mà không làm ảnh hưởng quá nhiều tới hệ thống đang chạy. Phải không?
Kết luận
Đến đây, mình xin khép lại bài viết hết sức dài và mệt mỏi kể về 1 ngày chủ nhật hứng chí của mình. Rất cảm ơn các bạn đã kiên nhẫn theo chân mình tới đây. Mặc dù mình luôn bảo các bạn đừng làm theo mình nhưng nếu ai đó muốn thử sức thì hãy cứ thử nhé. Bởi vì mọi thứ mình học được trên đường đi đều bổ ích và có rất nhiều ứng dụng trong những project khác của mình.
Qua bài viết này mình rút ra 3 điều (nhắc lại):
- Reinvent the wheel đem lại cho bạn nhiều thứ nhưng chỉ khi bạn thực sự hiểu được mình đang làm gì.
- Khi gặp vấn đề quá khó giải quyết, hãy ma-ke-no (mặc kệ nó) và đi làm thứ khác. Rồi tự nhiên đáp án sẽ va thẳng vào mặt bạn trước khi bạn kịp trở tay.
- Công nghệ - 1 lần nữa - không giúp ứng dụng của bạn chạy nhanh hơn. Bạn mới là người làm điều đó.
Hết rồi.
All rights reserved
