@hungpv à là cái gì cần hiển thị và cần các sự kiện như click chuột vào thì cho vào thẻ div rồi qua css chỉnh cái position là absolute với z-index hả anh ơi?? thông cảm em mới biết làm web nên không rành lắm ạ.
@hmquan08011996
local.zone[count.index % length(local.zone)]--- nhờ bác giải thích giúp em phần này ạ.
Ngoài ra trường hợp mình có nhiều mtrg khác nhau thì việc apply biến vào ntn bác nhỉ. Vdu dev/test , uat và prod
Còn field injection thì cũng có một số hạn chế (reflection, không final được) nhưng cũng không rõ ràng. Nói chung là tùy team thích cách nào thôi, và dùng thống nhất trong project.
Mình hay dùng constructor inject cho tiện, chỉ cần viết private final ... và sử dụng @RequiredArgsConstructor của Lombok là đủ.

THẢO LUẬN
Cám ơn mọi thứ mà bạn chia sẻ. Rất hữu ích !!!
chắc chắn nha bác 🤣
Hic, hóng bác hoàn thiện seri TF ạ.
Hay bạn ơi
@hungpv à là cái gì cần hiển thị và cần các sự kiện như click chuột vào thì cho vào thẻ div rồi qua css chỉnh cái position là absolute với z-index hả anh ơi?? thông cảm em mới biết làm web nên không rành lắm ạ.
Theo thuật toán thì triết gia cuối cùng và triết gia đầu tiên cùng ưu tiên một chiếc đũa. Vậy quyết định vào đâu để biết ai lấy đũa trước ạ?
Em có làm theo anh. nhưng khi xong các bước rồi hôm sau đăng nhập lại thì bị như này : https://viblo.asia/q/cho-em-hoi-ve-dang-ky-tai-khoan-tren-aws-3vKjbzGkK2R
https://itzone.com.vn/en/article/import-csv-with-special-encoding-via-laravel-excel/ ổng dịch lại thôi =))
@hmquan08011996 cho mình hỏi react quill có thêm emoji ko tại mình thấy nó ko có nên mình mới ko chọn editor này
Oke ạ
trong quá trình build ofbiz mình không gặp lỗi như bạn. Nên mình cũng không rõ ràng
Phần build project trong Intelij của mình bị lỗi này mà mình không biết khắc phục kiểu gì Không biết trong lúc build bạn có gặp lỗi này không ạ?
Không biết trong lúc build bạn có gặp lỗi này không ạ?
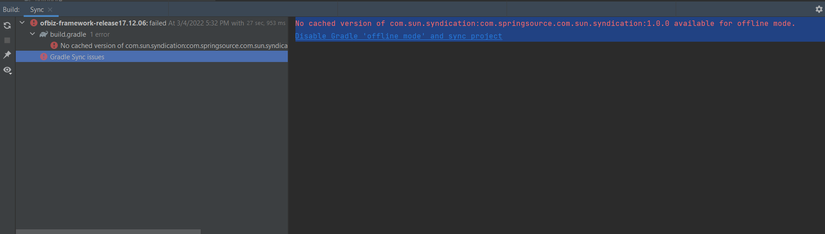
@HaiHaChan huhu goy bạn fix được chưa fix cho mình với
Bạn chạy câu lệnh gì mà gặp lỗi như trên vậy nhỉ?
Bạn thử chạy lệnh
apt install ca-certificatesxem saohttps://tkplaceholder.io/why-do-refs-have-a-key-named-current/
cần ghi nguồn
@hmquan08011996 tks bác đã giải thích chi tiết ạ .
chỗ này là chia lấy số dư nha bạn, để khi index nó lớn hơn length của local.zone thì nó sẽ quay lại từ đầu. Ví dụ:
Khi index nó lớn hơn 2. Nó sẽ quay lại:
Còn việc quản lý môi trường như dev/test/uat/pro thì mình sẽ dùng Terraform Workspace, bài này mình sẽ viết sau. Bạn có thể google trước để tìm hiểu
@hmquan08011996 local.zone[count.index % length(local.zone)]--- nhờ bác giải thích giúp em phần này ạ. Ngoài ra trường hợp mình có nhiều mtrg khác nhau thì việc apply biến vào ntn bác nhỉ. Vdu dev/test , uat và prod
Team Spring khuyên nên dùng constructor inject cho required bean và setter cho optional bean.
https://docs.spring.io/spring-framework/docs/current/reference/html/core.html#beans-dependencies
Còn field injection thì cũng có một số hạn chế (reflection, không final được) nhưng cũng không rõ ràng. Nói chung là tùy team thích cách nào thôi, và dùng thống nhất trong project.
Mình hay dùng constructor inject cho tiện, chỉ cần viết private final ... và sử dụng
@RequiredArgsConstructorcủa Lombok là đủ.