Công nghệ sóng não rất hữu ích và sẽ là tương lai của công nghệ, vì nó đi sâu vào bản chất của các giác quan, giúp người dùng trở nên tự chủ hơn, hiểu mình hơn. Mình muốn chia sẽ vài ý tưởng với tác giả, nếu có thể liên lạc. Emai của mình: vthung1990@gmail.com, cảm ơn.
vậy sao PV của em nó lại báo là gcepersistentdisk ta, em get storageclass cho anh xem thử. Và chạy câu lệnh minikube addons. Này có thể là lỗi của minikube thôi
"Mục tiêu của dự án GNU là tạo ra được một hệ điều hành miễn phí, giống Unix" đoạn này hơi sai đúng k nhỉ ? dù có 1 vài phiên bản miễn phí nhưng Unix là 1 os thương mại mà :v

THẢO LUẬN
bạn có thể giải thích chi tiết hơn phần Tuples Type
Test repository có cần phải tạo ra db để test không ạ?
Làm các phần tiếp theo đi chủ post ơi
công nhận bài viết của ô a hay thật =))
em thay bằng
hostpathnhé, do dưới local không xài mấy dạng lưu trữ của cloud được@devtdq1701 à, em xóa thuộc tính
gcePersistentDiskđi rồi tạo lại nhé@hmquan08011996 vẫn bị a ạ, file config của a có
gcePersistentDisknên nó tạo ra như vây ạ @@@maitrungduc1410 mình làm được rồi, cảm ơn bạn nhé
Công nghệ sóng não rất hữu ích và sẽ là tương lai của công nghệ, vì nó đi sâu vào bản chất của các giác quan, giúp người dùng trở nên tự chủ hơn, hiểu mình hơn. Mình muốn chia sẽ vài ý tưởng với tác giả, nếu có thể liên lạc. Emai của mình: vthung1990@gmail.com, cảm ơn.
1 vote.
ừm em, em disable rồi tạo lại thử xem
@hmquan08011996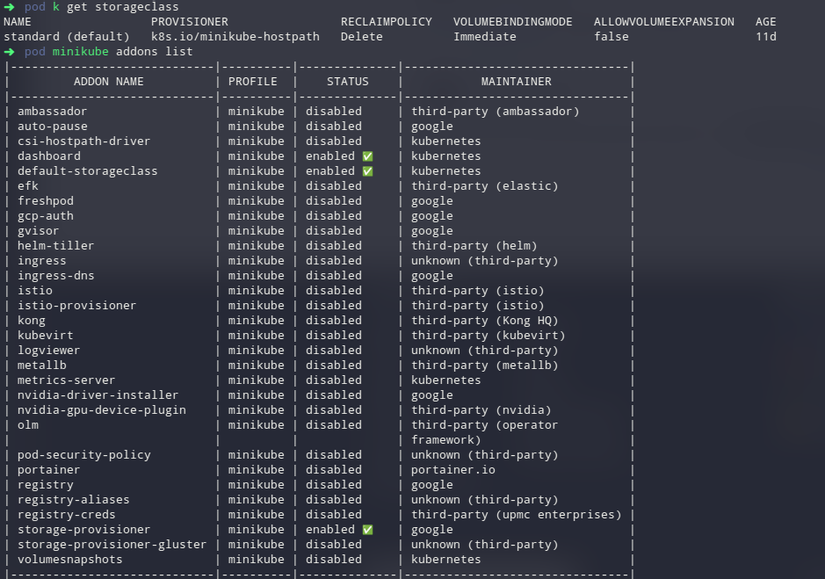 e thấy storage của gg enable, h mình disable là đc đúng k a
e thấy storage của gg enable, h mình disable là đc đúng k a
thanks
@bunny.pi.green Hay lắm bác :V
bài này bạn viết chi tiết quá Không biết phần 2 khi nào ra mắt nhỉ ;D
Mình theo dõi bạn đã lâu và thấy thật ngưỡng mộ bạn. Bạn có thể cho mình hỏi một số thông tin về visa được không ạ?
thông tin hữu ích, tks b
vậy sao PV của em nó lại báo là gcepersistentdisk ta, em get storageclass cho anh xem thử. Và chạy câu lệnh
minikube addons. Này có thể là lỗi của minikube thôi@hmquan08011996 k ạ, e chạy trên con laptop của e :v
"Mục tiêu của dự án GNU là tạo ra được một hệ điều hành miễn phí, giống Unix" đoạn này hơi sai đúng k nhỉ ? dù có 1 vài phiên bản miễn phí nhưng Unix là 1 os thương mại mà :v