
[Machine Learning] Sử dụng sóng não EEG để nhận biết và kiểm soát giấc ngủ của con người!
Bài đăng này đã không được cập nhật trong 7 năm
Lời mở đầu
- EEG classification - sử dụng sóng não EEG để nhận biết và kiểm soát giấc ngủ của con người.
Các nội dung sẽ được đề cập trong bài blog lần này
- EEG (Electroencephalography) là gì?
- 1 số lí thuyết cơ bản về EEG
- Bài toán Sleep-state classification
- Các hướng tiếp cận và luồng xử lí cơ bản khác
- Tiền xử lí dữ liệu (Data preprocessing)
- Trích rút đặc trưng (Feature Extraction)
- Chọn lọc đặc trưng (Feature Selection)
- Phân lớp (Classification)
- Kết quả
- Các khó khăn trong quá trình thực hiện
- Các hướng phát triển với dữ liệu EEG
- Kết luận
- Tài liệu tham khảo
EEG (Electroencephalography) là gì?!
- EEG - Electroencephalography (Electro + encephalography) hay điện não đồ là 1 hệ thống có khả năng ghi lại các xung điện được phát ra từ các neuron thần kinh, tiếp nhận qua vỏ não của con người. Tín hiệu này là phản hồi điện sinh học được tiếp nhận ngay tức khắc của tế bào não thông qua vỏ não. Là 1 trong những bộ phận phức tạp nhất trên cơ thể người, não người khi có các tác động từ các giác quan như: thị giác, thính giác, xúc giác, .v.v. sẽ sản sinh ra các tín hiệu điện rất nhỏ phản hồi lại và được trao đổi thông qua các neuron thần kinh. Việc tiến hành đo đạc EEG thường được thực hiện bằng cách gắn nhiều điện cực rải ráp xung quanh đầu, mỗi điện cực sẽ thu nhận được các xung điện tại từng khu vực riêng biệt, mỗi điện cực được coi như là 1 kênh (channel). Thường được thiết kế với mũ đội đầu gán điện cực như hình bên dưới:

1 số lí thuyết cơ bản
-
Tín hiệu điện của sóng não khá bé nên trước khi tiến hành lưu trữ thường được qua 1 bộ phận khuếch đại tín hiệu. Về cơ bản, dải tần của sóng não EEG thường nằm trong khoảng từ 0.5Hz - 40Hz và được chia nhỏ thành các loại sóng như sau:
- Sóng Delta (< 4Hz): là sóng với tần số thấp và biên độ cao, thường được phát hiện khi con người chìm vào giấc ngủ sâu.
- Sóng Theta (4-7Hz): cũng là sóng với biên độ khá thấp, thường được phát hiện khi con người ngủ.
- Sóng Alpha (8-15Hz): là loại sóng thường xuất hiện ở người trưởng thành, xuất hiện nhiều hơn tại phía sau vỏ não người. Thường xuất hiện khi con người thoải mái và nhắm mắt.
- Sóng Beta (16-31Hz): Xuất hiện đồng đều cả về độ tuổi và tần suất tại các vùng vỏ não. Là sóng với biên độ thấp nhưng tần số khá lớn, thường xuất hiện lúc con người đang tập trung suy nghĩ hay lo lắng cao độ.
- Sóng Gamma (> 32Hz): là sóng với tần số lớn nhất và biên độ thấp nhất, là loại sóng liên quan mật thiết tới các tác vụ cấp cao của con người như những chức năng của nhận thức. Sóng Gamma xuất hiện nhiều khi con người gặp stress, căng thẳng và thường được tìm thấy ở các thiên tài về hội họa, thi ca, .v.v.
- ...

-
Vì các điện cực được đặt rải ráp xung quanh đầu nên để cụ thể, mỗi channel đo tại 1 vùng riêng biệt sẽ có 1 quy ước đặt tên riêng. Trong thực tế, số lượng điện cực gán trên vỏ mũ không cố định, thông thường sẽ là 32 hoặc 64 channel, mỗi bản thiết kế điện cực sẽ có 1 tên riêng quy chuẩn và số lượng channel cũng khác nhau và được gọi chung là các montage. Ví dụ, với montage Standard 1005:

1 số ví dụ khác:
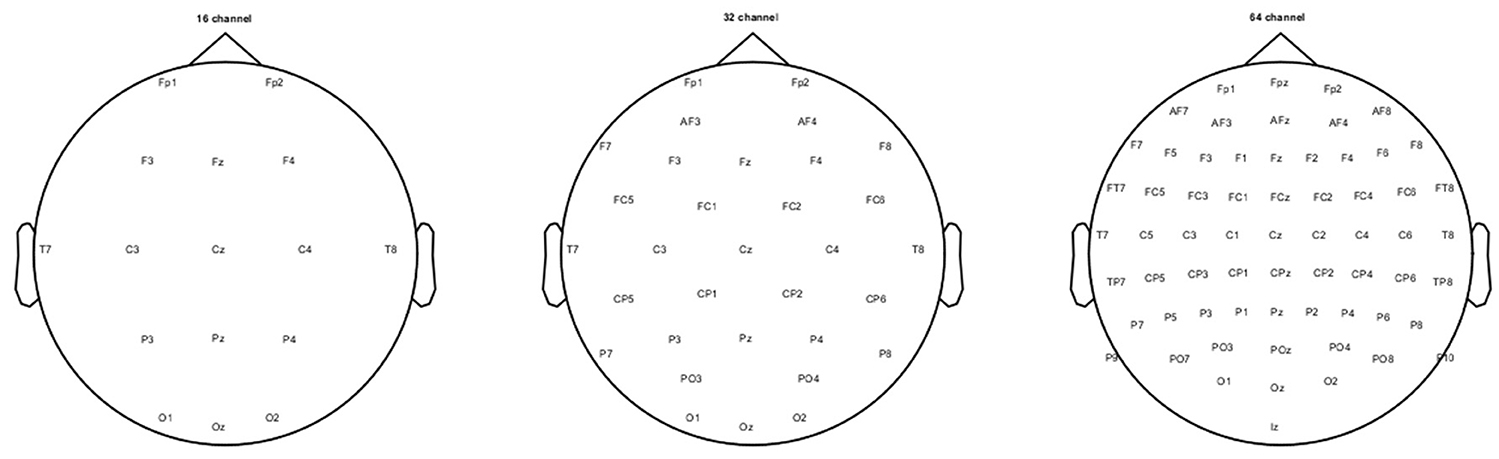
- Reference: mỗi điện cực đo xung điện đều dựa trên sự chênh lệch điện thế với 1 điểm gọi là reference. Việc chọn điểm reference tại đâu trên đầu cũng đều gây ảnh hưởng tới kết quả thu được của tín hiệu. Vậy nên, để thống nhất và tạo ra 1 quy chuẩn nhất định, tại các vị trí sau thường được chọn làm reference:
- 2 dái tai (earlobes)
- 2 xương chũm (mastoid bonds) - phần xương lồi lên ngay sau tai
- Đỉnh đầu (vertex)

-
Epochs: dữ liệu EEG được đo đạc và thu thập trong 1 khoảng thời gian liên tục và nhất định, tại mỗi điểm thời gian sẽ có tín hiệu điện não thu được tại mỗi điện cực. 1 Epoch được định nghĩa là tín hiệu thu được trong 1 khoảng thời gian nhất định. Ví dụ, tín hiệu với sampling rate là 100Hz đo trong 10s thu được 1 epochs với 100 x 10 = 1000 samples.

-
Evoked: đơn giản là trung bình giá trị của nhiều epoch trong 1 khoảng thời gian nhất định ứng với nhiều channels.

-
Đối với các bài toàn EEG classification sẽ có khá nhiều các cách tiếp cận để xử lí bài toán. Có thể xử lí bằng việc xây dựng các feature dạng time-domain, dạng frequency-domain hoặc cả 2 như time-frequency-domain, thậm chí dùng cả mạng CNN (với dữ liệu là ma trận thu được khi biến đổi tín hiệu EEG), ..v.v. Các công đoạn chính bao gồm:
- EDA & Data Preprocessing: khảo sát dữ liệu, visualize và tiền xử lí dữ liệu (lọc giới hạn miền tần số, giảm thiểu nhiễu, giảm thiểu các tín hiệu bên ngoài hay remove artifact như nhịp đập của tim, chớp mắt, ...)
- Feature Extraction: dữ liệu ban đầu gọi là raw data, sau khi được tiền xử lí cần thực hiện 1 số các thao tác để có thể trích rút các feature cụ thể, từ đó mô hình sau này sẽ dựa vào đó để "học" từ dữ liệu. Có khá nhiều các phương pháp về feature extraction với dữ liệu EEG nói riêng và dữ liệu về tín hiệu (signal) nói chung. 1 số từ khóa mình sẽ đề cập bên dưới như: time-domain, frequency-domain, time-frequency-domain, DFT và FFT (Fast Fourier Transform), Wavelet Transform, .v.v.
- Feature Selection: liên quan đến việc chọn lọc và giảm thiểu số lượng feature, 1 số khái niệm sẽ đề cập như: PCA, ICA, ..
- Classification: mô hình phân loại dựa trên các feature đã trích rút được bên trên, bất kì mô hình classification nào bạn cũng có thể thử và áp dụng: SVM, Tree-based model, CNN, ...
Bài toán Sleep-state classification
-
Dữ liệu mình sử dụng để demo là: Sleep-EDF. Về bước chuẩn bị dữ liệu, các bạn tham khảo thêm hướng dẫn tại đây: https://github.com/akaraspt/deepsleepnet#prepare-dataset
-
Source code: https://www.kaggle.com/phhasian0710/deepsleepnet-201708
-
Dữ liệu sleep-state gồm 5 class: W, N1, N2, N3 và REM, được hiểu như sau:
- W (Stage Wake): trạng thái con người tỉnh táo.
- N1 (Stage 1): giai đoạn bắt đầu của giấc ngủ hay ngủ nông, là giai đoạn chuyển tiếp giữa thức và ngủ, dễ bị gián đoạn và khó nhận biết.
- N2 (Stage 2): giai đoạn con người bắt đầu chìm vào trạng thái ngủ sâu, sóng não nhanh dần đều, nhiệt độ cơ thể giảm, nhịp tim chậm lại, nhận thức của con người với môi trường bên ngoài gần như không còn.
- N3 (Stage 3): giai đoạn ngủ sâu, con người ít có phản ứng với tiếng ồn và hoạt động bên ngoài. Nếu bị đánh thức đột ngột thì có thể sẽ mất vài phút để "định thần" lại

- REM (Rapid Eye Movement): trong kì này sẽ bắt đầu trong thời gian rất ngắn, cũng là lúc là giấc mơ xuất hiện. Là giai đoạn mà mắt sẽ chuyển động nhanh và liên tục, cơ bắp tê liệt; nhịp tim, hơi thở, nhiệt độ cơ thể không kiểm soát. Đôi khi, cũng xuất hiện hiện tượng "bóng đè" khi 1 người thức giấc ở trạng thái REM.
- Dữ liệu ban đầu gọi là raw data và cần được tiến hành tiền xử lí trước khi đưa vào model. Hiện tại, đối với data sleep state này chỉ có duy nhất 1 channel nên không cần phải tiền xử lí quá nhiều, 1 số bước cơ bản như: bandpass filter, scaling, ... Để thấy rõ sự hiệu quả của preprocess data, mình sẽ tiến hành training model 2 lần, 1 với raw data và 1 với preprocessed data.
X = np.zeros((0, 3000, 1))
y = []
for fn in total_fs:
samples = np.load(fn)
X_data = samples["x"]
X = np.concatenate((X, X_data), axis=0)
y.extend(samples["y"])
y = np.array(y)
# X.shape = (42308, 3000, 1)
# y.shape = (42308, )
- Thực hiện chia train, test, val:
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=42
)
X_train, X_val, y_train, y_val = train_test_split(
X_train,
y_train,
test_size=0.2,
random_state=42
)
# X_train.shape, X_test.shape, X_val.shape
# ((27076, 3000, 1), (8462, 3000, 1), (6770, 3000, 1))
- Thực hiện tiền xử lí dữ liệu, filter signal theo bandpass filter (lọc theo cận trên + cận dưới)
from scipy.signal import butter, lfilter
def butter_bandpass(lowcut, highpass, fs, order=4):
nyq = 0.5 * fs
# low = lowcut / nyq
high = highpass / nyq
b, a = butter(order, high, btype='highpass')
return b, a
def butter_bandpass_filter(data, highpass, fs, order=4):
b, a = butter_bandpass(0, highpass, fs, order=order)
y = lfilter(b, a, data)
return y
pp_X_train = np.array([butter_bandpass_filter(sample, highpass=40.0, fs=100, order=4) for sample in X_train])
pp_X_val = np.array([butter_bandpass_filter(sample, highpass=40.0, fs=100, order=4) for sample in X_val])
pp_X_test = np.array([butter_bandpass_filter(sample, highpass=40.0, fs=100, order=4) for sample in X_test])
- Ở đây mình sẽ xây dựng 1 mạng CNN để dùng cho bài toán sleep state classification gồm 5 class (W, N1, N2, N3, REM). Phần model mình sẽ dựa trên kiến trúc từ paper DeepSleepNet 2017. Đầu vào của model bao gồm 1 EEG signal được thu trong 30s, sampling rate = 100Fz. 2 nhánh CNN được sử dụng, 1 với filter nhỏ, 1 với filter lớn, đầu ra của 2 nhánh CNN được nối với nhau và đưa qua 2 lớp BiLSTM, cuối cùng là softmax layer với 5 nodes ứng với 5 class cần nhận diện.
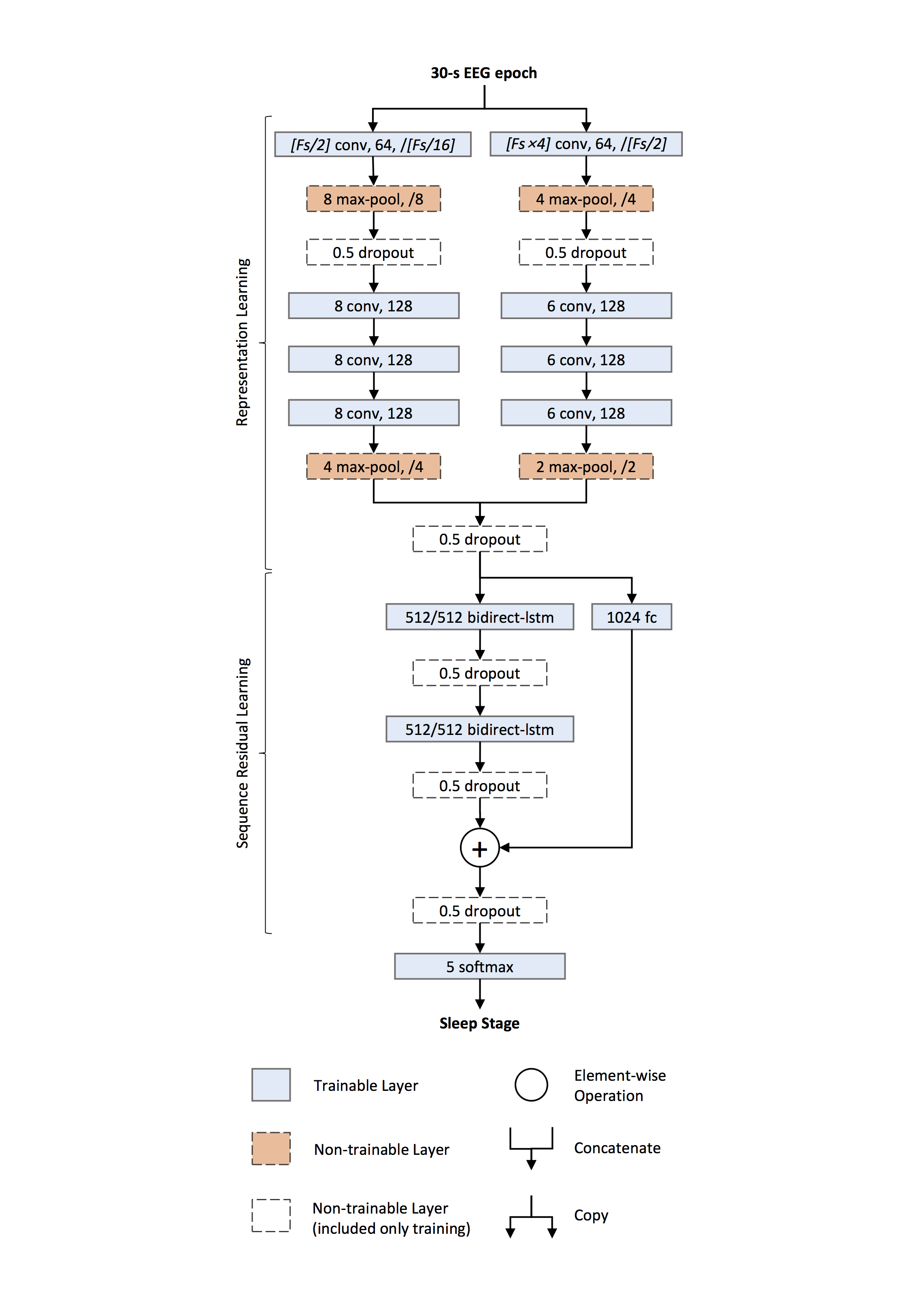
Model
def model_baseline_2017(n_classes=5, use_sub_layer=False, summary=True):
# two conv-nets in parallel for feature learning,
# one with fine resolution another with coarse resolution
# network to learn fine features
inputLayer = Input(shape=(3000, 1), name='inLayer')
convFine = Conv1D(filters=64, kernel_size=int(Fs/2), strides=int(Fs/16), padding='same', activation='relu', name='fConv1')(inputLayer)
convFine = MaxPool1D(pool_size=8, strides=8, name='fMaxP1')(convFine)
convFine = Dropout(rate=0.5, name='fDrop1')(convFine)
convFine = Conv1D(filters=128, kernel_size=8, padding='same', activation='relu', name='fConv2')(convFine)
convFine = Conv1D(filters=128, kernel_size=8, padding='same', activation='relu', name='fConv3')(convFine)
convFine = Conv1D(filters=128, kernel_size=8, padding='same', activation='relu', name='fConv4')(convFine)
convFine = MaxPool1D(pool_size=4, strides=4, name='fMaxP2')(convFine)
fineShape = convFine.get_shape()
convFine = Flatten(name='fFlat1')(convFine)
# network to learn coarse features
convCoarse = Conv1D(filters=32, kernel_size=Fs*4, strides=int(Fs/2), padding='same', activation='relu', name='cConv1')(inputLayer)
convCoarse = MaxPool1D(pool_size=4, strides=4, name='cMaxP1')(convCoarse)
convCoarse = Dropout(rate=0.5, name='cDrop1')(convCoarse)
convCoarse = Conv1D(filters=128, kernel_size=6, padding='same', activation='relu', name='cConv2')(convCoarse)
convCoarse = Conv1D(filters=128, kernel_size=6, padding='same', activation='relu', name='cConv3')(convCoarse)
convCoarse = Conv1D(filters=128, kernel_size=6, padding='same', activation='relu', name='cConv4')(convCoarse)
convCoarse = MaxPool1D(pool_size=2, strides=2, name='cMaxP2')(convCoarse)
coarseShape = convCoarse.get_shape()
convCoarse = Flatten(name='cFlat1')(convCoarse)
# concatenate coarse and fine cnns
mergeLayer = concatenate([convFine, convCoarse], name='merge_1')
outLayer = Dropout(rate=0.5, name='mDrop1')(mergeLayer)
if use_sub_layer:
sub_layer = Dense(1024, activation="relu", name='sub_layer')(outLayer)
# model = Model(inputLayer, mergeLayer)
# LSTM
outLayer = Reshape((1, int(fineShape[1]*fineShape[2] + coarseShape[1]*coarseShape[2])), name='reshape1')(outLayer)
outLayer = Bidirectional(LSTM(128, activation='relu', dropout=0.5, name='bLstm1'))(outLayer)
outLayer = Reshape((1, int(outLayer.get_shape()[1])))(outLayer)
outLayer = Bidirectional(LSTM(128, activation='relu', dropout=0.5, name='bLstm2'))(outLayer)
# merge out_layer and sub_layer
if use_sub_layer:
outLayer = concatenate([outLayer, sub_layer], name='merge_2')
outLayer = Dropout(rate=0.5, name='mDrop2')(outLayer)
outLayer = Dense(256, activation="relu", name='sub_layer_2')(outLayer)
outLayer = Dropout(rate=0.5, name='merge_out_sub')(outLayer)
# Classify
outLayer = Dense(n_classes, activation='softmax', name='outLayer')(outLayer)
model = Model(inputLayer, outLayer)
optimizer = keras.optimizers.Adam(lr=1e-4)
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['acc'])
if summary:
model.summary()
return model
model_2017 = model_baseline_2017(use_sub_layer=False, summary=True)
Reference: deepsleepnet & deepsleepnet-paper
- Calbacks:
checkpoint = ModelCheckpoint("model_cps", monitor='val_loss', verbose=1, save_best_only=True, mode='max')
early = EarlyStopping(monitor="val_loss", mode="max", patience=20, verbose=1)
redonplat = ReduceLROnPlateau(monitor="val_loss", mode="max", patience=5, verbose=2)
csv_logger = CSVLogger('log_training.csv', append=True, separator=',')
callbacks_list = [
checkpoint,
early,
redonplat,
csv_logger,
]
- Chuyển label sang dạng one-hot vector:
from tensorflow.keras.utils import to_categorical
y_train_ = to_categorical(y_train)
y_val_ = to_categorical(y_val)
y_test_ = to_categorical(y_test)
- Training model với raw_data
hist = model_2017.fit(
X_train, y_train_, batch_size=64, epochs=50, validation_data=(X_val, y_val_), callbacks=callbacks_list
t)
y_pred = model_2017.predict(X_test, batch_size=bs)
y_pred = np.array([np.argmax(s) for s in y_pred])
f1 = f1_score(y_test, y_pred, average="macro")
print(">>> f1 score: {}".format(f1))
report = classification_report(y_test, y_pred)
print(report)

- Vì số lượng samples giữa từng class không cân bằng nên ngoài accuracy, ta sử dụng thêm các metric khác như: presicion, recall và f1-score để đánh giá mô hình. Kết quả thu được với raw data:


- Training model với dữ liệu đã được preprocess:
model_2017 = model_baseline_2017()
hist2 = model_2017.fit(
pp_X_train, y_train_, batch_size=64, epochs=50, validation_data=(pp_X_val, y_val_), callbacks=callbacks_list
)
y_pred = model_2017.predict(pp_X_test, batch_size=bs)
y_pred = np.array([np.argmax(s) for s in y_pred])
f1 = f1_score(y_test, y_pred, average="macro")
print(">>> f1 score: {}".format(f1))
report = classification_report(y_test, y_pred)
print(report)

Có thể thấy là val_loss và val_acc của mô hình đã được cải thiện đáng kể so với bên trên
- Kết quả thu được với preprocessed data:


- Save model
model_2017.save_weights("model_2017.h5")
model_json = model_2017.to_json()
with open("eeg_model_2017_config.json", "w") as f:
f.write(model_json)
Kết quả
-
Dựa vào trạng thái ngủ, ta có thể có các biện pháp tác động từ bên ngoài để giúp con người ngủ ngon hơn và giảm căng thẳng, lo lắng.
-
Về bài toán sleep-state classification, có 1 điểm chú ý là dữ liệu giữa từng class thường không đều nhau (khá mất cân bằng) nên việc sử dụng accuracy không mạng lại nhiều ý nghĩa; bên cạnh đó, ta sử dụng thêm các metric thông dụng khác như: presicion, recall, f1-score, roc-auc.
-
Bên trên mình chỉ thực hiện chia train/test/val dữ liệu, kết quả đạt được cũng khá tốt. Các bạn có thể áp dụng thêm cross validation để mô hình có khả năng tổng quát hóa trên dữ liệu tốt hơn (generalization). Kết quả so với 1 số model hiện tại như:
- DeepSleepNet 2017: acc = 82.0%, f1-score = 76.9%
- SleepEEGNet 2019: acc = 84.26%, f1-score = 79.66%
-
Có thể thấy rằng, qua 2 lần training, precision / recall / f1-score của class N1 khá thấp so với các class khác. Điều này cũng đã được đề cập đến trong 2 paper bên trên, các bạn có thể tìm đọc thêm. Có thể cải thiện mô hình bằng cách kết hợp thêm nhiều các phương pháp feature extraction khác mà mình sẽ đề cập ngay bên dưới đây, bao gồm: preprocessing data, feature extraction, feature selection.
Các hướng tiếp cận khác của bài toán
1. Data Preprocessing
- Vì dữ liệu mình sử dụng trong bài blog lần này chỉ có 1channel duy nhất nên ít bị ảnh hưởng bởi các điều kiện ngoại cảnh hơn. Ngoài việc xử lí filter như:
- low-pass filter (thấp hơn thì lấy)
- high-pass filter (cao hơn thì lấy)
- band-pass fiter (lấy trong đoạn [a, b])
- north-filter (bỏ đi các sample tại 1 miền tần số xác định f)
thì còn 1 số các phương pháp xử lí khác như: remove noise, remove actifact. 1 vài phương pháp có thể kể đến như:
-
ICA (Independent Component Analysis)
-
SSP (Signal Subspace Projectors)
-
Wavelet Denoising
-
Hình ảnh 1 channel sau khi được xử lí loại bỏ artifact:
Reference: - https://cbrnr.github.io/2018/01/29/removing-eog-ica/ - https://martinos.org/mne/stable/auto_tutorials/plot_artifacts_detection.html - https://hal.sorbonne-universite.fr/hal-01757330/document
2. Feature Extraction
-
Mạng CNN bên trên mình sử dụng cũng có vai trò như 1 phương pháp feature extraction, tuy nhiên ngoài bước scaling và filter data thì model hiện tại như 1 hidden box vậy. Trước khi có sự can thiệp từ Deep Learning, rất nhiều các phương pháp về feature extraction khác cũng được đề xuất và khá phong phú về domain như:
- Time-domain
- Frequency-domain
- Time-frequency-domain
- CSP (Common Spatial Pattern) Techniques
-
Các phương pháp về Time-domain feature:
- Mean, median, variance, standard deviation, entropy, ...
- Hjorth Coefficients
- Autoregressive (AR)
- Correlation Dimension
- Hurst Coefficient
- Petrosian Fractal Dimension
- Power
- .v.v.
-
Frequency-domain
- Bandpower
- Spectral Entropy
- DFT & FFT: DFT (Discrete Fourier Transform) là 1 phương pháp chuyển dữ liệu từ dạng time-domain sang frequency-domain. Là 1 trong những phương pháp quen thuộc và được dùng nhiều trong xử lí tín hiệu nói chung. FFT (Fast Fourier Transform) là 1 cách đơn giản hóa biểu thức của DFT giúp tính nhanh hơn, giảm độ phức tạp từ xuống . Với giả định rằng bất kì 1 hàm non-linear nào cũng đều có thể
de-composethành tổng của các hàm sin với biên độ và tần số khác nhau.
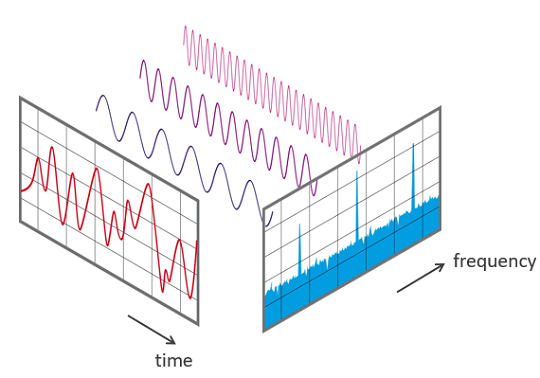
-
Time-frequency-domain
- STFT (Short-time Fourier Transform): là 1 phương pháp cải tiến hơn so với FFT. FFT có 1 nhược điểm đó là chỉ quan tâm đến frequency của dữ liệu mà bỏ qua time-domain. STFT cải thiện điều đó bằng cách chia epoch thành nhiều đoạn nhỏ hơn và tính FFT trên riêng từng đoạn.
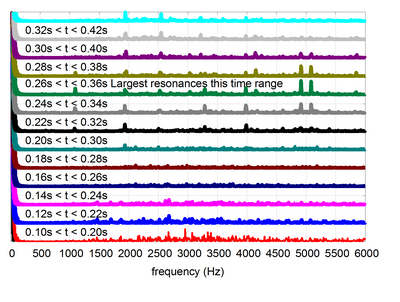
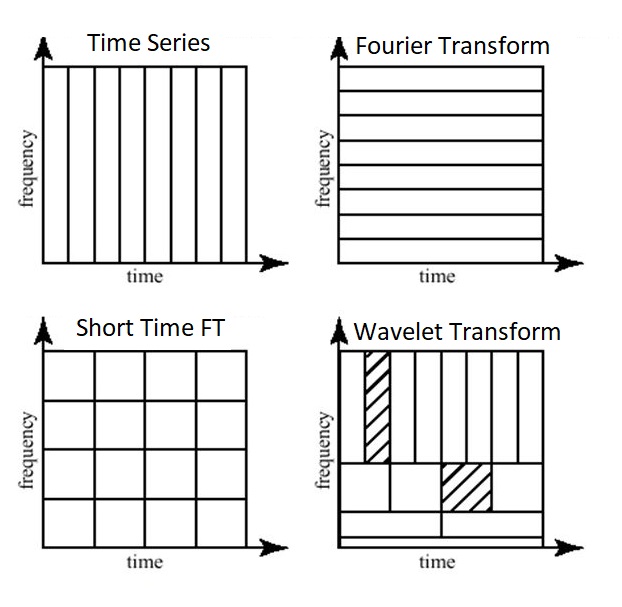
- Wavelet Transform và DWT (Discrete Wavelet Transform): nhược điểm của STFT là ta không biết được số đoạn cần chia để áp dụng FFT lên đó, việc cân đối giữa time-domain và frequency-domain là 1 điều không hề dễ dàng. Wavelet transform định nghĩa các hàm transform với các biên độ và tần số khác nhau nhưng giới hạn về độ dài, có tác dụng dùng để trích rút được các feature đặc trưng từ tín hiệu với từng hàm transform được sử dụng (tương tự như các filter trong mạng CNN vậy!). Các bạn có thể hiểu hơn về cách Wavelet hoạt động thông qua ảnh gif bên dưới:
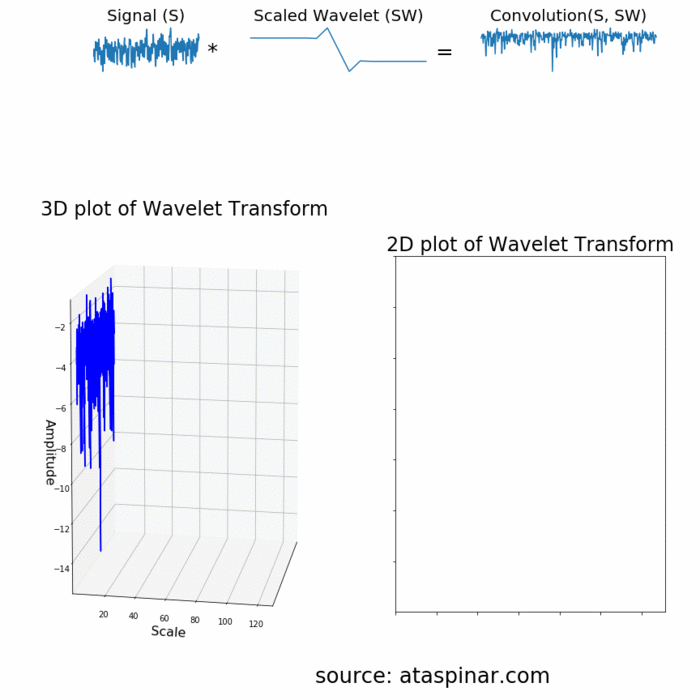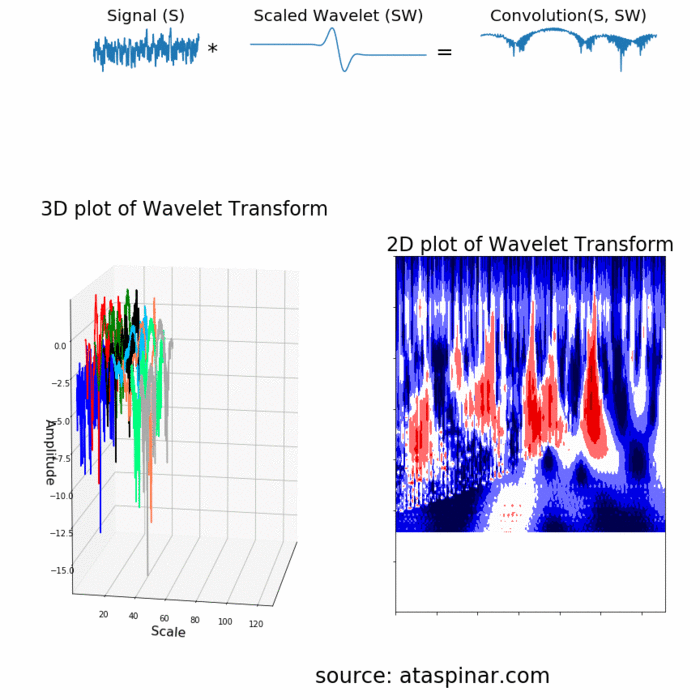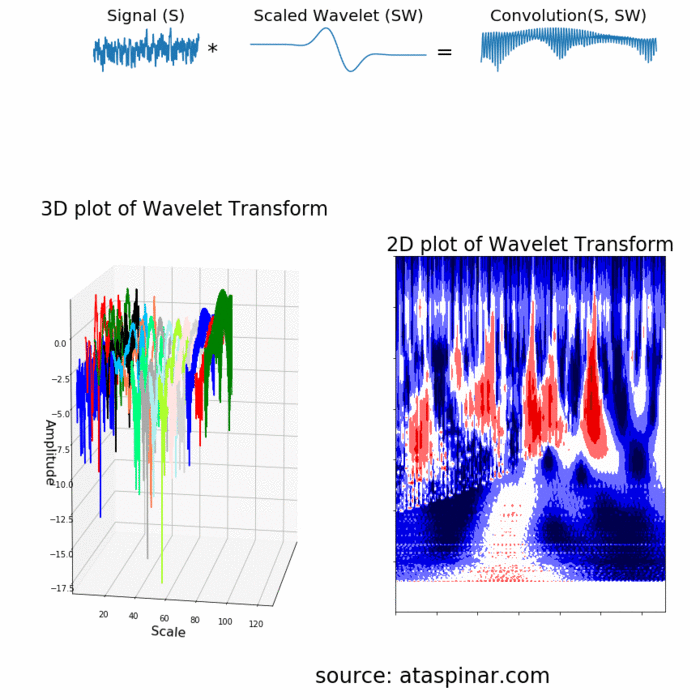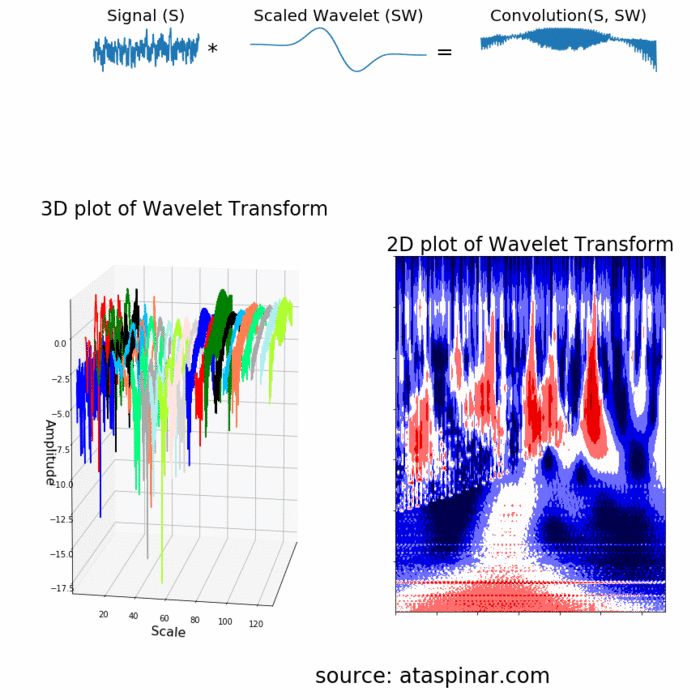
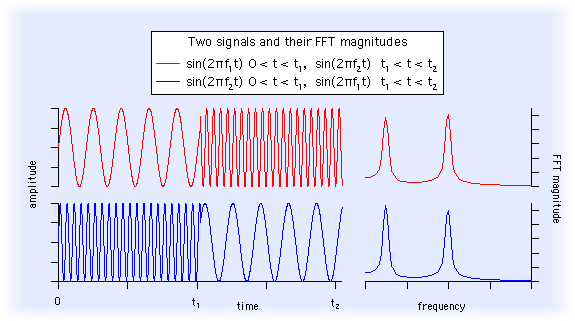
- 1 ví dụ khác để thấy được hạn chế của FFT lên tín hiệu, vì không quan tâm đến time-domain nên dù 2 tín hiệu nhìn "ngược nhau" nhưng đều trả về frequency feature tương tự nhau!
-
Common Spatial Pattern Techniques: là 1 trong các phương pháp về feature extraction phổ biến, thường được sử dụng trong bài toán EEG classification. Ý tưởng của CSP xuất phát từ việc những epochs khác nhau sẽ chứa các lượng thông tin khác nhau, và CSP được đưa vào với mục đích trích rút được feature từ các epoch mang nhiều thông tin đó; CSP biến đổi dữ liệu EEG sang 1 không gian mới với variance của 1 class cụ thể được tối đa hóa, còn variance của các class còn lại được giảm xuống.1 số biến thể khác của CSP bao gồm: CSSP, CSSSP, SBCSP, FPCSP, .v.v.

Reference CSP: https://martinos.org/mne/stable/auto_examples/decoding/plot_decoding_csp_eeg.html
Reference: - http://ataspinar.com/2018/12/21/a-guide-for-using-the-wavelet-transform-in-machine-learning/
- CNN: trong vài năm lại đây, với sự nở rộ của DL thì việc áp dụng DL vào DSP (Digital signal processing) ngày 1 phổ biến. Tiêu biểu nhất có lẽ là mạng CNN Wavenet của Google. Tùy thuộc vào dữ liệu (số lượng channel; dữ liệu đặc thù như EEG; ...) mà các mạng CNN được thiết kế với nhiều architech khác nhau, ví dụ:
- Mạng CNN thuần cho bài tóan classification
- RNN (LSTM)
- CNN + LSTM
- 2 CNN + LSTM (như mô hình mạng có đề cập bên trên)
- .v.v.
3. Feature Selection
-
Vì dữ liệu dạng signal là dạng dữ liệu liên tục, để xử lí thông thường ta sẽ chuyển từ digital signal sang analog signal (continoue signal --> discrete signal) để làm việc dễ dàng hơn. Tuy nhiên, số lượng samples thu được trong 1 thời gian vẫn khá lớn. Lấy ví dụ, tín hiệu EEG với 32 channels, sampling rate = 100, tiến hành xử lí 1 với 1 epoch = 30s thì số lượng samples cần xử lí = 100 * 30 * 32 = 96000 samples, 1 con số khá lớn chỉ với 1 epoch! Sau khi áp dụng các phương pháp feature extraction bên trên, ta có thể sử dụng thêm feature selection để giảm thiểu số lượng feature, giảm chi phí tính toán và chọn lọc ra các feature đặc trưng nhất. 1 vài phương pháp chú ý trong EEG như:
-
PCA (Principal Component Analysis) và ICA (Independent Component Analysis): PCA là 1 trong các giải thuật về linear dimension reduction và feature selection được sử dụng phổ biến nhất. Còn ICA là giải thuật non-linear dimension reduction và thường được kết hợp với wavelet transform để trích rút các spatial feature và time-frequency feature.
-
Filter Bank Selection: được sử dụng kèm các giải thuật về CSP (Common Spatial Pattern) bên trên.
-
Evolutionary Algorithms

Reference evolution algorithm: https://www.sciencedirect.com/science/article/pii/S0957417417305109?via%3Dihub
-

4. Classification
-
Rất nhiều các phương pháp về classification có thể áp dụng như: LDA, SVM, KNN, Naive Bayes, Tree-based, .v.v. Ngoài ra, cách tiếp cận với DL sử dụng các mạng neural quen thuộc như CNN, RNN (LSTM), Stack AutoEncoder, Deep Belief Networkds, .v.v. trong thời gian vài năm trở lại đây đạt được các kết quả khá tốt, thậm chí vượt trội hơn nhiều so với các phương pháp cổ điển. Việc thiết kế các mạng network cũng khá phong phú về ý tưởng: CNN + LSTM, CNN + Seq2Seq + Attention, Dilated CNN (Wavenet), .v.v.
-
Lấy ví dụ điển hình về việc sử dụng CNN cho bài toán classification. Với 1 tập dữ liệu đủ lớn, input của mạng CNN hoàn toàn có thể là raw data; CNN hoạt động như 1 hidden box và chúng ta khó có thể biết cụ thể trong đó tối ưu như thế nào với hàng triệu tham số. Bằng thực nghiệm như bên trên, ta thấy mô hình cho kết quả tốt hơn với dữ liệu preprocessed data. CNN thường được sử dụng trong các bài toán phân loại ảnh và hoạt động như 1 phương pháp feature extraction vậy.
-
Khi sử dụng CNN cho bài toán EEG classification, đầu vào của mạng network sẽ có 2 lựa chọn: 1 là biểu diễn EEG signal dưới dạng ảnh (matrix) hoặc raw data / preprocessed data:
- Với việc chuyển EEG signal sang dạng ảnh: sử dụng các time-frequency feature để thu được các ma trận 2 chiều thể hiện tương quan giữa time và frequency trên 1 hoặc nhiều channels. Các phương pháp điển hình đã đề cập bên trên như: STFT (Short time Fourier Transform), Wavelet Transform (CWT - Continuous Wavelet Transform), .v.v.
- Sử dụng raw data / preprocessed data làm đầu vào của CNN: ví dụ như mô hình 2CNN + LSTM được thiết kế bên trên. Bằng thực nghiệm đã cho thấy rằng CNN không chỉ hoạt động tốt với các dữ liệu dạng ảnh, mà còn có thể ứng dụng và đạt kết quả tương đương với các mạng RNN (LSTM) cho các bài toán như: text classification, signal classification, .v.v. Bằng việc sử dụng CNN 1D như 1 cửa sổ trượt, ta có thể trích rút ra được các thông tin quan trọng trong 1 epoch signal.
-
1 điểm mạnh nữa của CNN khi sử dụng cho các bài toán classification là thời gian training nhanh hơn rất nhiều so với RNN. Trong nhiều trường hợp, việc sử dụng CNN cho text classification, signal classification còn đem lại kết quả tốt hơn so với các mô hình RNN thông dụng như LSTM (GRU).
Các khó khăn trong quá trình thực hiện
-
Vấn đề annotate dữ liệu: dữ liệu sample về EEG có khá nhiều, các bạn có thể xem thêm tại: https://github.com/meagmohit/EEG-Datasets. Tuy nhiên, khi đối mặt với bài toán thực tế với yêu cầu cụ thể, việc annotate dữ liệu là 1 trong những công đoạn khó khăn và tốn thời gian nhất nếu không có domain về biometric. Các model architect hiện tại đã có khá nhiều, khâu quan trọng nhất luôn là việc chuẩn bị và tiền xử lí dữ liệu.
-
Xử lí nhiễu và loại bỏ antifact: data thực tế với nhiều channel thường bị ảnh hưởng bởi các điều kiện ngoại cảnh hoặc antifact như: nhịp tim đập, chớp mắt, .v.v. Nên việc loại bỏ và tách các thông tin không cần thiết cũng là 1 trong những công đoạn khi preprocessing data.
-
Multi-channel & single-channel với bài toán thực tế: Multi-channel hay single-channel thì đều gặp phải những khó khăn nhất định trong quá trình xây dựng mô hình. Với multi-channel là việc xử lí nhiễu, loại bỏ artifact, loại bỏ bad channel, ... Với single-channel là việc xử lí data synthesis, ensemble feature extraction techniques, ...
Các hướng phát triển với dữ liệu EEG
- Epileptic detection: dựa trên dữ liệu sóng não để chẩn đoán bệnh động kinh. Mình nghĩ đây là 1 bài toán khá hay và thực tế, hoàn toàn có thể đầu tư để nghiên cứu và phát triển thêm, giống như 1 số bài toán sử dụng CNN để chẩn đoán bệnh ung thư, ung thư vú chẳng hạn! Các bạn có thể tham khảo 1 số competition trên kaggle như:
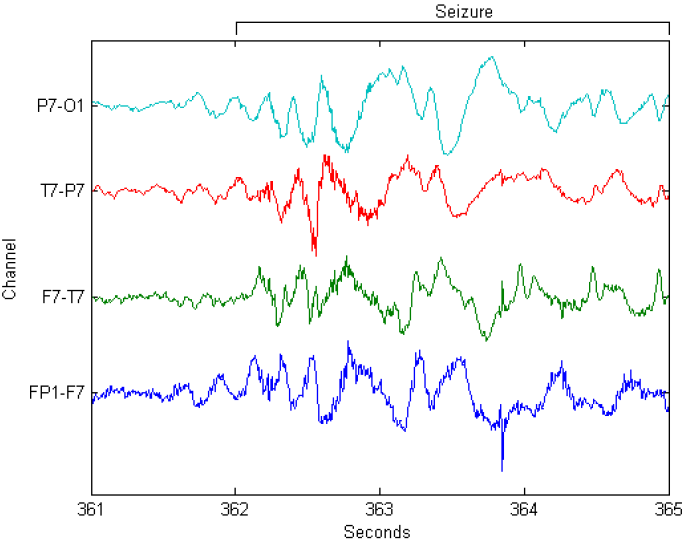
- EEG2Speech: hay chuyển đổi từ sóng não thành dữ liệu tiếng nói (hoặc text). Gần đây, 1 nhóm phát triển tại Nature đã phát triển 1 công nghệ có khả năng chuyển đổi từ brainwave sang dữ liệu tiếng nói, tuy rằng kết quả hiện tại chưa thực sự tốt nhưng đây cũng là 1 hướng phát triển "hẹp" trong tương lai, đặc biệt đối với các bệnh nhân mắc hội chứng về ngôn ngữ hoặc bị liệt, ..
- Emotion classification: dựa vào dữ liệu sóng để nhận biết các trạng thái vui vẻ, tập trung, căng thẳng, ... của con người.

- Sleep-state classification: như mô hình mình có đề cập trong bài blog này. Dựa trên dữ liệu sóng não thu được, từ đó nhận biết trạng thái ngủ của từng người để có biện pháp điều chỉnh cho phù hợp.

- Robotic: tương tự như cách mà nhà vật lí học Steven Hawking dùng các cơ gò má của mình để điều khiển con trỏ chuột, thao tác chọn các chữ cái trên màn hình, từ đó có thể giao tiếp với mọi người; chúng ta cũng hoàn toàn có thể sử dụng sóng não với cơ chế tương tự để giúp người bệnh trao đổi với thế giới bên ngoài, thậm chí thao tác nhờ 1 dụng cụ hỗ trợ! Nghe có vẻ bất khả thi và chỉ có trong các bộ phim viễn tưởng nhưng biết đâu 5, 10 năm sau thì lại hoàn toàn có thể trở thành hiện thực, nhất là trong thời đại công nghệ số như hiện nay.

Kết luận
-
Source code: https://www.kaggle.com/phhasian0710/deepsleepnet-201708
-
Vậy là mình cũng đã hoàn thành được bài blog khá dài này. Hi vọng mọi người sẽ có cái nhìn toàn diện về bài toán EEG classification và các hướng tiếp cận nói chung, từ preprocessing data, feature extraction, feature selection và classification method.
-
Cảm ơn các bạn đã đọc đến cuối bài viết, hãy upvote nếu thấy hữu ích và follow mình để chờ đợi các bài blog sắp tới nhé. Mọi ý kiến phản hồi, đóng góp vui lòng comment bên dưới hoặc gửi về mail: phan.huy.hoang@sun-asterisk.com.
Reference
-
EEG classification series:
All rights reserved
