Nếu bạn hiểu theo ý là "Kubernetes đã tuyên bố ngừng việc hỗ trợ docker hoàn toàn" hay kiểu khai tử thì chỗ đó sẽ không đúng, nhưng trong bài mình cũng có liên tục nhắc việc Kubernetes chỉ không support dockershim nữa. Kubernetes cũng khẳng định trong thời điểm hiện tại docker vẫn là 1 tool hữu dụng, ít có giải pháp thay thế cho nó. Dù sao cũng cám ơn bạn đã góp y
@longyu Bên mình dựa trên công nghệ của Heroku nên về cơ bản Heroku làm được gì gì Bizfly App Engine cũng làm được vậy nha! Cơ sở dữ liệu hay OneClick Services hiện cũng đang cho dùng miễn phí nha. Bạn cần hỗ trợ thêm có thể tạo ticket trên trang chủ hoặc liên hệ trực tiếp với mình qua Telegram @HoangViet12 cho tiện trao đổi nhé

THẢO LUẬN
"Tất tần tật" lộng ngôn.
kubenetesviết cho đúng làKubernetesnha. Viết sai chính tả nhiều quá, chú ý từ đúng làMySQL..."Giới hạn đến 2 CPU và 2GB RAM" --> Đây là 2 CPU (virtual) core (chứ không phải 2 CPU vật lý) https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/#resource-units-in-kubernetes . Hoặc viết đúng là 2 CPU unit.
Tiêu đề bài viết không phù hợp với nội dung bài viết. Chủ đề docker compose lại nói về Traefik.
@viet111 ,mình dùng fb,sao csdl phải xác thực,à sao lại bị lỗi 503 bad gateway
Nếu bạn hiểu theo ý là "Kubernetes đã tuyên bố ngừng việc hỗ trợ docker hoàn toàn" hay kiểu khai tử thì chỗ đó sẽ không đúng, nhưng trong bài mình cũng có liên tục nhắc việc Kubernetes chỉ không support dockershim nữa. Kubernetes cũng khẳng định trong thời điểm hiện tại docker vẫn là 1 tool hữu dụng, ít có giải pháp thay thế cho nó. Dù sao cũng cám ơn bạn đã góp y
@longyu Bên mình dựa trên công nghệ của Heroku nên về cơ bản Heroku làm được gì gì Bizfly App Engine cũng làm được vậy nha! Cơ sở dữ liệu hay OneClick Services hiện cũng đang cho dùng miễn phí nha. Bạn cần hỗ trợ thêm có thể tạo ticket trên trang chủ hoặc liên hệ trực tiếp với mình qua Telegram @HoangViet12 cho tiện trao đổi nhé
@NgocPH đã follow nhé
@minhtien1403 . Chào bro = ))))
"Kubernetes đã tuyên bố ngừng việc hỗ trợ docker từ những bản release tiếp theo. " --> chỗ này không đúng nha.
@Chloeyquiin t cũng dùng colab đấy bạn ạ
♥️
@viet111 ,cài django cũng được hả
@Honganh tớ dùng Google Colab free. Thông số môi trường của bạn là ntn? OS, versions..
Đúng cái mình đang tìm. Cảm ơn chia sẻ của bạn.
mính quên rổi,chiều kiểm tra,à chỉ thấy nó thông báo non exist access gì đó
@Chloeyquiin bạn restart lại kernel xem sao nhé t vẫn chạy ok ý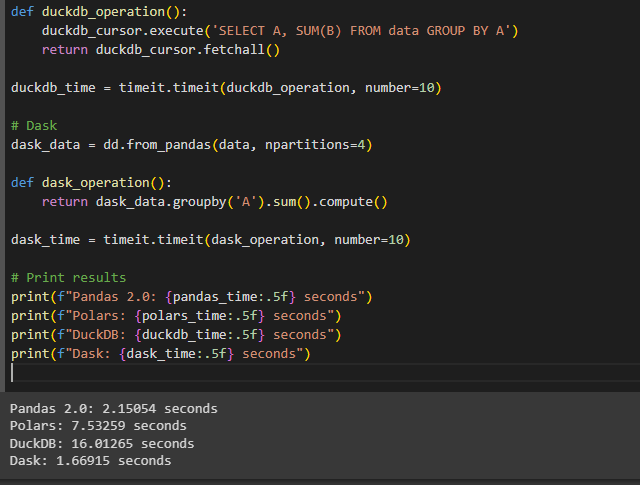
Bạn có code demo của cả 2 phần không ? Share mình với. Thanks
Mình làm theo hướng dẫn mà bên gateway truy cập upstream vẫn 404 nhỉ ?