Nhìn con game quen quen, hình như hôm nọ bác khoe trên mấy group dev hay sao nhỉ xD Cố gắng duy trì đam mê nhé bác, em cũng tính học thêm các mảng khác mà giờ đang đợt cao điểm, khách yêu cầu nhiều task quá chưa có thời gian mò tử tế.
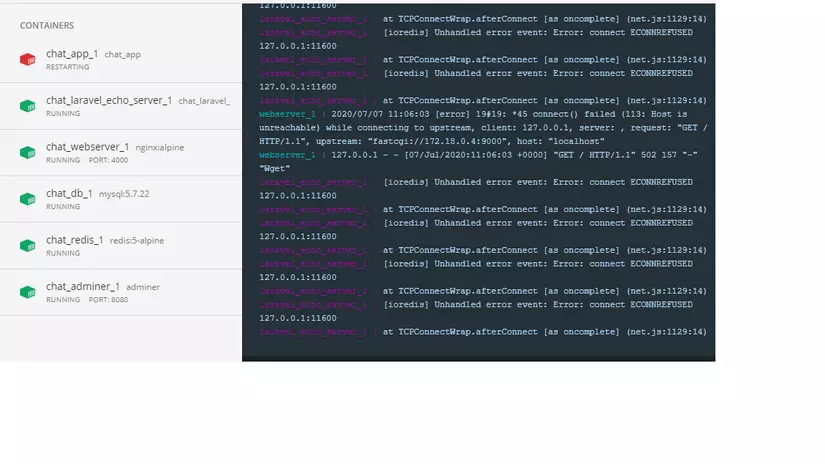
hiện tại hình như bạn đang dùng Docker thông qua 1 phần mềm nào đó, và như mình thấy lỗi trên hình thì laravel-echo-server đang không kết nối được tới redis (ERRCONNREFUSED)
Bạn nên check lại tool bạn dùng ở phần cấu hình thông số cho đúng nhé
Hi, Cảm ơn bạn đã comment. mình trả lời comment của bạn như sau:
attachToRoot là 1 biến để quyết định view đang được inflate có được add vào viewgroup luôn không. chứ k phải là do Listview không phải 1 ViewGroup nhé bạn. Nếu bạn decompile code của ListView bạn sẽ thấy listview thật ra cũng là 1 ViewGroup như bên dưới :
class ListView extends AbsListView
sau đó AbsListView extends AdapterView
và cuối cùng AdapterView<T extends Adapter> extends ViewGroup
Nhưng phương thức addView của nó định nghĩa không support addView bằng cách throw ra 1 RuntimeException như thế này
public void addView(View child) {
throw new RuntimeException("Stub!");
}
mình đang thắc mắc là thằng laravel-echo-server nó config cái url kiểu gì
ở dưới local thì tự động lấy localhost:6001 thế sau khi deloy lên server thì có cần config lại thành domain:6001 không hay là nó tự động hiểu ??@@

THẢO LUẬN
Ở dưới phía client mình có config 1 đoạn để kết nối với domain luôn rồi đó
Nhìn con game quen quen, hình như hôm nọ bác khoe trên mấy group dev hay sao nhỉ xD Cố gắng duy trì đam mê nhé bác, em cũng tính học thêm các mảng khác mà giờ đang đợt cao điểm, khách yêu cầu nhiều task quá chưa có thời gian mò tử tế.
hiện tại hình như bạn đang dùng Docker thông qua 1 phần mềm nào đó, và như mình thấy lỗi trên hình thì laravel-echo-server đang không kết nối được tới redis (ERRCONNREFUSED)
Bạn nên check lại tool bạn dùng ở phần cấu hình thông số cho đúng nhé
Cảm ơn tác giả, mình sẽ check lại

(nguongmo)
bài viết phải rõ ràng, dễ hiểu như thế này chứ! tks bro
Hello b minh ko start duoc service b xem giup minh loi nay bi sao nhi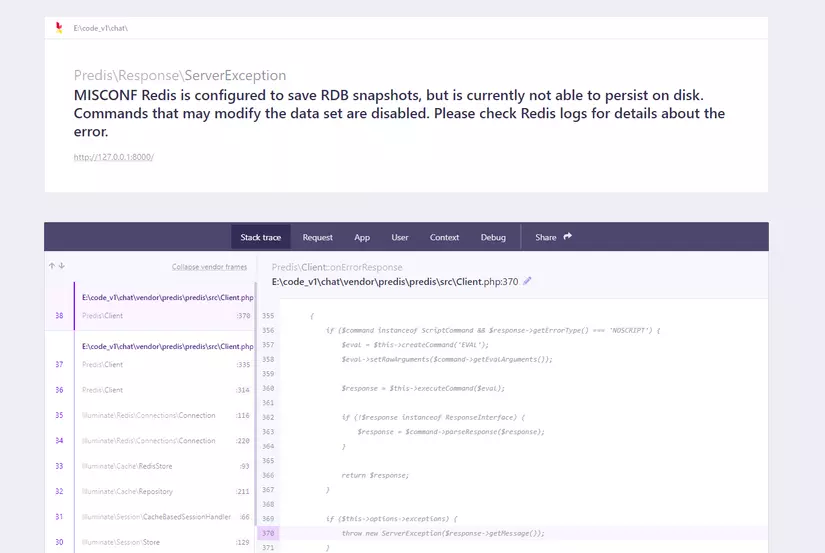
post hay quá cảm ơn b nhiều nhaa
Mình k muốn viết dài nhưng nó phải dài như vậy
Dài, lười đọc, nhưng chắc là hay và bổ ích. +1
Thanks bạn mình đã edit rồi nha


Dòng này chưa xử lý bạn ơi : $userCurrent = Auth::user();
Hi, Cảm ơn bạn đã comment. mình trả lời comment của bạn như sau: attachToRoot là 1 biến để quyết định view đang được inflate có được add vào viewgroup luôn không. chứ k phải là do Listview không phải 1 ViewGroup nhé bạn. Nếu bạn decompile code của ListView bạn sẽ thấy listview thật ra cũng là 1 ViewGroup như bên dưới : class ListView extends AbsListView sau đó AbsListView extends AdapterView và cuối cùng AdapterView<T extends Adapter> extends ViewGroup Nhưng phương thức addView của nó định nghĩa không support addView bằng cách throw ra 1 RuntimeException như thế này public void addView(View child) { throw new RuntimeException("Stub!"); }
thêm key connection vào nhé bạn
Gudboi


Bài viết rất chi tiết bạn Hoàn à,
Mình cũng đã phần nào hiểu Docker là gì rồi.
mình đang thắc mắc là thằng laravel-echo-server nó config cái url kiểu gì ở dưới local thì tự động lấy localhost:6001 thế sau khi deloy lên server thì có cần config lại thành domain:6001 không hay là nó tự động hiểu ??@@
@dao.thai.son điểm chưa tốt là gì bạn? và tốt hơn thì phải làm sao?