Hi bạn, hi mọi người, khi dùng thử số điện thoại nước ngoài Mobilephone và Vinaphone không nhận được OTP, vậy làm sao để giải quyết vấn đề, có phải mua 1 số Việt Nam.
UserDefaults: Được lưu trữ như một theo dạng key-value, như bạn nhìn ở view file info.plist >> rất dễ để đọc hiểu và sửa.
Bạn có thể dụng phần mềm thứ 3 ví dụ như IExplorer để chọc vào xem.
KeyChain thì dùng để lưu trữ các sensetive data như đã nói ở bài viết, nó được lưu trữ và mã hoá bởi. cơ chế của Apple. Data lưu trữ trong Keychain access thì có thể truy cập accross giữa các ứng dụng (cái này mình đọc được thôi, chứ chưa thử truy cập)
Trường hợp mình test Sampler là HTTP Request và server name là localhost thì có cấu hình gì thêm không bạn? Mình chạy mà cứ trả về 404 Not Found. Nhưng link test chạy trên trình duyệt thì được.

THẢO LUẬN
@cknguyen Thanks b
Bài viết hay quá, Hóng phần 2
Khá hay, mãi mới thấy bạn ra thêm bài về Speech
Hi bạn, hi mọi người, khi dùng thử số điện thoại nước ngoài Mobilephone và Vinaphone không nhận được OTP, vậy làm sao để giải quyết vấn đề, có phải mua 1 số Việt Nam.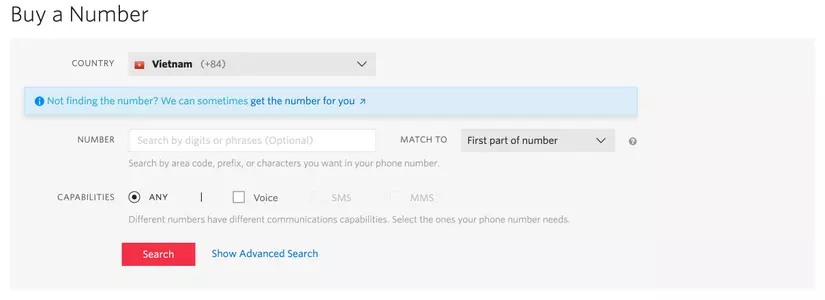
Bài viết quá hay, quá cảm động, cảm ơn bạn đã chia sẻ.
recommend các bạn kênh lập trình thật kỳ diệu, chuyên về angular nhé.
Oh yeah, có kênh của mình luôn. Cám ơn chủ thớt nhé
Mình xin lỗi nhưng tác giả bài viết này dùng Google Translate ạ ? Nhiều chỗ cứ ngợ ngợ thế nào ấy
Cái này mình thử từ trước rồi không được bạn ạ , cảm ơn bạn nhé
, cảm ơn bạn nhé
Vẫn theo dõi F8 ,hướng dẫn bài bản thật sự
e cảm ơn ạ
Chào bạn, theo mình tìm hiểu thì
Mong là nó đủ clear, còn đây là references: https://fluffy.es/persist-data/
@tnanhpt hi bạn,
đây là demo project ở đó mình đã setup pipeline có cache cả node_modules và cả docker image: https://gitlab.com/maitrungduc1410/gitlab-ci-docker.
Bạn xem job build docker image gần nhất của mình ở đây: https://gitlab.com/maitrungduc1410/gitlab-ci-docker/-/jobs/1176509961, ở đó nó pull image về nếu trước đó đã build để làm cache, sau đó build image mới với
--cache-fromthì toàn bộ dùng cache hết.(Job docker trước đó thì ko đc cache docker image nên nó phải build image từ đầu: https://gitlab.com/maitrungduc1410/gitlab-ci-docker/-/jobs/1176449579)
f8 người mới học dễ hiểu hơn, còn mấy kênh kia chủ yếu phải có ít kiến thức
Tất nhiên là có cho vào đẹp CV, giúp bạn qua vòng hồ sơ, còn chính vẫn là kiến thức lúc phỏng vấn
Những chứng chỉ trên Coursera có giúp ích nhiều trong việc tìm kiếm việc làm không bạn ?
cảm ơn anh đã chia sẻ
@phan.van.nhat em cam on anh nhieu a
Trường hợp mình test Sampler là HTTP Request và server name là localhost thì có cấu hình gì thêm không bạn? Mình chạy mà cứ trả về 404 Not Found. Nhưng link test chạy trên trình duyệt thì được.