Text to speech with Tacotron 2
Bài đăng này đã không được cập nhật trong 5 năm

1. Sơ lược về Text-to-Speech
Text to Speech (TTS), hay speech synthesis - tổng hợp tiếng nói là các phương pháp chuyển đổi từ văn bản (text) sang giọng nói - dạng như giọng nói của google translate vậy. Chủ đề này đã được nghiên cứu và sử dụng từ những năm 60 của thế kỉ trước. Những ngày đầu, các hệ thống speech synthesis thường được xây dựng theo cách sau:
- Thu âm từng âm tiết và lưu vào trong database thành 1 tập các audio
- Tiền xử lí văn bản -> tách từ, âm vị -> xác định và tìm các đoạn audio chứa âm tương ứng trong database
- Ghép các audio, hậu xử lí, tạo ra 1 đoạn tiếng nói hoàn chỉnh
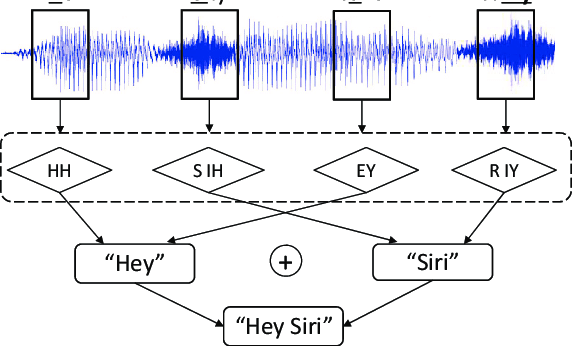
Nguồn ảnh: DolphinAtack_Inaudible_Voice_Commands
Với cách xây dựng này, giọng nói được tạo ra có chất lượng kém, mang tính "máy móc", đều đều và không có ngữ điệu giống như người. Hơn nữa, hệ thống kiểu này phụ thuộc quá nhiều vào việc chuẩn bị dữ liệu ghi âm.
Gần đây, deep learning đã đạt được rất nhiều thành tựu trong nhiều lĩnh vực, trong đó có lĩnh vực tổng hợp tiếng nói. Với sự ra đời của một loạt các mô hình, thuật toán như Deep Voice, Nuance TTS, WaveNet, Tacotron, Tacotron2... giọng nói sinh ra đạt được chất lượng rất tốt, có ngữ điệu và cảm xúc, người nghe khó phân biệt giọng nói đó có phải người thật hay không.
Trong bài viết hôm nay, mình sẽ viết về Tacotron2 - một phiên bản cải tiến, đơn giản hóa của Tacotron. Tacotron và tacotron2 đều do Google public cho cộng đồng, là SOTA trong lĩnh vực tổng hợp tiếng nói.
2. Kiến trúc tacotron 2
2.1 Mel spectrogram
Trước khi đi vào chi tiết kiến trúc tacotron/tacotron2, bạn cần đọc một chút về mel spectrogram. Trong lĩnh vực xử lí âm thanh và tiếng nói, thay vì xử lí trực tiếp data ở dạng sóng theo miền thời gian (1 chuỗi rất dài), ta sẽ chuyển âm thanh về miền tần số dạng như Spectrogram, Mel spectrogram, Mel Cepstrum, MFCC... Để hiểu rõ hơn, hãy đọc lại một chút kiến thức trong phần 2 Speech p2 - Feature extraction MFCC. Dưới đây là một minh họa về Spectrogram của một đoạn âm thanh:
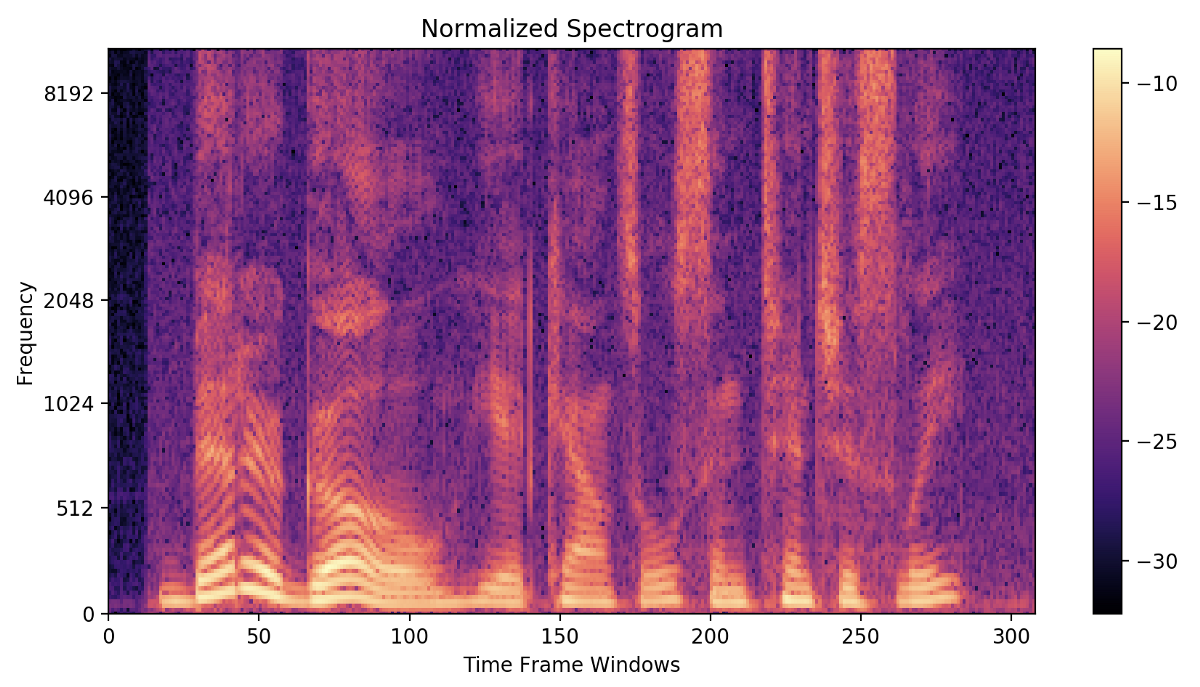
Nguồn ảnh: medium.com
Về cơ bản, quy trình biến đổi âm thanh từ time-domain sang frequency-domain theo các bước sau:
- Chia sóng âm dạng waveform thành 1 tập các đoạn ngắn (~25ms)
- Trên mỗi đoạn âm thanh đó, biến đổi DCT / FFT để tính ra 1 dãy N magnitude (cường độ) tương ứng với N tần số. (ngoài ra 1 dãy N phase (pha) nhưng phần này thường không dùng tới). Hai bước này được gọi là STFT - Short time furier transform.
- Như vậy, ta thu được data ở dạng spectrogram có dimension = 2. Chiều ngang là trục thời gian, chiều dọc là tần số, giá trị từng điểm được biểu thị bằng màu sắc - là cường độ tần số tương ứng.
- Do độ cảm nhận của tai người là non-linear (phi tuyến tính), người ta dùng các bộ lọc mel filter bank để biến đổi từ spectrogram sang mel-spectrogram.
Về cơ bản, data âm thanh ở dạng spectrogram, MFCC... khá tương tự ảnh. Trong nhiều bài toán deep learning, ta có dùng các Convolution layer để trích xuất đặc trưng tương tự khi áp dụng với dữ liệu ảnh.
2.2 Kiến trúc
Về cơ bản, tacotron và tacotron2 khá giống nhau, đều chia kiến trúc thành 2 phần riêng biệt:
- Phần 1: Spectrogram Prediction Network - được dùng để chuyển đổi chuỗi kí tự (text) sang dạng mel-spectrogram ở frequency-domain
- Phần 2: Vocoder - Biến đổi âm thanh từ mel-spectrogram (frequency-domain) sang waveform (time-domain)
Nếu bạn thắc mắc tại sao phải chia làm 2 phần như vậy, câu trả lời rất đơn giản: 1s âm thanh ở time-domain là 1 chuỗi 16000 số. Nếu model muốn inference trực tiếp ra 1s âm thanh thì model cần 16000 step cho LSTM/GRU ... Trong khi đó, trước khi tacotron ra đời, người ta đã tìm ra giải pháp biến đổi từ spectrogram sang waveform với chất lượng tốt rồi.
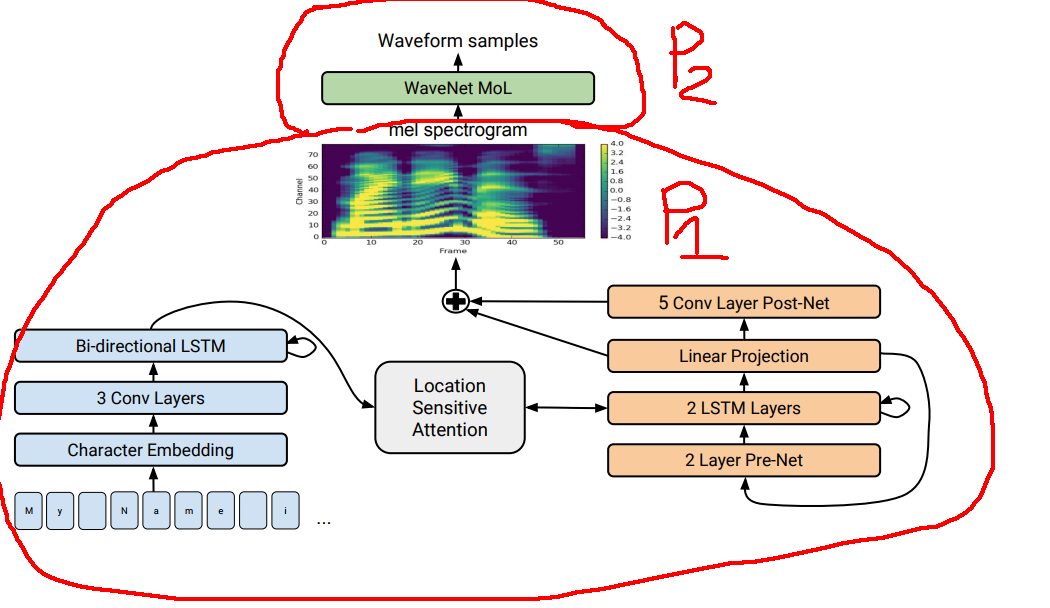
2.2.1 Spectrogram Prediction Network
Kiến trúc của Spectrogram Prediction Network khá đơn giản, theo kiến trúc Encoder-Decoder. Encoder và Decoder được kết nối với nhau bằng Location Sensitive Attention.
Encoder:
- Input đầu vào được tách và mã hóa (onehot encode) ở mức kí tự
- Thêm 1 layer Character Embedding dạng Lookup table đơn giản
- Thêm 3 layer Convolution
- Thêm Bi-directional LSTM (LSTM 2 chiều).
Decoder:
- Pre-Net - bản chất là 2 fully-connected layer được dùng để lọc thông tin từ step ngay trước đó.
- 2LSTM - lấy thông tin từ Encoder thông qua Attention, kết hợp với thông tin từ step ngay trước thông qua Pre-Net.
- Linear projection - một linear layer dùng để predict ra mel spectrogram
- Post Net: 5 convolution layer được thêm vào với mục đích lọc nhiễu trên mel spectrogram
Như vậy, output của Linear Projection và PostNet được kết hợp để tạo ra target mel spectrogram.
Loss function được dùng trong paper là MSE
2.2.2 Vocoder - WaveNet
Vocoder - hiểu đơn giản là bộ phát âm, được dùng để biến đổi dữ liệu từ định dạng Mel-spectrogram sang waveform (miền thời gian) mà con người có thể nghe được.
Như mình đã nói, âm thanh dạng waveform sau khi biến đổi STFT (Short time furier transform), ta tách thành 2 loại thông tin: magnitude và phase (cường độ và pha). Spectrogram chỉ là thông tin về magnitude. Điều đó đồng nghĩa với việc cần cả magnitude và phase mới có thể khôi phục lại âm thanh ban đầu. Như vậy, spectrogram mà model trả ra chưa đủ để phục dựng lại âm thanh dạng waveform.
Trước đây, tacotron sử dụng thuật toán Griffin-Lim để ước lượng ra phase dựa vào spectrogram. Sau đó khôi phục lại âm thanh dựa vào spectrogram (magnitude) và phase. Tuy nhiên cách này cho chất lượng âm thanh chưa hoàn hảo, âm thanh không trong, đôi khi xuất hiện nhiều nhiễu.

Nguồn ảnh: deepmind.com
Trong tacotron2, nhóm tác giả đã tận dụng WaveNet - mô hình sinh âm thanh được nghiên cứu trước đó vài năm (và tất nhiên vẫn là của Google). WaveNet hoạt động dựa trên các dilation convolution. Nhìn vào hình minh họa, bạn có thể thấy rằng 1 điểm dữ liệu được sinh ra dựa trên các điểm dữ liệu trong quá khứ. Và với dilation convolution, phạm vi bao phủ được trải rộng ra hơn rất nhiều so với convolution thông thường. Để tránh dông dài và lạc đề, nếu bạn muốn đọc về WaveNet, hãy đọc tại deepmind.com/wavenet.
WaveNet nguyên bản là loại non-conditional network, tức không nhận input nào mà chỉ sinh ngẫu nhiên các đoạn âm thanh vô nghĩa. Tuy nhiên trong Tacotron2, nhóm tác giả sử dụng a modified version of WaveNet which generates time-domain waveform samples conditioned on the mel spectrogram. Tức WaveNet được thiết kế để nhận input là dạng mel spectrogram, output ra waveform tương ứng.
Sau này, khi implement thuật toán, nhiều người đã thay thế wavenet bằng các model tương tự. VD phiên bản của NVIDIA sử dụng WaveGlow - một phiên bản cải tiến được đánh giá tốt và nhanh hơn WaveNet
3. Một vài thông tin hữu ích
Trong bài viết này mình không hướng dẫn implement thuật toán (vì thực tế tốn rất nhiều công sức). Tuy nhiên, bạn có thể đọc bài viết ung-dung-deep-learning-sinh-ra-audio-truyen-ma-khong-lo của anh Phạm Văn Toàn. Bài viết có hướng dẫn bạn ứng dụng open source code của NVIDIA
Có nhiều phiên bản implement của Tacotron2, trong đó bản NVIDIA/tacotron2 và Rayhane-mamah/Tacotron-2 được đánh giá cao và sử dụng rộng rãi.
Sau tacotron2, có khá nhiều bản cải tiến, sửa đổi, áp dụng một vài kĩ thuật mới...Tính tới thời điểm hiện tại, có thể tacotron2 không còn là thuật toán tốt nhất nữa. Tuy nhiên tacotron và tacotron2 vẫn là nền tảng chính của các thuật toán SOTA hiện nay.
4. Tham khảo
https://arxiv.org/pdf/1712.05884.pdf
https://deepmind.com/blog/article/wavenet-generative-model-raw-audio
https://medium.com/spoontech/tacotron2-voice-synthesis-model-explanation-experiments-21851442a63c
Cảm ơn bạn đã đón đọc, hẹn gặp lại ở những bài tới !
All rights reserved
