Xây dựng sentence matrix biểu diễn cho câu, đoạn văn tiếng Nhật
Bài đăng này đã không được cập nhật trong 6 năm
Đối với các bài toán xử lý ngôn ngữ tự nhiên, việc biểu diễn các từ ngữ thành vector tương ứng là một công đoạn rất quan trọng, ảnh hưởng trực tiếp đến kết quả của bài toán.
Trong bài viết này, mình xin chia sẻ một số vấn đề liên quan quan đến word embedding cho một ngôn ngữ, cụ thể là việc xây dựng ma trận biểu diễn cho câu từ tiếng Nhật.
Tổng quan, có 3 phần mình đề cập tới:
- Sơ lược về word embedding và word2vec
- Giới thiệu về fastText
- Xây dựng ma trận biểu diễn cho câu từ tiếng Nhật sử dụng FastText
Sơ lược về Word Embedding
Word Embedding là một trong những phương pháp phổ biến nhất trong trong xử lý ngôn ngữ tự nhiên để biểu diễn một từ (word representation) hay nói cách khác là nhiệm vụ ánh xạ một từ hoặc một cụm từ trong bộ từ vựng tới một vector số thực. Từ đó, tạo input cho các thuật toán xử lý.
Các kỹ thuật word embeddings
One-hot vector
One-hot vector là một phương pháp đơn giản nhất để tạo word_vector cho từ, cụm từ. Ý tưởng đơn giản là chúng ta xây dựng một từ điển bao gồm tất cả các từ có thể có (giả sử là n từ), sau đó gán cho mỗi từ 1 id duy nhất. Word vector cho mỗi từ sẽ là 1 vector n-chiều mà tại vị trí id của từ sẽ có giá trị = 1, các vị trí còn lại = 0.
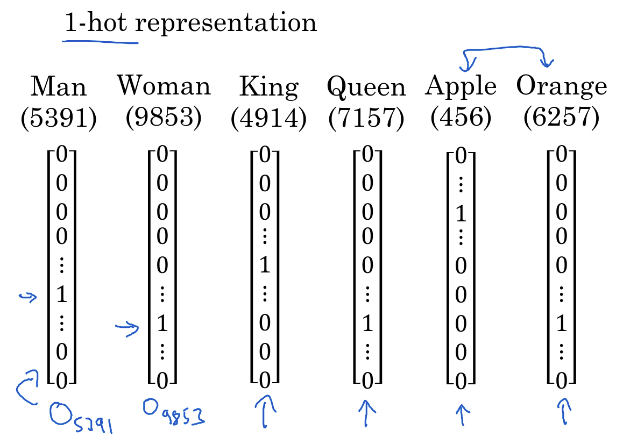
(Source: Andrew Ng - deeplearning.ai - NLP and Word Embeddings)
Tuy đơn giản, nhưng độ dài của one-hot vector quá lớn (vì bộ từ điển của chúng ta có vô số từ) và mặt khác thì không thể hiện được mối quan hệ ngữ nghĩa của các từ.
Word2Vec
Word2Vec được phát triển bởi Tomas Mikolov, 2013 - một kỹ sư của Google.
Trong phương pháp này đề cập đến 2 mô hình có thể xây dựng word2vec là : Skip Gram và Continous Bag of Words (CBOW). Có thể hiểu một cách đơn giản, nếu CBOW là sử dụng từ ngữ cảnh để dự đoán mục tiêu còn Skip Gram thì sử dụng một từ để dự đoán ngữ cảnh mục tiêu. Để biết thêm chi tiết về 2 mô hình này các bạn có thể tham khảo từ bài viết Xây dựng mô hình không gian vector cho Tiếng Việt - Phạm Hữu Quang
Mặc dù với word2vec thì phần nào đã thể hiện được mối tương quan ngữ nghĩa giữa các từ nhưng lại chỉ trong phạm vi dataset của bài toán và sẽ không hiệu quả trong trường hợp gặp từ mới, hiếm gặp.
FastText
FastText là mở rộng của Word2Vec, được xây dựng bởi Facebook AI Research, 2016. Thay vì training cho đơn vị word, nó chia text ra làm nhiều đoạn nhỏ được gọi là n-gram cho từ.
Mô hình kiến trúc của FastText:
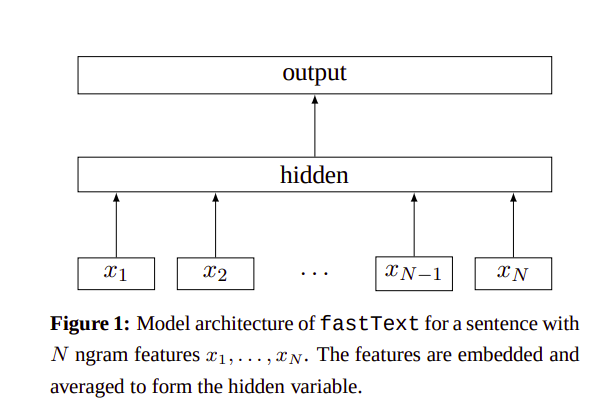
Ví dụ : Từ “where”, sau khi thêm prefix và subfix vào thành "<where>", tiến hành tách từ theo n-kí tự. Giả sử n=3 thì có "<wh, whe, her, er>" và bản thân từ "where"
Sau đó vector của từ được tính bằng tổng các vector n-gram.
FastTest xử lý tốt cho các trường hợp từ hiếm gặp, không có trong dataset. Vì các từ này vẫn có thể được chia thành các ký tự n-gram, chúng có thể chia sẻ các n-gram này với các từ phổ biến. Ví dụ, đối với một mô hình được đào tạo trên một tập dữ liệu tin tức, các thuật ngữ y tế, ví dụ: bệnh có thể là những từ hiếm.
Xây dựng ma trận biểu diễn câu cho tiếng Nhật sử dụng Fastext
Trong phần này, mình sẽ xây dựng ma trận biểu diễn các câu, đoạn văn tiếng Nhật (với các ngôn ngữ khác các bạn có thể làm tương tự) để tạo input cho các bài toán xử lý về mặt câu văn, đoạn văn.
Tạo Word List
Công việc đầu tiên đó là chúng ta xây dựng một bộ từ điển cho các từ tiếng Nhật.
Tại bước này, mình tạo một list với 20,000 từ tiếng Nhật thông dụng nhất (Source: Wikitionary:Frequency lits/Japanese) và lưu chúng vào một file jp_list.xlsx.
Sau đó, tiến hành tạo word_list.npy để lưu các từ lại dưới dạng list:
from tqdm import tqdm
import numpy as np
def get_all_words(path):
"""
:param path:
:return:
"""
pd_frame = pd.read_excel(path)
word_list = []
print('\n---start generating word_list---')
for i in tqdm(range(len(pd_frame))):
jp_words = pd_frame.iloc[i]['日文']
word_list.append(jp_words)
word_list.append('UNK')
word_list = np.asarray(word_list)
np.save("word_list.npy", word_list)
print('\n---finish generating word_list---')
return word_list
Tạo Word Vector
Trong bước này, mình có sử dụng pre-trained word vectors cho tiếng nhật từ fastText để lấy vector của các từ trong word_list được tạo ở trên. Thực tế thì fastText có cung cấp cho ta bộ pre-trained word_vector cho các từ, tuy viên với kích thước khá lớn - khoảng 4GB cho phần tiếng Nhật đề cập ở trên. Kích thước lớn của mô hình gây khó khăn cho việc sử dụng cho bài toán nên mục đích chính của mình là thu gọn lại với các từ thông dụng nhất.
import fasttext
from tqdm import tqdm
import numpy as np
def get_all_word_vec(model, word_list):
word_vec = []
print('\n---start generating word_vector---')
for i in tqdm(range(len(word_list))):
vec = model.get_word_vector(word_list[i])
word_vec.append(vec)
word_vector = np.asarray(word_vector)
np.save('word_vector.npy', word_vector)
print('\n---finish generating word_vector---')
return word_vec
ft = fasttext.load_model('wiki.ja.bin')
word_vector = get_all_word_vec(ft, word_list)
Kết quả là mình thu được file word_vector.npy với kích thước nhỏ ~23MB, word_vector.shape = (20001,300)
Lấy sentence matrix biểu diễn cho một câu, đoạn văn
Tại bước này, đầu tiên mình sẽ load lại word_list và word_vector thu được từ 2 bước trên. Sau đó là việc tách câu thành các từ. Một trong những điều khác so với tiếng việt là các từ được phân cách bằng dấu cách thì trong tiếng nhật, các từ viết liền nhau. Do đó chúng ta không thể sử dụng split() để tách một cách dễ dàng.
Ở đây, mình sử dụng sudachipy để get tokenizer cho câu văn tiếng Nhật:
try:
from sudachipy import dictionary
from sudachipy import tokenizer
except:
!pip install SudachiPy
!pip install https://object-storage.tyo2.conoha.io/v1/nc_2520839e1f9641b08211a5c85243124a/sudachi/SudachiDict_core-20190718.tar.gz
from sudachipy import dictionary
from sudachipy import tokenizer
def japanese_tokenizer(sentence):
tokenizer_obj = dictionary.Dictionary().create()
mode = tokenizer.Tokenizer.SplitMode.A
return [m.surface() for m in tokenizer_obj.tokenize(sentence, mode)]
Chạy thử với một ví dụ
sentence = "今日はいい天気ですね。"
japanese_tokenizer(sentence)
Output: ['今日', 'は', 'いい', '天気', 'です', 'ね', '。']cũng khá ổn. À mà trong output còn 1 vấn đề về dấu câu, chúng ta cũng cần loại bỏ:
import re
strip_special_chars = re.compile("[^\w0-9]+")
def clean_sentences(sentence):
sentence = sentence.lower().replace("<br />", " ")
return re.sub(strip_special_chars, "", sentence.lower())
Tiếp theo, là hàm lấy vector của câu :
def get_sentence_indices(sentence, max_seq_length, word_list):
sentence = clean_sentences(sentence)
indices = np.zeros((max_seq_length), dtype='int32')
words = japanese_tokenizer(sentence)
unk_idx = word2idx['UNK']
for idx, word in enumerate(words):
if idx < max_seq_length:
if (word in word_list):
word_idx = word2idx[word]
else:
word_idx = word2idx['UNK']
indices[idx] = word_idx
else:
break
return indices
Sau đó, các bạn có thể thiết lập một độ dài trung bình, hợp lý cho các câu tại MAX_SEQ_LENGTH và lấy indices của các câu, đoạn văn trong dataset để tạo input cho thuật toán.
Hy vọng bài viết có thể giúp ích được các bạn ! Cảm ơn các bạn đã dành thời gian đọc bài của mình !
References
All rights reserved
