Xây Dựng Mô Hình Ngôn Ngữ Lớn (Phần 5): Tiền huấn luyện với dữ liệu không gán nhãn
File Jupyter Notebook của bài viết này có thể xem tại đây
1. Tính toán các chỉ số: cross-entropy và perplexity
Trước quá trình huấn luyện mô hình, chúng ta cần một thước đo nào đó để xác định rằng việc huấn luyện có đang làm cho mô hình tiến bộ hơn không ? Và đây là lúc cần đến hàm mất mát (loss function)
Hàm mất mát (loss function) là một khái niệm trong học máy nhằm đo lường sự khác biệt giữa dự đoán của mô hình và giá trị thực tế.
Cross entropy loss
Cross-Entropy Loss là một hàm mất mát phổ biến, được sử dụng để đo lường sự khác biệt giữa phân phối xác suất dự đoán của mô hình và phân phối thực tế (nhãn đúng).
- N: Số lượng token đầu vào
- là xác suất dự đoán của mô hình cho token đúng tại vị trí
i
Các bước tính toán Cross-Entropy Loss như sau:
-
Bước 1: Lấy kết quả đầu ra logits của mô hình
-
Bước 2: Chuẩn hóa softmax để thu được phân phối xác suất
-
Bước 3: Trích xuất ra giá trị xác suất của các từ kỳ vọng qua các bước
-
Bước 4: Tính logarit cho các giá trị xác suất vừa trích xuất ra
-
Bước 5: Tính trung bình cộng các kết quả ở bước trên
-
Bước 6: Đảo dấu
-
Giá trị càng gần 0, chứng tỏ mô hình dự đoán so với kết quả càng ít sai lệch
Tại sao phải đảo dấu ?
- Trong học sâu, thay vì tối đa hóa
-10.7940để nó tiến gần đến 0, ta sẽ tối thiểu hóa10.7940để nó tiến gần đến 0 - Giá trị đối của
-10.7940là10.7940, được gọi là giá trị cross-entropy.
# ...
# Ta có 2 chuỗi đầu vào
inputs = torch.tensor([[16833, 3626, 6100], # ["every effort moves",
[40, 1107, 588]]) # "I really like"]
# Targets là kết quả kỳ vọng mô hình sẽ dự đoán ra được qua từng bước
targets = torch.tensor([[3626, 6100, 345], # ["effort moves you",
[1107, 588, 11311]]) # " really like chocolate"]
def main():
GPT_CONFIG_124M = {
"vocab_size": 50257, # Vocabulary size
"context_length": 256, # Shortened context length (orig: 1024)
"emb_dim": 768, # Embedding dimension
"n_heads": 12, # Number of attention heads
"n_layers": 12, # Number of layers
"drop_rate": 0.1, # Dropout rate
"qkv_bias": False # Query-key-value bias
}
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
model.eval();
with torch.no_grad():
logits = model(inputs)
probas = torch.softmax(logits, dim=-1)
text_idx = 0
# lấy 3 phần tử probas[0][0][3626], probas[0][1][6100], probas[0][2][345]
target_probas_1 = probas[text_idx, [0, 1, 2], targets[text_idx]]
text_idx = 1
# lấy 3 phần tử probas[1][0][1107], probas[1][1][588], (probas[1][2][11311]
target_probas_2 = probas[text_idx, [0, 1, 2], targets[text_idx]]
log_probas = torch.log(torch.cat((target_probas_1, target_probas_2)))
avg_log_probas = torch.mean(log_probas)
neg_avg_log_probas = avg_log_probas * -1
print(neg_avg_log_probas) # Kết quả: tensor(10.7940)
if __name__ == "__main__":
main()

Hoặc có thể dùng hàm có sẵn của Pytorch
# ...
def main():
GPT_CONFIG_124M = {
"vocab_size": 50257, # Vocabulary size
"context_length": 256, # Shortened context length (orig: 1024)
"emb_dim": 768, # Embedding dimension
"n_heads": 12, # Number of attention heads
"n_layers": 12, # Number of layers
"drop_rate": 0.1, # Dropout rate
"qkv_bias": False # Query-key-value bias
}
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
model.eval();
with torch.no_grad():
logits = model(inputs)
probas = torch.softmax(logits, dim=-1)
logits_flat = logits.flatten(0, 1)
targets_flat = targets.flatten()
loss = torch.nn.functional.cross_entropy(logits_flat, targets_flat)
print(loss)
Perplexity
Perplexity (tạm dịch là bối rối) được tính từ cross-entropy loss. Nó trả lời câu hỏi: "Mô hình bối rối như thế nào khi gặp dữ liệu mới ?". Perplexity càng thấp, mô hình càng tốt.
Lưu ý: Perplexity không phải là hàm mất mát, mà là chỉ số đánh giá độ hiệu quả của mô hình ngôn ngữ.
với e là số Euler (~2.718).
2. Tập huấn luyện và Tập đánh giá
Một điều không thể thiếu trong quá trình huấn luyện các mô hình là chia dữ liệu thành 2 phần là Tập huấn luyện (Training datasets) và Tập đánh giá (Validation datasets).
- Tập huấn luyện chứa được sử dụng để huấn luyện mô hình. Nó sẽ học các mẫu trong tập này để điều chỉnh các tham số.
- Tập đánh giá không được sử dụng để huấn luyện, mà chỉ dùng để đánh giá hiệu suất của mô hình. Nó giúp kiểm tra xem mô hình có đang học vẹt hay không ?
# Link file đầy đủ: https://sal.vn/HMXsKN
import os
import urllib.request
file_path = "the-verdict.txt"
url = "https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch02/01_main-chapter-code/the-verdict.txt"
if not os.path.exists(file_path):
with urllib.request.urlopen(url) as response:
text_data = response.read().decode('utf-8')
with open(file_path, "w", encoding="utf-8") as file:
file.write(text_data)
else:
with open(file_path, "r", encoding="utf-8") as file:
text_data = file.read()
# ...
# Train/validation ratio
# Chia theo tỷ lệ 9/1
train_ratio = 0.90
split_idx = int(train_ratio * len(text_data))
train_data = text_data[:split_idx]
val_data = text_data[split_idx:]
torch.manual_seed(123)
train_loader = create_dataloader_v1(
train_data,
batch_size=2,
max_length=GPT_CONFIG_124M["context_length"],
stride=GPT_CONFIG_124M["context_length"],
drop_last=True,
shuffle=True,
num_workers=0
)
val_loader = create_dataloader_v1(
val_data,
batch_size=2,
max_length=GPT_CONFIG_124M["context_length"],
stride=GPT_CONFIG_124M["context_length"],
drop_last=False,
shuffle=False,
num_workers=0
)
Training loss và Validation loss
Việc chia tập dữ liệu thành 2 phần cũng đồng thời tạo gấp đôi công sức tính hàm mất mát (loss function) trên mỗi tập 😄
# Link file đầy đủ: https://sal.vn/GJGVGi
# ...
def calc_loss_batch(input_batch, target_batch, model, device):
input_batch, target_batch = input_batch.to(device), target_batch.to(device)
logits = model(input_batch)
loss = torch.nn.functional.cross_entropy(logits.flatten(0, 1), target_batch.flatten())
return loss
def calc_loss_loader(data_loader, model, device, num_batches=None):
total_loss = 0.
if len(data_loader) == 0:
return float("nan")
elif num_batches is None:
num_batches = len(data_loader)
else:
# Reduce the number of batches to match the total number of batches in the data loader
# if num_batches exceeds the number of batches in the data loader
num_batches = min(num_batches, len(data_loader))
for i, (input_batch, target_batch) in enumerate(data_loader):
if i < num_batches:
loss = calc_loss_batch(input_batch, target_batch, model, device)
total_loss += loss.item()
else:
break
return total_loss / num_batches
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Note:
# Bỏ đoạn cmt dưới nếu bạn chạy trên máy Mac chip M của Apple
# Tốc độ sẽ nhanh hơn
# Tuy nhiên, giá trị loss trả về có thể sẽ khác
#if torch.cuda.is_available():
# device = torch.device("cuda")
#elif torch.backends.mps.is_available():
# device = torch.device("mps")
#else:
# device = torch.device("cpu")
#
# print(f"Using {device} device.")
model.to(device) # no assignment model = model.to(device) necessary for nn.Module classes
torch.manual_seed(123) # For reproducibility due to the shuffling in the data loader
with torch.no_grad(): # Disable gradient tracking for efficiency because we are not training, yet
train_loss = calc_loss_loader(train_loader, model, device)
val_loss = calc_loss_loader(val_loader, model, device)
print("Training loss:", train_loss)
print("Validation loss:", val_loss)
Với Training loss và Validation loss chúng ta có một số kịch bản sau
- Training loss và Validation loss đều giảm => Mô hình đang được huấn luyện hiệu quả
- Training loss giảm, Validation loss tăng => Mô hình chỉ đang làm tốt trên tập huấn luyện, gặp qua các dữ liệu chưa được huấn luyện thì đang bị tắc tị (Overfitting)
- Training loss và Validation loss đều tăng => Mô hình đang huấn luyện chưa tốt
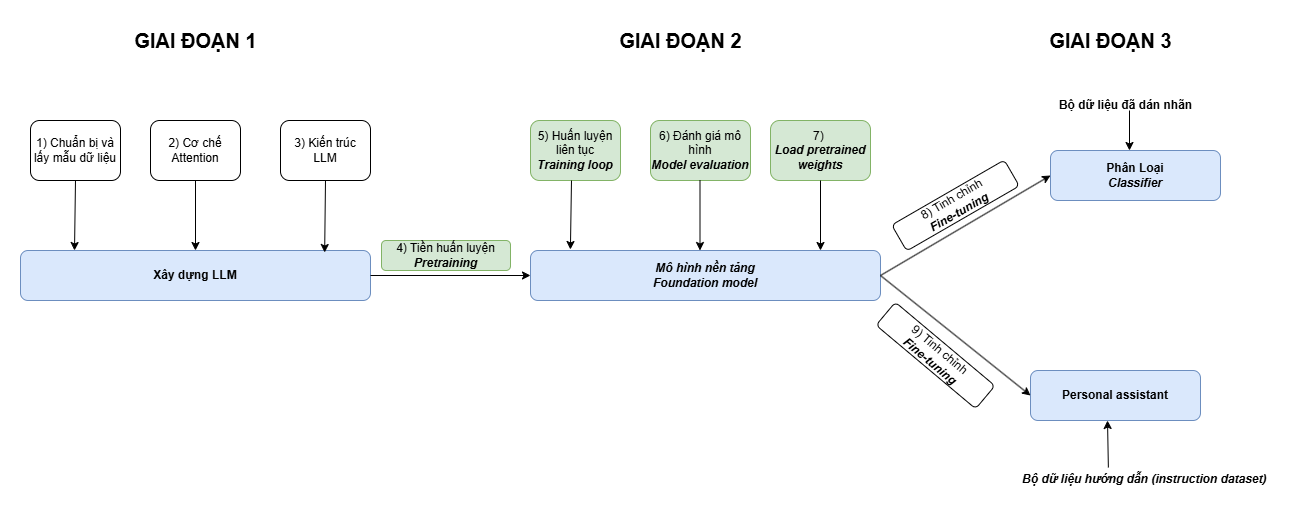
3. Huấn luyện LLM
Quy trình
Quy trình huấn luyện mô hình sẽ có các thao tác sau:
Bước 1: Chia thành các chu kỳ huấn luyện (epoch)
Một chu kỳ là một lần duyệt qua toàn bộ tập dữ liệu huấn luyện.
Bước 2: Chia tập dữ liệu huấn luyện thành các lô (batch)
- Dữ liệu huấn luyện được chia thành các lô thay vì huấn luyện cả tập dữ liệu một lúc.
- Trong mỗi chu kỳ, tiến hành lặp qua các lô dữ liệu.
Ví dụ: Nếu tập huấn luyện có 10,000 mẫu và batch size là 32, thì có khoảng 313 batch.
Bước 3: Đặt lại gradient
Gradient trong hàm mất mát là một đại lượng có hướng và độ lớn, chứa thông tin về cách thay đổi trọng số để tối ưu hàm mất mát.
- Trong PyTorch, gradient của các trọng số (weights) được tích lũy qua mỗi lần.
- Nếu không đặt lại gradient thì sẽ xảy ra hiện tượng cộng dồn, gây sai lệch. Bước này đảm bảo mỗi lô được tính gradient một cách độc lập.
Bước 4: Tính toán giá trị hàm mất mát (loss function)
Tính hàm mất mát cho từng lô dựa trên dự đoán của mô hình và nhãn thực tế.
Bước 5: Tính gradient cho từng lô
Bước 6:Cập nhật tham số của mô hình
Cập nhật tham số mô hình dựa trên gradient tính được, sử dụng một số thuật toán SGD, ADAM ...
Bước 7: Training and validation losses (Tùy chọn)
Tính Training loss và Validation loss xem mô hình đang học như thế nào ?
Bước 8: Sinh văn bản (Tùy chọn)
Sinh ra văn bản từ mô hình để kiểm tra chất lượng đầu ra.
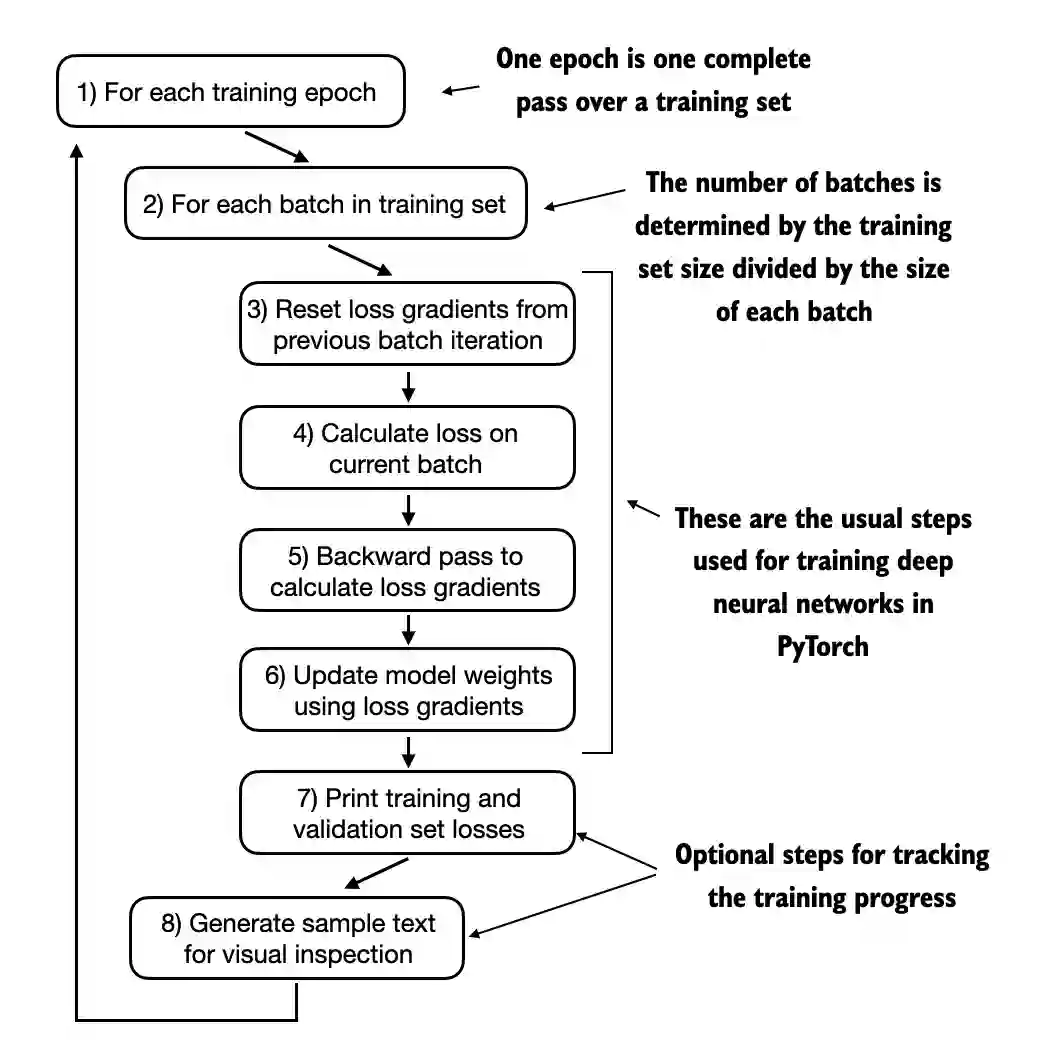
Minh họa với Pytorch
# FILE đầy đủ: https://sal.vn/8s0Maj
# Hàm tính Training loss và Validation loss
def evaluate_model(model, train_loader, val_loader, device, eval_iter):
model.eval()
with torch.no_grad():
train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter)
val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter)
model.train()
return train_loss, val_loss
# Sinh văn bản
def generate_and_print_sample(model, tokenizer, device, start_context):
model.eval() # Đặt mô hình ở chế độ đánh giá (evaluation mode)
context_size = model.pos_emb.weight.shape[0]
encoded = text_to_token_ids(start_context, tokenizer).to(device) # Chuyển văn bản sang token id
with torch.no_grad():
token_ids = generate_text_simple(
model=model, idx=encoded,
max_new_tokens=50, context_size=context_size
)
decoded_text = token_ids_to_text(token_ids, tokenizer) # Giải mã các token id thành văn bản
print(decoded_text.replace("\n", " "))
model.train()
def train_model_simple(model, train_loader, val_loader, optimizer, device, num_epochs,
eval_freq, eval_iter, start_context, tokenizer):
train_losses, val_losses, track_tokens_seen = [], [], []
tokens_seen, global_step = 0, -1
# Vòng lặp huấn luyện
for epoch in range(num_epochs):
model.train() # Bật trainning mode
for input_batch, target_batch in train_loader:
optimizer.zero_grad() # Reset gradient về 0
loss = calc_loss_batch(input_batch, target_batch, model, device)
loss.backward() # Tính gradient
optimizer.step() # Cập nhật tham số của mô hình
tokens_seen += input_batch.numel()
global_step += 1
if global_step % eval_freq == 0:
train_loss, val_loss = evaluate_model(
model, train_loader, val_loader, device, eval_iter)
train_losses.append(train_loss)
val_losses.append(val_loss)
track_tokens_seen.append(tokens_seen)
print(f"Ep {epoch+1} (Step {global_step:06d}): "
f"Train loss {train_loss:.3f}, Val loss {val_loss:.3f}")
# In ra văn bản được tạo bởi mô hình
generate_and_print_sample(
model, tokenizer, device, start_context
)
return train_losses, val_losses, track_tokens_seen
Kết quả huấn luyện sau 10 chu kỳ:
Ep 1 (Step 000000): Train loss 9.821, Val loss 9.931
Ep 1 (Step 000005): Train loss 8.069, Val loss 8.334
Every effort moves you,,,,,,,,,,,,,,.
Ep 2 (Step 000010): Train loss 6.623, Val loss 7.049
Ep 2 (Step 000015): Train loss 6.046, Val loss 6.598
Every effort moves you, and,, and,,,,,,,,,.
Ep 3 (Step 000020): Train loss 5.558, Val loss 6.503
Ep 3 (Step 000025): Train loss 5.471, Val loss 6.392
Every effort moves you, and to the to the of the to the, and I had. Gis, and I had, and, and, and, and I had, and, and, and, and, and, and, and, and, and,
Ep 4 (Step 000030): Train loss 4.995, Val loss 6.275
Ep 4 (Step 000035): Train loss 4.756, Val loss 6.289
Every effort moves you, and I had been the picture. "I"I the the donkey of the donkey the donkey of the picture and I had been a"I
Ep 5 (Step 000040): Train loss 4.113, Val loss 6.182
Every effort moves you know the "Oh, and he had to me--I me. "Oh, I felt--and it's the "Oh, and I had been the donkey--and it to me, and down the "Oh,
Ep 6 (Step 000045): Train loss 3.721, Val loss 6.143
Ep 6 (Step 000050): Train loss 3.170, Val loss 6.147
Every effort moves you know the fact, and I felt. "I had the last word. "I didn't. "I was his pictures--I looked. "I looked. "I
Ep 7 (Step 000055): Train loss 3.109, Val loss 6.186
Ep 7 (Step 000060): Train loss 2.370, Val loss 6.126
Every effort moves you know the inevitable garlanded to have to have the fact with a little: "Yes--and by me to me to have to see a smile behind his pictures--as I had been the honour of the donkey.
Ep 8 (Step 000065): Train loss 1.911, Val loss 6.151
Ep 8 (Step 000070): Train loss 1.592, Val loss 6.223
Every effort moves you?" "Yes--I glanced after him, and uncertain. "Oh, he was's an awful simpleton, and Mrs. Gisburn's head to look up at the sketch of the donkey. "There were days when I
Ep 9 (Step 000075): Train loss 1.239, Val loss 6.259
Ep 9 (Step 000080): Train loss 0.957, Val loss 6.270
Every effort moves you?" "Yes--quite insensible to the irony. The last word. He laughed again, and threw back the head to look up at the sketch of the donkey. "There were days when I
Ep 10 (Step 000085): Train loss 0.708, Val loss 6.387
Every effort moves you?" "Yes--quite insensible to the irony. She wanted him vindicated--and by me!" He laughed again, and threw back his head to look up at the sketch of the donkey. "There were days when I
Đồ thị hóa 2 thông số Training và Validation loss
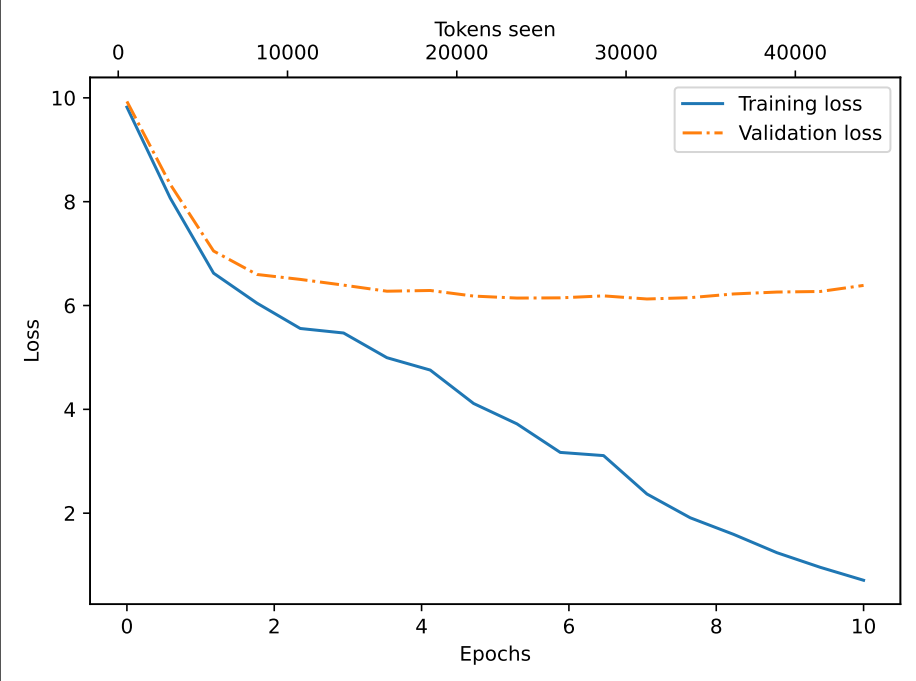
Training loss giảm dần theo thời gian chứng tỏ mô hình đang dự đoán rất tốt trên tập huấn luyện. Tuy nhiên, Validation loss giảm trong 2 chu kỳ đầu tiên và gần như đi ngang đến hết => Chứng tỏ quá trình huấn luyện đang bị quá khớp (overfit).
4. Điều chỉnh cách thức lựa chọn đầu ra
Như đã biết, từ tiếp theo sinh ra được chọn từ giá trị xác suất lớn nhất thu được khi chuẩn hóa softmax.
Trong phần này chúng ta sẽ làm quen với một số cách tiếp cận khác là temperature scaling và top-k sampling.
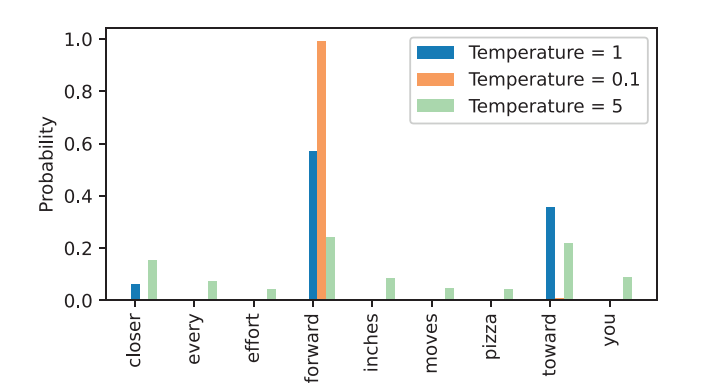
Temperature scaling
Ý tưởng chính của phương pháp này là làm mịn, điều chỉnh lại phân phối xác suất bằng cách chia các giá trị logits cho một số T > 0 trước khi chuẩn hóa softmax.
def softmax_with_temperature(logits, temperature):
scaled_logits = logits / temperature
return torch.softmax(scaled_logits, dim=0)
Thông số Temperature > 1 dẫn đến xác suất được phân phối đều hơn, trong khi nếu nó nhỏ hơn 1 sẽ dẫn đến các phân phối có sự cách biệt hơn. Cùng xem đồ thị minh họa để có thể dễ hình dung hơn
Top-k sampling
Top-k Sampling là một kỹ thuật trong đó chỉ giữ lại k token có xác suất cao nhất để xử lý.
Quy trình:
-
- Chỉ giữ lại k giá trị logits lớn nhất. Các giá trị còn lại gán bằng
-inf
- Chỉ giữ lại k giá trị logits lớn nhất. Các giá trị còn lại gán bằng
-
Softmax
-
- Lấy giá trị lớn nhất

top_k = 3
top_logits, top_pos = torch.topk(next_token_logits, top_k)
print("Top logits:", top_logits)
print("Top positions:", top_pos)
# Top logits: tensor([6.7500, 6.2800, 4.5100])
# Top positions: tensor([3, 7, 0])
# Các giá trị không thuộc k giá trị lớn nhất thì gán là -inf. Khi softmax sẽ ra xác suất = 0
new_logits = torch.where(
condition=next_token_logits < top_logits[-1],
input=torch.tensor(float("-inf")),
other=next_token_logits
)
print(new_logits)
# tensor([4.5100, -inf, -inf, 6.7500, -inf, -inf, -inf, 6.2800, -inf])
topk_probas = torch.softmax(new_logits, dim=0)
print(topk_probas)
# tensor([0.0615, 0.0000, 0.0000, 0.5775, 0.0000, 0.0000, 0.0000, 0.3610, 0.0000])
Điều chỉnh lại hàm sinh văn bản
Từ các kỹ thuật Temperature scaling và Top-k sampling ở trên, chúng ta điều chỉnh lại cách thức sinh văn bản dựa trên phân phối xác suất như sau:
def generate(model, idx, max_new_tokens, context_size, temperature=0.0, top_k=None, eos_id=None):
for _ in range(max_new_tokens):
idx_cond = idx[:, -context_size:]
with torch.no_grad():
logits = model(idx_cond)
logits = logits[:, -1, :]
# Áp dụng top-k sampling
if top_k is not None:
top_logits, _ = torch.topk(logits, top_k)
min_val = top_logits[:, -1]
logits = torch.where(logits < min_val, torch.tensor(float("-inf")).to(logits.device), logits)
# Áp dụng temperature scaling
if temperature > 0.0:
logits = logits / temperature
probs = torch.softmax(logits, dim=-1) # (batch_size, context_len)
# Sample from the distribution
idx_next = torch.multinomial(probs, num_samples=1) # (batch_size, 1)
# Nếu temperture <= 0 thì lại áp dụng cách thức cũ, lấy xác suất lớn nhất
else:
idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch_size, 1)
if idx_next == eos_id:
break
idx = torch.cat((idx, idx_next), dim=1) # (batch_size, num_tokens+1)
return idx
5. Tải về và sử dụng trọng số của OpenAI
Các tham số tải về và nạp vào mô hình là
- Ma trận trọng số W của token, position embeddings
- Các ma trận , , và hệ số tự do (bias) của cơ chế multi-head attetion
- Ma trận W và bias của Feed Forward Network
- Tham số của lớp chuẩn hóa LayerNorm
- Tham số của lớp chuẩn hóa Final LayerNorm
- Tham số của lớp Linear output
pip install tensorflow>=2.15.0 tqdm>=4.66
# ... file đầy đủ: https://sal.vn/KKG17C
model_configs = {
"gpt2-small (124M)": {"emb_dim": 768, "n_layers": 12, "n_heads": 12},
"gpt2-medium (355M)": {"emb_dim": 1024, "n_layers": 24, "n_heads": 16},
"gpt2-large (774M)": {"emb_dim": 1280, "n_layers": 36, "n_heads": 20},
"gpt2-xl (1558M)": {"emb_dim": 1600, "n_layers": 48, "n_heads": 25},
}
model_name = "gpt2-small (124M)"
NEW_CONFIG = GPT_CONFIG_124M.copy()
NEW_CONFIG.update(model_configs[model_name])
NEW_CONFIG.update({"context_length": 1024, "qkv_bias": True})
gpt = GPTModel(NEW_CONFIG)
gpt.eval();
def assign(left, right): # right là tham số nạp vào
# Kiểm tra kích thước 2 tensor
if left.shape != right.shape:
# Nếu không khớp, báo lỗi
raise ValueError(f"Shape mismatch. Left: {left.shape}, Right: {right.shape}")
# Trả về tensor right dưới dạng torch.nn.Parameter
return torch.nn.Parameter(torch.tensor(right))
# Duyệt qua và gán các tham số từ GPT-2 của OpenAI vào mô hình GPT của chúng ta
def load_weights_into_gpt(gpt, params):
gpt.pos_emb.weight = assign(gpt.pos_emb.weight, params['wpe'])
gpt.tok_emb.weight = assign(gpt.tok_emb.weight, params['wte'])
for b in range(len(params["blocks"])):
q_w, k_w, v_w = np.split(
(params["blocks"][b]["attn"]["c_attn"])["w"], 3, axis=-1)
gpt.trf_blocks[b].att.W_query.weight = assign(
gpt.trf_blocks[b].att.W_query.weight, q_w.T)
gpt.trf_blocks[b].att.W_key.weight = assign(
gpt.trf_blocks[b].att.W_key.weight, k_w.T)
gpt.trf_blocks[b].att.W_value.weight = assign(
gpt.trf_blocks[b].att.W_value.weight, v_w.T)
q_b, k_b, v_b = np.split(
(params["blocks"][b]["attn"]["c_attn"])["b"], 3, axis=-1)
gpt.trf_blocks[b].att.W_query.bias = assign(
gpt.trf_blocks[b].att.W_query.bias, q_b)
gpt.trf_blocks[b].att.W_key.bias = assign(
gpt.trf_blocks[b].att.W_key.bias, k_b)
gpt.trf_blocks[b].att.W_value.bias = assign(
gpt.trf_blocks[b].att.W_value.bias, v_b)
gpt.trf_blocks[b].att.out_proj.weight = assign(
gpt.trf_blocks[b].att.out_proj.weight,
params["blocks"][b]["attn"]["c_proj"]["w"].T)
gpt.trf_blocks[b].att.out_proj.bias = assign(
gpt.trf_blocks[b].att.out_proj.bias,
params["blocks"][b]["attn"]["c_proj"]["b"])
gpt.trf_blocks[b].ff.layers[0].weight = assign(
gpt.trf_blocks[b].ff.layers[0].weight,
params["blocks"][b]["mlp"]["c_fc"]["w"].T)
gpt.trf_blocks[b].ff.layers[0].bias = assign(
gpt.trf_blocks[b].ff.layers[0].bias,
params["blocks"][b]["mlp"]["c_fc"]["b"])
gpt.trf_blocks[b].ff.layers[2].weight = assign(
gpt.trf_blocks[b].ff.layers[2].weight,
params["blocks"][b]["mlp"]["c_proj"]["w"].T)
gpt.trf_blocks[b].ff.layers[2].bias = assign(
gpt.trf_blocks[b].ff.layers[2].bias,
params["blocks"][b]["mlp"]["c_proj"]["b"])
gpt.trf_blocks[b].norm1.scale = assign(
gpt.trf_blocks[b].norm1.scale,
params["blocks"][b]["ln_1"]["g"])
gpt.trf_blocks[b].norm1.shift = assign(
gpt.trf_blocks[b].norm1.shift,
params["blocks"][b]["ln_1"]["b"])
gpt.trf_blocks[b].norm2.scale = assign(
gpt.trf_blocks[b].norm2.scale,
params["blocks"][b]["ln_2"]["g"])
gpt.trf_blocks[b].norm2.shift = assign(
gpt.trf_blocks[b].norm2.shift,
params["blocks"][b]["ln_2"]["b"])
gpt.final_norm.scale = assign(gpt.final_norm.scale, params["g"])
gpt.final_norm.shift = assign(gpt.final_norm.shift, params["b"])
gpt.out_head.weight = assign(gpt.out_head.weight, params["wte"])
load_weights_into_gpt(gpt, params)
gpt.to(device);
torch.manual_seed(123)
token_ids = generate(
model=gpt,
idx=text_to_token_ids("Every effort moves you", tokenizer).to(device),
max_new_tokens=25,
context_size=NEW_CONFIG["context_length"],
top_k=50,
temperature=1.5
)
print("Output text:\n", token_ids_to_text(token_ids, tokenizer))
Kết quả mô hình cho ra đã khá mượt mà và tự nhiên 😆
Output text:
Every effort moves you as far as the hand can go until the end of your turn unless something happens
This would remove you from a battle
Tài liệu tham khảo
All rights reserved
