Xây dựng Collaborative Filtering RS [Recommender System cơ bản - Phần 3]
Bài đăng này đã không được cập nhật trong 5 năm
Tại bài viết trước, chúng ta đã tìm hiểu tổng quan về xây dựng một hệ thống Content-based Recommender System đơn giản. Tại bài viết này, chúng ta tiếp tục tìm hiểu thuật toán và xây dựng một hệ thống Collaborative Filtering Recommender System đơn giản với bộ dữ liệu Movilens.
Thuật toán
Ý tưởng cơ bản của thuật toán này là dự đoán mức độ yêu thích của một user đối với một item dựa trên các users khác “gần giống” với user đang xét. Việc xác định độ “giống nhau” giữa các users có thể dựa vào mức độ quan tâm (rating) của các users này với các items khác mà hệ thống đã biết trong quá khứ
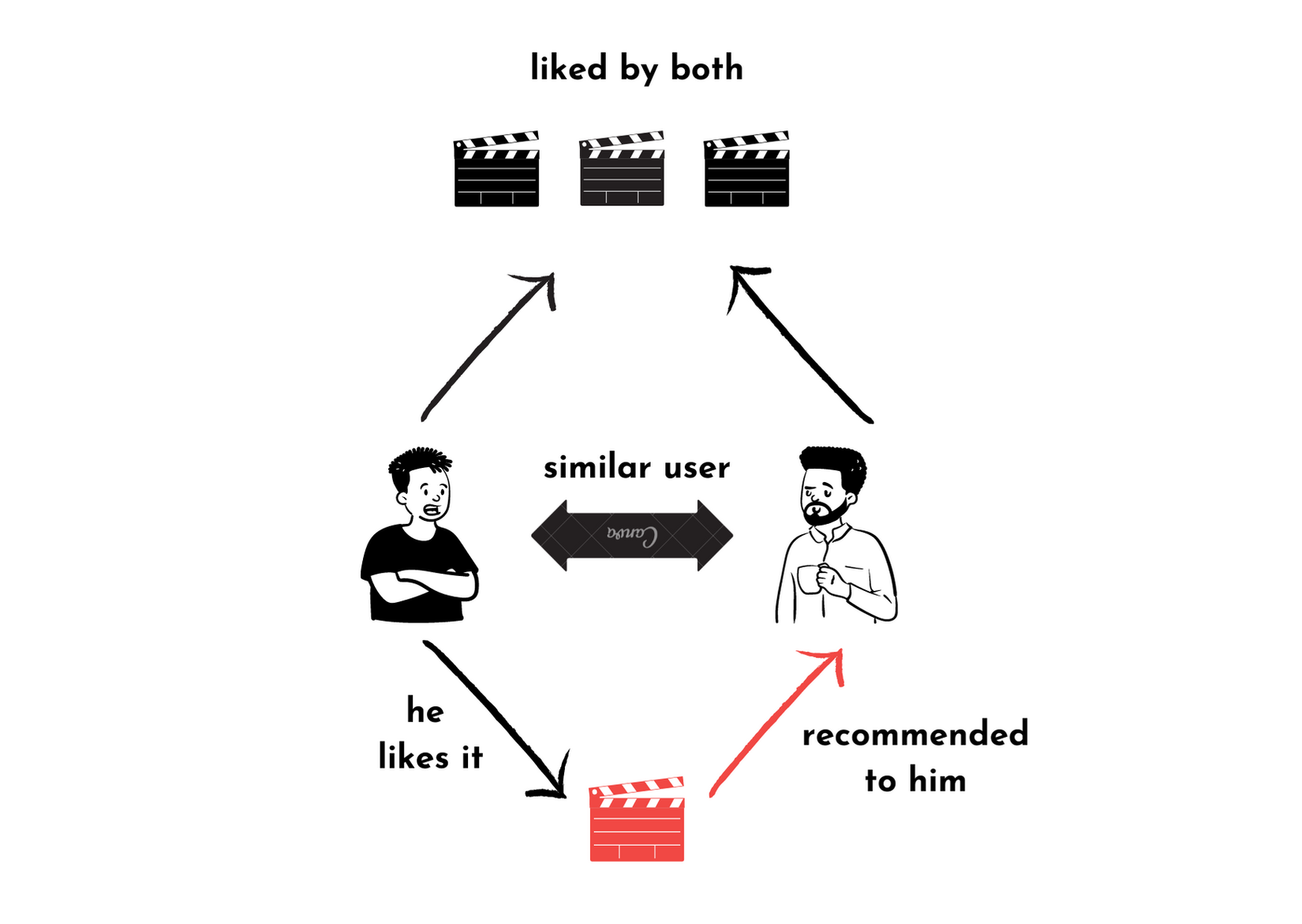
Ví dụ: Hai users A, B đều thích các phim về cảnh sát hình sự (tức là đều đánh giá các bộ phim thuộc thể loại này 4 -> 5 sao). Dựa vào lịch sử xem phim của B, ta thấy B thích bộ phim “Người phán xử”, vậy nhiều khả năng A cũng thích phim này, từ đó hệ thống sẽ đề xuất “Người phán xử” cho A.
Thiết kế
Có 2 hướng tiếp cận Collaorative Filtering:
- Một là xác định mức độ quan tâm của mỗi user tới một item dựa trên mức độ quan tâm của users gần giống nhau (similar users) tới item đó còn được gọi là User-user collaborative filtering.
- Hai là thay vì xác định user similarities, hệ thống sẽ xác định item similarities. Từ đó, hệ thống gợi ý những items gần giống với những items mà user có mức độ quan tâm cao.
Sau đây, chúng ta sẽ thiết kế hệ thống theo hướng user-user.
1. Khởi tạo ma trận dữ liệu
Đối với Collaborative filtering, chúng ta sử dụng 3 thành phần dữ liệu là user, movies và ratings (1), cụ thể:
- Users: là danh sách người dùng
- Movies: là danh sách các phim, mỗi phim có thể kèm theo thông tin mô tả.
- Ratings: là số điểm user đánh giá cho các bộ phim Để lưu trữ được 3 thành phần dữ liệu trên, chúng ta tiếp tục sử dụng module read_csv của Pandas để lưu trữ, chúng ta gọi là ma trận user – items. Cụ thể, ma trận user - items biểu diễn mức độ quan tâm (rating) của user với mỗi item. Ma trận này được xây dựng từ dữ liệu (1).
import pandas
from pandas import read_csv
def get_dataframe_ratings_base(text):
"""
đọc file base của movilens, lưu thành dataframe với 3 cột user id, item id, rating
"""
r_cols = ['user_id', 'item_id', 'rating']
ratings = pandas.read_csv(text, sep='\t', names=r_cols, encoding='latin-1')
Y_data = ratings.values
return Y_data
Ma trận này có rất nhiều các giá trị miss. Nhiệm vụ của hệ thống là dựa vào các ô đã có giá trị trong ma trận trên (dữ liệu thu được từ trong quá khứ), thông qua mô hình đã được xây dựng, dự đoán các ô còn trống (của user hiện hành), sau đó sắp xếp kết quả dự đoán (ví dụ, từ cao xuống thấp) và chọn ra Top-N items theo thứ tự rating giảm dần, từ đó gợi ý chúng cho người dùng.
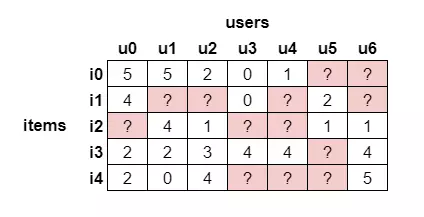
2. Chuẩn hóa ma trận dữ liệu
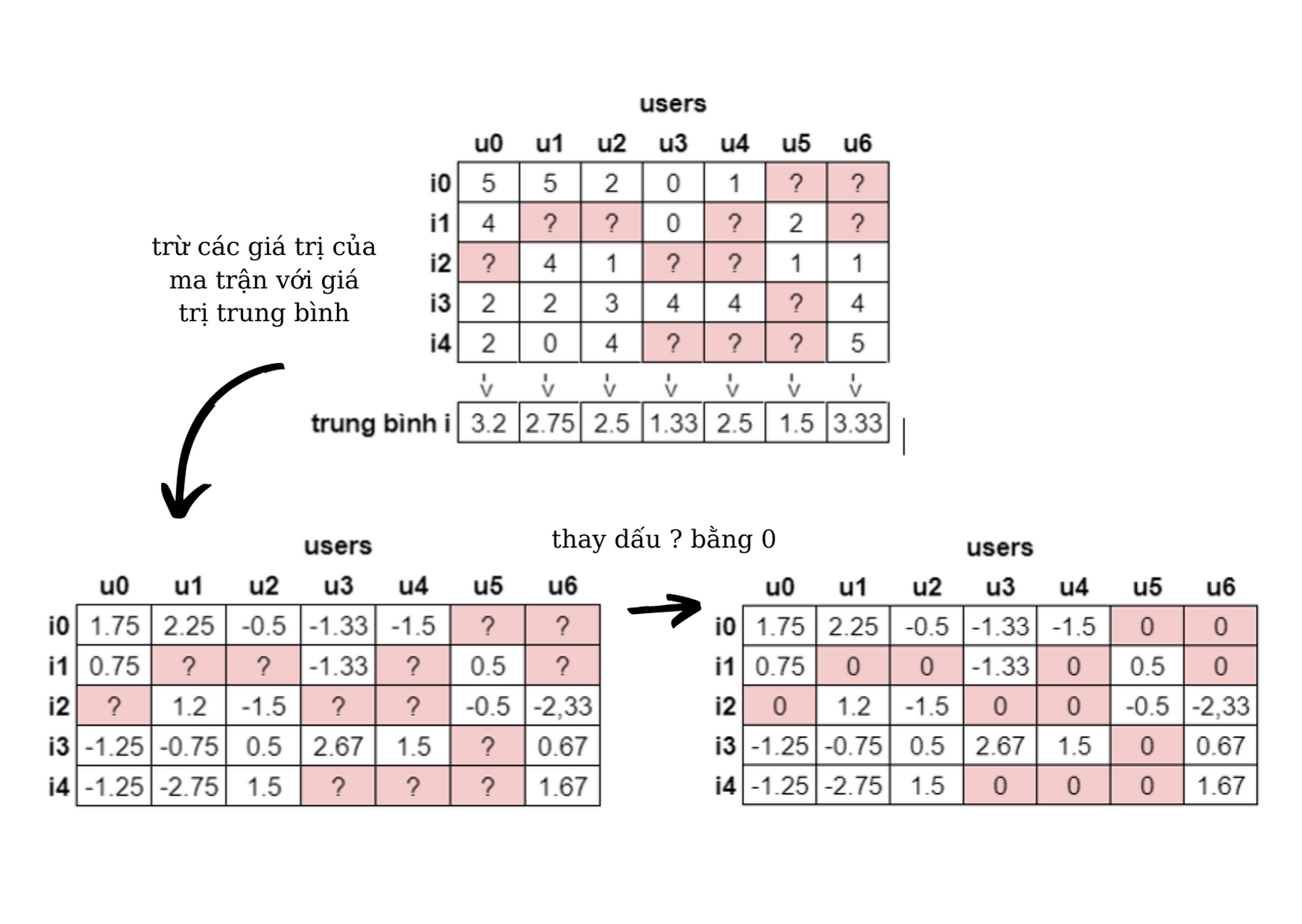
Để có thể sử dụng ma trận này vào việc tính toán, chúng ta cần thay những dấu ‘?’ bởi một giá trị. Đơn giản nhất có thể thay giá trị ‘0’ hay một cách khác là ‘2.5’ – giá trị trung bình giữa 0 và 5. Tuy nhiên, cách tính này có độ chính xác thấp vì những giá trị này sẽ hạn chế với những users dễ hoặc khó tính. Thay vào đó, ta sử dụng giá trị trung bình cộng ratings của mỗi user bằng cách trừ ratings của mỗi user cho giá trị trung bình ratings tương ứng của user đó và thay dấu ‘?’ bằng giá trị 0.
import pandas as pd
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
from scipy import sparse
class CF(object):
"""
class Collaborative Filtering, hệ thống đề xuất dựa trên sự tương đồng
giữa các users với nhau, giữa các items với nhau
"""
def __init__(self, data_matrix, k, dist_func=cosine_similarity, uuCF=1):
"""
Khởi tạo CF với các tham số đầu vào:
data_matrix: ma trận Utility, gồm 3 cột, mỗi cột gồm 3 số liệu: user_id, item_id, rating.
k: số lượng láng giềng lựa chọn để dự đoán rating.
uuCF: Nếu sử dụng uuCF thì uuCF = 1 , ngược lại uuCF = 0. Tham số nhận giá trị mặc định là 1.
dist_f: Hàm khoảng cách, ở đây sử dụng hàm cosine_similarity của klearn.
limit: Số lượng items gợi ý cho mỗi user. Mặc định bằng 10.
"""
self.uuCF = uuCF # user-user (1) or item-item (0) CF
self.Y_data = data_matrix if uuCF else data_matrix[:, [1, 0, 2]]
self.k = k
self.dist_func = dist_func
self.Ybar_data = None
# số lượng user và item, +1 vì mảng bắt đầu từ 0
self.n_users = int(np.max(self.Y_data[:, 0])) + 1
self.n_items = int(np.max(self.Y_data[:, 1])) + 1
def normalize_matrix(self):
"""
Tính similarity giữa các items bằng cách tính trung bình cộng ratings giữa các items.
Sau đó thực hiện chuẩn hóa bằng cách trừ các ratings đã biết của item cho trung bình cộng
ratings tương ứng của item đó, đồng thời thay các ratings chưa biết bằng 0.
"""
users = self.Y_data[:, 0]
self.Ybar_data = self.Y_data.copy()
self.mu = np.zeros((self.n_users,))
for n in range(self.n_users):
ids = np.where(users == n)[0].astype(np.int32)
item_ids = self.Y_data[ids, 1]
ratings = self.Y_data[ids, 2]
# take mean
m = np.mean(ratings)
if np.isnan(m):
m = 0 # để tránh mảng trống và nan value
self.mu[n] = m
# chuẩn hóa
self.Ybar_data[ids, 2] = ratings - self.mu[n]
self.Ybar = sparse.coo_matrix((self.Ybar_data[:, 2],
(self.Ybar_data[:, 1], self.Ybar_data[:, 0])), (self.n_items, self.n_users))
self.Ybar = self.Ybar.tocsr()
Mục đích của cách xử lý này là: − Phân loại ratings thành 2 loại: giá trị âm (user không thích item) và dương (user thích item). Các giá trị bằng 0 là những item chưa được đánh giá. − Số chiều của Utility matrix thường rất lớn, trong khi lượng ratings biết trước thường rất nhỏ so với kích thước của ma trận. Nếu thay dấu ‘?’ bằng ‘0’ thì chúng ta có thể sử dụng sparce matrix, tức ma trận chỉ lưu các giá trị khác 0 và vị trí của giá trị đó. Như vậy, việc lưu trữ sẽ tối ưu hơn.
3. Tính toán độ tương đồng
Sau khi chuẩn hóa ma trận Utility, ta tính toán độ tương đồng giữa các users. Chúng ta sử dụng hàm cosine similarity (hàm có sẵn của thư viện sklearn của Python). Dưới đây là công thức và hàm cosine similarity
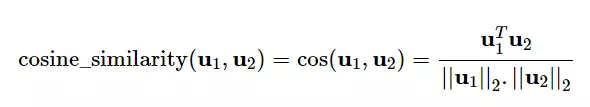
# ở phần khởi tạo class, ta đã gái: dist_func=cosine_similarity
def similarity(self):
"""
Tính độ tương đồng giữa các user và các item
"""
eps = 1e-6
self.S = self.dist_func(self.Ybar.T, self.Ybar.T)
Kết quả sau khi tính toán độ tương đồng (độ tương đồng là 1 con số trong khoảng -1 đến 1. Càng gần 1 thì càng tương đồng, càng gần -1 thì càng đối lập)
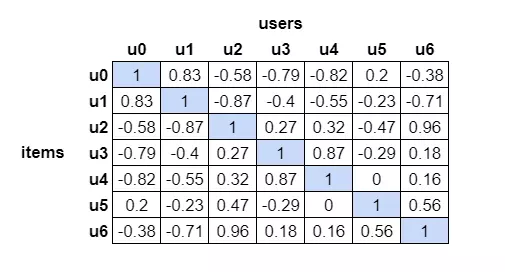
4. Dự đoán ratings
Ta sẽ dự đoán ratings của một user với mỗi item dựa trên k users gần nhất (neighbor users), tương tự như phương pháp K-nearest neighbors (KNN).
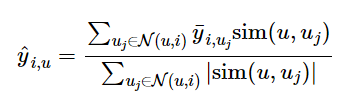
Trong đó, N(u, i) là tập k users gần nhất (có độ tương đồng cao nhất) với user u và đã từng đánh giá item i. Ví dụ, chúng tôi dự đoán normalized rating của user u1 cho item i1 với k = 2 là số users gần nhất.
- Bước 1: Xác định các users đã rated cho i1, đó là u0, u3, u5
- Bước 2: Lấy similarities của u1 với u0, u3, u5. Kết quả lần lượt là: {u0, u3, u5: {0.83, -0.4, -0.23}. Với k = 2. Chọn 2 giá trị lớn nhất là 0.83 và -0.23, tương ứng với các users u0, u5. Hai users này có normalized ratings với i1 là: {u0, u5} {0.75, 0.5}
- Bước 3: Tính normalized ratings theo công thức:
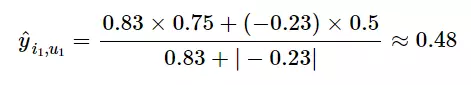
Thực hiện dự đoán cho các trường hợp missing ratings (chưa có dự đoán), ta sẽ thu được ma trận normalized ratings matrix như ví dụ: Cuối cùng, cộng lại các giá trị ratings với ratings trung bình (ở bước chuẩn hóa) theo từng cột. Chúng ta sẽ thu được ma trận hoàn thiện.
# hàm nằm trong class CF
def __pred(self, u, i, normalized=1):
"""
Dự đoán ra ratings của các users với mỗi items.
"""
# tìm tất cả user đã rate item i
ids = np.where(self.Y_data[:, 1] == i)[0].astype(np.int32)
users_rated_i = (self.Y_data[ids, 0]).astype(np.int32)
sim = self.S[u, users_rated_i]
a = np.argsort(sim)[-self.k:]
nearest_s = sim[a]
r = self.Ybar[i, users_rated_i[a]]
if normalized:
# cộng với 1e-8, để tránh chia cho 0
return (r * nearest_s)[0] / (np.abs(nearest_s).sum() + 1e-8)
return (r * nearest_s)[0] / (np.abs(nearest_s).sum() + 1e-8) + self.mu[u]
def pred(self, u, i, normalized=1):
"""
Xét xem phương pháp cần áp dùng là uuCF hay iiCF
"""
if self.uuCF: return self.__pred(u, i, normalized)
return self.__pred(i, u, normalized)
Kết quả:
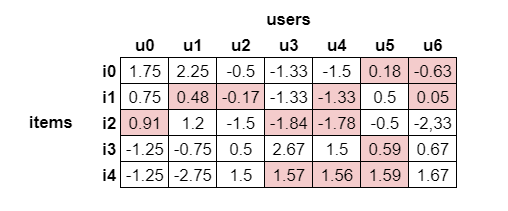
5. Kết quả
Sau khi chúng tôi đã dự đoán được ratings của các bộ phim mà người dùng sẽ đánh giá, chúng tôi lấy ra được top bộ phim mà user sẽ thích theo các bước:
- Lấy id người dùng
- Nhận danh sách rating của người dùng đối với các bộ phim chưa xem
- Sắp xếp danh sách các bộ giá trị rating đó
- Trả về các tiêu đề tương ứng với chỉ số của các phần tử trên cùng
def recommend_top(self, u, top_x):
"""
Determine top 10 items should be recommended for user u.
. Suppose we are considering items which
have not been rated by u yet.
"""
ids = np.where(self.Y_data[:, 0] == u)[0]
items_rated_by_u = self.Y_data[ids, 1].tolist()
item = {'id': None, 'similar': None}
list_items = []
def take_similar(elem):
return elem['similar']
for i in range(self.n_items):
if i not in items_rated_by_u:
rating = self.__pred(u, i)
item['id'] = i
item['similar'] = rating
list_items.append(item.copy())
sorted_items = sorted(list_items, key=take_similar, reverse=True)
sorted_items.pop(top_x)
return sorted_items
Vậy là chúng ta đã xây dựng xong hệ thống Collaborative Filtering RS với Python và Movilens theo hướng tiếp cận user-user. Đối với hướng tiếp cận item-item, thay vì tính similarity giữa các users như trong uuCF, chúng ta sẽ tính similarity giữa các items, rồi gợi ý cho users những items gần giống với item mà user đó đã thích. Lợi ích của phương pháp này là:
- Vì số lượng items thường rất nhỏ so với số lượng users nên kích thước ma trận Similarity sẽ nhỏ hơn rất nhiều, giúp tối ưu hơn cả về mặt lưu trữ và tốc độ tính toán.
- Thường thì mỗi item được đánh giá bởi rất nhiều users, và con số này thường lớn hơn nhiều so với số items mà mỗi user đánh giá. Vì vậy, số giá trị đã biết trong một vector biểu diễn item sẽ lớn hơn nhiều so với một vector biểu diễn user. Trong trường hợp có thêm một số dữ liệu về ratings, giá trị trung bình ratings của iiCF sẽ ít thay đổi hơn so với uuCF, vì vậy sẽ ít phải cập nhật Similarity Matrix hơn. Về mặt tính toán, iiCF có thể thực hiện theo uuCF bằng cách chuyển vị ma trận Utility, coi như items đánh giá users. Sau khi tính được kết quả, chúng ta lại thực hiện chuyển vị một lần nữa sẽ thu được kết quả cuối cùng.
Tổng kết
Vậy là qua series Recommender System cơ bản, chúng ta đã:
- Tìm hiểu về phương thức hoạt động và các yêu cầu của hệ thống Recommender System.
- Tìm hiểu về cách xử lý các ma trận, dữ liệu để nắm rõ được phương thức hoạt động của Recommender System.
- Giải quyết bài toàn Recommender System với MovieLens dataset ở mức độ đơn giản theo phương pháp Content-based và Collaborative Filtering.
Để có thể hiểu rõ hơn về Recommender System, các bạn có thể tham khảo source code demo, trong demo mình đã có thêm giao diện và hiển thị trực quan kết quả của hệ thống. Ngoài ra các bạn cũng có thể tham khảo thêm tài liệu tham khảo phía dưới. Chúc các bạn ngày học tập và làm việc thật hiệu quả. ^^
Tài liệu tham khảo
- Ekstrand, Michael D., John T. Riedl, and Joseph A. Konstan. “Collaborative filtering recommender systems” 2011
- Jure Leskovec, Anand Rajaraman, Jeffrey David Ullman, Stanford University, California. “Recommendation Systems” 2014
- Recomender System Tutorial
- Content Based Recommendations | Stanford University
- Collaborative Filtering | Stanford University
All rights reserved
