Unicode trong python 2 (Phần 1)
Bài đăng này đã không được cập nhật trong 8 năm
1. Đặt vấn đề
Làm việc với Python 2 các bạn đã bao giờ gặp những trường hợp như thế này chưa?
UnicodeEncodeError: 'ascii' codec can't encode character u'\xa0' in position 20: ordinal not in range(128)
hoặc print, bắn log ra toàn ra ký tự này chưa
WARNING:root:��{�ꕶ�������e�X�g/
và khi đi tìm solution thì bị tẩu hỏa nhập ma với các khái niệm decode, encode và khi nào dùng chúng, các loại bảng mã Unicode, UTF-8, SHIFT-JIS... loằng xì ngoằng. Mình sẽ giúp các bạn làm sáng tỏ một số vấn đề trên
2. Các khái niệm
a, Bảng mã Unicode, UTF-8, SHIFT-JIS... là gì?
- Bảng mã Unicode là bảng mã chứa gần như toàn bộ các kí tự của hầu hết các ngôn ngữ trên toàn cầu. Có nghĩa là gần như bất cứ ký tự nào đều mã hóa được qua bảng mã Unicode. Và mỗi một ký tự sẽ tương ứng với một một byte mã hóa. Trong python, ký tự mã hóa Unicode được bắt đầu bằng chữ
\u. Ví dụ chữTiếng việtđược mã hóa là'Ti\u1ebfng vi\u1ec7t' - Bảng mã UTF-8 là bảng mã hóa miêu tả bảng mã Unicode cho máy tính hiểu
- SHIFT-JIS là bảng mã được sử dụng ở gần như toàn bộ các máy tính tại Nhật, được JIS đưa ra. Nó cũng có tác dụng tương tự như bảng mã UTF-8 là miêu tả ký tự cho máy tính hiểu. Vậy Unicode là một Character Set(còn nhiều loại Character Set khác), một bộ tập hợp các ký tự cho con người sử dụng, còn UTF-8, SHIFT-JIS, ASCII... là những Character Encoding, chúng mã hóa các ký tự thành các con số để giúp máy tính hiểu được.
b, String, decode, encode trong python 2
- String trong python cũng là một object và được chia ra làm 2 loại(type):
strvàunicode. Một chuỗi là kiểuunicodethì sẽ có chữuđứng trước khi print. VD:u'Tiếng việt'. Mặc định trong python 2 thì mọi chuỗi sẽ đều được đưa về kiểustr - Decode và Encode là cách chuyển đổi qua lại giữa
strvàunicode
3. Các vấn đề xảy ra khi làm việc với Unicode
Thông thường khi code hoặc tương tác với các dữ liệu có nội dung là tiếng anh, chỉ chứa các ký tự latinh thông thường thì gần như chẳng gặp vấn đề gì, chỉ khi tương tác với các ký tự đặc biệt, các ký tự có dấu thì chúng ta mới thấy Unicode trong python 2 rất khó chịu.
1, Sử dụng Unicode trong code
Các bạn thử viết đoạn mã sau vào file và chạy chúng:
print "Xin chào Việt Nam"
các bạn sẽ gặp ngay lỗi sau
 để sửa lỗi trên, ta sẽ thêm dòng
để sửa lỗi trên, ta sẽ thêm dòng # encoding: utf-8 vào dòng đầu tiên của file để mã hóa toàn bộ string trong file đó bằng utf-8
2, Độ dài của chuỗi
Xem ví dụ sau:

Tại sao khi thêm chữ u vào phía trước thì nó còn 10 ký tự. Vì trong python 2 mặc định chuỗi sẽ được để là kiểu str và dùng bảng mã UTF-8 để mã hóa. Hãy xem thực sự chữ "Tiếng Việt" và u"Tiếng Việt" được biểu diễn như thế nào:
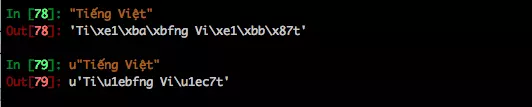
Hàm len sẽ đếm số byte để biểu diễn chuỗi đó, "Tiếng Việt" sử dụng 14 byte để biểu diễn còn u"Tiếng Việt" chỉ sử dụng 10 byte. Do đó, để làm việc với chuỗi trong python thì nên convert chúng về kiểu Unicode để tránh trường hợp như validate user_name 10 ký tự, người ta để là "Tiếng Việt" đủ 10 ký tự mà cứ báo lỗi dài quá 
P/S: Mình tạm dừng ở đây và sẽ quay trở lại ở phần tiếp theo
All rights reserved
