Xây dựng sơ bộ một hệ thống crawler
Bài đăng này đã không được cập nhật trong 8 năm
Mình vừa nhận được câu hỏi từ bạn đọc như sau:
 nên tiện đây mình sẽ viết 1 bài chia sẻ về hệ thống crawler mình đã làm sử dụng Scrapy gồm những gì.
nên tiện đây mình sẽ viết 1 bài chia sẻ về hệ thống crawler mình đã làm sử dụng Scrapy gồm những gì.
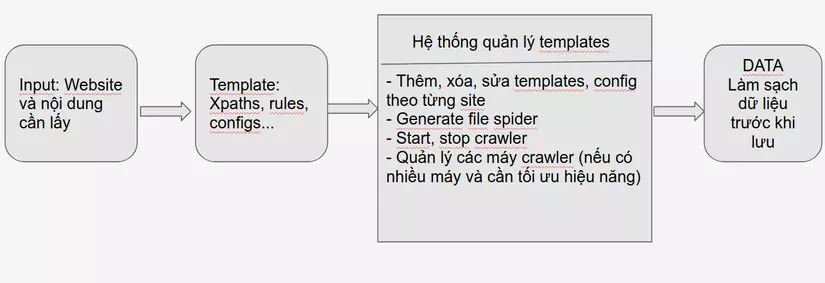
1. Lấy xpath như thế nào?
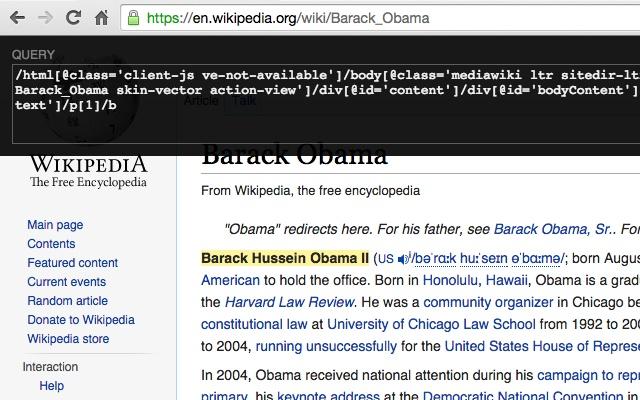
Để lấy được một đoạn mã xpath như thế này: //*[@id="aspnetForm"]/div[5]/div[1]/div[1]/div[1]/div[1]/div[1]/div[2]/h2/a mình hay dùng extension Xpath Helper. Tất nhiên mình có clone repo của extension này về và custome lại để cho thuận tiện việc lấy và insert template vào hệ thống. Trong 1 website, 1 xpath có thể đúng với page này nhưng lại không đúng với page kia nên bạn cần tối ưu xpath được suggest từ Xpath Helper sao cho phù hợp với nhiều page nhất.
2. Hệ thống quản lý template
a, Backend
Có thể dùng luôn Flask để tạo hệ thống api với các chức năng thêm, xóa, sửa, generate file, start, stop một spider cho đỡ mất công học thêm thứ khác. Flask của python dùng thì max nhanh và đơn giản, chỉ cần import là sài thôi. Nên dùng databases NoSQL để lưu trữ thông tin các template vì tính linh động của chúng.
b, Frontend
React hoặc Angularjs xx . Mình làm backend là chính nên cũng không quan tâm lắm, cứ dễ dùng, nhiều support thì mình sài thôi. Trước thì mình có dùng React, nhưng giờ chuyển qua Angularjs xx rồi (xx là version của Angular nhé  )
)
c, Quản lý các máy crawler
Khi hệ thống của bạn mở rộng có 2K, 3K site cần crawl mỗi ngày thì bạn sẽ cần phải có nhiều hơn 1 máy crawler. Lúc này cần thêm một việc là quản lý các máy crawler sao cho chúng chạy tối đa công suất có thể và không xảy ra tình trạng 1 site được crawl ở 2 máy khác nhau. Lúc này bạn có thể nghĩ tới Celery, nó sẽ giúp bạn đồng bộ giữa các máy crawler, quản lý dễ hơn và cũng tăng hiệu suất của server hơn. Hoặc to tay thì có thể tự code cũng được, vì về cơ bản thì mỗi máy có 1 cấu hình riêng, công suất riêng nên cứ ném riêng cho 1 file config, cho chúng sync được với một thằng master nào đấy rồi từ thằng master chỉ đạo thằng nào làm gì qua api thôi.
d, Giám sát hiệu năng của hệ thống
Mình đã dùng Datadog để tracking xem một ngày hệ thống mình crawl được bao nhiêu item, so sánh với các ngày trước đó. Khi có 1 máy crawler lăn ra chết sẽ có mail báo từ datadog, khi hight CPU..v.v
3. Kết luận
Về cơ bản để xây dựng một ứng dụng crawler, có rất nhiều cách và trên đây là cách mình đã tiếp cận. Hy vọng sẽ giúp được bạn xây dựng được một hệ thống crawler như mong muốn
All rights reserved
