Ứng dụng Support Vector Machine trong bài toán phân loại hoa
Bài đăng này đã không được cập nhật trong 4 năm
Xin chào các bạn, mình lại trở lại rồi đây. Tiếp tục với loạt bài viết về Machine Learning trong bài trước mình đã giới thiệu với các bạn một cách tổng quan nhất về Support Vector Machine - một phương pháp vô cùng hiệu quả trong bài toán phân lớp dữ liệu. Tuy nhiên nếu đọc lý thuyết nhiều quá hẳn sẽ rất khó khăn cho những bạn mới bắt đầu (mình cũng mới bắt đầu tìm hiểu về Machine Learning mà). Chính vì thế, ngày hôm nay chúng ta sẽ đến với một bài toán khá cụ thể đó là sử dụng SVM trong bài toán phân loại hoa. Hiểu nôm na đó là chúng ta sẽ xây dựng một mô hình (model) sao cho khi input vào là một bông hoa và ouput trả ra kết quả nó là loài hoa gì. Thú vị phải không các bạn  . OK chúng ta bắt đầu thôi nào.
. OK chúng ta bắt đầu thôi nào.
Cơ sở của bài toán phân loại hoa
Cái gì cũng phải có cơ sở một chút phải không nào. Ví dụ trong bài toán của ta đang quan tâm đến đối tượng là hoa chẳng hạn, vậy có một câu hỏi đặt ra là ***"Làm thế nào để phân biệt các loại hoa với nhau ???"***.

Con người chúng ta qua quá trình lớn lên đã tự tích lũy cho mình những đặc điểm rất riêng của mỗi loài hoa. Ví dụ hoa loa kèn có hình giống cái kèn, hoa huệ màu trắng có mùi thơm đặc trưng, hoa hồng màu đỏ và có gai... Vậy tức là trong đầu chúng ta đã có một tập dữ liệu về các loài hoa và nó chính là căn cứ để chúng ta nhận dạng một loài hoa khi chúng ta gặp phải. Nguyên tắc học của máy tính cũng như vậy thôi. Chúng ta cần phải cung cấp cho nó một tập dữ liệu và huấn luyện cho nó băng một cách nào đó để nó có thể căn cứ vào đó mà đoán được một bông hoa mới thuộc vào loài hoa nào. OK, quan trọng nhất vẫn là phải có một tập dữ liệu huấn luyện phải không nào? Trong bài viết này chúng ta sẽ sử dụng một tập dữ liệu về hoa vô cùng nổi tiếng đó là tập dữ liệu Iris. Chúng ta cùng nhau tìm hiểu sâu hơn về tập dữ liệu này nhé.
Tập dữ liệu Iris Flowers
Tập dữ liệu này còn có tên gọi khác là **Fisher's Iris ** vì nó do Ronald Fisher thu thập và tổng hợp. Tập dữ liệu này gồm 50 mẫu về 3 loài hoa khác nhau của họ Iris là (Iris setosa, Iris virginica và Iris versicolor). Cho cái ảnh cho các bạn dễ hình dung

Với mỗi một mẫu hoa này hắn thu thập bốn thuộc tính là chiều dài và chiều rộng của đài hoa và cánh hoa với đơn vị centimet. Để có thể sử dụng tập dữ liệu này chúng ta sẽ sử dụng thư viện datasets trong sklearn.
from sklearn import datasets
# import iris flowers dataset
iris = datasets.load_iris()
Sau khi đã có dữ liệu rồi, chúng ta hoàn toàn có thể chạy thuật toán SVM ngay để tiến hành phân loại. Tuy nhiên, mình nghĩ nên giúp các bạn có một cái nhìn trực quan hơn về tập dữ liệu này. Mà để hiển thị trực quan nhất thì không gì bằng biểu đồ với thư viện matplotlib thần thánh. Chúng ta cùng thử biểu diễn trên đồ thị xem tập dữ liệu mà chúng ta nhét vào máy tính nó là cái gì nhé.
Biểu diễn tập dữ liệu bằng đồ thị 2D
Chúng ta tưởng tượng tập dữ liệu của ta là một tập hợp của 150 điểm dữ liệu tương ứng với 150 bông hoa.. Chúng ta sẽ lấy chúng ta từ datasets bằng hàm sau:
def getData():
# Get iris data from datasets
iris = datasets.load_iris()
return iris
Lúc này đã có một tập hợp các điểm dữ liệu. Mỗi điểm dữ liệu bao gồm 4 thuộc tính như đã nói ở trên. Tuy nhiên để biểu diễn trong đồ thị hai chiều chúng ta cần phải giảm bớt số thuộc tính biểu diễn. Ở đây giả sử chọn hai thuộc tính đầu tiên là độ rộng và chiều cao của đài hoa. Chúng ta có hàm xử lý vẽ đồ thị 2D như sau:
def get2DPlot(iris):
X = iris.data[:, :2] # Lấy hai thuộc tính đầu tiên
Y = iris.target
X_min, X_max = X[:, 0].min() - .5, X[:, 0].max() + .5
Y_min, Y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
plt.figure(2, figsize=(8, 6))
plt.clf()
# Biểu diễn tập dữ liệu huấn luyện bằng đồ
plt.scatter(X[:, 0], X[:, 1], c=Y, cmap=plt.cm.Paired)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(X_min, X_max)
plt.ylim(Y_min, Y_max)
plt.xticks(())
plt.yticks(())
plt.show()
Và đây là thành quả
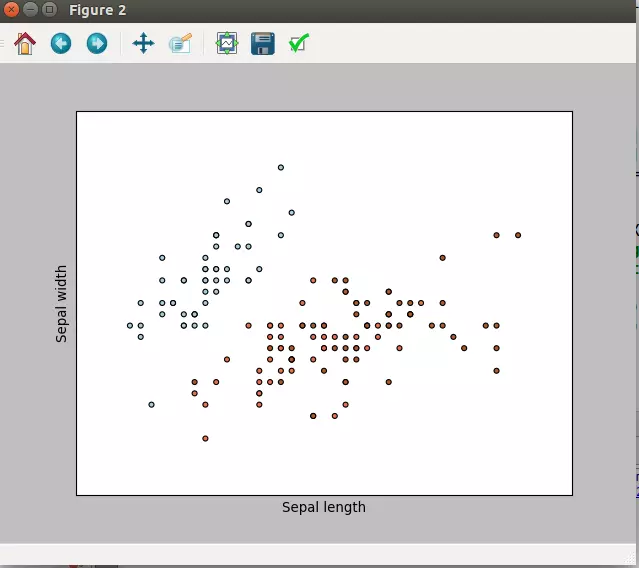
Chúng ta có thể thấy được các điểm dữ liệu với hai thuộc tính trên đồ thị hai chiều. Các điểm này được phân biệt bằng mắt thường với 3 màu khác nhau. Tuy nhiên muốn máy tính phân biệt được như chúng ta lại là một câu chuyện hoàn toàn khác và bạn sẵn sàng cùng tôi đi đến cuối cùng của câu chuyện này chứ. OK chúng ta tiếp tục thôi
Phân lớp sử dụng SVM với các Kernel khác nhau
Với tập dữ liệu Iris chúng ta cần phân loại các bông hoa thành 3 lớp dữ liệu. Sử dụng SVM với các phương pháp khác nhau sẽ cho hiệu quả phân lớp khác nhau. Cũng tương tự như trên, chúng ta chỉ xem xét đến 2 thuộc tính đầu tiên của tập dữ liệu, tức là phân lớp trong không gian 2 chiều. Chúng ta sử dụng các Kernel khác nhau bao gồm:
- SVC with linear kernel
- LinearSVC (linear kernel
- SVC with RBF kernel
- SVC with polynomial (degree 3) kernel
Đầu tiên chúng ta cần huấn luyện dữ liệu
X = iris.data[:, :2] # lấy hai thuộc tính đầu tiên của tập dữ liệu để tiện quan sát bằng đồ thị hai chiều
y = iris.target
h = .02 # hiệu chỉnh độ mỏng của lưới tọa độ trên đồ thị. Càng nhỏ thì càng sắc nét
# we create an instance of SVM and fit out data. We do not scale our
# data since we want to plot the support vectors
C = 1.0 # SVM regularization parameter
svc = svm.SVC(kernel='linear', C=C).fit(X, y)
rbf_svc = svm.SVC(kernel='rbf', gamma=0.7, C=C).fit(X, y)
poly_svc = svm.SVC(kernel='poly', degree=3, C=C).fit(X, y)
lin_svc = svm.LinearSVC(C=C).fit(X, y)
Tiếp theo là việc đẩy các mô hình thu được vào đồ thị
# title for the plots
titles = ['SVC with linear kernel',
'LinearSVC (linear kernel)',
'SVC with RBF kernel',
'SVC with polynomial (degree 3) kernel']
for i, clf in enumerate((svc, lin_svc, rbf_svc, poly_svc)):
# Plot the decision boundary. For that, we will assign a color to each
# point in the mesh [x_min, x_max]x[y_min, y_max].
plt.subplot(2, 2, i + 1)
plt.subplots_adjust(wspace=0.4, hspace=0.4)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
# Put the result into a color plot
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.coolwarm, alpha=0.8)
# Plot also the training points
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.coolwarm)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.xticks(())
plt.yticks(())
plt.title(titles[i])
plt.show()
Bây giờ sau khi vẽ các đồ thị trên là chúng ta có thể so sánh hiệu quả phân lớp của các Kernel khác nhau rồi đấy. Kết quả như sau:
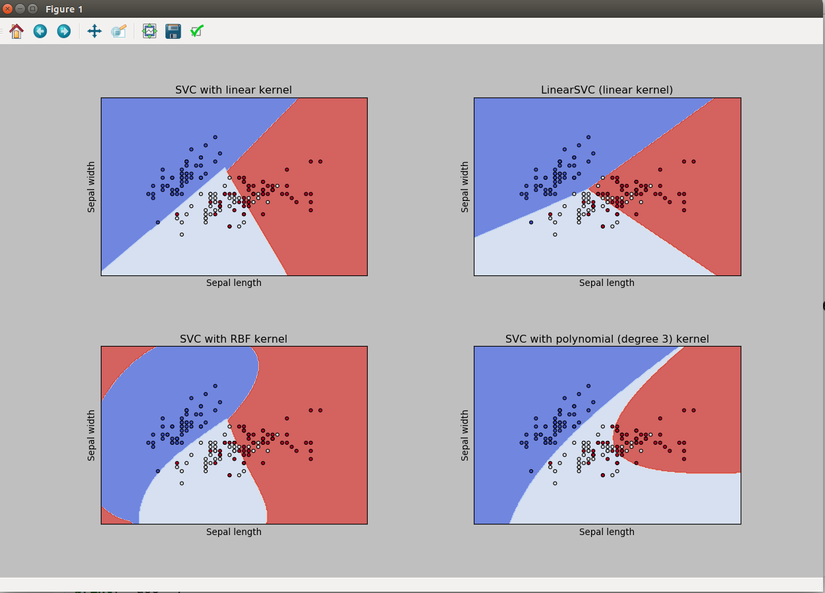
Bằng việc phân lớp chúng ta có thể chia mặt phẳng tọa độ thành các phần khác nhau. Khi có một điểm dữ liệu mới chúng ta có thể dựa vào tọa độ của chúng để phán đoán xem nó thuộc lớp nào.
Hướng phát triển
Chúng ta hoàn toàn có thể tự custom một Kernel riêng của mình. Điều đó làm cho SVM trở nên linh hoạt hơn.

Mình rất hi vọng được trình bày với các bạn sâu hơn về Custom Kernel của mình để việc phân lớp cụ thể là phân lớp ảnh được tốt hơn. Nhưng trong phạm vi bài viết này mình sẽ dừng lại ở các Kernel tuyến tính và phi tuyến thôi đã. Kẻo nói nhiều quá chúng ta khó năm bắt được hết vấn đề.
Source code trong bài viết
Các bạn có thể tham khảo mã nguồn mình viết trong bài này tại đây
Tham khảo
All rights reserved
