Tìm hiểu về windows functions in PostgresSql
Bài đăng này đã không được cập nhật trong 6 năm
Mở đầu
Tất cả chúng ta khi sử dụng hệ cơ sở dữ liệu đều biết về các hàm tổng hợp thông thường thao tác trên toàn bộ bảng(SUM,MIN,MAX,COUNT...) và được sử dụng với mệnh đề GROUP BY. Nhưng rất ít người sử dụng Window functions trong SQL. Windows funtion hoạt động trên một tập hợp các hàng và trả về một giá trị tổng hợp duy nhất cho mỗi hàng.
Ưu điểm chính của việc sử dụng Window functions so với các hàm tổng hợp thông thường là: Các hàm Window functions sẽ không làm các hàng được nhóm thành một hàng duy nhất, các hàng giữ lại các danh tính thuộc tính riêng biệt của chúng và một giá trị tổng hợp sẽ được thêm vào mỗi hàng.
Giới thiệu về Window functions
Như đã đề cập, Windows functions hoạt động trên một tập hợp các hàng và trả về một giá trị tổng hợp duy nhất cho mỗi hàng. Chúng ta sẽ xác định Windows Function bằng cách sử dụng mệnh đò OVER().
Kiểu của Window functions
- Aggregate Window Functions: SUM(), MAX(), MIN(), AVG(). COUNT()
- Ranking Window Functions : RANK(), DENSE_RANK(), ROW_NUMBER(), NTILE()
- Value Window Functions: LAG(), LEAD(), FIRST_VALUE(), LAST_VALUE()
Cú pháp
window_function ( [ ALL ] expression )
OVER ( [ PARTITION BY partition_list ] [ ORDER BY order_list] )
Arguments
window_function
Chỉ định tên của windows funtions
ALL
ALL là một từ khóa tùy chọn. Khi chỉ định ALL, PostgresSql sẽ xử lý tất cả dữ liệu kể cả các dữ liệu trùng. Từ khóa DISTINCT không hỗ trợ trong Windows Functions
expression
Chỉ định tên cột mà chúng ta cần tổng hợp giá trị . Ví dụ : Chỉ định cột tên là order amount để xác định tổng số order amount nhận được
OVER
Chỉ định window clauses(PARTITION BY , ORDER BY ...) cho Windows Funtions
PARTITION BY partition_list (tương tự mệnh đề group by)
Chỉ định tập hợp các hàng mà windows functions có thể thao tác trên đó. Chúng ta cần cung cấp một field hoặc tập hợp các fields phía sau mệnh đề PARTITION BY. Nếu đối với nhiều field, các field cách nhau bởi dấu phẩy. Nếu PARTITION BY không được chỉ định, mặc định sẽ được group trên toàn bộ bảng.
ORDER BY order_list
Thực hiện sorts theo PARTITION BY đã chỉ định phía trên, nếu ORDER BY không được chỉ định, sẽ thực hiện ORDER BY theo bảng
Các ví dụ thực tế
Về phần lý thuyết có vẻ hơi khó hiểu. Để hiểu rõ hơn về Windows functions chúng ta sẽ đi vào các ví dụ cụ thể. Đấu tiên chuẩn bị database và insert dữ liệu như bên dưới. Bài viết thực hiện trên PostgresSql
Example database
CREATE TABLE public.orders
(
order_id VARCHAR(250),
order_date DATE,
customer_name VARCHAR(250),
city VARCHAR(100),
order_amount MONEY
)
INSERT INTO public.orders
SELECT '1001',DATE('2017-04-01'),'David Smith','GuildFord',10000
UNION ALL
SELECT '1002',DATE('2017-04-02'),'David Jones','Arlington',20000
UNION ALL
SELECT '1003',DATE('2017-04-03'),'John Smith','Shalford',5000
UNION ALL
SELECT '1004',DATE('2017-04-04'),'Michael Smith','GuildFord',15000
UNION ALL
SELECT '1005',DATE('2017-04-05'),'David Williams','Shalford',7000
UNION ALL
SELECT '1006',DATE('2017-04-06'),'Paum Smith','GuildFord',25000
UNION ALL
SELECT '1007',DATE('2017-04-10'),'Andrew Smith','Arlington',15000
UNION ALL
SELECT '1008',DATE('2017-04-11'),'David Brown','Arlington',2000
UNION ALL
SELECT '1009',DATE('2017-04-20'),'Robert Smith','Shalford',1000
UNION ALL
SELECT '1010',DATE('2017-04-25'),'Peter Smith','GuildFord',500
Aggregate Window Functions:
Sum()
Chúng ta đều biết hàm SUM (). Nó thực hiện tổng của trường được chỉ định cho nhóm được chỉ định (như city, state, country, v.v.) hoặc cho toàn bộ bảng nếu nhóm không được chỉ định.
Dưới đây là ví dụ của SUM aggregate function () và Windows Functions . Ví dụ dưới chúng ta muốn tính tổng ở cột order_amount và nhóm lại theo city
SUM aggregate function
SELECT city, SUM(order_amount) as total_order_amount
FROM Orders GROUP BY city
Kết quả
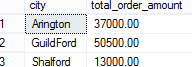
Chúng ta có thể thấy từ tập kết quả rằng aggregate function sẽ nhóm nhiều hàng thành một hàng đầu ra duy nhất, điều này làm cho các hàng riêng lẻ bị mất danh tính.
Windows Functions
SELECT order_id, order_date, customer_name, city, order_amount
,SUM(order_amount) OVER(PARTITION BY city) as grand_total
FROM Orders
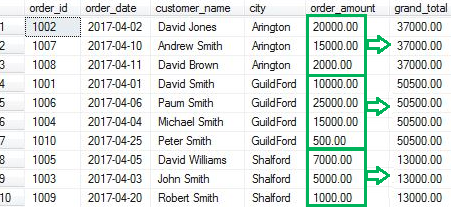
Đối với Windows Funtions, hàm giữ lại các thuộc tính riêng của chúng và hiển thị một giá trị tổng hợp cho mỗi hàng. Trong câu lệnh phía trên, query thực hiện Sum các dữ liệu cho từng city và hiển thị tổng order_amount cho từng city. Tuy nhiên, query sẽ chèn thêm một cột khác cho tổng order_amount để giữ lại thuộc tính cho mỗi hàng.
AVG()
AVG() cũng là một trong những hàm hay gặp khi tính toán. Truy vấn sau sẽ thực hiện truy vấn lượng đơn đặt hàng trung bình cho mỗi city và cho mỗi tháng sử dụng Windows Functions
SELECT order_id, order_date, customer_name, city, order_amount
,AVG(order_amount) OVER(PARTITION BY city, MONTH(order_date)) as average_order_amount
FROM Orders
Ở truy vấn trên , chúng ta đã chỉ định nhiều hơn một fields trong PARTITION, chúng ta cũng có thể sử dụng các hàm như MONTH , YEAR ... trong PARTITION BY miễn là cú pháp đúng.
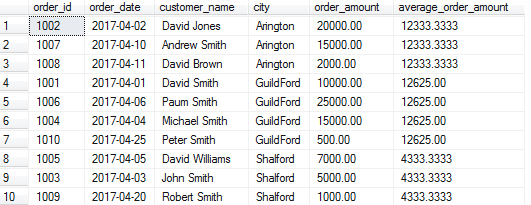
Ở kết quả trên chúng ta có thể thấy Windows Functions đã thực hiện tính toán trùng bình cho mỗi city và mỗi tháng. Ví dụ kết quả là 12,333 đối với city Arlington của tháng 04 2017 .
MIN()
Hàm MIN () sẽ tìm giá trị nhỏ nhất cho một nhóm được chỉ định hoặc cho toàn bộ bảng nếu nhóm không được chỉ định.
Ví dụ dưới tìm kiếm order nhỏ nhất cho mỗi city :
SELECT order_id, order_date, customer_name, city, order_amount
,MIN(order_amount) OVER(PARTITION BY city) as minimum_order_amount
FROM Orders
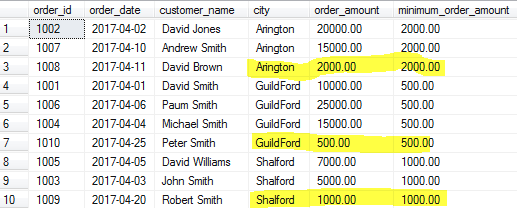
MAX()
Hàm MAX () sẽ tìm giá trị lớn nhất cho một nhóm được chỉ định hoặc cho toàn bộ bảng nếu nhóm không được chỉ định.
Ví dụ dưới tìm kiếm order lớn nhất cho mỗi city :
SELECT order_id, order_date, customer_name, city, order_amount
,MAX(order_amount) OVER(PARTITION BY city) as maximum_order_amount
FROM Orders
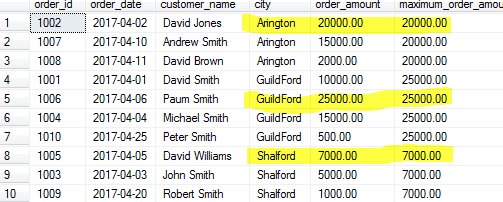
COUNT()
Hàm count được sử dụng để đếm số hàng/số record được chỉ định. Lưu ý toán tử DISTINCT không được sử dụng trong windows function với hàm count() nhưng được hỗ trợ trong hàm count thông thường. Toán tử DISTINCT giúp bạn tìm các giá trị riêng biệt của một trường được chỉ định.
Ví dụ : Chúng ta muốn xem có bao nhiêu khách hàng đã order vào tháng 4/2017 , chúng ta không thể đếm trực tiếp tất cả các khách hàng. Có thể một khách hàng có thể order nhiều lần trong cùng một tháng
COUNT với DISTINCT hỗ trợ đối với hàm tổng hợp thông thường
SELECT city,COUNT(DISTINCT customer_name) number_of_customers
FROM GROUP BY city
COUNT với DISTINCT không làm việc với windows function :
SELECT order_id, order_date, customer_name, city, order_amount
,COUNT(DISTINCT customer_name) OVER(PARTITION BY city) as number_of_customers
FROM Orders
Kết quả :
![]()
Câu lệnh phía dưới sẽ đếm tất các order của mỗi city
SELECT order_id, order_date, customer_name, city, order_amount
,COUNT(order_id) OVER(PARTITION BY city) as total_orders
FROM Orders
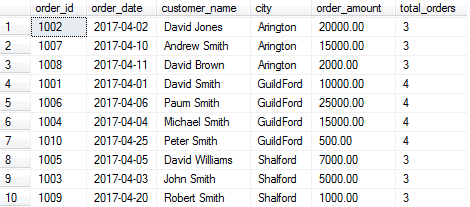
Ranking Window Functions
Giống như các hàm Window aggregate tổng hợp giá trị của một trường được chỉ định, các hàm RANKING sẽ xếp hạng các giá trị của một trường được chỉ định và phân loại theo thứ hạng của chúng.
Việc sử dụng phổ biến nhất của các hàm RANKING là tìm các bản ghi (N) dựa trên một giá trị nhất định. Ví dụ: Top 10 nhân viên được trả lương cao nhất, Top 10 sinh viên được xếp hạng, Top 50 đơn hàng lớn nhất, v.v.
RANK()
Hàm RANK () được sử dụng để xếp hạng duy nhất cho mỗi bản ghi dựa trên một giá trị được chỉ định, ví dụ: salary, amount_orders, v.v.
Nếu hai bản ghi có cùng giá trị thì hàm RANK () sẽ gán cùng một thứ hạng cho cả hai bản ghi bằng cách bỏ qua thứ hạng tiếp theo. Điều này có nghĩa là - nếu có hai giá trị giống hệt nhau ở rank 2 nó sẽ gán cùng rank 2 cho cả hai bản ghi và sau đó bỏ qua rank 3 và gán rank 4 cho bản ghi tiếp theo.
Ví dụ
SELECT order_id,order_date,customer_name,city,
RANK() OVER(ORDER BY order_amount DESC) [Rank]
FROM Orders
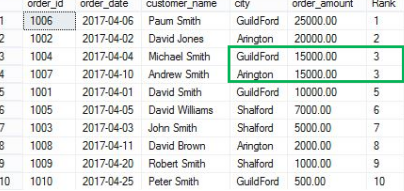
Nhìn vào ví dụ trên, có thể thấy rằng cùng một RANK(3) được gán cho hai bản ghi giống nhau (mỗi bản có order_amount là 15.000) và sau đó bỏ qua Rank tiếp theo (4) và gán Rank 5 cho bản ghi tiếp theo.
DENSE_RANK()
Hàm DENSE_RANK () giống hệt với hàm RANK () ngoại trừ việc nó không bỏ qua bất kỳ Rank nào. Điều này có nghĩa là nếu tìm thấy hai bản ghi giống hệt nhau thì DENSE_RANK () sẽ gán cùng một Rank cho cả hai bản ghi nhưng không bỏ qua rank tiếp theo
SELECT order_id,order_date,customer_name,city, order_amount,
DENSE_RANK() OVER(ORDER BY order_amount DESC) [Rank]
FROM Orders
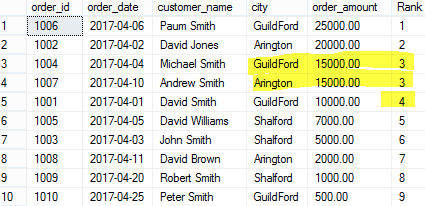
ROW_NUMBER()
Hàm này gán một số hàng duy nhất cho mỗi bản ghi. Số hàng sẽ được đặt lại cho mỗi partition nếu PARTITION BY được chỉ định. Hãy cùng xem cách thức ROW_NUMBER () hoạt động mà không có PARTITION BY và có PARTITION BY.
ROW_ NUMBER() without PARTITION BY
SELECT order_id,order_date,customer_name,city, order_amount,
ROW_NUMBER() OVER(ORDER BY order_id) [row_number]
FROM Orders
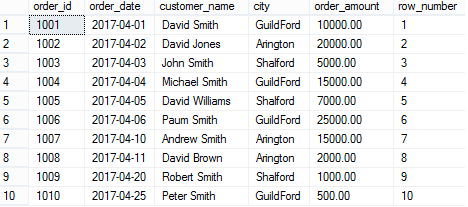
ROW_NUMBER() with PARTITION BY
SELECT order_id,order_date,customer_name,city, order_amount,
ROW_NUMBER() OVER(PARTITION BY city ORDER BY order_amount DESC) [row_number]
FROM Orders
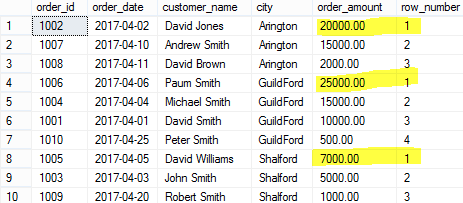
Lưu ý rằng chúng ta đang sử dụng partition với City. Điều này có nghĩa là số hàng được đặt lại cho mỗi city.
Value Window Functions
Value Window Functions được sử dụng để tìm các giá trị first, last, previous và next . Các hàm có thể được sử dụng là LAG (), LEAD (), FIRST_VALUE (), LAST_VALUE ()
LAG() and LEAD()
Các hàm LEAD () và LAG () là những hàm rất mạnh mẽ trong việc tính toán dữ liệu nhưng khó để giải thích cụ thể.
Hàm LAG cho phép truy cập dữ liệu từ hàng trước trong cùng tập kết quả mà không cần sử dụng bất kỳ phép join SQL nào. Bạn có thể thấy trong ví dụ dưới đây, sử dụng hàm LAG, chúng ta đã tìm thấy ngày đặt hàng trước đó.
SELECT order_id,customer_name,city, order_amount,order_date,
LAG(order_date,1) OVER(ORDER BY order_date) prev_order_date
FROM Orders
Hàm LEAD cho phép truy cập dữ liệu từ hàng tiếp theo trong cùng tập kết quả mà không cần sử dụng bất kỳ phép join SQL nào. Bạn có thể thấy trong ví dụ dưới đây, sử dụng hàm LEAD, chúng ta đã tìm thấy ngày đặt hàng sau đó.
SELECT order_id,customer_name,city, order_amount,order_date,
LEAD(order_date,1) OVER(ORDER BY order_date) next_order_date
FROM Orders
FIRST_VALUE() and LAST_VALUE()
Các funtion này giúp bạn xác định bản ghi đầu tiên và bản ghi cuối cùng trong một partition hoặc toàn bộ bảng nếu từ khóa PARTITION BY không được chỉ định.
Ví dụ dưới sẽ tìm ra thứ tự đầu tiên và cuối cùng của mỗi thành phố . Lưu ý mệnh đề ORDER BY là bắt buộc đối với các hàm FIRST_VALUE () và LAST_VALUE ().
SELECT order_id,order_date,customer_name,city, order_amount,
FIRST_VALUE(order_date) OVER(PARTITION BY city ORDER BY city) first_order_date,
LAST_VALUE(order_date) OVER(PARTITION BY city ORDER BY city) last_order_date
FROM Orders
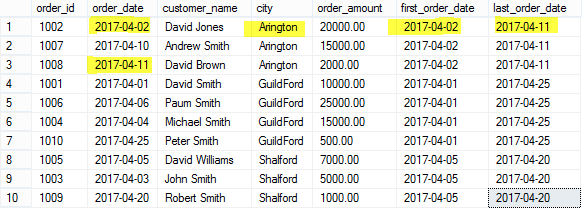
Từ kết quả chúng ta có thể thấy rõ rằng đơn hàng đầu tiên nhận được vào ngày 2017-04 - 02 và đơn hàng cuối cùng nhận được vào ngày 2017-04-11 cho thành phố Arlington và nó hoạt động tương tự cho các thành phố khác.
Kết luận
Qua bài viết trên hy vọng có thề giúp mọi người hiểu thêm về Windows Functions và áp dụng nó vào project của các bạn. Hẹn mọi người trong các bài viết tiếp theo
All rights reserved
