Tìm hiểu DVC (phần 1): Làm quen với một số concept cơ bản của DVC
Bài đăng này đã không được cập nhật trong 2 năm
Giới thiệu
DVC (Data Version Control) là một công cụ quản lý phiên bản cho dữ liệu (Data Version Control) được sử dụng để quản lý các phiên bản của dữ liệu và các tập tin liên quan đến dữ liệu trong các dự án Machine Learning.
Giống như Git, DVC cũng sử dụng hệ thống quản lý phiên bản (version control) để lưu trữ và quản lý các phiên bản của dữ liệu và các tập tin liên quan đến dữ liệu. DVC cho phép người dùng track các thay đổi của dữ liệu từ đó dễ dàng kết hợp với code để reproduce kết quả thực nghiệm. Khi xây dựng một machine learning project cần nhiều thực nghiệm khác nhau, mô hình khác nhau, mỗi mô hình lại chạy với tập dữ liệu khác nhau, dữ liệu lại được xử lý theo nhiều cách khác nhau,... Do đó DVC cực kì hữu ích trong trường hợp này 
Cài đặt
Ta cài đặt DVC đơn giản bằng cách sử dụng lệnh sau
pip install dvc
Khởi động với DVC
Trước khi bắt đầu với những chức năng chính của DVC, chúng ta hay cùng thực hiện một số bước setup đơn giản ban đầu. Như trong doc của DVC đã thực hiện, ta sẽ tạo một folder rỗng là nơi sẽ chứa code cho ML project sau này. Ta thực hiện chạy các câu lệnh sau:
mkdir example-get-started
cd example-get-started
Sau đó, ta sẽ khởi tạo git:
git init
Sau khi khởi tạo git, ta tiếp tục khởi tạo DVC trong Git project:
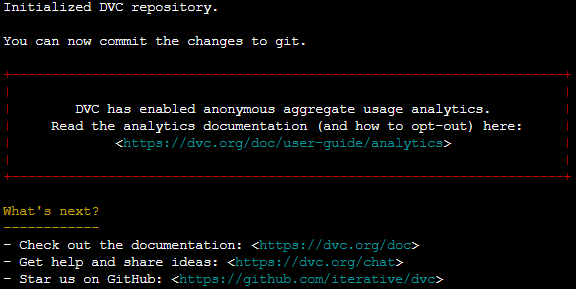
dvc init
Nếu thấy thông báo như hình dưới là okie
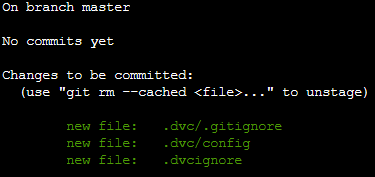
Sau khi khởi tạo DVC, ta kiểm tra thay đổi trong git như sau:
git status
Kết quả:
Sau đó, ta sẽ thực hiện lệnh commit việc khởi tạo DVC
git commit -m "Initialize DVC"
Vậy là xong, DVC đã sẵn sàng cho các nhiệm vụ tiếp theo
Hai use-case chính của DVC là Data management và Experiment tracking, trong đó:
- Data Management là thực hiện track và đánh version cho data đi kèm với code. Việc sử dụng DVC sẽ giúp ta reproduce lại pipeline của quá trình training cũng như là kết quả thực nghiệm.
- Experiment Management là thực hiện quản lý các thực nghiệm. DVC sẽ giúp ta quản lý, chia sẻ và hỗ trợ cộng tác giữa các dev trong và sau quá trình tiến hành thực nghiệm.
Theo kinh nghiệm của mình thì DVC thường ít được sử dụng trong Experiment Management. Trong khuôn khổ bài viết, mình sẽ tập trung mô tả nhiều hơn trong case Data Management. Cấu trúc bài viết sẽ follow theo doc của DVC.
Data Management
Data Versioning
Data versioning là quá trình mà ta quản lý dữ liệu, checkpoints của machine learning model và các file có dung lượng lớn khác. Khi sử dụng DVC, version của data sẽ đi kèm với version của code và tất nhiên các data này sẽ không push lên Git repo. Có thể hiểu rằng, việc sử dụng DVC như ta đang sử dụng Git cho data vậy
Để thử nghiệm xem các thao tác tracking data của DVC như nào, ta cần chọn một data file hoặc folder bất kì. Ở đây, chúng ta sẽ chọn data.xml file như doc của DVC mô tả. Ta sẽ chạy câu lệnh sau:
dvc get https://github.com/iterative/dataset-registry get-started/data.xml -o data/data.xml
DVC sẽ thực hiện download data

Oke done Vậy là ta đã có folder data và trong folder data có chứa 1 file là data.xml.
Chú ý rằng, lệnh dvc get chỉ tải được file hoặc directory mà được track bởi DVC repository, tức là chỉ tải được file hoặc directory từ repo mà được khởi tạo DVC. Để kiểm tra, bạn chỉ cần thấy có xuất hiện file và folder này trong repo là oke

Để tracking data file ta sử dụng câu lệnh dvc add:
dvc add data/data.xml
Kết quả sau khi thực hiện câu lệnh trên:
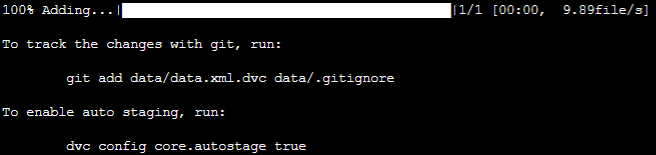
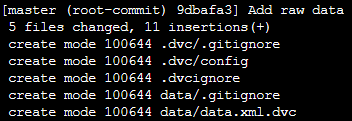
Khi đó DVC sẽ lưu trữ thông tin của việc add file trong .dvc file tên là data/data.xml.dvc.

Sau đó, để track những thay đổi này, ta sử dụng câu lệnh git như sau:
git add data/data.xml.dvc data/.gitignore
git commit -m "Add raw data"
Oke xong
Ta có thể upload DVC-tracked data lên nhiều hệ thống lưu trữ khác nhau. Hiểu đơn giản với git thì ta có github, với DVC ta có Amazon S3, NFS,SSH, Google Drive, Azure Blob Storage, HDFS hoặc có thể là "local remote" (là một folder tại local). Đặc biệt, về mặt thao tác và concept nói chung thì không khác gì khi ta thao tác với git
Nếu muốn hệ thống lưu trữ là một folder tại local, ta sẽ chạy câu lệnh sau:
mkdir /tmp/dvcstore # tạo folder storage bất kì
dvc remote add -d myremote /tmp/dvcstore
Nếu muốn storage là Amazon S3, ta chạy câu lệnh sau:
dvc remote add -d storage s3://mybucket/dvcstore
Oke. Để upload data lên storage ta sẽ sử dụng cậu lệnh dvc push như sau:
dvc push
Khi DVC-tracked data và checkpoints model được lưu trữ trên các hệ thống lưu trữ, ta có thể muốn tải dữ liệu về để sử dụng nếu cần thiết. Khi đó ta sử dụng câu lệnh dvc pull. Thường thì ta sẽ chạy câu lệnh này sau khi chạy lệnh git pull hoặc git clone.
Quay trở lại việc nếu như data thay đổi thì ta sẽ thực hiện cập nhật như nào. Giả sử, sau khi thay đổi nội dung trong file data.xml, ta sẽ cập nhật sự thay đổi như sau:
dvc add data/data.xml
Sau đó, ta thực hiện dvc push để cập nhật sự thay đổi trên remote storage.
dvc push
git commit data/data.xml.dvc -m "Dataset updates"
Để chuyển giữa các version của data cũng như ta thực hiện với git trên code vậy. Câu lệnh sẽ như sau:
git checkout <...>
dvc checkout
Ví dụ để quay trở lại version trước của data. Ta làm như sau:
git checkout HEAD~1 data/data.xml.dvc
dvc checkout
Sau đó thực hiện commit. Tại đây, ta không cần dvc push vì version trước đó của dataset đã được lưu rồi.
git commit data/data.xml.dvc -m "Revert dataset updates"
Ta sẽ thấy là về mặt kĩ thuật DVC không phải là một version control system. Nó chỉ thao tác trên các .dvc file, nội dung các file xác định version của data file. Về bản chất Git sử dụng để version code và cũng là version luôn data
Data Pipelines
Việc version data trong các dự án ML là rất cần thiết nhưng thường chưa đủ. Data thường được biến đổi theo nhiều cách trước khi được fit vào các mô hình ML, DL. Với mục đích đó, DVC giới thiệu một hệ thống hỗ trợ định nghĩa, thực thi và track data pipeline.
DVC pipeline được version sử dụng Git, cho phép tổ chức project khoa học hơn, đặc biệt là có thể reproduce workflow và kết quả.
Để rõ hơn, ta sẽ thực nghiệm trên một repo giả định mà doc của DVC cung cấp.
wget https://code.dvc.org/get-started/code.zip
unzip code.zip && rm -f code.zip
Dữ liệu được sử dụng cho repo này được lấy như sau:
dvc get https://github.com/iterative/dataset-registry get-started/data.xml -o data/data.xml
Mình sẽ bỏ qua việc setup môi trường vì việc này khá là cơ bản (và nhàm chán) rồi 
Sau khi cài cắm đủ thì ta sẽ chạy lệnh commit như sau là okay:
git add .github/ data/ params.yaml src .gitignore
git commit -m "Initial commit"
Ta sử dụng lệnh dvc stage add để tạo stage cho dữ liệu. Stage ở đây có thể hiểu là các bước xử lý dữ liệu trong pipeline data. Stage cho phép connect code với data input và output tương ứng. Thực hiện biến đổi Python script thành một stage qua câu lệnh sau:
dvc stage add -n prepare \
-p prepare.seed,prepare.split \
-d src/prepare.py -d data/data.xml \
-o data/prepared \
python src/prepare.py data/data.xml
Sau khi chạy lệnh trên, file dvc.yaml được tạo. File này lưu thông tin của câu lệnh ta muốn chạy (trong câu lệnh trên là python src/prepare.py data/data.xml), các phụ thuộc và output.
Chi tiết một số option được sử dụng như sau:
-n preparechỉ định tên của stage (ở đây tên là prepare.-p prepare.seed,prepare.splitchỉ định các phụ thuộc hay parameter. Thường khi code ta hay có file config có đuôi là.yamlthì parameter ở đây giống như các giá trị lưu trong file.yaml.-d src/prepare.pyvà-d data/data.xmlcó nghĩa là stage phụ thuộc vào các filesrc/prepare.pyvàdata/data.xml.-o data/preparedlà folder lưu output của script.- Cuối cùng
python src/prepare.py data/data.xmllà command được run trong stage.
Cuối cùng file dvc.yaml sẽ như sau:
stages:
prepare:
cmd: python src/prepare.py data/data.xml
deps:
- src/prepare.py
- data/data.xml
params:
- prepare.seed
- prepare.split
outs:
- data/prepared
Sau khi thêm stage, ta có thể chạy pipeline bằng lệnh dvc repro.
Tất nhiên rằng, ta cần nhiều bước processing để cho ra được 1 data chuẩn chỉnh. Do đó, ta cần xây dựng một đồ thị các stage mà mỗi stage tương ứng với thao tác nào đó trên data
Tiếp tục từ stage trước, ta sẽ tạo thêm một stage thao tác trên output của stage prepare. Stage này có nhiệm vụ thực hiện trích xuất feature:
dvc stage add -n featurize \
-p featurize.max_features,featurize.ngrams \
-d src/featurization.py -d data/prepared \
-o data/features \
python src/featurization.py data/prepared data/features
Sau khi chạy lệnh trên, file dvc.yaml tiếp tục được cập nhật lên 2 stage.
Cuối cùng, ta sẽ thêm stage train:
dvc stage add -n train \
-p train.seed,train.n_est,train.min_split \
-d src/train.py -d data/features \
-o model.pkl \
python src/train.py data/features model.pkl
Vậy ta đã có 3 stage. Sau đó, ta sẽ commit thay đổi vào Git.
git add .gitignore data/.gitignore dvc.yaml
git commit -m "pipeline defined"
Okay Vậy ta đã sẵn sàng để chạy pipeline. Thông tin về pipeline được lưu trong dvc.yaml, ta thực hiện reproduce pipeline như sau:
dvc repro
Sau khi chạy command trên, file dvc.lock được tạo để lưu kết quả reproduction. Sau khi chạy xong ta sẽ thực hiện commit.
git add dvc.lock && git commit -m "first pipeline repro"
Ta có thể visualize đồ thị bằng lệnh dvc dag.
+---------+
| prepare |
+---------+
*
*
*
+-----------+
| featurize |
+-----------+
*
*
*
+-------+
| train |
+-------+
Kết luận
Vậy ta đã đi qua concept và thao tác cơ bản nhất của DVC. Trong bài viết tới, mình sẽ chia sẻ cách kết hợp DVC với một số stack khác trong một project hoàn chỉnh.
Tham khảo
All rights reserved
