Spatial Transformation trong Adversarial ML
Bài đăng này đã không được cập nhật trong 5 năm
Introduction
Từ trước đến nay, khi nhắc đến adversarial examples, chúng ta đều thường nghĩ đến những chiến lược tấn công dựa trên hoặc . Tuy nhiên, đây chưa hẳn là một thước đo lí tưởng bởi thường rất nhạy cảm với những tác nhân như ánh sáng của ảnh, v..v... Chẳng hạn như chúng ta dịch cả ảnh tăng lên 1 pixel cũng có thể tạo nên sự thay đổi lớn cho . Bởi vậy nên chúng ta cần có một hướng đi mới, và xin giới thiệu Spatially Transformed Adversarial Examples hay tạm gọi là biến dạng hình ảnh.
Related Work
Adversarial Examples: Trong một mô hình phân loại ảnh (image classification), với mỗi một ảnh đưa qua mô hình (sample x), nếu chúng ta thêm vào đó một sự "nhiễu loạn" nhỏ (noise/perturbation), mặc dù đối với nhận thức của con người thì bức ảnh không hề xuất hiện một sự thay đổi nào nhưng khi đưa qua mô hình phân loại, máy sẽ trả lại kết quả không chính xác so với kết quả ban đầu. Dưới đây là ví dụ một bức ảnh được phân loại là "Pig", nhưng sau khi thêm noise đã làm cho mô hình phân loại sai thành "Airliner" (tìm hiểu thêm tại đây)
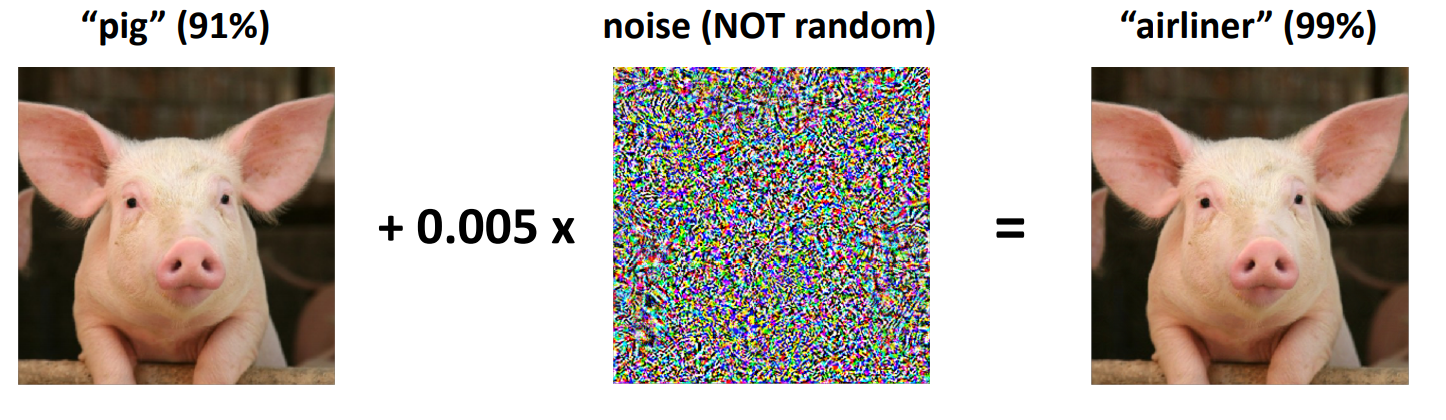
Vậy những sample khiến cho mô hình đã được trained phân loại nhầm được gọi là adversarial examples, kí hiệu là (, với là noise đã nói ở trên)
Defensive method: Việc lợi dụng adversarial example để khiến mô hình đưa ra phán đoán sai lệch được gọi là adversarial attacks và để đảm bảo cho các mô hình khi sử dụng có khả năng kháng lại những sự tấn công từ adversarial example thì những defensive methods đã được ra đời. Có thể kể đến các phương pháp như adversarial training, distilllation, feature squeezing, ensemble và hơn nữa.
Tạo Adversarial Examples
Pixel-based Attacks:
- Fast Gradient Sign Method: là một phương thức tấn công bậc nhất đơn giản sử dụng gradient ascent để tạo nên adversarial example sử dụng công thức:
Trong đó, là hàm mất mát được sử dụng để huấn luyện mô hình g, y là nhãn đúng và điều khiển perturbation được thêm vào ảnh.
- C&W: tạo nên adversarial examples có chủ đích (targeted) dựa trên một số ràng buộc được thể hiện qua công thức:
Trong đó, được sử dụng để đảm bảo rằng nhỏ. Công thức có thể được thay đổi với cho các adversarial examples không có chủ đích (untargeted).
Spatial Transformation Attack:
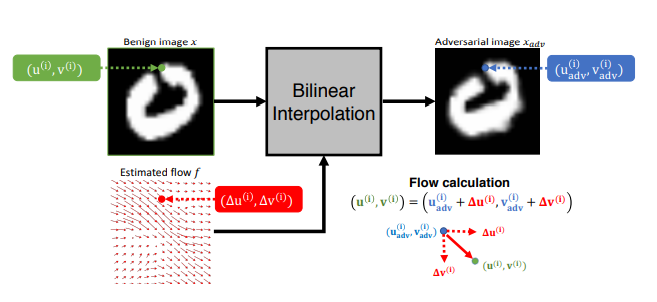
Sở dĩ gọi là phương pháp "biến đổi không gian" là bởi thay vì chúng ta trực tiếp thay đổi giá trị pixel như ở các phương pháp tấn công trước kia, thì giờ một trường chuyển dời (flow field) f sẽ được tạo nên. Có thể hiểu trường f sẽ chứa các véc-tơ giúp xác định hướng biến đổi của các pixels trong ảnh.
Một bức ảnh sẽ được biểu diễn dưới dạng một ma trận khi cho vào mô hình, vậy mỗi vị trí của một pixel sẽ được biểu diễn qua (u, v). Một adversarial examples tại vị trí ith pixel sẽ được kí hiệu . Tại đây, chúng ta sẽ tối ưu hóa một véc-tơ chuyển dời , véc-tơ này có chiều đi từ ith pixel của đến ith pixel của vì vậy chúng ta có sự biểu diễn . Sử dụng differentiable bilinear interpolation, công thức mới dưới đây sẽ được tạo ra để biến đổi ảnh đầu vào
Trong đó, tập là tập hợp các tọa độ của các pixels trên, dưới, trái, phải của pixel . Áp dụng công thức trên với i là toàn bộ các pixels của ảnh ta sẽ thu được .
Các phương pháp tấn công trước đây đều bị giới hạn lượng perturbation được thêm vào ảnh dựa trên , tuy nhiên phương pháp tấn công mới này sẽ đưa ra một khái niệm hàm regularization loss mới . Từ đó, mục tiêu của phương pháp tấn công mới trở thành tạo nên các adversarial examples có thể đánh lừa được mô hình đồng thời tối thiểu hóa sự bóp méo của hình ảnh đến từ trường chuyển dời (flow field) f. Vậy trường chuyển dời (flow field) được tính như thế nào?
Trong đó, hàm khuyến khích sự lệch nhãn khi đưa adversarial example vào mô hình, hàm giảm thiểu sự bóp méo hình ảnh để vẫn giữ nguyên được đa phần hình dạng ban đầu để không dẫn tới sự sai lệch nhận thức và biến số giúp cân bằng giữa 2 hàm mất mát này
Ngoài ra, trong tấn công có chủ đích (targeted attack), hàm còn đóng vai trò đảm bảo rằng với là mô hình đang sử dụng và là nhãn chúng ta đang hướng tới, khác với nhãn đúng . Để làm được vậy, chúng ta sẽ áp dụng tương tự phương pháp tấn công C&W đã được nhắc đến ở trên:
là biểu diễn cho véc-tơ output của mô hình đang sử dụng, chỉ thành phần thứ của véc-tơ và tượng trưng cho confidence level.
Về hàm , hàm này sẽ được tính bằng cách tính tổng khoảng cách dịch chuyển của của 2 pixels bất kì cạnh nhau. Có thể dễ dàng hình dung được rằng khi hàm nay được tối thiểu hóa, sự bóp méo hình ảnh cũng được giảm xuống mức thấp nhất, giữ được đa phần hình ảnh gốc vì các pixels kề nhau thường có xu hướng di chuyển theo hướng và khoảng cách gần. Chúng ta có công thức:
trong đó là một pixel trong ảnh và là các pixels kề cạnh pixel .
Kết quả thực nghiệm


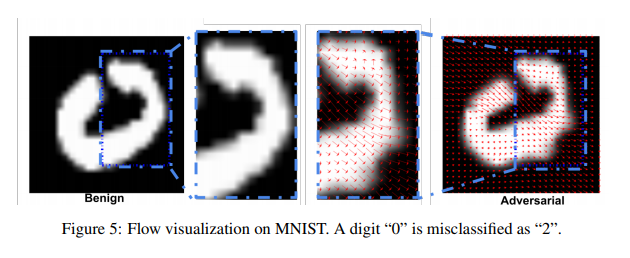
Ảnh và kết quả được lấy tại đây.
Quan điểm cá nhân
Đây là một phương pháp tấn công mới, cho thấy các mô hình hiện tại của chúng ta tuy rằng đã cho thấy những kết quả rất tốt nhưng vẫn còn tồn tại những lỗ hổng và thiếu sót. Và cũng mở ra một hướng nghiên cứu mới về an ninh mô hình khi phương pháp này không đi theo những lối mòn của các phương án trước kia sử dụng để tạo adversarial examples
All rights reserved
