
So sánh các mô hình dự đoán trong bài toán nhận dạng khuôn mặt và ví dụ thực tế
Bài đăng này đã không được cập nhật trong 4 năm
Chào tất cả các bạn. Lời đầu tiên cho mình xin gửi lời chúc đến các bạn một năm 2017 thật mạnh khỏe và thành công nhé. Không biết các bạn thế nào nhưng riêng với mình không có điều gì ý nghĩa hơn việc viết một bài Viblo thật hay trong ngày đầu tiên đi làm của năm mới này. Tiếp tục với Machine Learning nhưng hôm nay chúng ta sẽ bàn luận một chủ đề mới đó là Nhận dàng khuôn mặt. Chúng ta có thể kể đến rất nhiều ứng dụng của nhận dạng khuôn mặt, tiêu biểu như việc Facebook tự động gắn thẻ một người nào đó khi đăng ảnh đó. Có bao giờ bạn hỏi rằng đằng sau một chức năng đơn giản đó là những gì không? Hẳn câu trả lời của rất nhiều người là Hmm.. phức tạp lắm phải không nào? Thật vậy, chắc chắn những thuật toán học máy phía sau một hệ thống lớn như Facebook quả thực không tầm thường. Tuy nhiên chúng ta hoàn toàn có thể tìm hiểu ngay từ các thuật toán đơn giản quen thuộc như Hồi quy tuyến tính hoặc Hồi quy Ridge hay K Nearest Neighbor... Bài viết này sẽ giúp các bạn tìm hiểu được các bước cơ bản của nhận dạng hình ảnh và so sánh hiệu quả nhận dạng giữa các phương pháp kể trên.
Chuẩn bị tâm lý
Bài này rất ít thứ để chém gió, cũng không có nhiều hoa hoét như bài trước, hình ảnh trong bài toàn gái xấu, thậm chí còn rất xấu nên bài này tự mình thấy khá là buồn ngủ nên các bạn có thể vừa đọc vừa nghe MV mới nhất của Sơn Tùng MTP cho đỡ buồn nhé. Bài Lạc Trôi đó.  OK nếu đã sẵn sàng rồi thì chúng ta bắt đầu thôi. Let goooo.....
OK nếu đã sẵn sàng rồi thì chúng ta bắt đầu thôi. Let goooo.....
Tập dữ liệu khuôn mặt Olivetti
Để thử nghiệm bất cứ thuật toán học máy nào chúng ta cũng cần phải có một tập dữ liệu phải không nào. Tập dữ liệu có thể coi là linh hồn của một bài toán học máy. Và với các tập dữ liệu hình ảnh chúng ta thường sử dụng một tập dữ liệu rất nỏi tiếng đó là tập dữ liệu Olivetti. Chúng ta có thể tải tập dữ liệu này tại đây. Tập dữ liệu này được thu thập tại Cambridge University Engineering Department nhằm phục vụ mục đích nghiên cứu thử nghiệm các thuật toán nhận dạng hình ảnh tại đây. Tập dữ liệu thu thập 10 bức ảnh ở các trạng thái khác nhau như nhắm mắt, mở mắt, cười, không cười, soi gương... của 40 người. Chúng ta có thể hình dung 10 trạng thái của một người như sau:

Trong bài viết này chúng ta sẽ sử dụng các mô hình dự đoán kể trên để dự đoán nửa dưới của khuôn mặt khi đầu vào là nửa trên của khuôn mặt đó. Cụ thể chúng ta sẽ sử dụng các mô hình sau để cài đặt:
Trong phạm vi của bài viết mình sẽ không trình bày cụ thẻ chi tiết của nội dung từng thuật toán này. Các bạn có thể tham khảo thêm ở các đường link tương ứng. Bây giờ chúng ta sẽ cung nhau tìm hiểu các bước của bài toán xử lý hình ảnh nhé. Cụ thể như đã mô tả ở đầu bài viết, kết quả của việc này đó là với đầu vào là nửa trên của khuôn mặt ta sẽ dự đoán được đầu ra là nửa dưới của khuôn mặt đó bằng việc áp dụng các phương pháp khác nhau. OK chúng ta tiếp tục nào
Số hóa hình ảnh
Chúng ta hãy tưởng tưởng hình ảnh của chúng ta là một lưới các điểm ảnh gọi là pixel. Ứng với mỗi điểm ảnh chúng ta có một màu khác nhau được đánh dấu theo thứ tự từ 0 đến 255 sử dụng phương pháp nghịch đảo giá trị này chúng ta có tương ứng với mỗi pixel là một số thực nằm trong khoảng từ 0 đến 1. Chúng ta có thể hình dung dễ dàng hơn về cách số hóa hình ảnh này thông qua hình bên dưới

Tập dữ liệu của chúng ta được mã hóa với 256 màu như trên được biểu diễn bằng một dãy nhị phân 8 bit cho mỗi pixel. Loader của chương trình khi nạp dữ liệu sẽ convert mỗi pixel sang một số thực nằm trong khoảng từ 0 đến 1 giúp thuận tiện hơn cho rất nhiều thuật toán. Trong tập dữ liệu chính thống thì số chiều của mỗi ma trận điểm ảnh là 92 x 112 tuy nhiên trong thư viện Scikit Learn của Python đã giảm số chiều này xuống còn 64 x 64 để thuận lời cho việc tính toán sau này.
Xử lý dữ liệu với Python
Vẫn như các bài viết trước của mình về Machine Learning chúng ta sẽ vẫn sử dụng Python để xử lý dữ liệu. Trước tiên chúng ta cần import các thư viện cần thiết để sử dụng trong chương trình của chúng ta:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_olivetti_faces
from sklearn.utils.validation import check_random_state
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.neighbors import KNeighborsRegressor
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import RidgeCV
Chúng ta cần sử dụng numpy để tính toán các phép toán về ma trận cũng như sử dụng matplotlib.pyplot để vẽ đồ thị biểu diễn kết quả của chúng ta. Từ thư viện nổi tiếng sklearn chúng ta có thể sử dụng các thuật toán Machine Learning kể trên cho mô hình dự đoán của chúng ta.
Load tập dữ liệu từ thư viện datasets
# Load the faces datasets
data = fetch_olivetti_faces()
targets = data.target
data = data.images.reshape((len(data.images), -1))
train = data[targets >= 10]
test = data[targets < 10] # Test on independent people
Thông qua hàm fetch_olivetti_faces() chúng ta sẽ lấy được tập dữ liệu Olivetti với targets từ 0 đến 39 ở đây là các chỉ mục được đánh số từ 0 đến 40 tương ứng với 40 người khác nhau trong tập dữ liệu khuôn mặt. Chúng ta sử dụng 10 người đầu tiên để làm tập dữ liệu kiểu trong cho mô hình trong khi sử dụng 30 người còn lại để làm tập dữ liệu huấn luyện.
Xác định tập dữ liệu huấn luyện và tập dữ liệu kiểm tra
Như đã mô tả, theo yêu cầu đặt ra của bài toán là khi chúng ta cho đầu vào là nửa trên của một khuôn mặt, thuật toán sẽ tính toán các tham số và dự đoán ra nửa dưới của khuôn mặt tương ứng. Một biểu diễn rât trực quan là chúng ta sẽ có vector X đại diện cho các đại lượng đã biết chính là các nửa trên của ma trận điểm ảnh. vector y cần dự đoán chính là nửa dưới của ma trận đó. Hai ma trận này có số chiều bằng nhau do đó việc áp dụng các mô hình dự đoán bản chất là tìm ra hàm phụ thuộc y = f(X) tương tự như các bài toán dự đoán của chúng ta đã làm ở các bài viết trước của mình vậy.
# Test on a subset of people
n_faces = 6
rng = check_random_state(4)
face_ids = rng.randint(test.shape[0], size=(n_faces, ))
test = test[face_ids, :]
n_pixels = data.shape[1]
X_train = train[:, :np.ceil(0.5 * n_pixels)] # Upper half of the faces
y_train = train[:, np.floor(0.5 * n_pixels):] # Lower half of the faces
X_test = test[:, :np.ceil(0.5 * n_pixels)]
y_test = test[:, np.floor(0.5 * n_pixels):]
Ngoài ra chúng ta chỉ lựa chọn 6 trong 10 đối tượng của tập dữ liệu kiểm tra nhằm dễ dàng cho việc quan sát. Sử dụng các hàm **np.floor **và np.cell chúng ta sẽ lấy được các phần trên và dưới của hình ảnh dưới dạng ma trận các điểm ảnh. Vậy là đã xong việc xác định tập dữ liệu huấn luyện và tập dữ liệu kiểm tra. Việc còn lại của chúng ta là đi cài đặt các thuật toán trên tập dữ liệu này và đánh giá hiệu quả của từng thuật toán.
Sử dụng các mô hình học máy vào nhận dạng hình ảnh
Sau khi có được tập dữ liệu, việc cần làm là xử lý thế nào với tập dữ liệu đó, không thì chúng ta sẽ chẳng thu được kết quả gì cả. Đầu tiên chúng ta sẽ định nghĩa một object tên là ESTIMATORS chứa tất cả các ESTIMATORS của chúng ta - chính là các phương pháp mà mình đã liệt kê tại phần trên. Sau đó chúng ta sử dụng một vòng for để áp dụng các mô hình cho tập dữ liệu huấn luyện, đồng thời kiểm tra luôn trên tập dữ liệu kiểm tra và lưu vào y_test_predict:
# Fit estimators
ESTIMATORS = {
"Extra trees": ExtraTreesRegressor(n_estimators=10, max_features=32,
random_state=0),
"K-nn": KNeighborsRegressor(),
"Linear regression": LinearRegression(),
"Ridge": RidgeCV(),
}
y_test_predict = dict()
for name, estimator in ESTIMATORS.items():
estimator.fit(X_train, y_train)
y_test_predict[name] = estimator.predict(X_test)
y_test_predict lúc này sẽ lưu lại kết quả của từng thuật toán và ta sẽ sử dụng chúng trong việc vẽ đồ thị biểu diễn kết quả.
Vẽ đồ thị biểu diễn kết quả
Đây có lẽ là phần mình thích nhất trong mỗi lần làm về Machine Learning vì mình có thói quen kiểm tra kêt quả một cách trực quan bằng đồ thị hơn là các con số. Chúng ta hãy tưởng tượng với một một khuôn mặt được dự doán bằng 4 thuật toán khác nhau nên chúng ta sẽ cần phải vẽ 5 hình cho mỗi khuôn mặt nhằm so sánh kết quả của 4 hình tìm ra bởi 4 thuật toán và 1 hình gốc ban đầu. Mỗi hình có kích cỡ là 64 x 64 pixels. Chúng ta thực hiện ý tưởng đó như sau:
# Plot the completed faces
image_shape = (64, 64)
n_cols = 1 + len(ESTIMATORS)
Sau khi đã có 5 cột biểu diễn 5 bức ảnh chúng ta thực hiện vẽ các ảnh tương ứng với dữ liệu vừa dự đoán được
for i in range(n_faces):
true_face = np.hstack((X_test[i], y_test[i]))
if i:
sub = plt.subplot(n_faces, n_cols, i * n_cols + 1)
else:
sub = plt.subplot(n_faces, n_cols, i * n_cols + 1,
title="true faces")
sub.axis("off")
sub.imshow(true_face.reshape(image_shape),
cmap=plt.cm.gray,
interpolation="nearest")
for j, est in enumerate(sorted(ESTIMATORS)):
completed_face = np.hstack((X_test[i], y_test_predict[est][i]))
if i:
sub = plt.subplot(n_faces, n_cols, i * n_cols + 2 + j)
else:
sub = plt.subplot(n_faces, n_cols, i * n_cols + 2 + j,
title=est)
sub.axis("off")
sub.imshow(completed_face.reshape(image_shape),
cmap=plt.cm.gray,
interpolation="nearest")
plt.show()
Kết quả so sánh các thuật toán
Sau khi chạy chương trình chúng ta có được đồ thị biểu diễn kết quả của các thuật toán như sau:
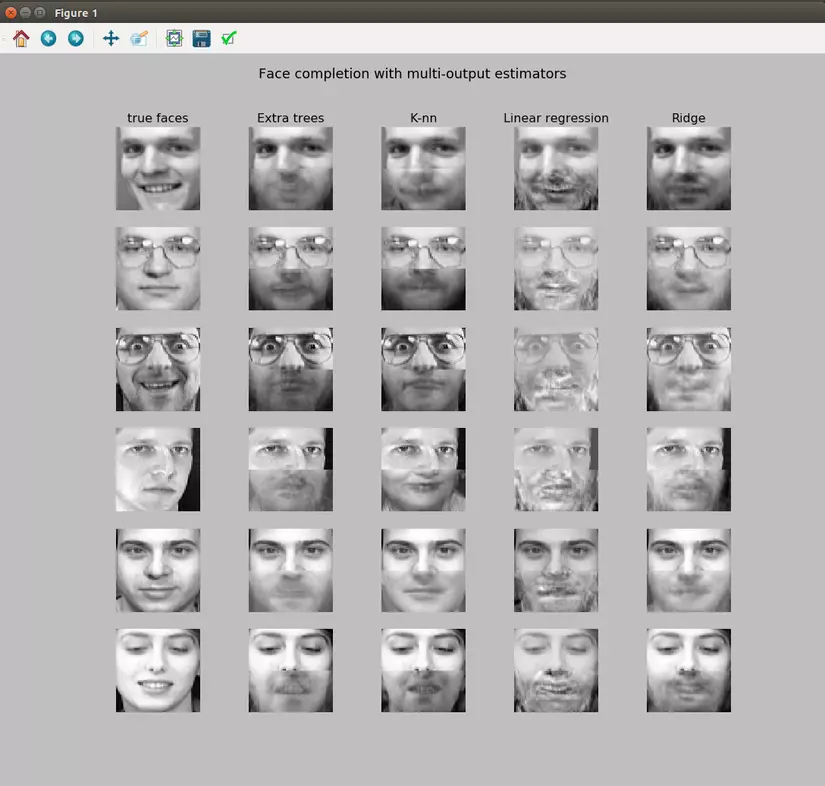 Một cách trực quan chúng ta có thể thấy rằng các thuật toán Hồi quy tuyến tính , Cây quyết định, Hồi quy Ridge và K Nearest Neighbor lần lượt cho kết quả dự đoán nửa dưới của khuôn mặt khác nhau. Có thể thấy rằng Hồi quy tuyến tính cho độ mượt kém nhất so với các phương pháp còn lại. Cá nhân mình nghĩ rằng Cây quyết định hoặc Hồi quy Ridge thích hợp cho bài toán nhận dạng này
Một cách trực quan chúng ta có thể thấy rằng các thuật toán Hồi quy tuyến tính , Cây quyết định, Hồi quy Ridge và K Nearest Neighbor lần lượt cho kết quả dự đoán nửa dưới của khuôn mặt khác nhau. Có thể thấy rằng Hồi quy tuyến tính cho độ mượt kém nhất so với các phương pháp còn lại. Cá nhân mình nghĩ rằng Cây quyết định hoặc Hồi quy Ridge thích hợp cho bài toán nhận dạng này
Kết luận
Qua bài viết này mình rất hi vọng có thể giúp các bạn hiểu rõ hơn về ứng dụng của Học máy vào nhận dạng khuôn mặt. Về ứng dụng thực tế của nó thì có lẽ không phải bàn cãi nhiều tuy nhiên để có được những mô hình thực sự tốt hơn nữa, có khả năng ứng dụng vào thực tế thì đòi hỏi chúng ta phải đào sâu nghiên cứu rất nhiều.
Code sử dụng trong bài
Tài liệu tham khảo
All rights reserved
