
Separable Convolutions - Toward realtime object detection applications
Bài đăng này đã không được cập nhật trong 4 năm
I. Introduction
Xin chào mọi người, chắc hẳn mọi người ở đây ai đã từng làm việc với mô hình mạng CNN MobileNet thì đều đã nghe đến cái tên Separable Convolutions, một kỹ thuật mới vô cùng mạnh mẽ giúp giảm lượng tham số mô hình trong mạng CNN mà vẫn đáp ứng đẩy đủ các yêu cầu trong việc học các features của ảnh, với separable convolutions, chúng ta có thể hướng đến việc giải quyết các bài toán realtime khả thi hơn rất nhiều so với các mô hình mạng CNN truyền thống. Ở bài viết này chúng ta sẽ cùng nhau tìm hiểu xem Separable Convolutions là gì, tác dụng của nó là gì, tại sao nên sử dụng và nó khác gì so với Normal Convolutions.
Chúng ta sẽ có 2 loại chính của Separable Convolutions: Spatial Separable Convolutions và Depthwise Separable Convolutions. Cùng đi chi tiết vào 2 loại này nào!
II. Spatial Separable Convolutions
Về mặt lý thuyết, spatial separable convolutions(ssc) sẽ chia 1 convolution thành 2 bước thay vì một như trước, giúp giảm lượng phép tính cần phải thực hiện. Tuy nhiên, ssc có một vài hạn chế dẫn đến việc nó không được sử dụng rộng rãi trong Deep Learning.
spatial separable convolutions được đặt tên như vậy là bởi vì nó dùng chủ yếu với spatial dimensions của ảnh và kernel, nghĩa là với width và height (chúng ta còn 1 dimension của ảnh khác là "depth" là số lượng các channels của ảnh).
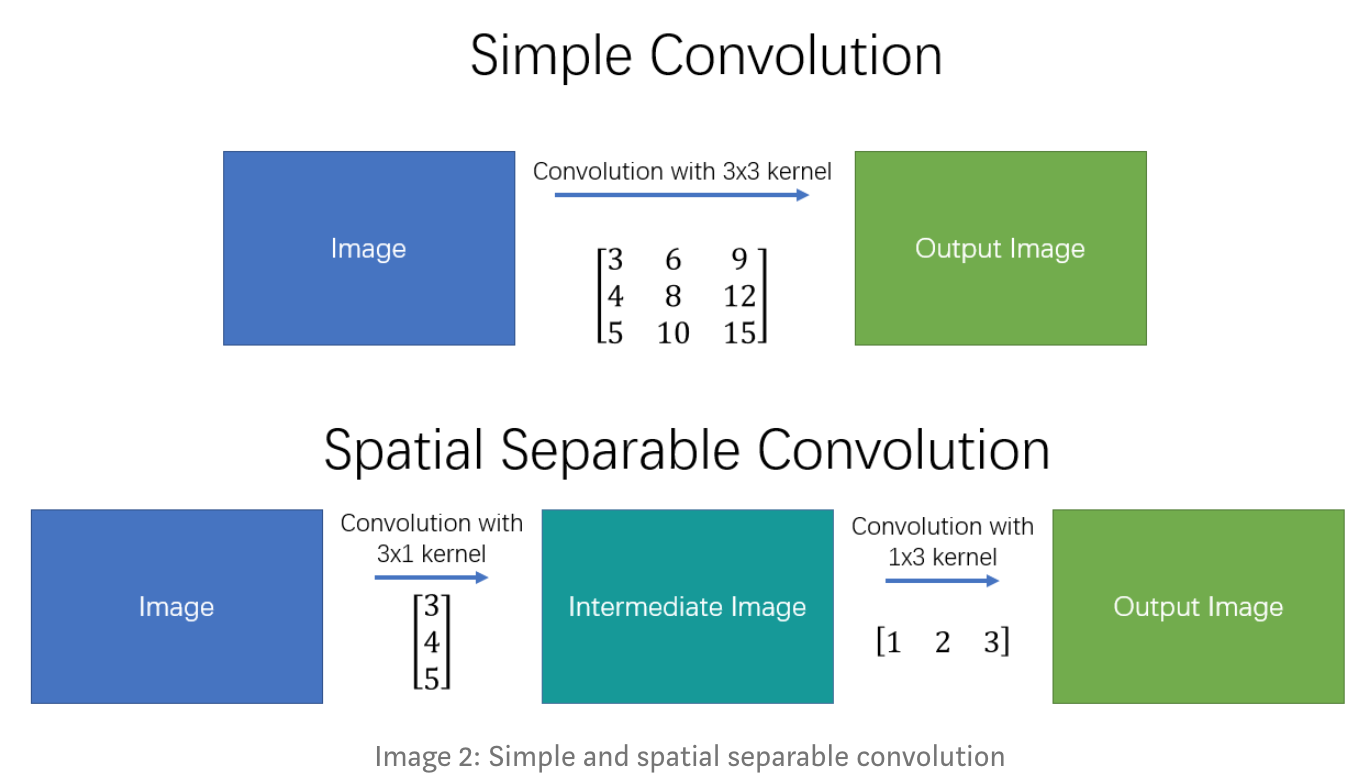
Dưới đây sẽ là một ví dụ, spatial separable convolutions chia 1 kernel 3x3 thành 2 kernel nhỏ hơn là 3x1 và 1x3, như sau:
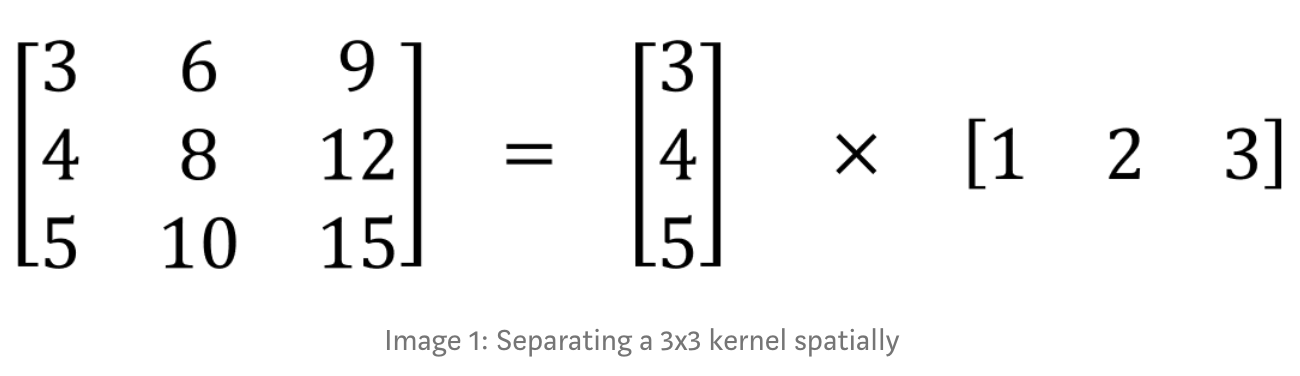
Hãy lấy ví dụ với Sobel kernel:
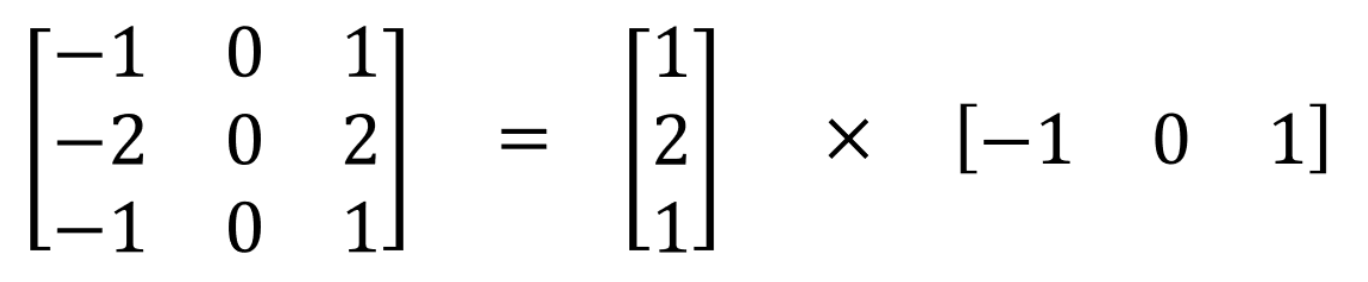
Ở đây, thay vì thực hiện 1 convolution với 9 phép nhân thì nó chỉ dùng 3 phép nhân cho mỗi kernel nhỏ nghĩa là 6 phép nhân tất cả để đặt được kết quả tương tự như với convolution thông thường. Như vậy, khi số lượng các phép nhân giảm đi, độ phức tạp tính toán cũng giảm xuống và mô hình của chúng ta cũng run nhanh hơn.
Vấn đề chính đối với spatial separable convolutions đó là không phải tất cả kernel đều có thể chia thành 2 kernel nhỏ hơn, dẫn đến khó khăn trong quá trính chúng ta training. Đó là lý do vì sao nó không được sử dụng nhiều trong Deep Learning.
III.Depthwise Separable Convolutions
Không giống spatial separable convolutions, depthwise separable convolutions hoạt động được với các kernel không thể chia thành các kernel nhỏ hơn. Chúng ta có 2 loại này trong keras và tensorflow tương ứng là keras.layers.SeparableConv2D và tf.layers.separable_conv2d. Nó không chỉ hoạt động được với spatial dimension mà còn được với cả depth dimension của image.
Ý tưởng tương tự với spatial separable convolution, depthwise separable convolutions chia 1 kernel thành 2 kernel riêng biệt là depthwise convolution và pointwise convolution để thực hiện 2 convolution. Trước khi chúng ta đi chi tiết hơn về cái cách mà depthwise và pointwise convolution thực hiện, hãy cùng xem lại cách mà convolution thông thường hoạt động như thế nào.
1. Normal Convolution
Giả sử có một input image có kích thước 12x12x3, bây giờ chúng ta sẽ thực hiện 1 convolution có cửa sổ 5x5 lên input image với no padding và stride=1. Nếu chỉ xét trên width và height của image, thì quá trình convolution sẽ là: 12x12 — (5x5) — >8x8. Kernel 5x5 lướt qua toàn bộ ảnh, mỗi lần thực hiện 25 phép nhân và trả về 1 output, vì là no padding nên chúng ta sẽ nhận được (12-5+1)=8x8 pixels ảnh đầu ra.
Tuy nhiên, ảnh đầu vào có 3 channels, dẫn đến việc chúng ta phải thực hiện convolution trên cả 3 channels này, nghĩa là thay vì 25 phép nhân như trước thì giờ là 75 phép nhân mỗi lần kernel dịch chuyển.
Tương tự với chiều không gian 2 chiều, với không gian 3 chiều chúng ta cũng thực hiện phép nhân ma trận vô hướng trên tất cả 25 pixels và trả về 1 number. Sau khi kernel 5x5x3 lướt qua toàn bộ ảnh, 12x12x3 image sẽ trở thành 8x8x1.
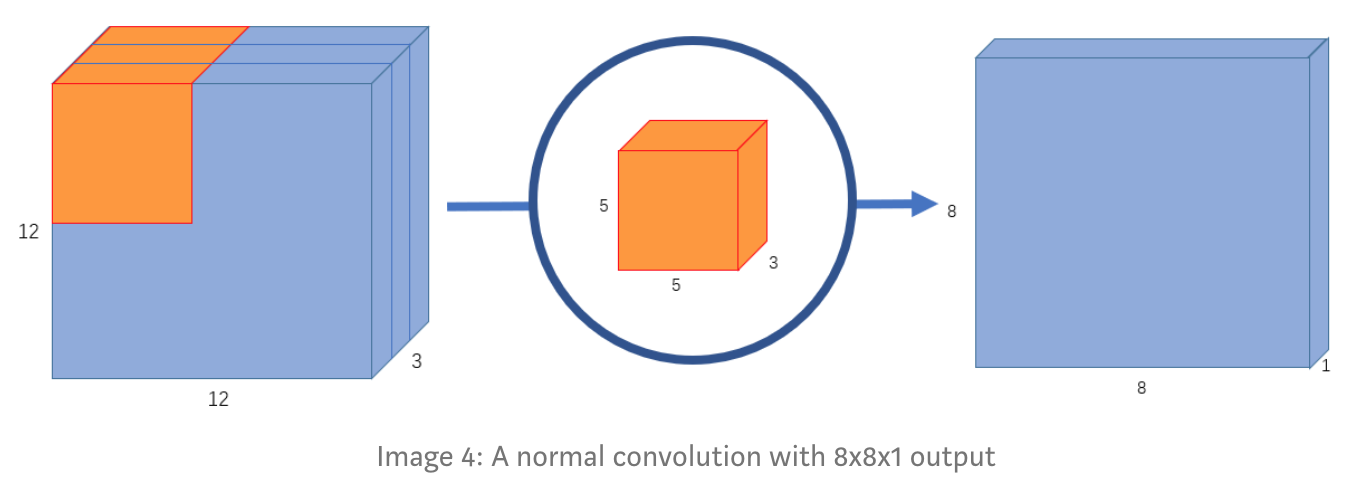
Câu hỏi đặt ra là, nếu chúng ta tăng số channels output thì sẽ ra sao, ví dụ 8x8x256. Như vậy, chúng ta sẽ phải tạo ra 256 kernel 5x5x3, sau khi tất cả kernel thực hiện xong chúng ta sẽ gộp tất cả các output lại để thu được 8x8x256 image output.
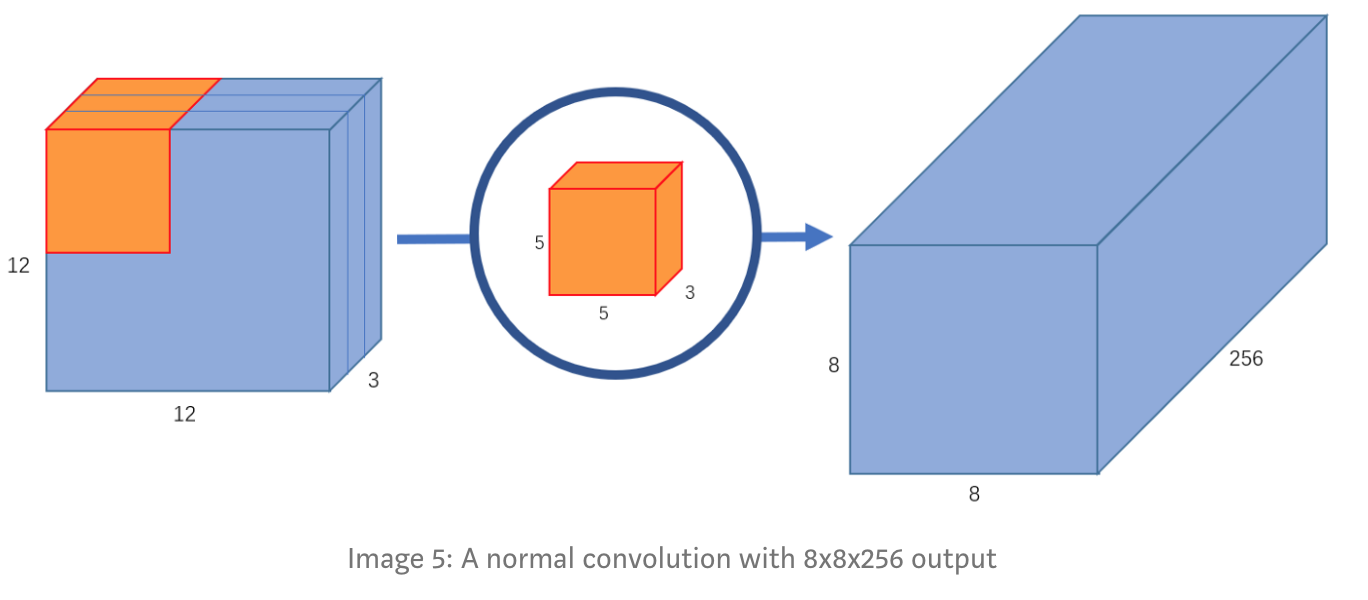
Đó chính là cách mà một convolution thông thường hoạt động, tóm tắt lại quá trình như sau:
12x12x3 — (5x5x3x256) — > 8x8x256. Tiếp theo chúng ta sẽ nói đến depthwise convolution và pointwise convolution.
2. Depthwise Convolution
Đầu tiên, ở đây chúng ta sẽ thực hiện convolution trên input image mà không làm thay đổi số lượng channels của ảnh, bằng cách sử dụng 3 kernel 5x5x1.
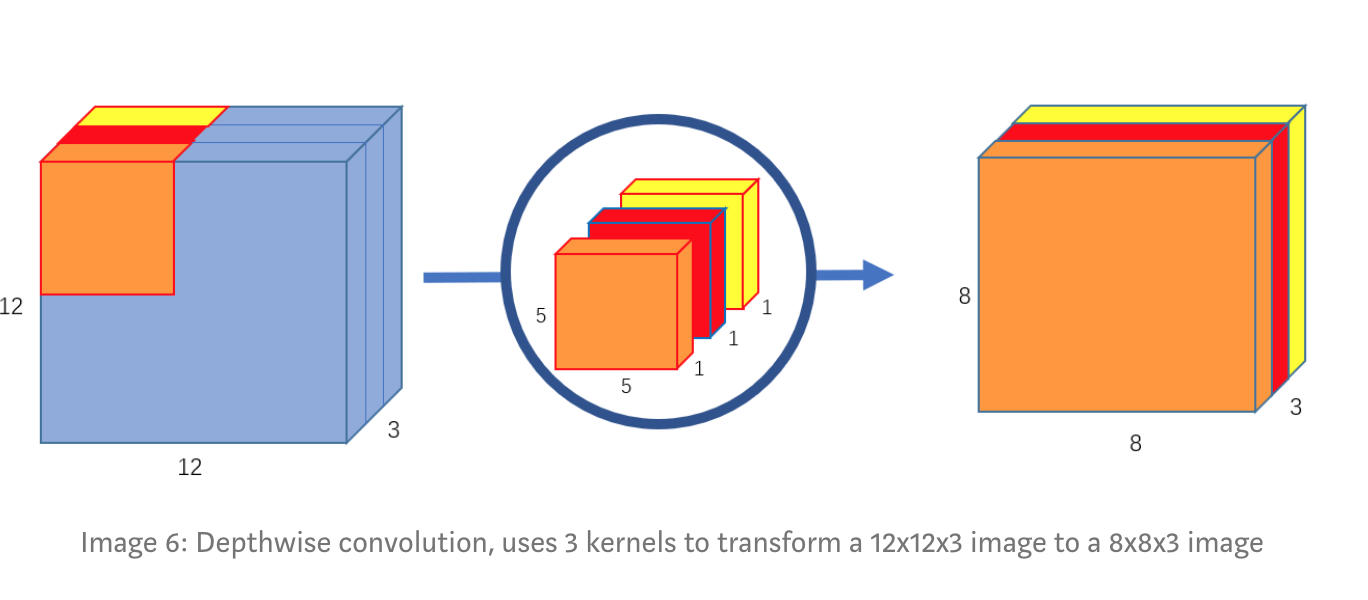
Ở đây, mỗi kernel sẽ thực hiện phép convolution với mỗi channel của ảnh đầu vào cho ra output 8x8x1, gộp các kết quả lại, chúng ta sẽ thu được 8x8x3 output image.
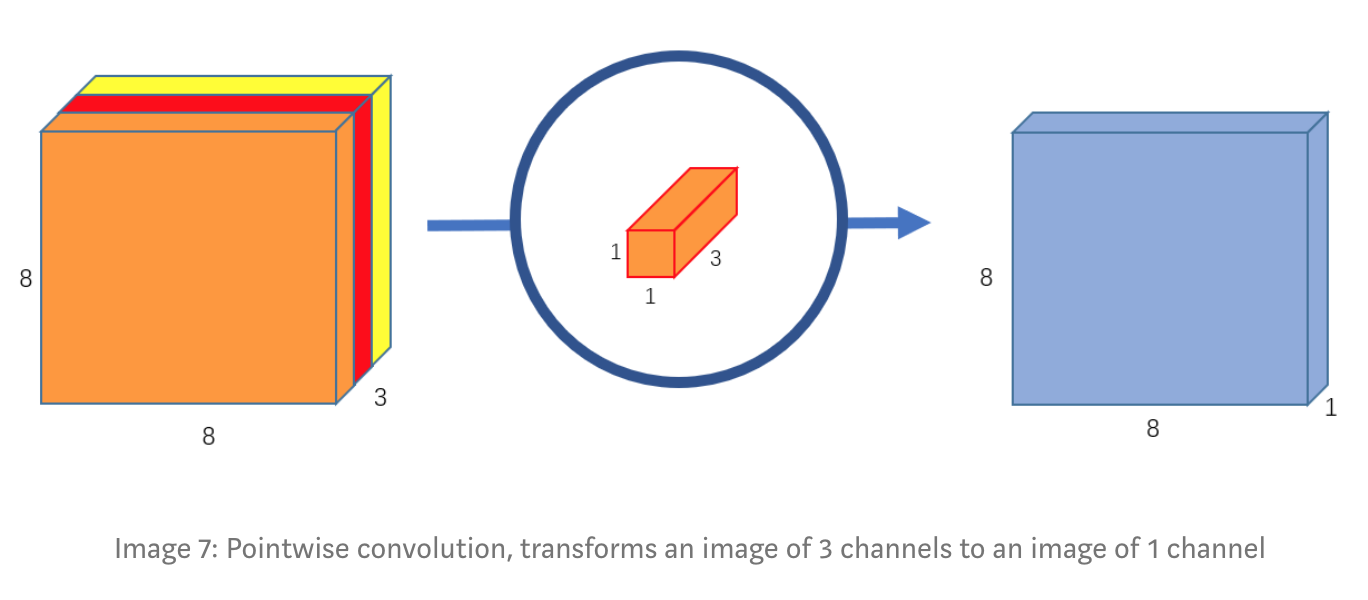
3. Pointwise Convolution
Nhớ lại phần trước ta có, convolution thông thường đã biến đổi image 12x12x3 thành 8x8x256 output image bằng cách sử dụng 256 kernel 5x5x3. Hiện tại sử dụng Depwise convolution, chúng ta đã biến đổi được từ 12x12x3 và thu được 8x8x3 ảnh đầu ra, nhiệm vụ bây giờ là làm tăng số lượng channels lên để thu được 8x8x256 như normal convolution đã làm.
Thì đây sẽ là nhiệm vụ của pointwise convolution, nó được đặt tên như vậy là bởi vì nó sử dụng các kernel 1x1 để thực hiện phép convolution với từng điểm dữ liệu. Kernel sẽ có số lượng channels bằng với số lượng channels của ảnh đầu vào với mục đích để thu được 1 channel của ảnh đầu ra. Ở đây, kernel của chúng ta sẽ là 1x1x3, sau khi convolution ảnh 8x8x3 — (1x1x3) — > 8x8x1.
Tiếp theo, tạo ra 256 kernel 1x1x3, chúng ta sẽ có được ảnh đầu ra là 8x8x256.
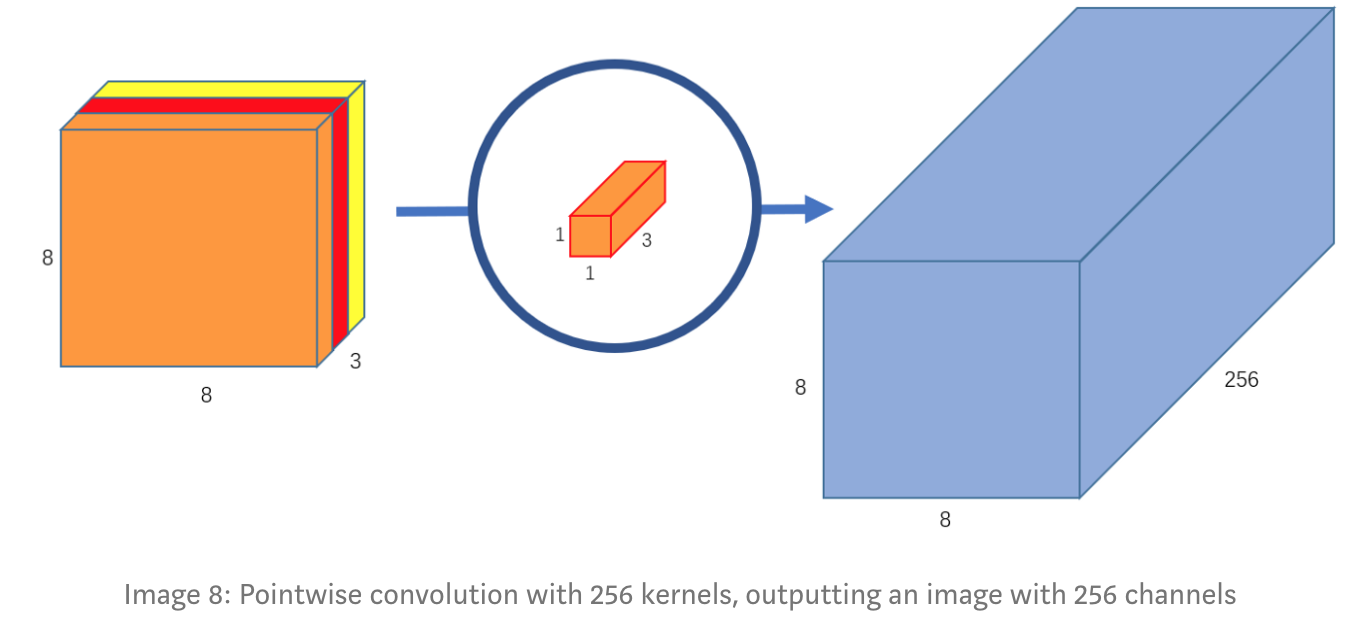
Đó là cách mà depthwise separable convolutions thực hiện, chúng ta có thể tóm tắt lại như sau: 12x12x3 — (5x5x1x1) — > (1x1x3x256) — >8x8x256.
IV. Why use depthwise separable convolutions
Bây giờ, hãy cùng nhau phân tích xem depthwise separable convolutions có đặc điểm gì nổi bật so với convolution thông thường nhé. Cách tiếp cận là tính xem số lượng phép nhân cần phải thực hiện, với normal convolution, thực hiện convolution 256 kernel 5x5x3 trên 8x8 điểm của image đầu vào, nghĩa là 256x3x5x5x8x8=1,228,800 phép nhân.
Còn với separable convolution thì sao? Depthwise convolution, chúng ta có 3 5x5x1 kernels dịch chuyển 8x8 lần, nghĩa là 3x5x5x1x8x8=4,800 phép nhân. Còn pointwise convolution, chúng ta có 256 1x1x3 kernels dịch chuyển 8x8 lần, 256x1x1x3x8x8=49,152 phép nhân, cộng 2 cái lại chúng ta mất 53,952 phép nhân tất cả.
Chúng ta đều thấy được rằng 53,952 nhỏ hơn 1,228,800 rất nhiều, mô hình mạng của chúng ta sẽ nhẹ hơn và có khả năng thực hiên nhanh hơn rất nhiều so với các phép nhân convolution thông thường.
Câu hỏi đặt ra, liệu 2 loại convolutions này có thực hiện như nhau? Sự khác biệt nằm ở chỗ, với convolution thông thường chúng ta biến đổi ảnh đầu vào 256 lần, mỗi lần biến đổi sử dụng 5x5x3x8x8=4800 phép nhân. Còn với separable convolutions, chúng ta chỉ biến đổi ảnh đầu vào duy nhất 1 lần ở depthwise convolution, sau đó kéo dài phần biến đổi này lên 256 channels. Việc chỉ phải biến đổi ảnh đầu vào duy nhất 1 lần, dẫn đến việc khả năng tính toán của mạng nhanh hơn rất nhiều.
V. Summary
Ở bài viết này chúng ta đã cùng nhau đi phân tích khá rõ những đặc điểm của separable convolution, khái niệm, công dụng, cũng như sự khác biệt với convolution thông thường. Cảm ơn mọi người đã đọc bài.
**References
https://towardsdatascience.com/a-basic-introduction-to-separable-convolutions-b99ec3102728
All rights reserved
