Recurrent Neural Network(Phần 1): Tổng quan và ứng dụng
Bài đăng này đã không được cập nhật trong 7 năm
Bài viết này dành cho những bạn đã có kiến thức cơ bản về mạng thần kinh Neural Network. Nếu bạn chưa có cái nhìn nào về Neural Network thì hãy tham khảo bài viết tóm tắt kiến thức về Artificial Neural Network của tôi tại đây hoặc nếu quá khó hiểu thì bạn có thể tham khảo video này.
Mạng hồi quy RNN
Để có thể hiểu rõ về RNN, trước tiên chúng ta cùng nhìn lại mô hình Neural Network dưới đây:
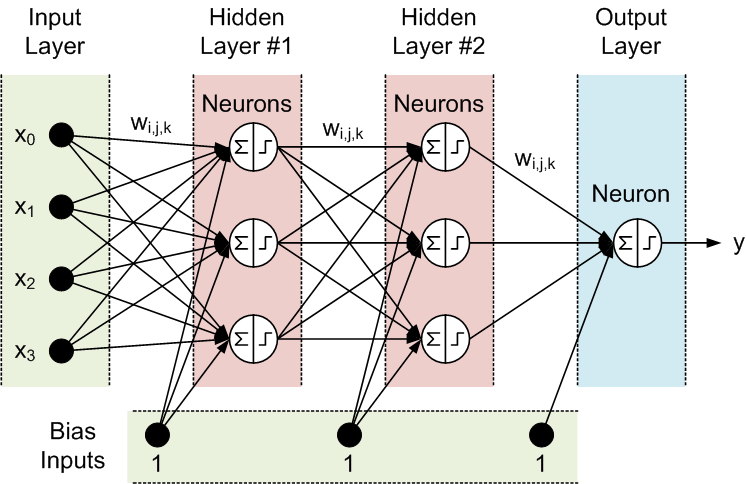
Như đã biết thì Neural Network bao gồm 3 phần chính là Input layer, Hidden layer và Output layer, ta có thể thấy là đầu vào và đầu ra của mạng neuron này là độc lập với nhau. Như vậy mô hình này không phù hợp với những bài toán dạng chuỗi như mô tả, hoàn thành câu, ... vì những dự đoán tiếp theo như từ tiếp theo phụ thuộc vào vị trí của nó trong câu và những từ đằng trước nó.
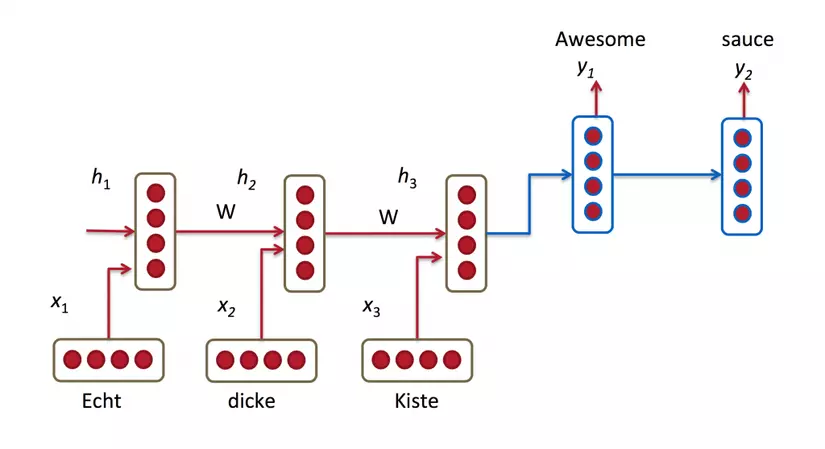
Và như vậy RNN ra đời với ý tưởng chính là sử dụng một bộ nhớ để lưu lại thông tin từ từ những bước tính toán xử lý trước để dựa vào nó có thể đưa ra dự đoán chính xác nhất cho bước dự đoán hiện tại. Nếu các bạn vẫn chưa hiểu gì thì hãy cùng xem mô hình mạng RNN sau và cùng phân tích để hiểu rõ hơn:
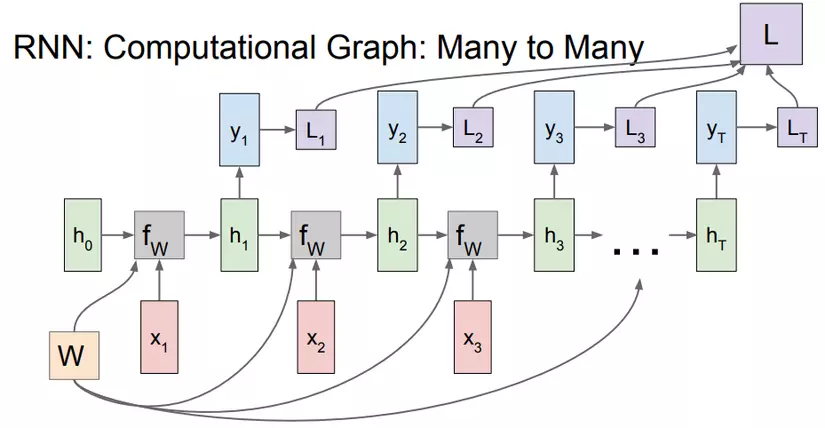
Giải thích một chút: Nếu như mạng Neural Network chỉ là input layer đi qua hidden layer và cho ra output layer với full connected giữa các layer thì trong RNN, các input sẽ được kết hợp với hidden layer bằng hàm để tính toán ra hidden layer hiện tại và output sẽ được tính ra từ , là tập các trọng số và nó được ở tất cả các cụm, các là các hàm mất mát sẽ được giải thích sau. Như vậy kết quả từ các quá trình tính toán trước đã được "nhớ" bằng cách kết hợp thêm tính ra để tăng độ chính xác cho những dự đoán ở hiện tại. Cụ thể quá trình tính toán được viết dưới dạng toán như sau:
Hàm chúng ta sẽ xử dụng hàm tanh, công thức trên sẽ trở thành :
Đến đây có 3 thứ mới xuất hiện: . Đối với mạng NN chỉ sử dụng một ma trận trọng số W duy nhất thì với RNN nó sử dụng 3 ma trận trọng số cho 2 quá trình tính toán: kết hợp với "bộ nhớ trước" và kết hợp với để tính ra "bộ nhớ của bước hiện tại" từ đó kết hợp với để tính ra .
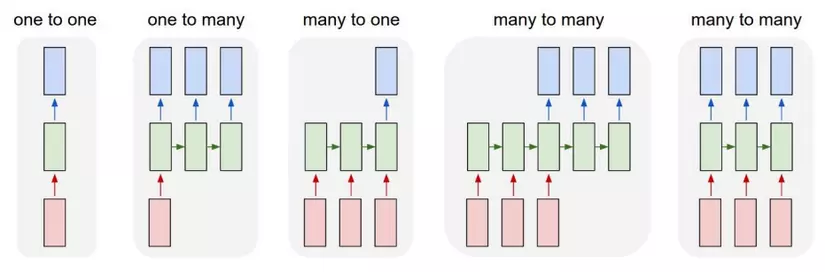
Ngoài mô hình Many to Many như ta thấy ở trên thì RNN còn rất nhiều dạng khác như sau:
Ứng dụng và ví dụ
Để hiểu hơn về mô hình RNN ta lấy một ví dụ sau: Cho tập input x = [h,e,l,o], sử dụng mô hình RNN để tạo ra một từ có nghĩa. Ta sẽ encode các chữ cái dưới dạng one hot encoding.
Và kết quả như sau:
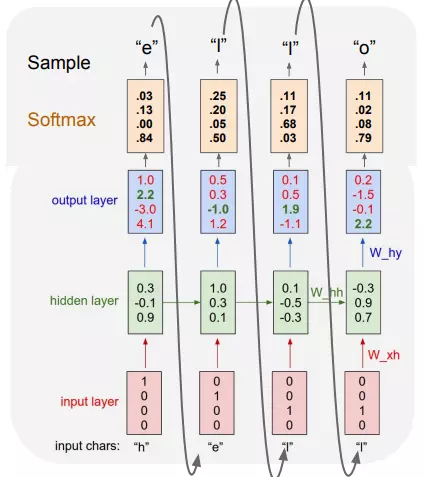
Ta thấy kí tự bắt đầu là "h" từ đó ta tìm ra chữ cái tiếp theo có xác suất lớn nhất là "e" và "e" tiếp tục trở thành input vào của cụm tiếp theo,... cứ như vậy cho đến khi tạo thành một từ có nghĩa, trong trường hợp này là từ "hello".
RNN được ứng dụng và thành công ở rất nhiều bài toán, đặc biệt là ở lĩnh vực NLP(xử lý ngôn ngữ tự nhiên). Trên lý thuyết thì đúng là RNN có khả năng nhớ được những tính toán (thông tin) ở trước nó, nhưng mô hình RNN truyền thống không thể nhớ được những bước ở xa do bị mất mát đạo hàm (sẽ được đề cập ở bài sau) nên những thành công của mô hình này chủ yếu đến từ một mô hình cải tiến khác là LSTM (Long Short-Term Memory, sẽ được đề cập ở những bài sau). LSTM về cơ bản cũng giống với RNN truyền thống ngoài việc thêm các cổng tính toán ở hidden layer để quyết định giữ lại các thông tin nào.
Ta sẽ cùng tìm hiểu một số lĩnh vực chính mà RNN cũng như LSTM được ứng dụng.
Mô hình ngôn ngữ và tự động sinh văn bản
RNN cho phép ta dự đoán xác suất của một từ mới nhờ vào các từ đã biết liền trước nó. Cơ chế này hoạt động giống với ví dụ bên trên, với các đầu ra của cụm này sẽ là đầu vào của cụm tiếp theo cho đến khi ta được một câu hoàn chỉnh. Các input thường được encode dưới dạng 1 vector one hot encoding. Ví dụ với tập dataset gồm 50000 câu ta lấy ra được một dictionary gồm 4000 từ, từ "hot" nằm ở vị trí 128 thì vector one hot của từ "hot" sẽ là một vector gồm 4000 phần tử đều bằng 0 chỉ có duy nhất vị trí 128 bằng 1. Mô hình này này chính là mô hình Many to Many với số lượng đầu ra, đầu vào và lớp ẩn bằng nhau.
Một vài nghiên cứu về lĩnh vực này :
- Recurrent neural network based language model
- Extensions of Recurrent neural network based language model
Dịch máy
Dịch máy giống với mô hình ngôn ngữ ở chỗ đầu vào của chúng là một chuỗi các từ trong ngôn ngữ cần dịch(ví dụ: tiếng Đức). Ta cần phải dịch các từ đó sang một ngôn ngữ đích(ví dụ: tiếng Anh). Nếu suy nghĩ đơn giản thì nó thật dễ đúng không, chỉ cần ánh xạ từ đó đến nghĩa của từ đó trong database rồi ghép chúng lại với nhau. Nhưng mọi thứ không đơn giản như vậy, vì mỗi từ khi đi cùng một từ trước nó thì nghĩa của nó lại thay đổi, và một từ có rất nhiều nghĩa trong từng hoàn cảnh khác nhau, vậy nên đó là lý do ta cần dùng đến RNN để tạo ra một câu dịch sát cả về nghĩa và văn vẻ. Để làm được vậy thì ta cần phải xem xét và xử lý qua tất cả chuỗi đầu vào.
 Một số nghiên cứu về dịch máy :
Một số nghiên cứu về dịch máy :
- A Recursive Recurrent Neural Network for Statistical Machine Translation
- Sequence to Sequence Learning with Neural Networks
Nhận dạng giọng nói
Với chuỗi đầu là tín hiệu âm thanh ở dạng sóng âm, chúng ta có thể dự đoán một chuỗi các đoạn ngữ âm cùng với xác suất của chúng. Một số nghiên cứu về Speech Recognition:
Mô tả hình ảnh
Trong lĩnh vực này mạng convolution neural network thường được sử dụng để detect các object có trong ảnh sau đó RNN sẽ sinh ra các câu có nghĩa mô tả bức ảnh đó. Sự kết hợp này mang lại sự hiệu quả đáng kinh ngạc.
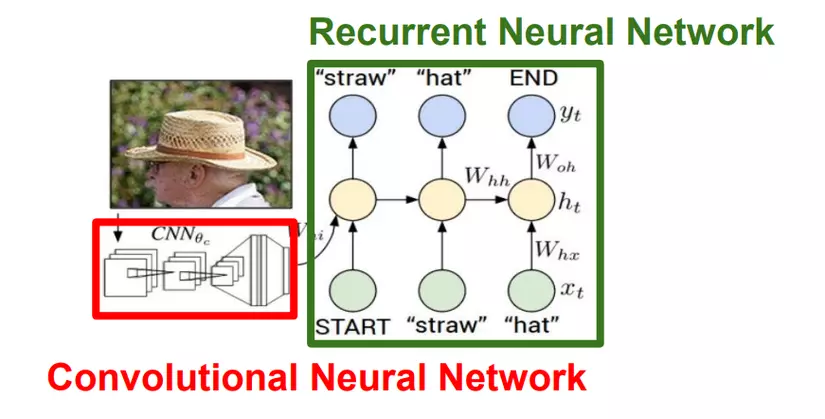
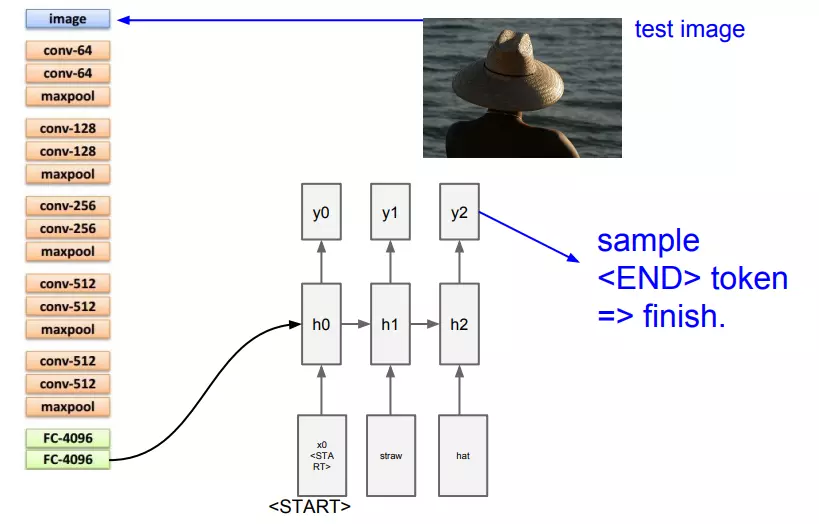 Hình ảnh trên là cách những người thiết kế đã kết hợp mạng CNN VGG16 (bỏ đi 2 lớp FC-1000 và Softmax) với mạng RNN.
Hình ảnh trên là cách những người thiết kế đã kết hợp mạng CNN VGG16 (bỏ đi 2 lớp FC-1000 và Softmax) với mạng RNN.
Kết luận
Trên đây ta đã có được cái nhìn tổng quan nhất về RNN là gì và nó được ứng dụng như thế nào. Ở phần sau ta sẽ đi vào tìm hiểu về Training cũng như đi trả lời câu hỏi mất mát đạo hàm là gì và vì sao nó lại khiến mạng RNN truyền thống không thể nhớ được những bước ở xa.
Tham khảo
Slide lectures 10 khóa Stanford về RNN
Recurrent Neural Networks Tutorial (một series cực hay về RNN tuy hơi khó hiểu nếu mới tìm hiểu)
All rights reserved
