Tổng quan về Artificial Neural Network
Bài đăng này đã không được cập nhật trong 8 năm
SƠ LƯỢC VỀ ARTIFICIAL NEURAL NETWORK
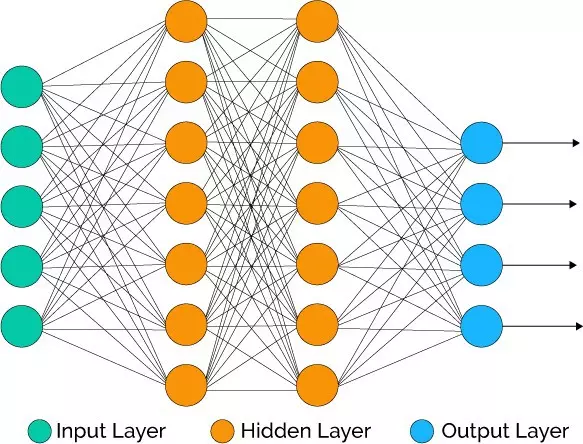
Artificial Neural Network (ANN) gồm 3 thành phần chính: Input layer và output layer chỉ gồm 1 layer , hidden layer có thể có 1 hay nhiều layer tùy vào bài toán cụ thể. ANN hoạt động theo hướng mô tả lại cách hoạt động của hệ thần kinh với các neuron được kết nối với nhau
Trong ANN, trừ input layer thì tất cả các node thuộc các layer khác đều full-connected với các node thuộc layer trước nó. Mỗi node thuộc hidden layer nhận vào ma trận đầu vào từ layer trước và kết hợp với trọng số để ra được kết quả. Ở trong course của Andrew Ng trên coursera, thầy sử dụng Logistic Regression ở các node.
Sơ qua về Logistic Regression:
Logistic Regression có activation function là hàm sigmoid :
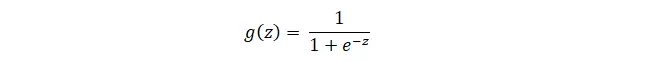
Hàm hypothesys :
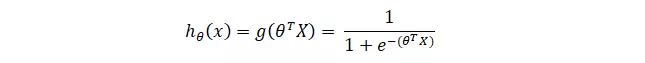
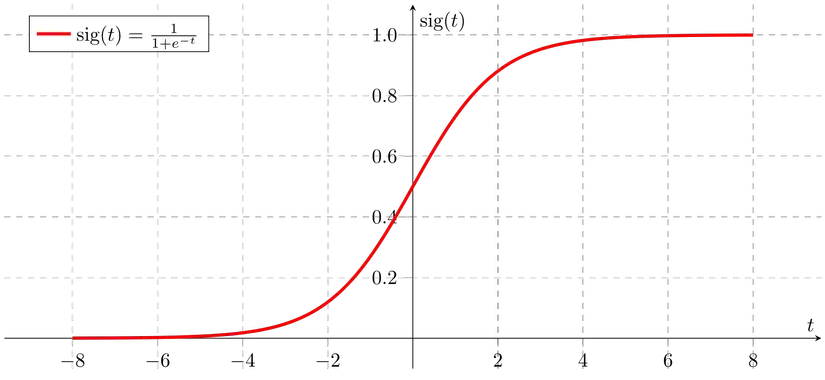
Đồ thị có dạng :
Cost function:
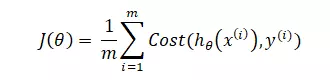
Với :
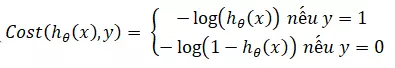
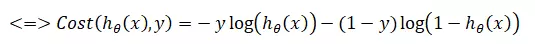
Vậy ta có cost function :
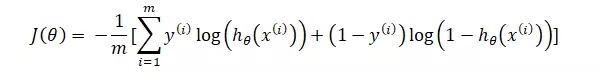
Kết hợp với Regurlarization:
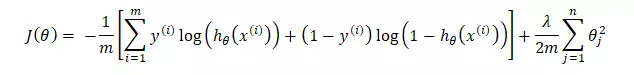
Vậy với ANN với mỗi node thuộc layer khác input layer đều là một Logistic Regression ta sẽ có :
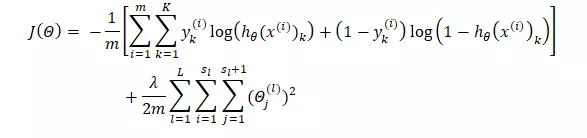
Công việc của chúng ta hiện tại là tìm ra được sao cho min.
Để tìm cực tiểu của ta áp dụng thuật toán Gradient Descent.
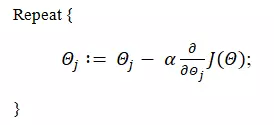
Với α là learning rate.
Để thực hiện được thì cần phải tính được , để tính được đạo hàm này là việc tương đối khó và ta cần thực hiện một thuật toán được gọi là backpropagation để tính.
FORWARD PROPAGATION
Ta có mạng neural như sau :
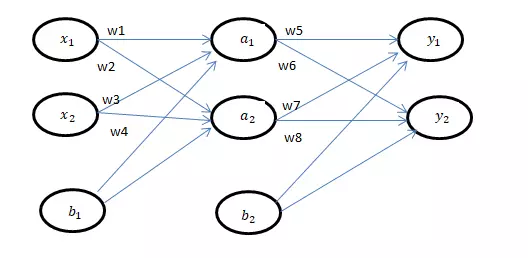
Chú thích :
là các features của input.
là các output.
là các bias.
là các trọng số.
Như cái tên của forward propagation , ta sẽ tiến hành tính toán từ trái qua phải.
Tương tự :
Forward propagation là một công đoạn tính toán giá trị tại từng node để phục vụ việc tính toán trong Back propagation.
BACK PROPAGATION
Như đã nói ở trên, mục tiêu của back propagation là đi tính .
Giả sử ta đang cần tính .
Áp dụng chain rule ta tách $\frac{∂}{∂\Theta_{5}} J(\Theta)$thành :
Để cho dễ hiểu chúng ta sẽ bỏ qua regularization và giả sử m = 1 với tập kết quả trong training set ứng với $y_1,y_2 $ là :
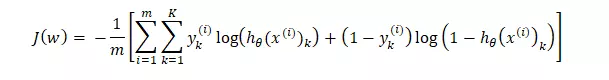
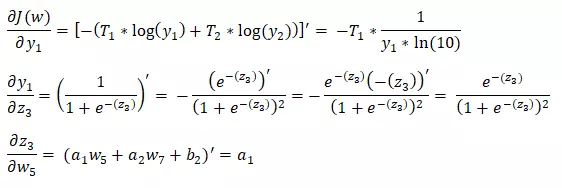
Tất cả các kết quả của đều có thể tính được thông qua kết quả thu được từ forward propagation. Vậy ta có thể tính được .
Tương tự như vậy ta có thể lần lượt tính được giá trị với j = 1, 2, …, 8 trong trường hợp này.
Như vậy nhờ vào back propagation ta đã có thể tính được từ đó giúp thuật toán Gradient descent có thể hoạt động và ta có thể tìm ra tập sao cho Cost function là nhỏ nhất.
All rights reserved
