Paper reading | ZipIt! Merging Models from Different Tasks without Training
Bài đăng này đã không được cập nhật trong 2 năm
Giới thiệu chung
Các model hình ảnh ngày càng phát triển mạnh với khả năng thực hiện chính xác được nhiều task khác nhau, từ classification với hàng nghìn class cho đến những task về object detection, instance segmentation, image generation  Tuy phát triển nhanh và mạnh như vậy nhưng các model này cũng có một số vấn đề tiềm ẩn:
Tuy phát triển nhanh và mạnh như vậy nhưng các model này cũng có một số vấn đề tiềm ẩn:
- Các model chỉ thực hiện được trên các task được train, nếu ta mở rộng việc train trên các task mới sẽ xảy ra vấn đề "lãng quên" (trong bài báo gọi là catastrophic forgetting). Catastrophic forgetting đề cập đến hiện tượng một model được đào tạo về một task cụ thể sẽ quên "kiến thức đã học" trước đó khi nó được đào tạo về một task mới. Đây là một vấn đề trong deep learning, đặc biệt là trong các tình huống continual learning, trong đó model cần học các nhiệm vụ mới theo thời gian mà không cần truy cập vào tất cả dữ liệu trước đó . Sự lãng quên xảy ra nghiêm trọng khi các tham số của model được cập nhật dựa trên dữ liệu mới, khiến model ghi đè lên kiến thức đã học trước đó. Về cơ bản, dữ liệu đào tạo ban đầu của model trở nên ít quan trọng hơn theo thời gian khi model được tinh chỉnh trên dữ liệu mới. Do đó, model có thể thực hiện kém các nhiệm vụ đã học trước đó khi được thử nghiệm lại.
- Nếu đánh giá model trên những data mới chưa được cập nhật, ta sẽ thường thấy là model có khả năng tổng quát hóa khá kém với những domain mà chưa được train bao giờ.
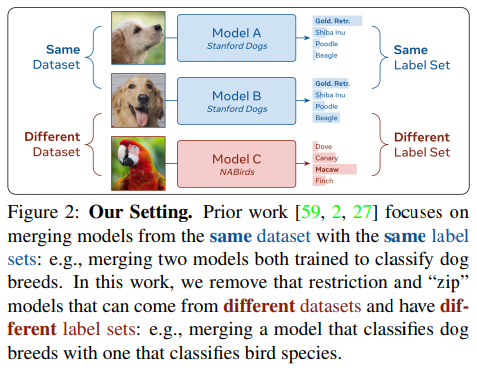
Các cách giải quyết vấn đề này thường là các kĩ thuật regularization hoặc phải training lại, điều này làm mất thời gian và tài nguyên để training. Nếu như bây giờ có một phương pháp có thể kết hợp các model được train trên trên các task khác nhau thành một model mà không phải train lại thì quá tuyệt Trong bài báo, nhóm tác giả đề xuất phương pháp kết hợp các model được khởi tạo khác nhau và được train trên các task hoàn toàn riêng biệt, bạn đọc xem hình dưới đươc trích trong bài báo để hiểu hơn về ý tưởng chung  .
.
Động lực
Mục tiêu của phương pháp là kết hợp các model khác nhau mà không cần phải training thêm lần nào. Cụ thể bài toán được mô tả như sau. Xét một model là một tập hợp của các layer , mỗi layer này có chứa các tham số (ví dụ như với linear layer thì ta có tham số ). Ta định nghĩa kết hợp 2 model và là kết hợp các tham số của 2 model này thành một model mới sao cho vẫn duy trì được độ chính xác của và trên các task gốc.
Nếu và được finetuned từ cùng checkpoint, một số nghiên cứu nhận thấy rằng việc kết hợp 2 model khá dễ dàng bằng cách thực hiện tính trung bình các trọng số của chúng. Ví dụ, nếu là một linear layer, ma trận trọng số mới được tính như sau:
Tuy nhiên, nếu và không được finetuned từ cùng 1 checkpoint thì cách tính ma trận trọng số trên cho ta độ chính xác ngẫu nhiên Để giải quyết vấn đề này, một số nghiên cứu trước đây đề xuất phương pháp căn chỉnh (ví dụ như hoán vị) feature space của một model với feature space của một model khác trước khi tính giá trị trung bình. Nếu một trong các feature space của model được căn chỉnh để khớp với feature space của model kia thì hai model có thể trở nên bổ sung cho nhau nhiều hơn, điều này có thể dẫn đến sự kết hợp chính xác hơn các dự đoán của chúng. Cụ thể hơn, gọi là một ma trận hoán vị thực hiện hoán vị output của layer sang space của .
Nhóm tác giả thực hiện hoán vị output space của nhưng cũng cần hoán vị input space của . Lý do là input space của là output space của layer trước đó và feature dimension của input space đã được hoán vị bởi hoán vị của layer trước đó. Vì vậy, để căn chỉnh input và output space của với space tương ứng của model khác, ta cần "undo" hoán vị input space của bằng cách sử dụng . Tuy nhiên, cách làm này chỉ chính xác với các model được train trên task giống nhau.

Phương pháp
Phương pháp được sử dụng là kết hợp các trọng số của 2 model thành một bộ trọng số duy nhất. Ý tưởng là ta sẽ thực hiện kết hợp mỗi layer của model này với layer tương ứng của model kia và sẽ điều chỉnh cả hai (khác với cách làm đã được trình bày ở trên, ta chỉ thực hiện hoán vị một trong hai mô hình).
Ví dụ, nếu layer là một linear layer, ta sẽ có bộ trọng số và input là $x \in $ với output feature vector được tính như sau
Mục tiêu là lấy từ model A và từ model B và kết hợp thành một layer , feature space chứa thông tin của và .
Để xây dựng feature ta giả sử rằng tồn tại các feature "thừa" (redundant feature) trong và . Điều này có nghĩa là tồn tại một số phần tử của 2 feature vector có độ tương quan cao trên một mẫu dữ liệu. Để có thể xét sự tương quan giữa các gặp phần tử trong 2 feature vector, ta thực hiện concat 2 feature vector thành (với là số cặp các phần tử) và xét sự tương quan giữa các cặp phần tử trong vector được concat mới.
Nếu 2 feature có độ tương quan cao thì ta chỉ cần tính trung bình của chúng. Ta định nghĩa ma trận kết hợp và được tính như sau
Khi đó ma trận là một ma trận thưa và tồn tại cặp có chỉ số của bộ với . Ta có thể tìm bộ này sử dụng thuật toán tham lam, vẫn có thuật toán tối ưu độ chính xác hơn nhưng chạy rất chậm và độ chính xác chỉ hơn một chút.

Một vấn đề gặp phải là với layer tiếp theo không tương thích với biểu diễn tính ở công thức trên. Vì vậy, ta cần "undo" thao tác merge trước khi truyền các feature vào layer tiếp theo. Ta định nghĩa ma trận "unmerge" thỏa mãn
Ta cũng có thể tách ma trận unmerge thành bằng cách chia nửa số hàng của ma trận. Khi đó ta có thể tính toán feature mới như sau:
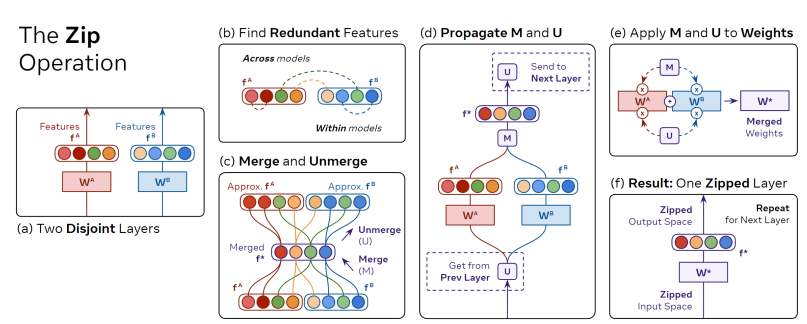
Từ các thành phần trên ta rút ra một thao tác chung để merge và bất kì như sau:
- Tính và bằng cách matching feature và . Sau đó truyền tới layer tiếp theo và nhận từ layer trước đó.
- Từ và ta tính được parameter mới với linear layer như sau:
Trong đó và là được chia thành 2 nửa theo cột. được tính tương tự như công thức trên nhưng không dùng unmerge.
Tuy nhiên, các model hiện đại không chỉ có một loại layer là linear layer. Một số layer như BatchNorm, ReLU không có ma trận trọng số để tính toán bằng công thức trên. Do đó, ta truyền và qua các layer này như mô tả trong hình dưới.
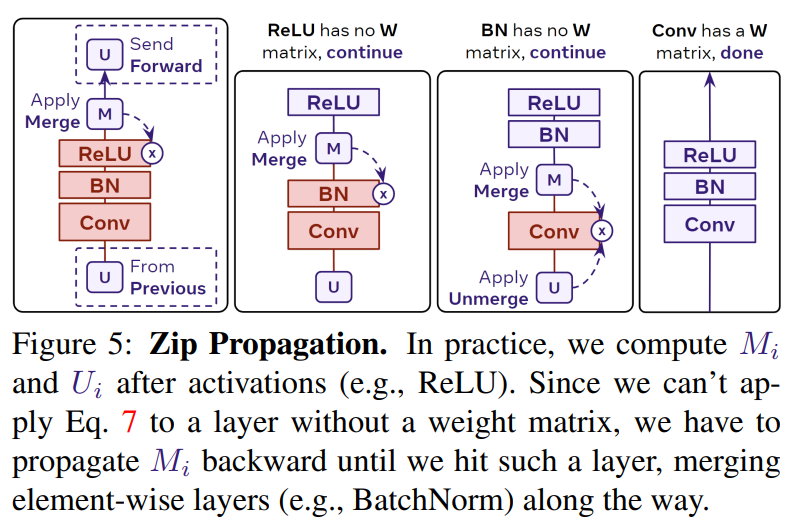
Như hình trên ta có một block phổ biến trong mạng CNN, do ReLU và BatchNorm không có ma trận trọng số nên ta bỏ qua, sau đó ta chỉ cần tính ma trận trọng số mới dùng và khi tới Conv layer. Một cách tổng quát hơn, ta cần quan tâm đến cơ chế propagation của từng model để tính toán ma trận trọng số mới sao cho phù hợp.
Trong một số trường hợp, ta có thể không muốn "zip" tất cả layer của 2 mạng neural, đặc biệt nếu như không gian vector của các layer không tương thích hoặc làm giảm độ chính xác đi quá nhiều. Thay vào đó, ta sẽ thực hiện "zip một phần" như trong hình dưới.
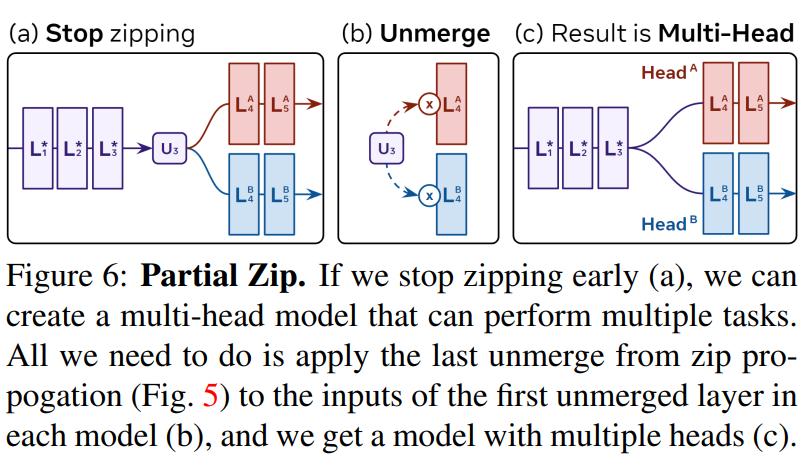
Cách thực hiện rất đơn giản, ta thực hiện zip bình thường đến layer nào đó, sau đó các layer mà không được zip sẽ nhận thông qua zip propagation. Khi đó, kết quả sẽ có dạng multihead model và thực hiện multple tasks.
Trong trường hợp khác, ta lại muốn merge nhiều hơn 2 model. Khi đó, ta sẽ thực hiện việc lặp matching. Tại đây, khi sử dụng thuật toán tham lam tìm được 2 feature khớp với nhau, ta sẽ xóa chúng và thay bằng merged feature mới. Để ngăn việc một feature được merge quá nhiều lần, nhóm tác giả đặt giá trị tương quan feature mới là giá trị tối thiểu của giá trị tương đồng các feature cũ và được đánh trọng số bởi .
Nhóm tác giả sử dụng một tham số gọi là "budget" biểu thị tỷ lệ phần trăm feature được merge trong chính model của chúng trên tổng các feature được merge. Bằng cách chỉ định budget, ta có thể tìm hiểu tác động của việc tự merge feature trong các model riêng lẻ.
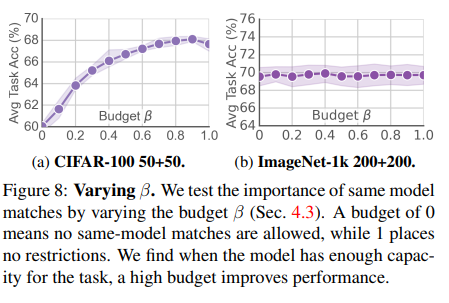
Nhóm tác giả nhận thấy rằng trong tập dữ liệu CIFAR budget tối ưu nhất có giá trị trên 0.8, tức là 80% việc merge là đến từ chính bên trong model riêng lẻ. Đối với ImageNet, điều này lại không xảy ra do độ khó của task làm cho tồn tại ít các feature thừa trong mỗi model.
Thực nghiệm
Nhóm tác giải thực hiện 2 loại thực nghiệm để đánh giá kết quả của việc merge 2 model. Thực nghiệm 1 đó là merge các model được train trên cùng dataset nhưng khác label. Thực nghiệm 2 là merge các model được train khác dataset và tất nhiên là khác cả label.
Bảng dưới là kết quả trong bộ data CIFAR. So sánh ZipIt! n/m với các baseline, trong đó n/m có nghĩa là n trên m layer được zip. Model được zip từ 2 model, một model được train trên một nửa class (Task A) và một model được train trên các class khác. Model được sử dụng là ResNet-20.
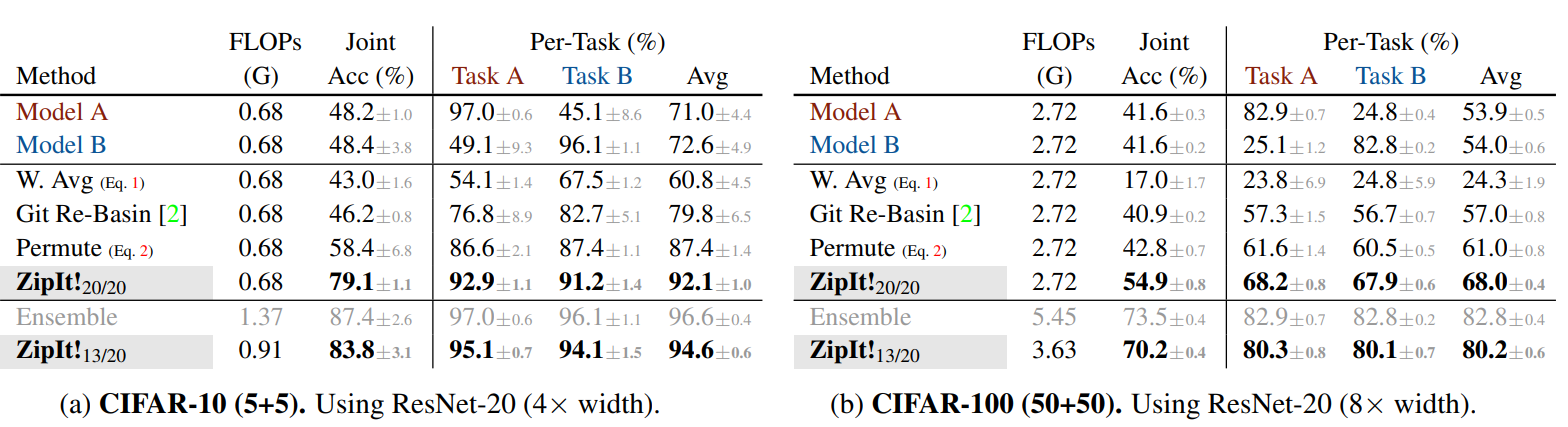
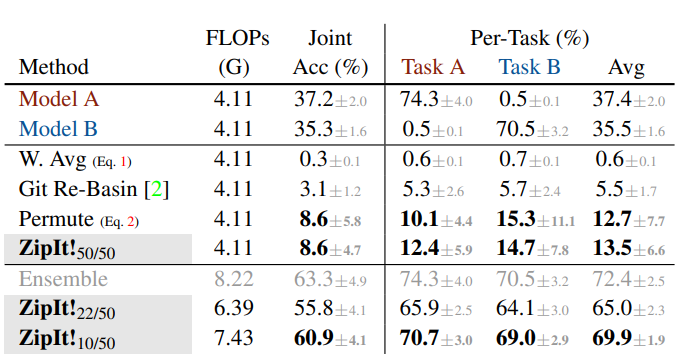
Bảng dưới là kết quả trên tập ImageNet-1k sử dụng ResNet-50 được train từ đầu trên 200 class con (mỗi model) trong 1000 class của bộ data.
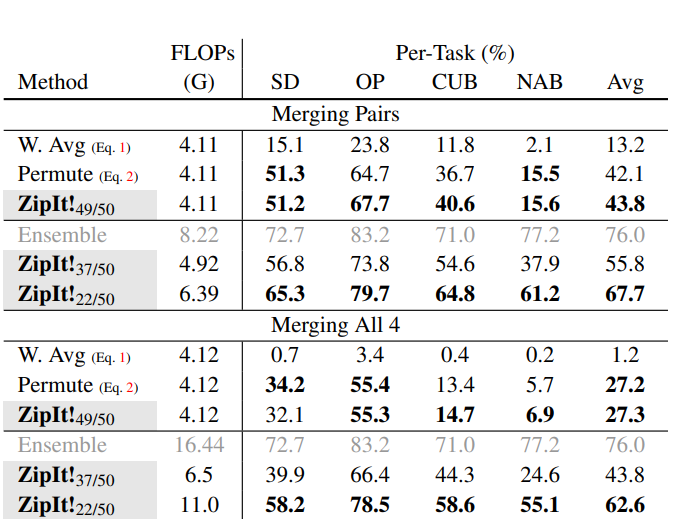
Với model được train trên nhiều bộ dữ liệu khác nhau Stanford Dogs (SD), Oxford Pets (OP), CUB200 (CUB), và NABirds (NAB). Bảng dưới report kết quả độ chính xác trung bình trên mỗi task theo 2 cách, merge theo cặp model và merge cả 4 model.
Kết luận
Bài báo cho ta một ý tưởng mới để tận dụng tài nguyên bằng cách kết hợp các model được train trên các task khác nhau mà không phải training lại từ đầu. Đây là một ý tưởng khá độc đáo tuy nhiên lại rất "kén" áp dụng cho từng bài toán cụ thể. Hy vọng sau bài báo này các bạn có thêm một hướng đi mới cho việc xây dựng model của mình.
Tham khảo
[1] ZipIt! Merging Models from Different Tasks without Training
All rights reserved
