Paper reading | Xception phiên bản nâng cấp của Inception V3
Bài đăng này đã không được cập nhật trong 2 năm
Đóng góp của bài báo
Bài báo giới thiệu mô hình Xception (Extreme Inception) là một kiến trúc mạng neural được phát triển dựa trên ý tưởng của Inception và sử dụng các convolution depthwise separable để cải thiện hiệu suất và hiệu quả tính toán. Được giới thiệu bởi François Chollet vào năm 2017, Xception đã đạt được thành công đáng kể trong lĩnh vực thị giác máy tính.
Dưới đây là một số điểm nổi bật về mô hình Xception:
-
Depthwise Separable Convolutions: Xception sử dụng các convolution depthwise separable để thay thế convolution truyền thống. Việc này tách riêng quá trình convolution theo channel dimension và spatial dimension của dữ liệu, giúp giảm đáng kể lượng tính toán và số lượng tham số. Kết quả là mạng trở nên nhẹ nhàng hơn và dễ huấn luyện hơn.
-
Kiến trúc gốc Inception: Xception dựa trên kiến trúc gốc của Inception, trong đó các lớp conv kích thước khác nhau được sử dụng để trích xuất đặc trưng từ dữ liệu. Sự kết hợp của các lớp này giúp mô hình có khả năng nắm bắt đa dạng các đặc trưng từ ảnh đầu vào.
-
Hiệu suất cao: Xception đã đạt được hiệu suất cao trên các tập dữ liệu thị giác máy tính, chẳng hạn như bộ dữ liệu ImageNet. Sự kết hợp giữa kiến trúc gốc Inception và convolution depthwise separable giúp mô hình đạt được độ chính xác tốt và tối ưu tài nguyên tính toán.
-
Ứng dụng rộng rãi: Xception không chỉ được sử dụng trong thị giác máy tính, mà còn có thể được áp dụng trong nhiều lĩnh vực khác như xử lý âm thanh, ngôn ngữ tự nhiên và nhiều bài toán khác.
Module Inception
Convolution layer là một phần quan trọng trong mạng neural, đặc biệt là trong việc xử lý dữ liệu như hình ảnh. Convolution layer được sử dụng để học các đặc trưng từ dữ liệu. Các convolution layer học các filter trong một không gian 3D. Không gian 3D này gồm hai chiều không gian (spatial dimension) là chiều rộng và chiều cao cùng với một chiều kênh (channel dimension). Ví dụ, một ảnh màu RGB sẽ có ba kênh là đỏ, xanh lá cây và xanh lam.
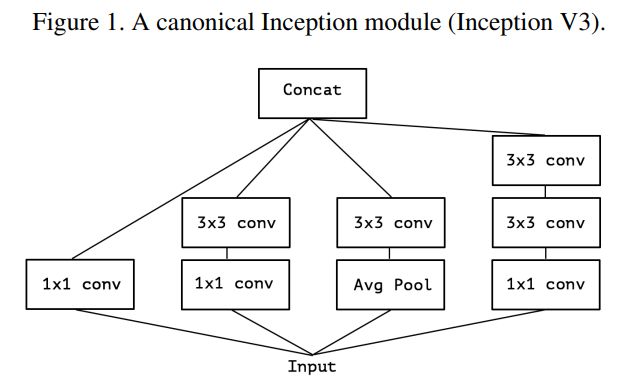
Module Inception được thiết kế để giúp quá trình học các tương quan giữa các channel và spatial hiệu quả hơn. Cụ thể, một module Inception điển hình đầu tiên sử dụng các convolution (như hình trên), lý do:
-
Giảm số lượng kênh (channel reduction): Các conv giúp giảm số lượng kênh của input ban đầu. Việc này hữu ích trong việc giảm chi phí tính toán, giảm thiểu khả năng bị overfitting (hiện tượng mô hình quá tập trung vào dữ liệu huấn luyện mà không tổng quát hóa tốt cho dữ liệu mới) và tạo ra một biểu diễn với chiều kênh thấp hơn, giúp tốn ít bộ nhớ hơn và tiết kiệm thời gian tính toán.
-
Học tương quan giữa các kênh (channel-wise correlation): Sử dụng conv trên các kênh tương tự như việc thực hiện một loạt các phép nhân ma trận độc lập trên các kênh. Điều này cho phép mô hình học tương quan giữa các kênh nhưng không liên quan đến không gian. Điều này rất hữu ích vì module Inception sau đó sử dụng các conv lớn hơn như hoặc để học tương quan không gian trong không gian nhỏ hơn được tạo ra bởi các conv .
Một phiên bản đơn giản hơn của module Inception là vẫn dùng conv và conv nhưng không dùng Avg pool như hình dưới:
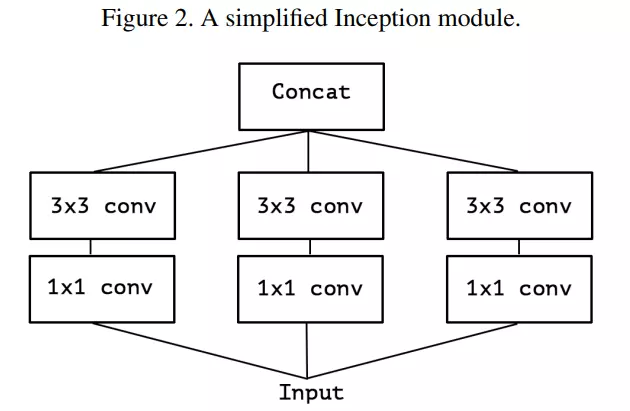
Làm cho module Inception trở nên "extreme"
Để làm cho module Inception "extreme" hơn, ta thực hiện thay 3 lớp conv bằng 1 conv duy nhất và các conv được sử dụng trên các đoạn (segment) không chồng chéo nhau của output channel.
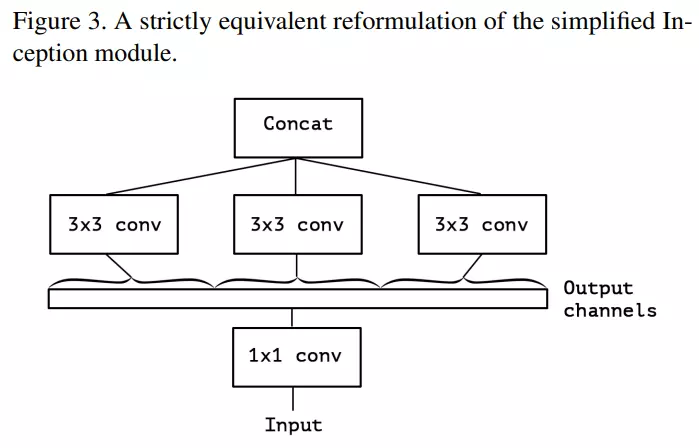
Để hiểu hơn về kiến trúc trên, ta sẽ minh họa bằng ví dụ sau. Giả sử output của lớp conv có shape là . Ta sẽ không xét đến batch dimesion mà chỉ tập trung vào tensor. Tensor này sẽ được cắt thành các segment theo chiều channel thành các tensor mới có shape là . Sau đó các tensor này đi qua lớp conv . Lưu ý rằng mỗi tensor này có một conv riêng (như hình trên). Sau khi đi qua conv các output tensor được concat lại với nhau.
Sự khác nhau giữa Depthwise Separable Convolution và module Inception extreme
Module Inception extreme khá giống Depthwise separable convolution tuy nhiên chúng có một số điểm khác nhau như sau:
- Về thứ tự các thao tác: Depthwise separable convolution thường sử dụng channel-wise spatial convolution trước sau đó mới đến convolution. Phiên bản extreme của module Inception thì ngược lại.
- Sự khác nhau về việc sử dụng hàm activation ReLU: Depthwise separable convolution thường được cài đặt không sử dụng có hàm activation phi tuyến tính còn module Inception extreme thì có.
Nếu như bạn chưa biết về Depthwise separable convolution thì có thể đọc thêm bài viết tại [3] và [4].
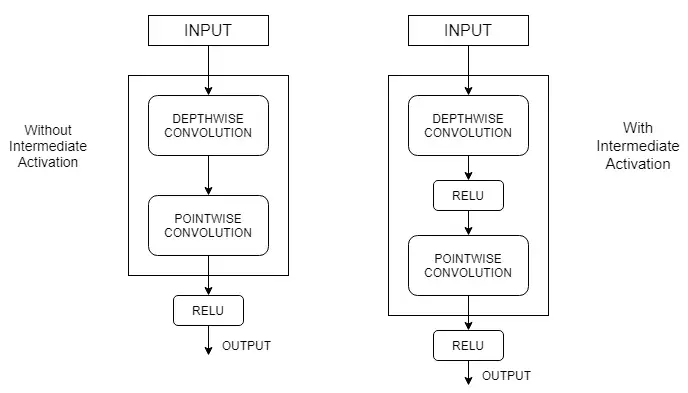
Về yếu tố đầu tiên thì ảnh hưởng không nhiều tới tổng thể mô hình do các module được stack với nhau nên bản chất không có nhiều khác biệt. Với yếu tố thứ hai, nhóm tác giả nhận thấy rằng quá trình học trở nên nhanh hơn khi không có hàm activation ở giữa Depthwise convolution và Pointwise convolution.
Kiến trúc Xception
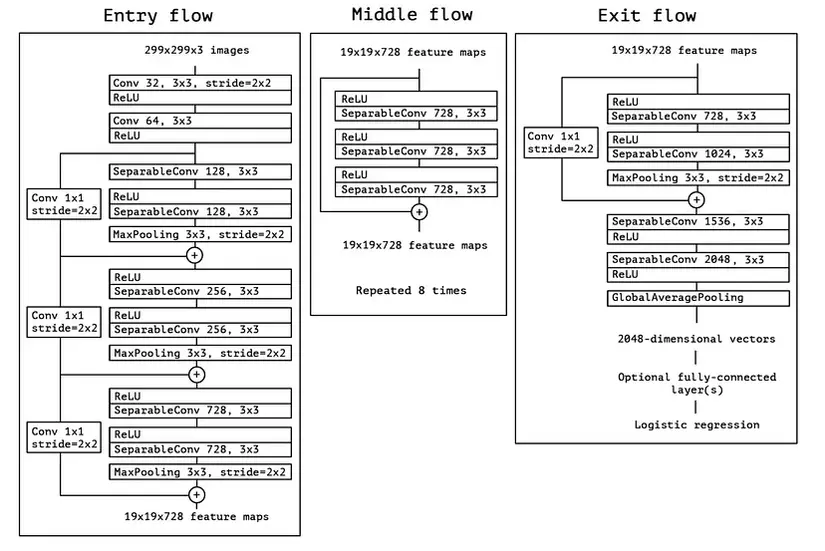
Kiến trúc tổng thể của Xception được mô tả tường minh trong hình dưới. Kiến trúc gồm 3 phần Entry flow, Middle flow, Exit flow. Có tổng cộng 14 module trong kiến trúc, trong đó Entry flow có 4 module, Middle flow có 8 module và Exit flow có 2 module. Mỗi module là tập hợp của depthwise seperable convolution và pooling layer. Các layer cuối của kiến trúc là các fully connected layer.
Coding
Code tham khảo kiến trúc Xception.
import math
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.model_zoo as model_zoo
from torch.nn import init
import torch
__all__ = ['xception']
model_urls = {
'xception':'http://data.lip6.fr/cadene/pretrainedmodels/xception-43020ad28.pth'
}
class SeparableConv2d(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size=1,stride=1,padding=0,dilation=1,bias=False):
super(SeparableConv2d,self).__init__()
self.conv1 = nn.Conv2d(in_channels,in_channels,kernel_size,stride,padding,dilation,groups=in_channels,bias=bias)
self.pointwise = nn.Conv2d(in_channels,out_channels,1,1,0,1,1,bias=bias)
def forward(self,x):
x = self.conv1(x)
x = self.pointwise(x)
return x
class Block(nn.Module):
def __init__(self,in_filters,out_filters,reps,strides=1,start_with_relu=True,grow_first=True):
super(Block, self).__init__()
if out_filters != in_filters or strides!=1:
self.skip = nn.Conv2d(in_filters,out_filters,1,stride=strides, bias=False)
self.skipbn = nn.BatchNorm2d(out_filters)
else:
self.skip=None
self.relu = nn.ReLU(inplace=True)
rep=[]
filters=in_filters
if grow_first:
rep.append(self.relu)
rep.append(SeparableConv2d(in_filters,out_filters,3,stride=1,padding=1,bias=False))
rep.append(nn.BatchNorm2d(out_filters))
filters = out_filters
for i in range(reps-1):
rep.append(self.relu)
rep.append(SeparableConv2d(filters,filters,3,stride=1,padding=1,bias=False))
rep.append(nn.BatchNorm2d(filters))
if not grow_first:
rep.append(self.relu)
rep.append(SeparableConv2d(in_filters,out_filters,3,stride=1,padding=1,bias=False))
rep.append(nn.BatchNorm2d(out_filters))
if not start_with_relu:
rep = rep[1:]
else:
rep[0] = nn.ReLU(inplace=False)
if strides != 1:
rep.append(nn.MaxPool2d(3,strides,1))
self.rep = nn.Sequential(*rep)
def forward(self,inp):
x = self.rep(inp)
if self.skip is not None:
skip = self.skip(inp)
skip = self.skipbn(skip)
else:
skip = inp
x+=skip
return x
class Xception(nn.Module):
def __init__(self, num_classes=1000):
super(Xception, self).__init__()
self.num_classes = num_classes
self.conv1 = nn.Conv2d(3, 32, 3,2, 0, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(32,64,3,bias=False)
self.bn2 = nn.BatchNorm2d(64)
self.block1 = Block(64,128,2,2,start_with_relu=False,grow_first=True)
self.block2 = Block(128,256,2,2,start_with_relu=True,grow_first=True)
self.block3 = Block(256,728,2,2,start_with_relu=True,grow_first=True)
self.block4 = Block(728,728,3,1,start_with_relu=True,grow_first=True)
self.block5 = Block(728,728,3,1,start_with_relu=True,grow_first=True)
self.block6 = Block(728,728,3,1,start_with_relu=True,grow_first=True)
self.block7 = Block(728,728,3,1,start_with_relu=True,grow_first=True)
self.block8 = Block(728,728,3,1,start_with_relu=True,grow_first=True)
self.block9 = Block(728,728,3,1,start_with_relu=True,grow_first=True)
self.block10 = Block(728,728,3,1,start_with_relu=True,grow_first=True)
self.block11 = Block(728,728,3,1,start_with_relu=True,grow_first=True)
self.block12=Block(728,1024,2,2,start_with_relu=True,grow_first=False)
self.conv3 = SeparableConv2d(1024,1536,3,1,1)
self.bn3 = nn.BatchNorm2d(1536)
self.conv4 = SeparableConv2d(1536,2048,3,1,1)
self.bn4 = nn.BatchNorm2d(2048)
self.fc = nn.Linear(2048, num_classes)
#------- init weights --------
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
#-----------------------------
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
x = self.block6(x)
x = self.block7(x)
x = self.block8(x)
x = self.block9(x)
x = self.block10(x)
x = self.block11(x)
x = self.block12(x)
x = self.conv3(x)
x = self.bn3(x)
x = self.relu(x)
x = self.conv4(x)
x = self.bn4(x)
x = self.relu(x)
x = F.adaptive_avg_pool2d(x, (1, 1))
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def xception(pretrained=False,**kwargs):
model = Xception(**kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['xception']))
return model
Thực nghiệm
Bảng dưới so sánh Xception với các model trước đó trên tập dữ liệu Imagenet.
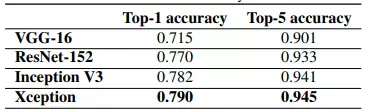
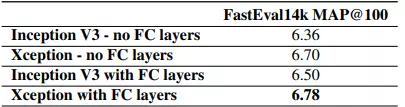
Xception cũng thể hiện kết quả vượt trội so với Inception V3.
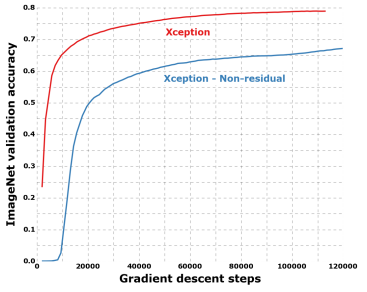
Việc sử dụng residual connections làm cho độ chính xác của Xception tăng đáng kể.
Tham khảo
[1] Xception: Deep Learning with Depthwise Separable Convolutions
[2] Review of Deep Learning Architectures for Image Classification Problem (Part 3)
[3] Depthwise Separable Convolution
[4] [CNN Architecture series #1] MobileNets - Mô hình gọn nhẹ cho mobile applications - Viblo
[5] Xception: Meet The Xtreme Inception
[6] https://github.com/tstandley/Xception-PyTorch/blob/master/xception.py
[7] Rethinking the Inception Architecture for Computer Vision
All rights reserved
