Những lưu ý khi thiết kế cơ sở dữ liệu
Bài đăng này đã không được cập nhật trong 7 năm
Giới thiệu
Trích dẫn từ Wiki
Chuẩn hóa cơ sở dữ liệu là một phương pháp khoa học để phân tách (scientific method of breaking down) một bảng có cấu trúc phức tạp (complex table structures) thành những bảng có cấu trúc đơn giản (simple table structures) theo những quy luật đảm bảo (certain rule) không làm mất thông tin dữ liệu. Kết quả là sẽ làm giảm bớt sự dư thừa và loại bỏ những sự cố mâu thuẫn về dữ liệu, tiết kiệm được không gian lưu trữ. Một số dạng chuẩn hóa dữ liệu thông dụng là:
- Dạng chuẩn thứ nhất (First Normal Form - 1NF)
- Dạng chuẩn thứ hai (Second Normal Form - 2NF)
- Dạng chuẩn thứ ba (Third Normal Form - 3NF)
- Dạng chuẩn Boyce-Codd (Boyce-Codd Normal Form - BCNF)
Chắc hẳn chúng ta không còn xa lạ gì với bốn quy tắc chuẩn hóa dữ liệu khi thiết kết cở sở dữ liệu này. Có thể nói đây là 4 quy tắc vàng được mọi người xem như là kim chỉ nam khi thiết kết cở sở dữ liệu. Nhưng ngoài các quy tắc này chúng ta cần lưu ý thêm một vài quy tác sau để cở sở dữ liệu chúng ta tạo ra tốt hơn nhé.
Xác định bản chất của ứng dụng
Khi chúng ta bắt đầu thiết kế cơ sở dữ liệu, điều đầu tiên cần xác định là bản chất của ứng dụng bạn đang thiết kế là gì, Transactional hay Analytica?
Một lỗi chúng ta rất hay mắc phải là áp dụng các quy tắc chuẩn hóa mà không cần suy nghĩ về bản chất của ứng dụng và sau đó đi vào các vấn đề về hiệu suất và tùy chỉnh.
Như đã nói, có hai loại ứng dụng là:
-
Transactional: Trong loại ứng dụng này, người dùng cuối của bạn quan tâm nhiều hơn đến CRUD, tức là create, read, update, và delete bảng ghi. Cơ sở dữ liệu cho hệ thống này được gọi là OLTP.
-
Analytical: Trong các loại ứng dụng này, người dùng cuối của bạn quan tâm nhiều hơn đến phân tích, báo cáo, dự báo v.v... Những loại cơ sở dữ liệu này có số lần chèn và cập nhật ít hơn. Mục đích chính ở đây là tìm nạp và phân tích dữ liệu nhanh nhất có thể. Cơ sở dữ liệu cho hệ thống này được gọi là OLAP.
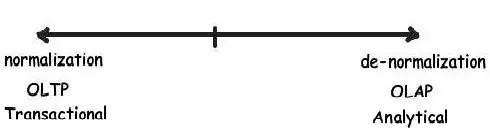
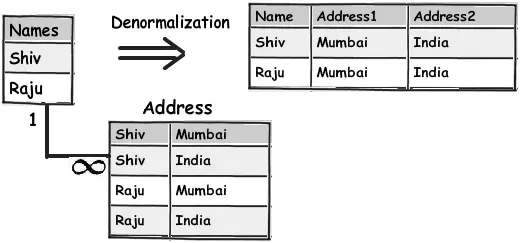
Cụ thể nếu bạn nghĩ rằng chèn, cập nhật và xóa là nổi bật hơn thì hãy thiết kế bảng chuẩn hóa(normalization), nếu không thì tạo cấu trúc cơ sở dữ liệu không chuẩn hóa phẳng(denormalized).
Ví dụ: Giả sử chúng ta có một danh sách người dùng và mỗi người dùng sẻ có một tên và nhiều địa chỉ khác nhau. Normalization - thông thường chúng ta sẻ thiết kế ra bảng cho quan hệ 1-n. Còn Denormalized - chúng ra sẻ làm phẳng cấu trúc thành một bảng với nhiều cột địa chỉ, lúc này dữ liệu của người dùng hoàn toàn nằm trên 1 bảng giúp cho việc tìm, phần tích v.v.. sẻ nhanh chóng hơn.
Nên hay không nên chia nhỏ cấu trúc dữ liệu
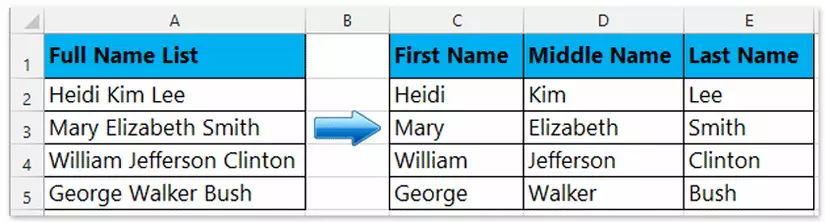
Khi truy vấn có sử dụng nhiều hàm phân tích chuỗi như substring, charindex chúng ta nên chia nhõ cấu trúc dữ liệu để câu truy vấn rõ ràng và tối ưu hơn.
Ví dụ: Bảng bên dưới có trường tên sinh viên. Giả sử chúng ra muốn truy vấn các sinh viên có từ “lee” và không có từ “william” hoặc là muốn biết chính sát họ,tên đệm, tên của sinh viên là gì thì sẻ thực sự khó khăn. Vì vậy giải pháp tốt hơn là thay vì lưu cả họ và tên vào một trường chúng ta hãy chia nhỏ ra lưu họ riêng, tên đệm riêng, tên riêng, từ đó ta có thể viết câu truy vấn rõ ràng và tối ưu hơn.
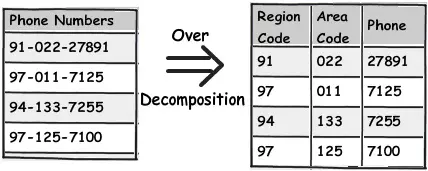
Tuy nhiên chúng ta không nên lạm dụng quy tắc trên quá nhiều khi không thật sự cần thiết, vì điều đó sẻ gây ra nhiều khó khăn trong lúc tạo, cập nhật dữ liệu
Ví dụ: Trường số điện thoại rất hiếm khi phải sử dụng đến mã ISD. Vì thế không nênphân rã các phần của số điện thoại thành các trường riêng biệt.
Thiết kế bảng chung
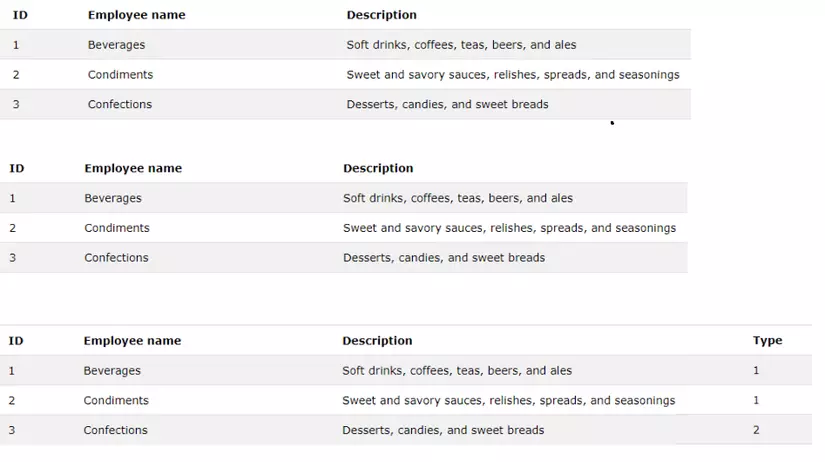
Thông thường chúng ta hay thiết kết cơ sở dữ liệu theo hướng đối tượng, tức là mỗi đối tượng sẻ là bảng. Điều này là tốt nhưng nếu cấu trúc dữ liệu của các đối tượng là giống nhau thì chúng ta có thể gộp chung lại một bảng và sau đó thêm một trường để phân biệt hai đối tượng.
Ví dụ:
Giả sử chúng ta có 2 bảng nhân viên và khách hàng chỉ chưa các thông tin là tên và mô tả giống nhau thì chúng ta có thể thiết kế bảng chung, điều này giúp chúng ta thay vì phải thực hiện CRUD trên 2 bảng thì chúng ta chỉ cần thực hiện trên 1 bảng.
Lưu ý khi đánh index
Bộ tối ưu SQL phụ thuộc nhiều vào các index được định nghĩa cho bảng. Không index sẽ làm chậm tốc độ truy vấn SELECT nhưng quá nhiều index sẽ làm chậm các truy vấn tạo và cập nhật dữ liệu. Vì vậy nếu bạn đang insert hàng nghìn dòng trong 1 hệ thống trực tuyến, sử dụng bảng tạm để tải dữ liệu. Đảm bảo chắc chắn rằng bảng tạm này không có index. Di chuyển dữ liệu từ bảng này sang bảng khác nhanh hơn nhiều so với tải dữ liệu từ nguồn bên ngoài và nên cân nhắc việc xóa các index trong bảng trước khi tải số lượng lớn các lô của dữ liệu. Việc này làm cho lệnh insert chạy nhanh hơn vì mỗi lần lệnh insert hoàn thành nó sẻ tạo tại index
Tham khảo
https://www.codeproject.com/Articles/359654/11-important-database-designing-rules-which-I-fo-2
All rights reserved
