Người kiến tạo tri thức: SageMaker và tổng quan các bước trong triển khai mô hình học máy
Mở đầu
Chỉ trong một vài năm trở lại đây, trí tuệ nhân tạo (artificial intelligence), học máy (machine learning), và đặc biệt là học sâu (deep learning) đã cho thấy tốc độ phát triển đáng kinh ngạc, hứa hẹn trở thành ngành công nghệ mũi nhọn của thế giới. Ngày càng nhiều cá nhân, tổ chức, và doanh nghiệp trong nhiều lĩnh vực muốn tận dụng sức nóng của AI để tạo ra giá trị và lợi nhuận, thông qua việc huấn luyện các mô hình (model) dựa trên lượng dữ liệu và nguồn tài nguyên tính toán khổng lồ để tạo ra các sản phẩm thông minh, cải thiện hiệu suất làm việc, hay để đưa ra các quyết định sáng suốt.
Tuy nhiên, những người làm nghiên cứu về khoa học dữ liệu và AI thường chỉ dửng lại ở việc phát triển mô hình ở cục bộ, tức là trên máy tính cá nhân hoặc trong các Jupyter Notebooks đơn lẻ để lưu lại được tạo tác mô hình (model artifacts) và chạy đánh giá, mà chưa chú trọng đến việc chuẩn bị triển khai (deploy) mô hình sao cho người dùng thực tế có thể sử dụng, dẫn đến hạn chế trong việc biến những mô hình này thành lợi ích thực sự.
May mắn thay, cùng với sự phát triển của AI, các nền tảng điện toán đám mây lớn cũng dần cho ra đời những dịch vụ hỗ trợ triển khai các mô hình học máy từ mã nguồn (code) chạy suy luận (inference) và model artifacts phù hợp. Trong số những dịch vụ này, không thể không kể đến SageMaker, một dịch vụ quản lý ML toàn diện hàng đầu của AWS, cho phép các nhà phát triển nhanh chóng thử nghiệm, quản lý môi trường, thuê máy chủ hỗ trợ GPU, cũng như triển khai, quản lý, và mở rộng quy mô cho quá trình vận hành mô hình.
Tuy tiềm năng của SageMaker là vậy, việc triển khai mô hình đối với người chưa có nhiều kinh nghiệm vẫn có thể gặp một số trở ngại. Bài viết này sẽ giới thiệu cho các bạn các bước chính trong việc deploy model thông qua Docker, FastAPI, và AWS SageMaker, cũng như cách lựa chọn cài đặt phù hợp và các lỗi sai có thể xảy ra trong quá trình này.
Deploy model với FastAPI, Docker, và SageMaker
Các bước chính trong quá trình này bao gồm:
- Huấn luyện (train) model để có được model artifacts
- Lưu model artifacts lên một S3 bucket
- Đóng docker (dockerize) đối với code chạy inference để có Docker image
- Đẩy Docker image lên Amazon Elastic Container Registry (ECR)
- Tạo một SageMaker model, sử dụng các model artifacts (đã lưu ở bước 4) và Docker image (đã có trên ECR từ bước 3) nói trên
- Tạo một SageMaker endpoint configuration, để xác định SageMaker model ở bước 5 và tài nguyên tính toán cần thuê để chạy inference
- Tạo một SageMaker endpoint bất đồng bộ (asynchronous endpoint) với configuration ở bước 6
- Sử dụng boto3 để gọi (invoke) đến endpoint trực tiếp
- Tự động điều chỉnh tài nguyên (Auto-scale) với SageMaker endpoint
Bước 1: Train model
Các bạn có thể train model của mình ở bất cứ nơi nào bạn muốn. Điều mấu chốt là sau khi train, các bạn có được một tập hợp các file cần thiết để deploy model. Bên cạnh đó, các bạn cũng có thể tải artifact từ các model có sẵn trên HuggingFace, v.v. để triển khai. Bài viết này sẽ sử dụng trực tiếp pipeline về tóm tắt văn bản (text summarization) của thư viện transformers, thông qua mô hình facebook/bart-large-cnn. Các artifact của mô hình được tải xuống và đóng thành một file có định dạng .tar.gz, file này sẽ được SageMaker unzip để sử dụng.
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="facebook/bart-large-cnn",
local_dir="model",
local_dir_use_symlinks=False,
ignore_patterns=["*.bin", "*.h5", "*.msgpack", "*.ot"]
)
Chú ý rằng tên folder model ở đây là hoàn toàn ngẫu nhiên, có thể là tên bất kì - khi giải nén tệp .tar.gz này sẽ trả lại một folder với tên đó. Để zip cả folder thành file định dạng .tar.gz, các bạn có thể dùng câu lệnh
tar -czvf model.tar.gz model
Như vậy bạn đã có và đóng gói model artifacts cần thiết.
Bước 2: Lưu model artifacts lên S3
Bước này không quá phức tạp. Bài viết này sẽ không phân tích vào các khía cạnh chi tiết hơn về quản lý truy cập, mã hóa, hay bảo mật thông tin, nên những lựa chọn còn lại trên giao diện upload của S3 sẽ được giữ như mặc định. Tùy vào tính chất của công việc, các bạn nên tìm hiểu và trao đổi thêm với những người có liên quan về những vấn đề này.
Bước 3: Đóng docker với code inference
Dù cho quá trình inference có đơn giản hay phức tạp, toàn bộ phần code này cần được xây dựng dưới hình thức một API endpoint lắng nghe (listen) ở cổng 8080, và cần cung cấp hai phương thức tối thiểu sau:
- GET request tới
/ping. Đây là method SageMaker sẽ gọi để kiểm tra xem endpoint còn sống hay không - POST request tới
/invocations. Đây là method thực hiện toàn bộ công việc inference cho một request nào đó. Tất nhiên, cấu trúc của request (có những trường gì với kiểu dữ liệu nào) là tùy model, tuỳ cách chạy inference.
Ví dụ, một endpoint đơn giản có thể chỉ cần như phía dưới:
# app/main.py
import os
from fastapi import FastAPI, Request
from transformers import pipeline
app = FastAPI()
summarizer = pipeline(
"summarization",
model=os.environ.get("MODEL_NAME"),
device="cuda"
)
@app.get("/ping")
async def ping():
return {"message": "ok"}
@app.post("/invocations")
async def invocations(request: Request):
data = await request.json()
paragraph = data.get("text")
max_length = data.get("max_length", 50)
min_length = data.get("min_length", 25)
summary = summarizer(
paragraph,
max_length=max_length,
min_length=min_length,
do_sample=False
)
return {"summary": summary[0]["summary_text"]}
Bài viết này sử dụng FastAPI, một framework đơn giản và hiệu năng cao cho lập trình web. Tất nhiên, khi mô hình phức tạp hơn, các bạn có thể tận dụng thêm các yếu tố khác của FastAPI, như Depends, APIRouter, hay các mô hình dữ liệu phức tạp dựa trên BaseModel...
Mã nguồn của các bạn sẽ có cấu trúc tối thiểu như sau
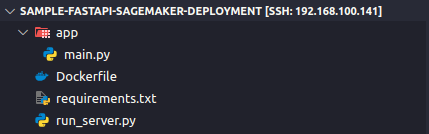
Để có được Docker image, bạn cần viết Dockerfile cho mã nguồn của mình.
# Dockerfile
FROM python:3.9-slim
WORKDIR /opt/src
ADD ./requirements.txt /opt/src/requirements.txt
RUN pip install --no-cache-dir -r /opt/src/requirements.txt
ADD . /opt/src/
EXPOSE 8080
RUN chmod +x run_server.py
ENTRYPOINT ["python", "run_server.py"]
Thông thường, Dockerfile kết thúc bằng lệnh CMD để bắt đầu thực hiện một câu lệnh nào đó khi khởi động container. Tuy nhiên, documentation của SageMaker nói rằng khi SageMaker chạy một container bằng docker run image serve để kích hoạt chế độ inference, lệnh CMD sẽ được ghi đè bởi tham số serve, từ đó khiến endpoint không thể khởi động. Thay vào đó, nhà phát triển SageMaker gợi ý sử dụng lệnh ENTRYPOINT thay thế, để container có thể xử lý các tín hiệu SIGTERM và SIGKILL khi muốn dừng hay bật lại container. Documentation không giải thích rõ hơn về vấn đề này.
Bản thân run_server.py sẽ gọi đến lệnh để khởi động endpoint
# run_server.py
import uvicorn
if __name__ == "__main__":
uvicorn.run(
"app.main:app",
host="0.0.0.0",
port=8080,
proxy_headers=True
)
Còn requirements.txt, như thông thường, sẽ ghi lại những thư viện cần cài đặt.
Bước 4: Đẩy Docker image lên ECR
Trước tiên, các bạn hãy lên giao diện của Amazon Elastic Container Registry để tạo một repository mới cho Docker container. Các yếu tố về mã hóa, tag, ... có thể để như mặc định.
Sau đó, khi nhấn chọn vào repository mới được tạo, và nhấn nút "View push commands", hệ thống sẽ hiện thị 4 câu command cần được sử dụng.
aws ecr get-login-password --region <your_region> | docker login --username AWS --password-stdin xxxxxxxxxx.dkr.ecr.<your_region>.amazonaws.com
docker build -t <your_repository_name> .
docker tag <your_repository_name>:latest xxxxxxxxxx.dkr.ecr.<your_region>-1.amazonaws.com/<your_repository_name>:latest
docker push xxxxxxxxxx.dkr.ecr.<your_region>.amazonaws.com/<your_repository_name>:latest
Lần lượt, các command này để (1) xác thực với ECR, (2) build Docker image, (3) gắn tag cho image được build tương ứng với repository trên ECR, và (4) đẩy lên ECR. Khi thành công, repository sẽ hiện ra image gần nhất (latest) của nó.
Bước 5: Tạo SageMaker model
Bài viết này sẽ chủ yếu sử dụng Python SDK (Boto3) để khởi tạo các tài nguyên của SageMaker. Những gì làm được ở SDK hoàn toàn có thể làm được qua CLI hay chính giao diện trên AWS, tuy nhiên làm việc với mã nguồn thường sẽ đơn giản và tránh gặp lỗi hơn.
Hãy mở Jupyter Notebook và đảm bảo môi trường mà bạn đang sử dụng có đầy đủ các quyền để có thể truy cập đến các tài nguyên cần thiết trên AWS nhé. Với bài viết này, ý tưởng là các bạn làm việc trong một session, tạo ra các client để tương tác với SageMaker và SageMaker Runtime, và tạo ra một execution role để ủy quyền cho SageMaker truy cập các tài nguyên AWS.
import boto3
from sagemaker import get_execution_role
from sagemaker import Session
session = boto3.Session(profile_name=...)
sagemaker_client = session.client(service_name='sagemaker')
runtime_sagemaker_client = session.client(service_name='sagemaker-runtime')
account_id = session.client('sts').get_caller_identity()['Account']
region = session.region_name
sagemaker_session = Session(boto_session=session, sagemaker_client=sagemaker_client, sagemaker_runtime_client=runtime_sagemaker_client)
role = get_execution_role(sagemaker_session=sagemaker_session)
Mã nguồn để tạo SageMaker model như sau:
from time import gmtime, strftime
model_name = "your_model_name" + strftime("%Y-%m-%d-%H-%M-%S", gmtime())
container = "xxxxxxxxxx.dkr.ecr.<your_region>.amazonaws.com/<your_container_name>:latest"
container = {
'Image': container,
'ModelDataSource': {
'S3DataSource': {
'S3Uri': 's3://s3/uri/to/model.tar.gz',
'S3DataType': 'S3Object',
'CompressionType': 'Gzip',
}
},
'Environment': {
'MODEL_DIR': '/opt/ml/model/model',
}
}
create_model_response = sagemaker_client.create_model(
ModelName = model_name,
ExecutionRoleArn = role,
Containers = [container])
print("Model Arn: " + create_model_response['ModelArn'])
Theo quy ước, các tài nguyên SageMaker thường có ấn định thời gian ở trong tên để tạo ra một cái tên độc nhất và dễ theo dõi. Để khởi tạo SageMaker model, các bạn cần truyền URI của repository trên ECR cũng như truyền URI của file định dạng .tar.gz đang lưu model artifacts trên S3.
Khi truyền ModelDataSource ở đây, bản chất SageMaker sẽ đưa file .tar.gz vào và unzip trong container (hãy nhớ rằng, vì ở phía trên, folder tên model được zip, nên khi unzip cũng sẽ trả lại một folder tên model). SageMaker sẽ tự động unzip vào đường dẫn opt/ml/model, nghĩa là bản thân những file artifact (model.safetensors, config.json, v.v) sẽ nằm ở đường dẫn opt/ml/model/model, chính là biến môi trường MODEL_DIR cần truyền vào code inference ở bước 3.
Bước 6: Tạo SageMaker endpoint configuration
from time import gmtime, strftime
endpoint_config_name = "your_config_name" + strftime("%Y-%m-%d-%H-%M-%S", gmtime())
print('Endpoint config name: ' + endpoint_config_name)
model_name = ... # defined in the previous step
create_endpoint_config_response = sagemaker_client.create_endpoint_config(
EndpointConfigName = endpoint_config_name,
ProductionVariants=[{
'InstanceType': 'ml.g4dn.xlarge', # or some other types
'InitialInstanceCount': 1,
'InitialVariantWeight': 1,
'ModelName': model_name,
'VariantName': 'AllTraffic'
}],
AsyncInferenceConfig={
'OutputConfig': {
'S3OutputPath': 's3://path/to/bucket/for/successful/requests',
'S3FailurePath': 's3://path/to/bucket/for/failed/requests',
'NotificationConfig': {
'SuccessTopic': 'arn:aws:sns:ap-northeast-1:250506505253:image-search-module-success',
'ErrorTopic': 'arn:aws:sns:ap-northeast-1:250506505253:image-search-module-fail',
'IncludeInferenceResponseIn': ['SUCCESS_NOTIFICATION_TOPIC', 'ERROR_NOTIFICATION_TOPIC']
}
}
}
)
print("Endpoint config Arn: " + create_endpoint_config_response['EndpointConfigArn'])
SageMaker cung cấp một vài lựa chọn về quá trình deploy model, trong đó có việc deploy dưới hình thức Endpoint thời gian thực (real-time endpoint) hoặc Endpoint bất đồng bộ (asynchronous endpoint). Điểm khác nhau lớn nhất, đúng theo tên gọi, đó là real-time endpoint được sử dụng khi việc gọi đến endpoint là liên tục và thời gian cho endpoint xử lý là ngắn (cụ thể là dưới 60 giây), trong khi asynchronous endpoint được sử dụng khi thời gian xử lý request cần phải dài hơn và không phải lúc nào endpoint cũng cần phải gọi đến. Bài viết này sẽ tập trung vào loại thứ hai.
Vì kết quả không được trả lại trực tiếp, asynchronous endpoint yêu cầu phải có S3OutputPath và S3FailurePath, là hai bucket trên S3 được chọn để lưu phản hồi (response) của endpoint khi xử lý request thành công hoặc thất bại. Các bạn hãy tạo hai bucket này trên S3 và truyền URI của chúng làm tham số.
Cũng về vấn đề output, vì asynchronous endpoint không trả lại kết quả xử lý ngay lập tức mà đưa kết quả này vào S3, SageMaker cũng xây dựng một cơ chế đơn giản để thông báo mỗi khi có kết quả của một lần xử lý request nào đó. Điều này được thể hiện qua 2 tham số của NotificationConfig, bao gồm SuccessTopic và ErrorTopic, lần lượt là 2 tài nguyên Simple Notification Service (SNS) của AWS, để thông báo thành công hay thất bại. Các bạn hãy tạo hai topic này trên giao diện của SNS, lựa chọn loại SNS thông thường, và truyền ARN của các topic này làm tham số.
Hai topic này là một phần quan trọng trong việc tích hợp SageMaker vào một hệ thống sử dụng Machine Learning - ví dụ, một HTTPS endpoint có thể đăng ký lắng nghe (subscribe) đến topic để biết được request đã xử lý xong, từ đó đọc file từ S3 để xử dụng kết quả của model.
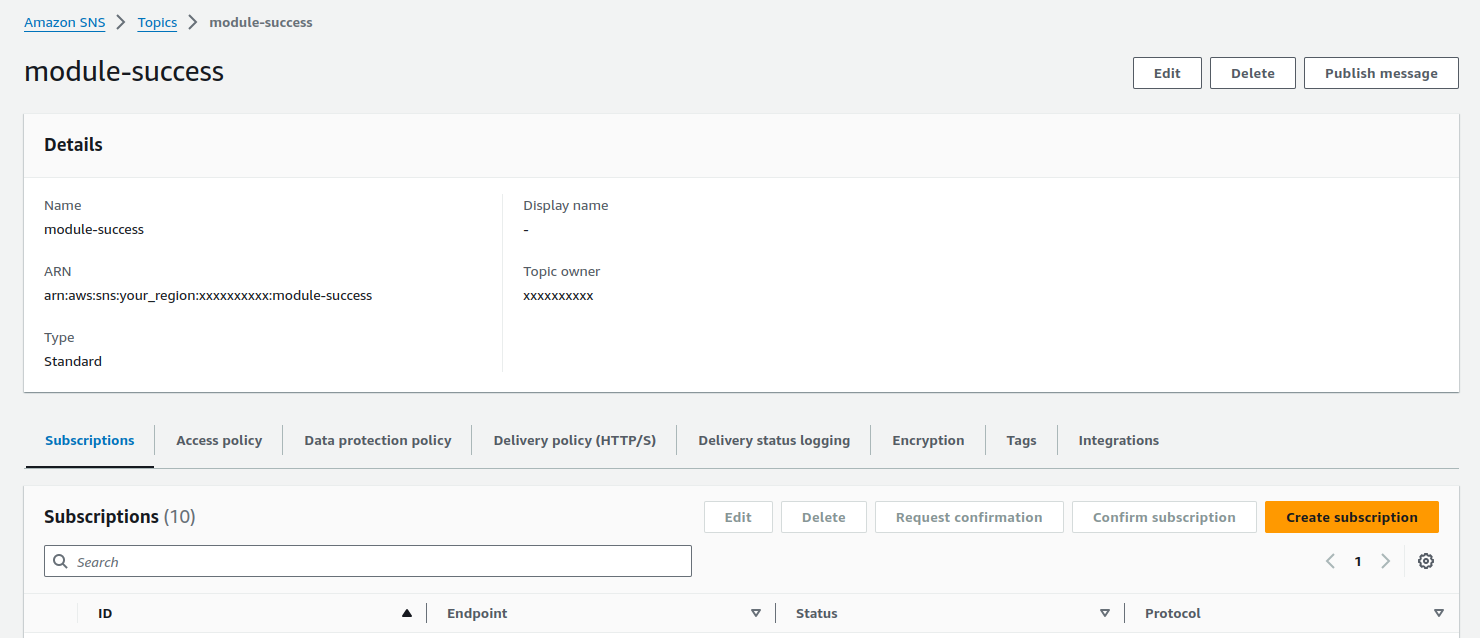
Ngoài vấn đề output của endpoint bất đồng bộ, SageMaker endpoint configuration nói chung còn đóng vai trò liệt kê loại tài nguyên các bạn muốn thuê để chạy model inference. InstanceType đưa ra tên loại máy muốn sử dụng (hãy đảm bảo rằng loại máy đó được cấp trong AWS Region của bạn), InitialInstanceCount đưa ra số máy bạn muốn sử dụng, còn ModelName chính là tên SageMaker model được tạo ra ở Bước 5. Nếu bạn để ý, những tham số kia nằm trong một dictionary, cũng là một phần tử của list là ProductionVariants. SageMaker đưa ra variants để có cơ chế sử dụng nhiều model, với nhiều loại tài nguyên khác nhau cho một endpoint configuration - InitialVariantWeight đại diện cho tỉ lệ traffic đến variant đó. Nếu các bạn muốn tất cả request đều được xử lý bởi một model và tài nguyên giống nhau, thì ở đây chỉ cần khai báo một variant.
Bước 7: Tạo SageMaker asynchronous endpoint
endpoint_name = MODEL + strftime("%Y-%m-%d-%H-%M-%S", gmtime())
print('Endpoint name: ' + endpoint_name)
create_endpoint_response = sagemaker_client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name
)
print('Endpoint Arn: ' + create_endpoint_response['EndpointArn'])
resp = sagemaker_client.describe_endpoint(EndpointName=endpoint_name)
status = resp['EndpointStatus']
print("Endpoint Status: " + status)
print('Waiting for {} endpoint to be in service...'.format(endpoint_name))
waiter = sagemaker_client.get_waiter('endpoint_in_service')
waiter.wait(EndpointName=endpoint_name)
Khi đã có endpoint configuration, việc tạo endpoint chỉ còn là việc đưa ra một cái tên (nên được gắn timestamp để khiến tên độc nhất và dễ theo dõi). Quá trình tạo endpoint thường sẽ mất từ 4 phút rưỡi đến 5 phút - nếu quá 6-7 phút, khả năng rất cao là đã có lỗi. Khi đó, các bạn có thể vào model container logs trên giao diện SageMaker endpoint để đọc log trên CloudWatch và debug. Thường SageMaker sẽ mất rất nhiều thời gian trước khi đánh dấu một endpoint là thất bại, vì vậy, hãy thường xuyên kiểm tra, và khi thấy báo lỗi, bạn hãy xóa endpoint đó đi.
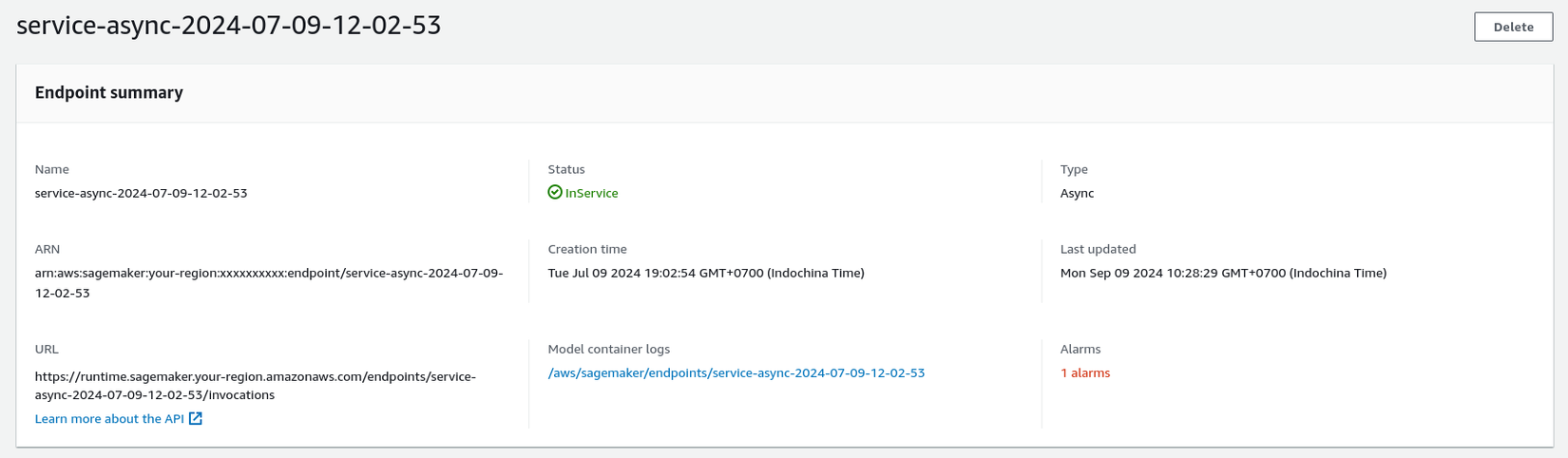
Bước 8: Invoke endpoint bằng boto3
AWS cung cấp SDK cho ngôn ngữ Python thông qua thư viện boto3, và trong các bước trước, các bạn đã dùng boto3 để tương tác với vị trí client của SageMaker và SageMaker Runtime, để từ đó tạo ra endpoint. Đi thêm một bước nữa, boto3 cũng có thể được dùng để gọi tới và gửi request tới SageMaker endpoint.
Trước tiên, cần biết rằng SageMaker asynchronous endpoint có yêu cầu một số tham số. EndpointName chính là tên của endpoint bạn muốn gọi, InputLocationlà đường dẫn trên S3 trỏ tới file chứa request, và ContentType, thường là application/json cho một request điển hình. Điều mấu chốt ở đây đó là một asynchronous endpoint làm việc với một file input đã được upload lên S3 - như vậy, khi invoke endpoint, trước hết bạn cũng cần upload request của bạn lên S3.
Các bạn có thể tham khảo phần code sau đây:
import json
import time
import urllib
import sagemaker
from botocore.exceptions import ClientError
session = boto3.Session(profile_name="sagemakerdev")
sm_session = sagemaker.session.Session(boto_session=session)
def upload_file(path):
"""
Function to upload a file onto S3.
Returns the string that is the path on S3 pointing at the BUCKET containing that file.
"""
prefix = f"blip-vqa-service-async"
key_prefix = 'your-key-prefix' + prefix
bucket_name = 'your-bucket-name'
return sm_session.upload_data(
path=path,
bucket=bucket_name,
key_prefix=key_prefix,
extra_args={"ContentType": "application/json"},
)
def get_output(output_location):
"""
Function to loop and try to obtain results from a specific S3 path.
Returns the dictionary that is the output.
"""
output_url = urllib.parse.urlparse(output_location)
while True:
try:
return json.loads(sm_session.read_s3_file(bucket=output_url.netloc, key_prefix=output_url.path[1:]))
except ClientError as e:
if e.response["Error"]["Code"] == "NoSuchKey":
print("waiting for output...")
time.sleep(2)
continue
raise
# Specify request
request = {
# Insert your request, following your own schema
...
}
# Save to a .json file in local
with open('input.json', 'w') as json_file:
json.dump(request, json_file, indent=4)
# Send request to invoke endpoint
endpoint_name = ...
response = runtime_sagemaker_client.invoke_endpoint_async(
EndpointName=ENDPOINT_NAME,
InputLocation=input_s3_dir + f"/input.json",
ContentType='application/json'
)
# Loop to wait for the output
output = get_output(response['OutputLocation'])
print(output)
Chú ý rằng hàm để upload file input sẽ trả lại đường dẫn tới bucket chứa input đó, còn InputLocation cần đường dẫn cụ thể tới input đó. Thời gian có được output sẽ phụ thuộc vào liệu endpoint có đang có máy để chạy không và bản thân tốc độ của quá trình inference.
Bài viết này sẽ không đề cập tới API Gateway, nhưng khi đã có SageMaker endpoint, có thể dễ dàng thiết lập một REST API trên API Gateway, cùng với API key (truyền cùng header) và những tính chất đi kèm, để dễ dàng deploy và sử dụng model. API này sẽ có các resource khác nhau (ví dụ, /call_model_1, /call_model_2,...), mỗi resource sẽ có một hoặc một vài method (POST, GET, ...) tích hợp tài nguyên AWS. Để làm được điều này, cần thiết lập mapping giữa các trường gửi tới API và các trường gứi tới tài nguyên AWS, chính là SageMaker endpoint, cũng như giữa các trường do endpoint trả lại và các trường API trả lại.



Bước 9 (optional): Autoscale một SageMaker endpoint
Nếu như các bạn đã làm theo các bước trước, thì asynchronous endpoint của các bạn đã hoạt động và endpoint cũng đang có một (hoặc nhiều hơn một) máy được thuê để chạy inference. Tuy nhiên, asynchronous endpoint được thiết kế với use case là sử dụng không thường xuyên, không đều đặn, trong khi đó, nếu vẫn liên tục thuê máy kể cả khi không được sử dụng, thì sẽ tạo ra những chi phí AWS không đáng có. Để khắc phục điều này, AWS nói chung và SageMaker nói riêng có sử dụng dịch vụ Auto-scaling, hiểu nôm na là tự điều chỉnh lượng tài nguyên cần thuê (cụ thể là số instance - số máy ảo) dựa trên traffic (hay số request) gọi tới một endpoint.

Asynchronous endpoint có thể thu nhỏ số lượng instance (scale in) xuống đến 0 hoặc một cận dưới do các bạn tự chọn, hoặc mở rộng số lượng instance (scale out) lên tới giới hạn (quota) của AWS đối với một loại máy cho tài khoản của bạn hoặc một cận trên do các bạn tự chọn. Ví dụ, dòng máy g4dn.xlarge có quota mặc định là 4, nghĩa là auto-scaling có thể điều chỉnh trong khoảng từ 0 đến 4 máy. Quota này có thể được nới rộng bằng cách đặt yêu cầu với AWS.
Bản chất của auto-scaling là làm việc với CloudWatch Alarm, còn bản chất của alarm này là việc AWS có cơ chế theo dõi một số chỉ số (metrics) gắn liền với một endpoint. Khi chỉ số này vượt một ngưỡng được đặt ra và vượt trong một khoảng thời gian đủ lâu, thì SageMaker sẽ tự động điều chỉnh để tăng số instance thuê cho endpoint. Ngược lại, khi chỉ số này hạ dưới ngưỡng đó đủ lâu, thì SageMaker sẽ tự động giảm số instance. Như vậy, để có auto-scaling, các bạn cần suy nghĩ đến MinCapacity và MaxCapacity, cũng như vấn đề về quota của AWS. Bên cạnh đó, cần lựa chọn đúng CustomizedMetricSpecification để có metric và ngưỡng phù hợp. Các bạn có thể tham khảo đoạn code sau đây
endpoint_name = ...
resource_id = f"endpoint/{endpoint_name}/variant/AllTraffic"
autoscaling_client.register_scalable_target(
ServiceNamespace='sagemaker',
ResourceId=resource_id,
ScalableDimension='sagemaker:variant:DesiredInstanceCount',
MinCapacity=0,
MaxCapacity=4
)
policy_name = 'Invocations-ScalingPolicy'
response = autoscaling_client.put_scaling_policy(
PolicyName=policy_name,
ServiceNamespace='sagemaker',
ResourceId=resource_id,
ScalableDimension='sagemaker:variant:DesiredInstanceCount',
PolicyType='TargetTrackingScaling',
TargetTrackingScalingPolicyConfiguration={
'TargetValue': 60,
"CustomizedMetricSpecification": {
"MetricName": "ApproximateAgeOfOldestRequest",
"Namespace": "AWS/SageMaker",
"Dimensions": [{"Name": "EndpointName", "Value": endpoint_name}],
"Statistic": "Maximum",
},
'ScaleOutCooldown': 0,
'ScaleInCooldown': 30
}
)
Một số metrics khác có thể sử dụng có ở bảng dưới. Các metric này đều chỉ ra được một endpoint có đang gặp nhiều hay ít request, nhưng tùy thuộc vào tính chất của hệ thống sử dụng endpoint, nên thử nghiệm và cân nhắc cho phù hợp. Mỗi metric cần lựa chọn một ngưỡng phù hợp - ví dụ, HasBacklogWithoutCapacity có thể chọn target là 0.5
| Tên metric | Mô tả |
|---|---|
| ApproximateBacklogSize | Số lượng request đang trong hàng đợi của một endpoint, đang hoặc chưa được xử lý |
| ApproximateBacklogSizePerInstance | Số lượng request đang trong hàng đợi, tính trung bình trên số lượng instance |
| ApproximateAgeOfOldestRequest | Thời gian đã tồn tại của request đã tồn tại lâu nhất trong hàng đợi |
| HasBacklogWithoutCapacity | Metric nhận giá trị 1 khi có request trong hàng đợi nhưng không có instance nào đang chạy, còn trong các thời điểm khác sẽ nhận giá trị 0. |
Chú ý là auto-scaling cần phải áp dụng cho variant. Ở Bước 6, endpoint configuration chỉ có một variant tên là AllTraffic, nên resource_id ở đây cũng dùng cái tên này. Các tham số khác các bạn có thể giữ nguyên như đoạn code phía trên.
Lời kết
Như vậy, với những bước phía trên, các bạn đã thành công trong việc đưa model AI của mình một bước gần hơn tới sản phẩm thực tế để tiếp cận người dùng, thông qua việc thiết kế mã nguồn theo hướng API endpoint, đóng Docker và đẩy inference code lên ECR, và tạo SageMaker endpoint có thể invoke để xử lý request. Dịch vụ SageMaker của AWS (thực chất là tập hợp của SageMaker, ECR, S3, SNS, API Gateway, v.v, đã được AWS liên kết sẵn) giúp việc phát triển và vận hành model trơn tru hơn, cũng như giúp đơn giản hóa việc thuê và quản lý tài nguyên, từ đó giảm thiểu chi phí trong quá trình deploy model của các cá nhân, tổ chức, hay doanh nghiệp. Với sự phát triển như vũ bão của AI hiện nay, SageMaker sẽ là một công cụ đắc lực để đưa những mô hình AI phức tạp trở thành lợi nhuận và giá trị thiết thực cho doanh nghiệp.
Tài liệu tham khảo
[1]: docs.aws.amazon.com/sagemaker/latest/dg/async-inference.html
[2]: docs.aws.amazon.com/sagemaker/latest/dg/adapt-inference-container.html
[3]: docs.aws.amazon.com/sagemaker/latest/dg/your-algorithms-inference-code.html
[4]: sii.pl/blog/en/deploying-custom-models-on-aws-sagemaker-using-fastapi/
🔗 Kết nối với Pixta Vietnam: http://bit.ly/3kdkzvW
All rights reserved
