Model của bạn thật sự tốt hay chỉ là một sự may mắn?
Bài đăng này đã không được cập nhật trong 2 năm
Nếu từng tham gia các cuộc thi trên Kaggle, bạn sẽ thấy rằng, chỉ cần chênh lệch 0.01% kết quả cũng sẽ làm bạn thằng $100.000 hoặc không có gì trong tay  Lấy ví dụ về cuộc thi Data Science Bowl 2017 Giải thưởng $500.000 cho đội được giải nhất, 200.000 cho đội đứng thứ hai và 100.000 cho đội đứng thứ ba. Metric dùng để đánh giá là log-loss. Dưới đây là bảng xếp hạng của cuộc thi
Lấy ví dụ về cuộc thi Data Science Bowl 2017 Giải thưởng $500.000 cho đội được giải nhất, 200.000 cho đội đứng thứ hai và 100.000 cho đội đứng thứ ba. Metric dùng để đánh giá là log-loss. Dưới đây là bảng xếp hạng của cuộc thi
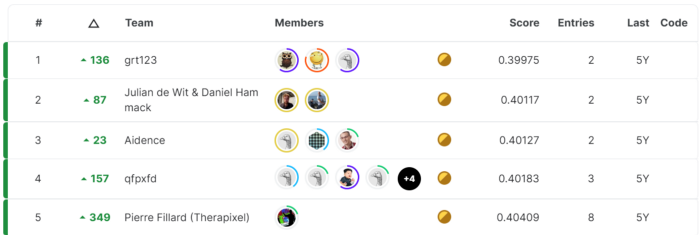
Nhìn thử vào vị trí thứ nhất và vị trí thứ hai, bạn nhận ra điều gì  Nếu như bạn nghĩ model của đội thứ nhất tốt hơn đội thứ hai do có log-loss nhỏ hơn thì đó là một kết luận hơi vội Thực tế như sau:
Nếu như bạn nghĩ model của đội thứ nhất tốt hơn đội thứ hai do có log-loss nhỏ hơn thì đó là một kết luận hơi vội Thực tế như sau:
Làm như nào để ta có thể chắc chắn một model với metric tốt hơn trên tập test data là tốt thật hay chỉ là một sự may mắn?
Tất nhiên, đây chỉ là một cuộc thi trên Kaggle nhưng trên thực tế có rất nhiều trường hợp tương tự. Biết thành phần nào chỉ là một sự ngẫu nhiên trong quá trình lựa chọn model là một kỹ năng cơ bản đối với một nhà khoa học dữ liệu. Trong bài viết này, chúng ta sẽ xem cách định lượng tính ngẫu nhiên liên quan đến quá trình chọn model tốt nhất.
Vậy thì như nào mới là một model tốt thật sự?
Nhưng để rõ ràng hơn, hãy định nghĩa như nào là một "model tốt". Tưởng tượng ta có 2 model A và B, chúng ta đều đồng ý với nhau rằng, model tốt hơn là model có performance tốt trên dữ liệu không được nhìn thấy
Do vậy, ta phải thu thập dữ liệu cho bộ test và đánh giá model trên đó. Giả sử rằng, model A đạt 86% ROC và model B đạt 85% ROC. Điều đó có nghĩa là model A tốt hơn model B không? Thời điểm hiện tại có lẽ là có
Nhưng hãy tưởng tượng rằng, sau một thời gian, bạn đã thu thập thêm dữ liệu và thêm nó vào tập test trước đó. Bây giờ, mô hình A vẫn là 86%, nhưng mô hình B đã tăng lên 87%. Tại điểm này, B tốt hơn A. Vậy giờ như nào nhỉ?
Vậy thì ta có một định nghĩa rõ ràng duy nhất như sau:
Đối với một nhiệm vụ nhất định, mô hình tốt nhất là mô hình hoạt động tốt nhất trên tất cả các dữ liệu không nhìn thấy được
Phần quan trọng của định nghĩa này là “tất cả các dữ liệu không nhìn thấy được”. Thật vậy, chúng ta luôn bị hạn chế trong việc thu thập dữ liệu, vì vậy tập dữ liệu thử nghiệm của chúng ta chỉ là một phần nhỏ của tất cả dữ liệu không nhìn thấy được. Điều này giống như nói rằng chúng ta sẽ không bao giờ thực sự biết đâu là mô hình tốt nhất!
Để đối phó với vấn đề này, chúng ta cần một khái niệm mới.
Universe?
Okay! Giờ thì ta sẽ gọi unseen data có thể có là universe. Tất nhiên, trong thế giới thực, ta hoàn toàn không thể nhìn thấy toàn bộ universe, nhưng một tập dữ liệu test có thấy lấy ngẫu nhiên từ universe
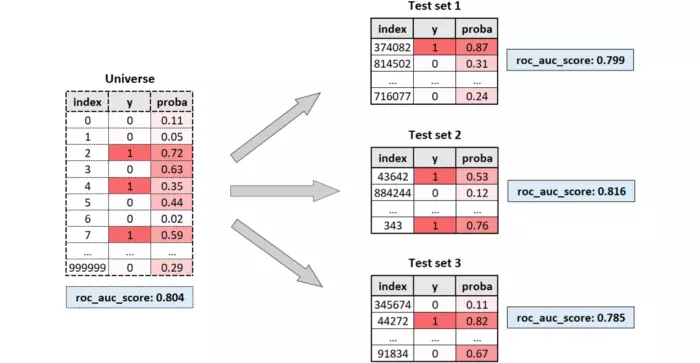
Performance thực sự của một model là performance của nó trên universe. Trong trường hợp này, điểm ROC thực của mô hình là 80,4%. Tuy nhiên, chúng ta không bao giờ có thể quan sát được universe và kết quả là chúng ta không bao giờ có thể quan sát ROC thực sự của mô hình.
Tất cả những gì chúng ta có thể quan sát là điểm ROC được tính trên bộ test. Đôi khi nó sẽ cao hơn (81,6%), đôi khi nó sẽ nhỏ hơn (79,9% và 78,5%), nhưng không có cách nào để chúng ta biết điểm ROC thực sự lớn hay nhỏ hơn bao nhiêu so với điểm ROC được quan sát.
Tất cả những gì chúng ta có thể làm là cố gắng đánh giá mức độ ngẫu nhiên tham gia vào quá trình. Để làm được điều đó, chúng ta cần phải mô phỏng universe và lấy mẫu nhiều bộ dữ liệu test ngẫu nhiên từ nó. Bằng cách này, ta có thể định lượng độ phân tán của các điểm số quan sát được.
Làm như nào để mô phỏng được Universe?
Mục đích của chúng ta là thu được một loạt các quan sát với điểm ROC cho trước. Hóa ra có một cách khá đơn giản để làm điều đó.
Trước hết, chúng ta cần đặt số lượng cá thể mong muốn trong universe (thường là một con số lớn). Sau đó, ta cần đặt mức độ phổ biến, tức là tỷ lệ phần trăm positive (chúng ta có thể để mặc định là 50%). Bước thứ ba là chọn điểm ROC mà chúng ta muốn có trong universe.
Cuối cùng, chúng ta có thể tính toán xác suất dự đoán cho từng cá nhân trong universe: các negative phải cách đều nhau giữa 0 và 1, trong khi positive phải cách đều giữa α và 1.
Trong đó α có thể được tính từ ROC theo công thức sau
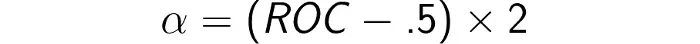
Khi ROC là 50%, α là 0, có nghĩa là sự phân bố của negative và positive là như nhau. Ngược lại, khi ROC là 100%, α là 1, có nghĩa là tất cả các giá trị positive đều tập trung vào 1: không có sự chồng chéo giữa các negative và positive.
Trong Python, điều này có thể được viết thành hàm sau:
def get_y_proba(roc, n=100000, prevalence=.5):
'''Get two arrays, y and proba, for a given roc (greater than .5)'''
n_ones = int(round(n * prevalence))
n_zeros = n - n_ones
y = np.array([0] * n_zeros + [1] * n_ones)
alpha = (roc - .5) * 2
proba_zeros = np.linspace(0, 1, n_zeros)
proba_ones = np.linspace(alpha, 1, n_ones)
proba = np.concatenate([proba_zeros, proba_ones])
return y, proba
Thước đo về sự không chắc chắn
Bây giờ chúng ta có một cách để tạo ra một universe tổng hợp, sử dụng dòng code sau:
y_universe, proba_universe = get_y_proba(roc=.8, n=100000, prevalence=.5)
Vậy universe của chúng ta được tạo nên từ 100.000 quan sát, một nửa số đó là positive và ROC là 80%. Bây giờ, hãy mô phỏng việc trích xuất các bộ test khác nhau. Chúng ta sẽ trích xuất 5.000 bộ test khác nhau, mỗi bộ bao gồm 1.000 quan sát đến từ universe. Đây là code để thực hiện việc đó:
rocs_sample = []
for i in range(5_000):
index = np.random.choice(range(len(y_universe)), 1_000, replace=True)
y_sample, proba_sample = y[index], proba[index]
roc_sample = roc_auc_score(y_sample, proba_sample)
rocs_sample.append(roc_sample)
Đây là sự phân bố của điểm ROC quan sát được:
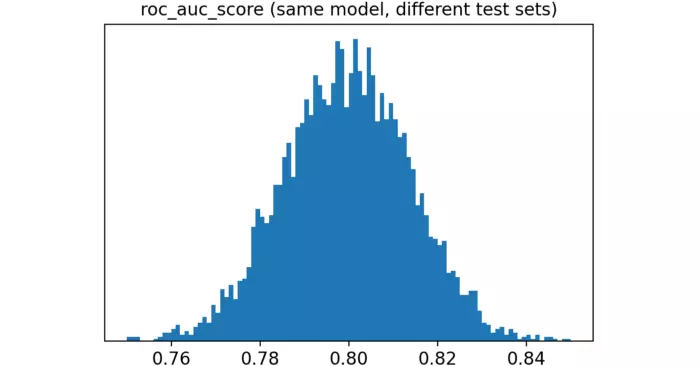
Như bạn có thể thấy, kết quả khá đa dạng, từ nhỏ hơn 76% đến lớn hơn 84%.
Trong các ứng dụng thông thường, câu hỏi mà chúng ta muốn trả lời như sau. Giả sử có hai mô hình, một mô hình có điểm ROC là 78% và mô hình còn lại là 82%. Khả năng là 2 mô hình này có cùng một ROC cơ bản, và sự khác biệt này chỉ là kết quả của sự may rủi?
Để thực hiện ý tưởng, chúng ta có thể tính toán khoảng cách giữa mỗi cặp điểm ROC quan sát được trong mô phỏng. Scikit-learn có một hàm pairwise_distances cho phép thực hiện điều đó.
import numpy as np
from sklearn.metrics import pairwise_distances
dist = pairwise_distances(np.array(rocs_sample).reshape(-1,1))
dist = dist[np.triu_indices(len(rocs_sample), k=1)]
Hãy hình dung khoảng cách theo từng cặp giữa các điểm ROC trong một empirical cumulative distribution function.
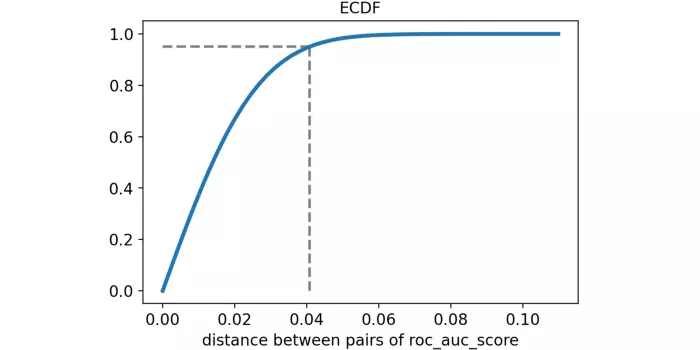
Phân vị thứ 95 (được đánh dấu bằng nét đứt) là khoảng 4%. Điều này có nghĩa là khoảng cách giữa hai mô hình (có cùng hiệu suất) lớn hơn 4% chỉ chiếm 5%.
Do đó, sử dụng ngôn ngữ thống kê, chúng ta sẽ nói rằng sự khác biệt nhỏ hơn 4% là không đáng kể! Điều này khá thú vị bởi vì thông thường chúng ta nghĩ rằng mô hình 82% ROC tốt hơn nhiều so với mô hình 78% ROC
Để có một hình dung khác về khái niệm này, ta thử mô phỏng ba universe khác nhau, một universe có điểm ROC là 75%, một universe khác là 80% và universe cuối cùng là 81%. Đây là những phân phối của điểm ROC được quan sát của chúng.
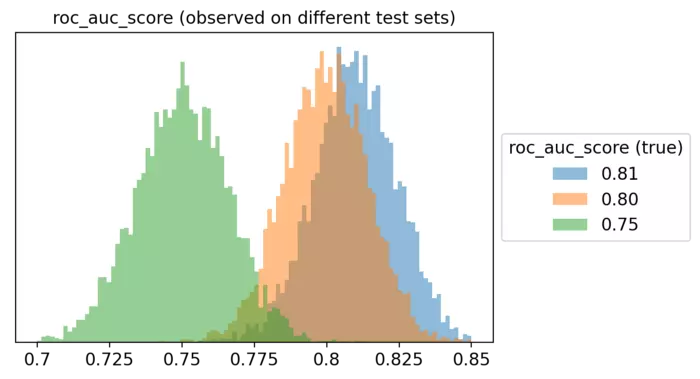
Rõ ràng là từ biểu đồ này, thường thì mô hình tốt nhất sẽ không giành chiến thắng! Chỉ cần tưởng tượng là bạn so sánh hàng chục mô hình, mỗi mô hình có một điểm ROC thực khác nhau.
Rất ít khả năng bạn sẽ thực sự chọn được mô hình tốt nhất. Rất có thể, bạn sẽ chọn ra mô hình "may mắn" có ROC cao nhất.
Cuối cùng thì ta phải làm gì?
Vậy ta có thể nói rằng là không thế kết luận chắc chắn 100% một mô hình này tối hơn một mô hình khác. Điều này nghe như một cơn ác mộng Tất nhiên: không có cái gọi là chắc chắn 100% trong khoa học dữ liệu. Đừng buồn
Có thể kỳ vọng rằng mức độ không chắc chắn trong việc lựa chọn mô hình tốt nhất phụ thuộc cả vào đặc điểm của universe và đặc điểm của tập test được trích xuất từ universe. Đặc biệt, có ba tham số chi phối mức độ không chắc chắn đó:
True ROC: Điểm ROC được tính trên universe.
Sample dimension: số lượng quan sát trong tập test.
Mức độ phổ biến của mẫu (sample prevalence): tỷ lệ phần trăm positive trong bộ testing.
Để xem các yếu tố này tác động như thế nào đến sự không chắc chắn, ta thử mô phỏng điều gì xảy ra bằng cách thử các giá trị khác nhau cho từng yếu tố trong số chúng:
True ROC: 70%, 80% và 90%.
Sample dimension: 1.000, 5.000 và 10.000 quan sát.
Sample prevalence: 1%, 5% và 20%.
Vì chúng ta đang thử ba giá trị cho ba tham số, nên có thể có 27 trường hợp.
Đối với mỗi trường hợp, ta mô phỏng một universe, sau đó lấy mẫu 1.000 bộ test khác nhau và đo điểm ROC tương ứng. Sau đó, ta tính toán ma trận khoảng cách của 1.000 điểm ROC. Cuối cùng, ta lấy được phân vị thứ 95 của khoảng cách (được gọi là “d” kể từ bây giờ). Như ta đã tìm hiểu ở trên, đây là một thước đo cho sự không chắc chắn trong việc lựa chọn mô hình.
Ví dụ, đây là 5 thử nghiệm trong số 27 thử nghiệm.
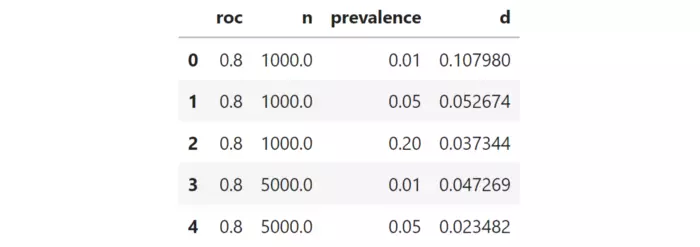
Chúng ta đo độ không chắc chắn với phân vị thứ 95. Con số này càng cao thì độ không chắc chắn trong việc so sánh các đường cong ROC càng cao.
Vì chúng ta muốn biết độ không chắc chắn phụ thuộc vào 3 tham số như thế nào, điều thú vị là đo mối tương quan từng phần giữa mỗi tham số và “d”. Đây là kết quả:
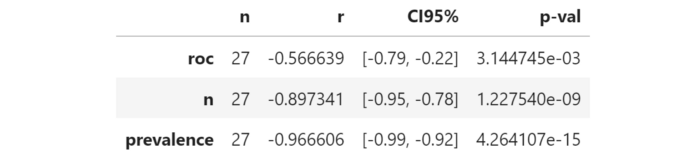
Cột “r” cho thấy mối tương quan từng phần giữa mỗi tham số và độ không chắc chắn. Tất cả các hệ số tương quan đều âm, cho thấy rằng việc tăng bất kỳ hệ số nào trong ba hệ số này sẽ làm giảm độ không chắc chắn (rất clear đúng không ). Đặc biệt,
- True ROC. Điểm ROC cao hơn trong universe có nghĩa là ít "bất ổn" hơn . Điều này có ý nghĩa vì ROC cao hơn có nghĩa là mức độ không chắc chắn nhỏ hơn, theo định nghĩa.
- Sample dimension. Tăng kích thước mẫu làm giảm độ không chắc chắn. Điều này là khá rõ ràng và luôn xảy ra trong các thống kê.
- Sample prevalence. Mức độ phổ biến tăng làm giảm độ không chắc chắn. Tỷ lệ phổ biến nhỏ hơn có nghĩa là ít positive hơn. Ít positive hơn có nghĩa là tính ngẫu nhiên có trọng số hơn khi lấy mẫu chúng. Do đó, sự không chắc chắn càng lớn.
Hãy cũng hình dung sự phân bố của điểm ROC được quan sát khi thay đổi sample dimension và Sample prevalence, để có ROC thực cố định (trong trường hợp này là 80%).
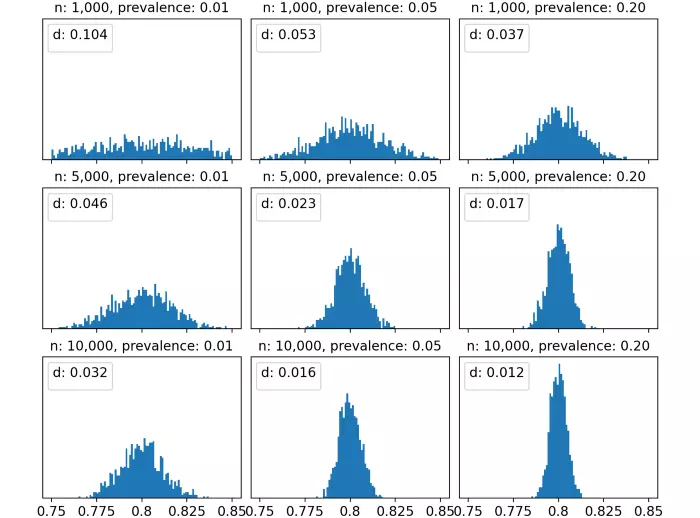
Với biểu đồ đầu tiên, ta chọn cả sample dimension và sample prevalence đều nhỏ: chúng ta có 1.000 quan sát và 1% positive, có nghĩa là 10 positive và 990 negative. Trong trường hợp này, độ không chắc chắn là rất cao và kết quả là phân phối điểm ROC gần như đồng đều, từ 75% và 85%. Hơn nữa, phân vị thứ 95 của khoảng cách giữa các điểm ROC là 10%, có nghĩa là không có sự khác biệt đáng kể giữa ROC quan sát là 75% và ROC quan sát là 85%.
Tuy nhiên, khi chúng ta tăng dần sample dimension và / hoặc sample prevalence của mẫu, tình hình được cải thiện và phân phối điểm ROC quan sát được ngày càng tập trung hơn xung quanh giá trị thực (trong trường hợp này là 80%). Ví dụ: với 10.000 quan sát và 20% sample prevalence, phân vị thứ 95 trở thành 1,2% hợp lý hơn nhiều.
Hmm, vậy cuối cùng những tìm hiểu trên mang lại lợi ích gì?
Trên thực tế, ngay cả khi tất cả chúng ta đều bất lực trước những may rủi, điều quan trọng là phải biết kết quả của model có tính thống kê trong điều kiện nào.
Lặp lại một mô phỏng giống như mô phỏng chúng ta đã thấy trong các phần trước có thể giúp bạn biết liệu sample dimension và sample prevalence của tập test của bạn có đủ để phát hiện sự khác biệt thực sự giữa hiệu suất của các mô hình của bạn hay không.
Tham khảo
[0] https://laurenoakdenrayner.com/2019/09/19/ai-competitions-dont-produce-useful-models/
[1] https://github.com/smazzanti/tds_best_or_luckiest/blob/main/model_selection_best_or_luckiest.ipynb
All rights reserved
