Mô hình ngôn ngữ lớn (LLM) là gì và hoạt động ra sao?
Mô hình ngôn ngữ lớn (Large Language Model, LLM) là hệ thống trí tuệ nhân tạo được huấn luyện trên kho dữ liệu văn bản khổng lồ để hiểu và tạo ra ngôn ngữ tự nhiên.
Về mặt kỹ thuật, nó là một chương trình học cách dự đoán từ tiếp theo dựa trên xác suất toán học — không phải một cỗ máy biết suy nghĩ.
Bản chất của LLM là kết quả của việc phân tích hàng nghìn tỷ câu văn để dựng nên một bản đồ thống kê của ngôn ngữ. Nó không có ý thức, cũng chẳng thật sự thấu hiểu thế giới; thứ nó giỏi là mô phỏng cách con người dùng chữ. LLM không tư duy. Nó tính xác suất.
Mô hình ngôn ngữ lớn là gì và tại sao có quy mô "lớn"?
Để định vị LLM, hãy nhìn vào cấu trúc phân tầng của ngành: trí tuệ nhân tạo → học máy → học sâu → mô hình ngôn ngữ lớn, mỗi lớp là một trường hợp đặc biệt của lớp bên trên. Trí tuệ nhân tạo (AI) là lớp bao quát nhất; học máy (Machine Learning) tập trung vào nhận diện quy luật; học sâu (Deep Learning) dùng mạng thần kinh nhân tạo để xử lý dữ liệu phi cấu trúc; còn LLM là mạng học sâu được tối ưu riêng cho ngôn ngữ.
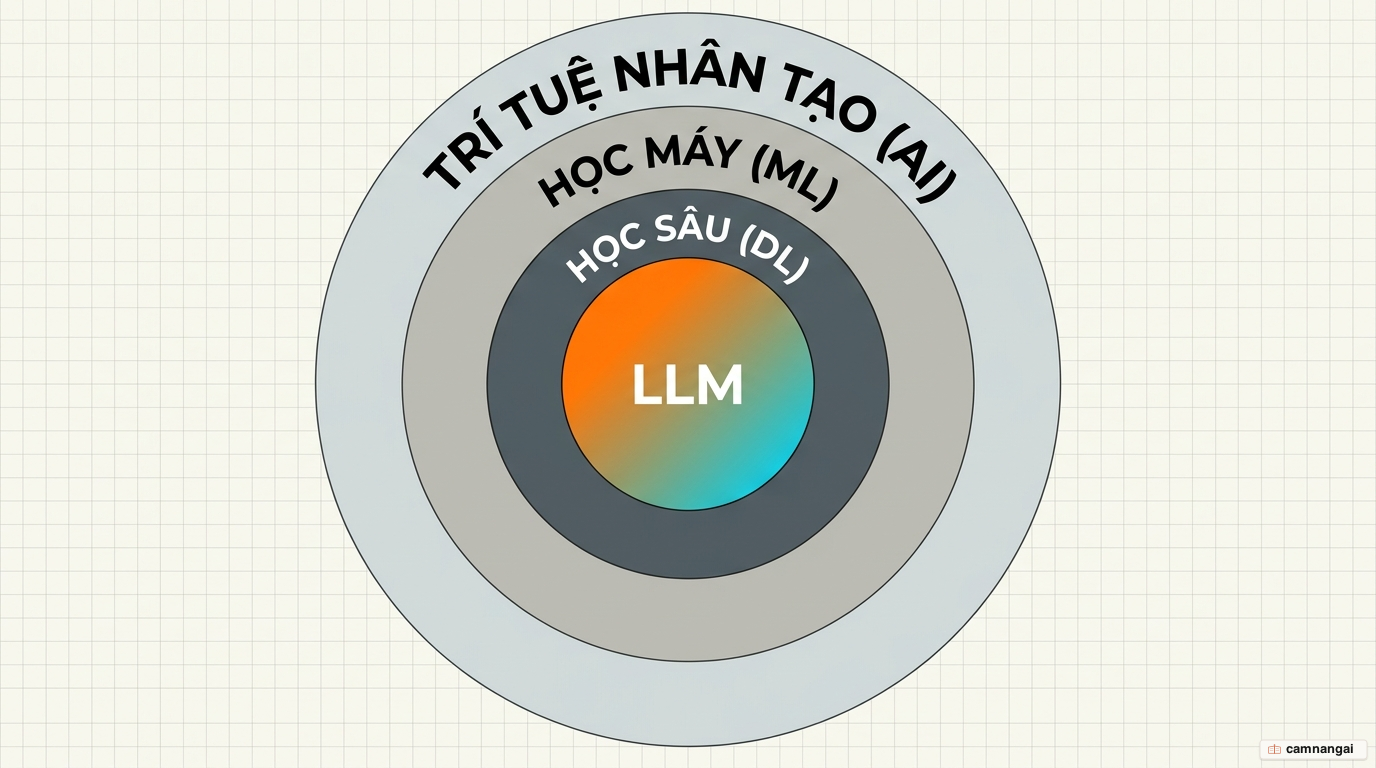
Chữ "lớn" đến từ hai con số:
- Số lượng tham số (parameters). Đây là các biến số nội tại mà mô hình tự tinh chỉnh khi học. GPT-3 có 175 tỷ tham số; các mô hình thế hệ mới như GPT-4 được cho là đã vượt mốc 1 nghìn tỷ. Để dễ hình dung: một mô hình hồi quy tuyến tính đơn giản chỉ cần hai tham số — độ dốc và điểm cắt — để dự đoán một xu hướng.
- Quy mô dữ liệu. "Lớn" còn nằm ở trải nghiệm. Một LLM giống như chương trình đã "đọc" gần hết Internet và hàng triệu cuốn sách, đủ để phân biệt một quả táo với một chiếc Boeing 787 — không qua trải nghiệm vật lý, mà qua khối lượng mô tả ngôn ngữ khổng lồ.
Mô hình ngôn ngữ lớn "học" từ dữ liệu bằng cách nào?
Việc "học" của máy thực chất là một chuỗi phép tính tối ưu hóa nhằm giảm dần sai số.
- Hàm mất mát (loss function). Đây là thước đo mức độ sai của mô hình: sai càng nhiều thì điểm càng cao, và mục tiêu huấn luyện là kéo con số này xuống. Một hàm tốt phải cụ thể, tính được nhanh và phải "mịn". Độ chính xác (accuracy) lại là một hàm dở vì nó có dạng bậc thang — đúng hoặc sai — nên không cho biết mô hình cần chỉnh bao nhiêu. Vì vậy LLM tối ưu theo cross-entropy loss, tạo ra một đường cong sai số mịn để biết mình còn cách đáp án đúng bao xa.
- Hạ gradient ngẫu nhiên (Stochastic Gradient Descent). Thuật toán này tìm hướng "xuống dốc" của sai số. Hãy hình dung một quả cầu lăn trong sương mù, chỉ thấy độ dốc ngay dưới chân để chọn bước kế tiếp. Thay vì nuốt trọn toàn bộ dữ liệu một lúc, nó xử lý theo từng nhóm nhỏ ngẫu nhiên (batch) để việc huấn luyện trở nên khả thi trên kho dữ liệu khổng lồ.
- Tính "tham lam" (greedy). Thuật toán chỉ thấy bước tối ưu ngay trước mắt, không nhìn được toàn cục. Nghịch lý là trong không gian hàng tỷ tham số, lối đi này lại hiệu quả đến bất ngờ.
Vì sao chỉ dự đoán từ tiếp theo lại tạo ra trí tuệ?
Nhiệm vụ cốt lõi của một LLM là dự đoán từ tiếp theo (next-token prediction). Nhận đầu vào "Con mèo ngồi trên...", mô hình tính xác suất cho hàng nghìn token rồi chọn từ khả năng cao nhất — chẳng hạn "thảm".
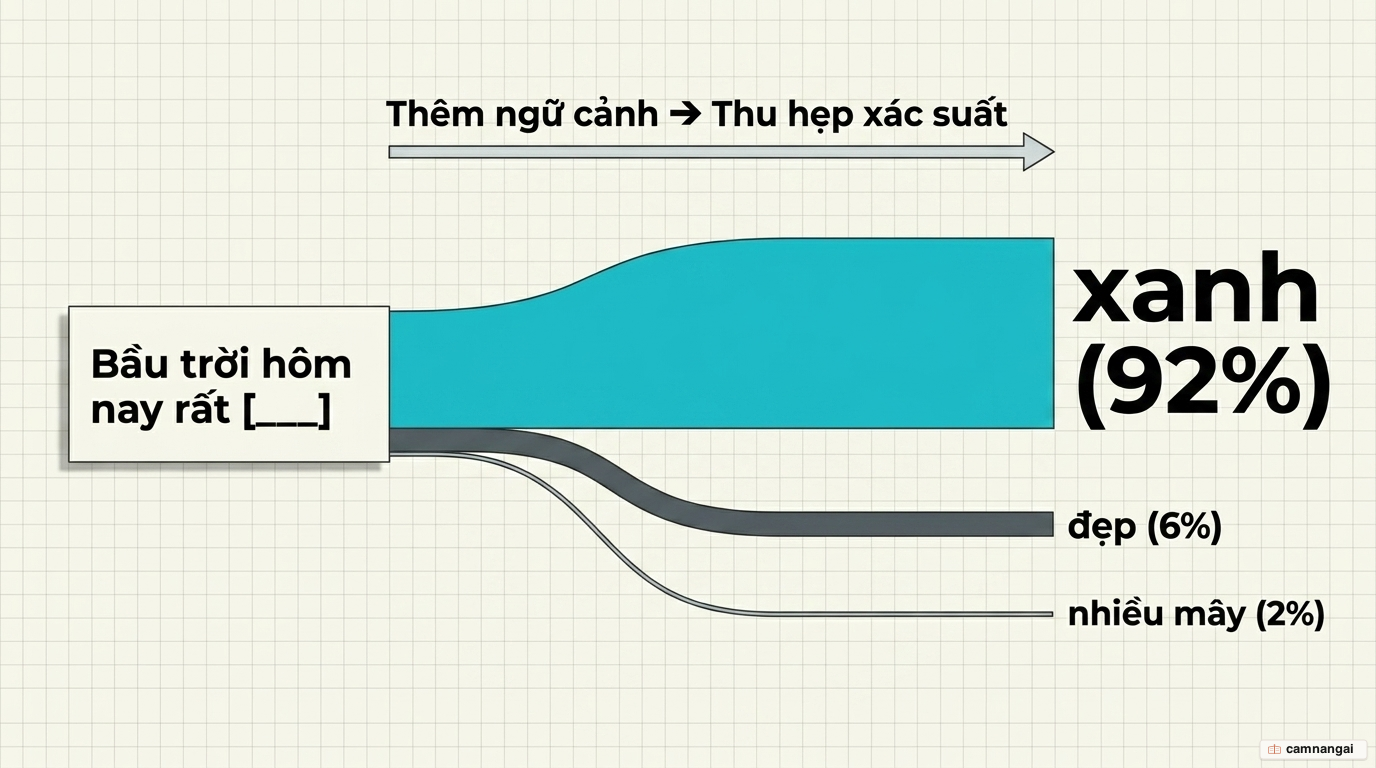
Sức mạnh thật sự nằm ở lớp chồng ngữ cảnh. Với "I love to eat...", khả năng gần như vô hạn. Thêm "...for breakfast", xác suất dồn về "eggs". Thêm tiếp "...with chopsticks in Tokyo", "ramen" hay "natto" vọt lên dẫn đầu. Càng nhiều ngữ cảnh, mô hình càng thu hẹp được vùng xác suất — đó là lý do một câu lệnh dài và cụ thể thường cho kết quả sát ý hơn. Chính khả năng khớp mẫu ở quy mô siêu lớn này tạo ra "ảo giác" về trí tuệ, dù mô hình không hề suy luận logic như con người.
Quy trình huấn luyện một mô hình ngôn ngữ lớn gồm những giai đoạn nào?
Để biến một bộ dự đoán thống kê thô thành trợ lý như ChatGPT, hệ thống phải đi qua ba bước:
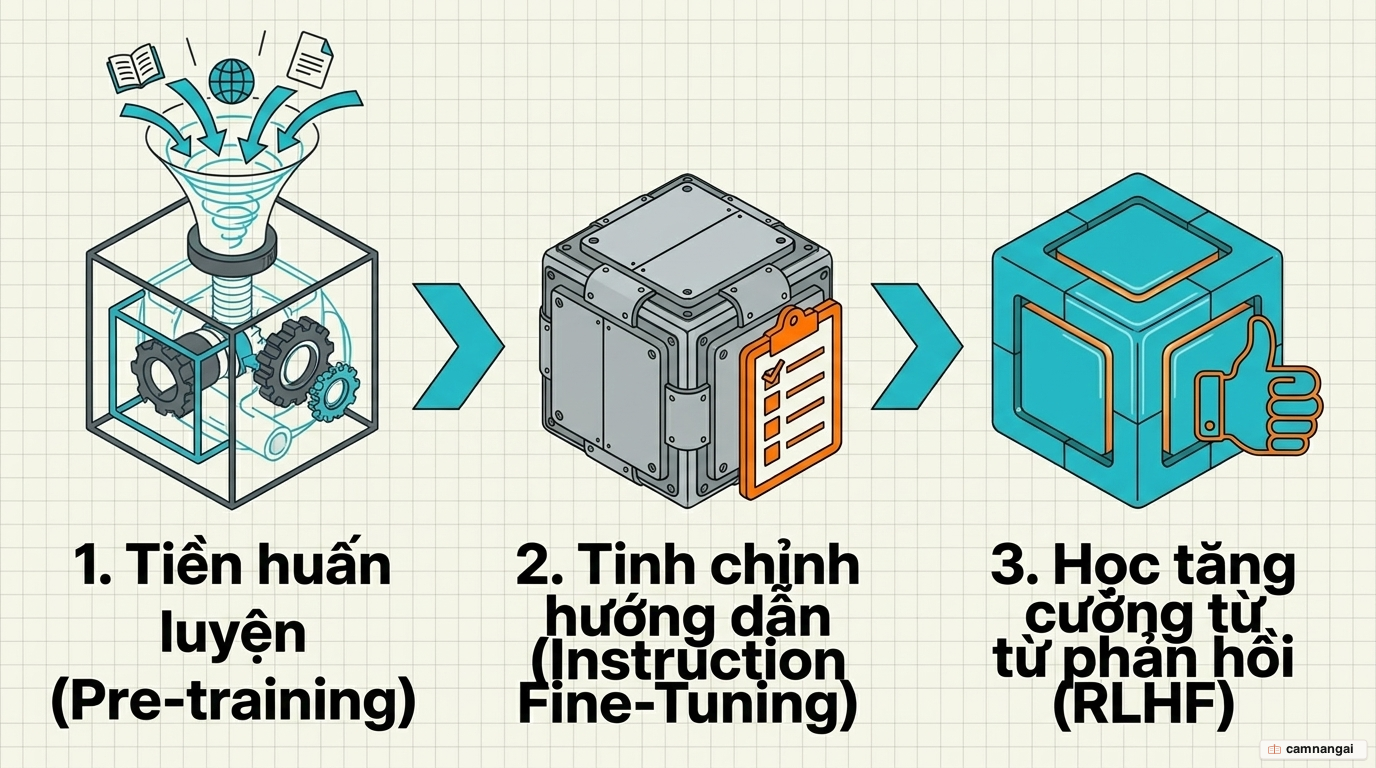
- Tiền huấn luyện (pre-training). Mô hình tự học từ vựng, ngữ pháp và kiến thức thế giới qua phương pháp tự giám sát (self-supervised learning). Ở giai đoạn này, nó mới chỉ là công cụ hoàn thiện văn bản chưa căn chỉnh — có thể nói lan man hoặc hỏi ngược lại thay vì trả lời.
- Tinh chỉnh hướng dẫn (instruction fine-tuning). Mô hình được dạy trên các cặp "câu hỏi — phản hồi" chất lượng cao để học cách hành xử như một trợ lý biết tuân lệnh. Nó hiểu rằng "Tên bạn là gì?" cần một câu trả lời, chứ không phải một câu hỏi ngược.
- Học tăng cường từ phản hồi con người (RLHF). Con người trực tiếp chấm điểm các câu trả lời theo mức độ hữu ích. Thông qua mô hình phần thưởng (reward modeling), LLM được căn chỉnh để phản hồi an toàn, hữu ích và hợp với giá trị con người.
Kiến trúc Transformer và GPU đóng vai trò gì?
Làn sóng LLM hiện nay là cuộc hôn phối giữa một đột phá kiến trúc và một bước nhảy phần cứng.
- Kiến trúc Transformer. Các mạng cũ như RNN phải đọc văn bản tuần tự, từng từ một — một nút thắt cổ chai về tốc độ. Transformer gỡ bỏ ràng buộc đó, xử lý song song cả khối văn bản cùng lúc.
- Cơ chế chú ý (attention). Đây là trái tim của Transformer: nó cân trọng số mức độ liên quan giữa các từ, bất kể chúng cách xa nhau ra sao. Nhờ vậy mô hình phân biệt được "bow" là "cúi chào" trong câu "the singer took a bow" hay "cây cung" trong "a bow for target practice", chỉ dựa vào các từ xung quanh.
- GPU (bộ xử lý đồ họa). Vốn sinh ra để dựng hình điểm ảnh, GPU lại cực giỏi những phép tính ma trận song song mà Transformer cần. Nó rút thời gian huấn luyện từ hàng thập kỷ xuống còn vài tuần.
Mô hình ngôn ngữ lớn làm được những công việc gì?
Nhờ khả năng xử lý ngôn ngữ, LLM đang được áp dụng khắp các ngành:
- Sáng tạo và lập trình. Soạn thảo, tóm tắt văn bản và hỗ trợ viết mã nguồn — lập trình viên dùng các nền tảng như Replicate để tích hợp các mô hình như Llama 3 vào việc sinh và gỡ lỗi code.
- Dịch vụ khách hàng. Chatbot thông minh và trợ lý ảo phản hồi theo thời gian thực.
- Y tế và nghiên cứu. Tóm tắt hồ sơ bệnh án, rà soát hàng nghìn bài báo khoa học để tìm xu hướng, và hỗ trợ chẩn đoán dựa trên dữ liệu.
- Giáo dục. Cá nhân hóa lộ trình học tập và giải đáp kiến thức đa lĩnh vực.
Vì sao mô hình ngôn ngữ lớn vẫn thường xuyên mắc lỗi?
Một người dùng tỉnh táo phải nhìn thẳng vào các giới hạn nội tại của LLM. Mấu chốt: khớp mẫu không phải là suy luận.
- Ảo giác (hallucination). Mô hình được tối ưu để tạo ra văn bản có xác suất cao nhất, không phải đúng sự thật nhất. Nó không có bộ lọc sự thật, nên có thể bịa số liệu hay trích dẫn không tồn tại bằng một giọng điệu rất tự tin — đơn giản vì nó học theo giọng tự tin của dữ liệu huấn luyện.
- Khớp mẫu, không suy luận. Mô hình thường thất bại ở các câu đố logic nếu điều kiện bị đổi khác đôi chút so với bản gốc trong dữ liệu. Với bài toán "qua sông" kinh điển (chở sói, dê và bắp cải sang sông bằng chiếc thuyền chỉ chở được một thứ mỗi lượt, sao cho không con nào ăn mất con/thứ kia), chỉ cần sửa luật chơi là mô hình vẫn trả lời theo đáp án quen thuộc — vì nó đang khớp mẫu của câu đố nổi tiếng chứ không lập luận trên ràng buộc mới.
- Định kiến (bias). Mô hình hấp thụ luôn cả những thiên kiến lệch lạc có sẵn trong dữ liệu Internet.
- Chi phí và hộp đen. Huấn luyện ngốn năng lượng và hạ tầng GPU đắt đỏ; và rất khó giải thích vì sao một mạng hàng tỷ tham số lại đưa ra một quyết định cụ thể.
Làm sao để dùng mô hình ngôn ngữ lớn hiệu quả và chính xác hơn?
Kỹ thuật ra lệnh (prompt engineering) là cách kiểm soát đầu ra mà không cần huấn luyện lại mô hình.
- Học không mẫu và học ít mẫu (zero-shot & few-shot). LLM có thể làm một tác vụ mới mà không cần huấn luyện lại; đưa thêm vài ví dụ mẫu sẽ giúp nó bắt chước đúng định dạng bạn muốn.
- Chuỗi tư duy (chain-of-thought). Yêu cầu mô hình "suy nghĩ từng bước" buộc nó tự sinh ra các bước trung gian làm bộ nhớ tạm, nhờ đó giải được những bài toán nhiều tầng — kiểu "ai vô địch World Cup năm trước khi Messi ra đời".
- Tiếp đất bằng ngữ cảnh (grounding). Đưa thẳng tài liệu cụ thể vào câu lệnh và buộc mô hình chỉ trả lời dựa trên đó. Kỹ thuật này — thường triển khai dưới dạng RAG (Retrieval-Augmented Generation) — là cách hiệu quả nhất để vượt qua "điểm dừng kiến thức" và giảm ảo giác.
Bạn nên bắt đầu từ đâu?
LLM chỉ là một mắt xích trong chuỗi khái niệm nền tảng. Vài bài viết liên quan giúp bạn bóc tách từng lớp:
- Trí tuệ nhân tạo là gì? — lớp bao quát chứa mọi thứ bên dưới.
- Học máy là gì? — phương pháp giúp máy học từ dữ liệu thay vì lập trình cứng.
- Học sâu là gì? — mạng nơ-ron nhiều lớp, động cơ đằng sau LLM.
- AI tạo sinh là gì? — lớp chuyên tạo ra nội dung mới.
- Token AI là gì? — đơn vị mà mọi mô hình ngôn ngữ đọc và viết.
- Xử lý ngôn ngữ tự nhiên là gì? — ngành học đứng sau việc máy hiểu tiếng người.
Điểm chính
- Mô hình ngôn ngữ lớn (LLM) là mô hình toán học dự đoán từ tiếp theo dựa trên xác suất thống kê, học từ kho dữ liệu quy mô lớn.
- Quy trình huấn luyện chuẩn gồm ba giai đoạn: tiền huấn luyện, tinh chỉnh hướng dẫn và học tăng cường từ phản hồi con người (RLHF).
- LLM vận hành bằng cơ chế khớp mẫu (pattern matching), không thực hiện tư duy logic thực sự như con người.
- Giới hạn lớn nhất là ảo giác — mô hình đưa ra thông tin sai lệch bằng một giọng điệu rất tự tin.
Tài liệu tham khảo
- A Beginner's Guide to Large Language Models — freeCodeCamp
- How Large Language Models Work — Data Science at Microsoft
- Large Language Models: A Short Introduction
- How Large Language Models Learn — ByteByteGo
Bài viết được đăng lần đầu trên camnangai.com.
All rights reserved
