
Machine Translate với Attention trong Deep Learning
Bài đăng này đã không được cập nhật trong 6 năm
1. Giới thiệu
Bài toán dịch ngôn ngữ là 1 bài toán khá hay, Hôm nay, mình sẽ hướng dẫn chi tiết và code lại thuật toán Attention trong lĩnh vực Deep learning cho dạng bài toán Seq2Seq (Sequence to sequence). Trong bài hướng dẫn này mình sẽ code một Machine Translation có chức năng dịch ngôn ngữ Anh -> Việt.
Với mục đích hiểu sâu hơn về thuật toán, sản phẩm được code trên Tensorflow 2.0 thay vì Keras (code với Keras đơn giản hơn rất nhiều nhưng khó hiểu sâu). Code:
Kiến thức nền tảng:
- Python, tensorflow
- Deep learning (cơ bản), RNN
2. Encode-Decode
Trước đây, bài toán Seq2Seq được giải quyết chủ yếu bằng các mô hình Deep learning. Tuy chất lượng không so được với con người nhưng các Deep learning vẫn cho chất lượng hơn hẳn các thuật toán truyền thống. Dạng mô hình được sử dụng phổ biến (trước đây) trong bài toán này có dạng encoder-decoder như hình minh họa dưới đây:
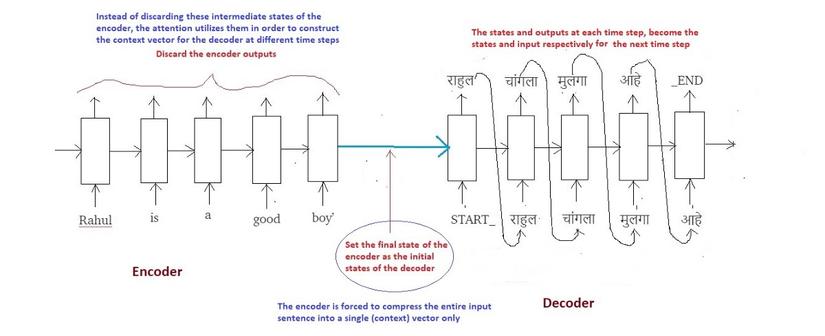
Mô hình gồm 2 phần encode và decode. Giả sử dịch câu A tiếng Anh thành câu A' tiếng Việt. Encoder đọc và mã hóa (encode) thông tin câu A thành 1 context vector. Thông thường context vector này chính là state cuối cùng của encode. Về mặt ý nghĩa, context vector cần đảm bảo chứa đủ các thông tin ngữ cảnh (chủ ngữ, vị ngữ, tính từ, trạng thái, tính chất) chuỗi A. Decoder nhận context vector làm input, giải mã (decode) thành chuỗi A'.
Có thể dễ dàng thấy mô hình encode-decode có nhược điểm: input của decoder chỉ là 1 vector duy nhất, điều đó có nghĩa rằng kết quả decode phụ thuộc quá nhiều vào 1 context vector.Đặc biệt khi input là chuỗi dài, thông tin có thể mất mát trong quá trình lan truyền, context vector không còn chứa đủ thông tin cần thiết để decode. Attention ra đời nhằm khắc phục nhược điểm đó.
3. Attention
Ý tưởng của Attention: thay vì chỉ sử dụng 1 context vector duy nhất (last state), decoder có thể đọc thông tin từ tất cả state trong encode cho mỗi lần predict. Hãy quan sát 2 câu sau:
This is a bookĐó là một quyển sách
Có thể thấy sự tương ứng giữa các từ ngữ giữa 2 câu: "this"-"đó" , "book"-"quyển sách". Như vậy việc dịch ra "quyển sách" sẽ phụ thuộc vào "book" hơn là "this", "is" hay "a".
Ý tưởng cốt lõi của Attention:
- Thay vì sử dụng 1 context vector duy nhất (last state) khi dịch tất cả các từ, ta sử dụng mỗi context vector riêng biệt khi predict ra từng từ.
- Mỗi context vector được tổng hợp có trọng số từ tất cả các state trong encode.
Chi tiết thuật toán
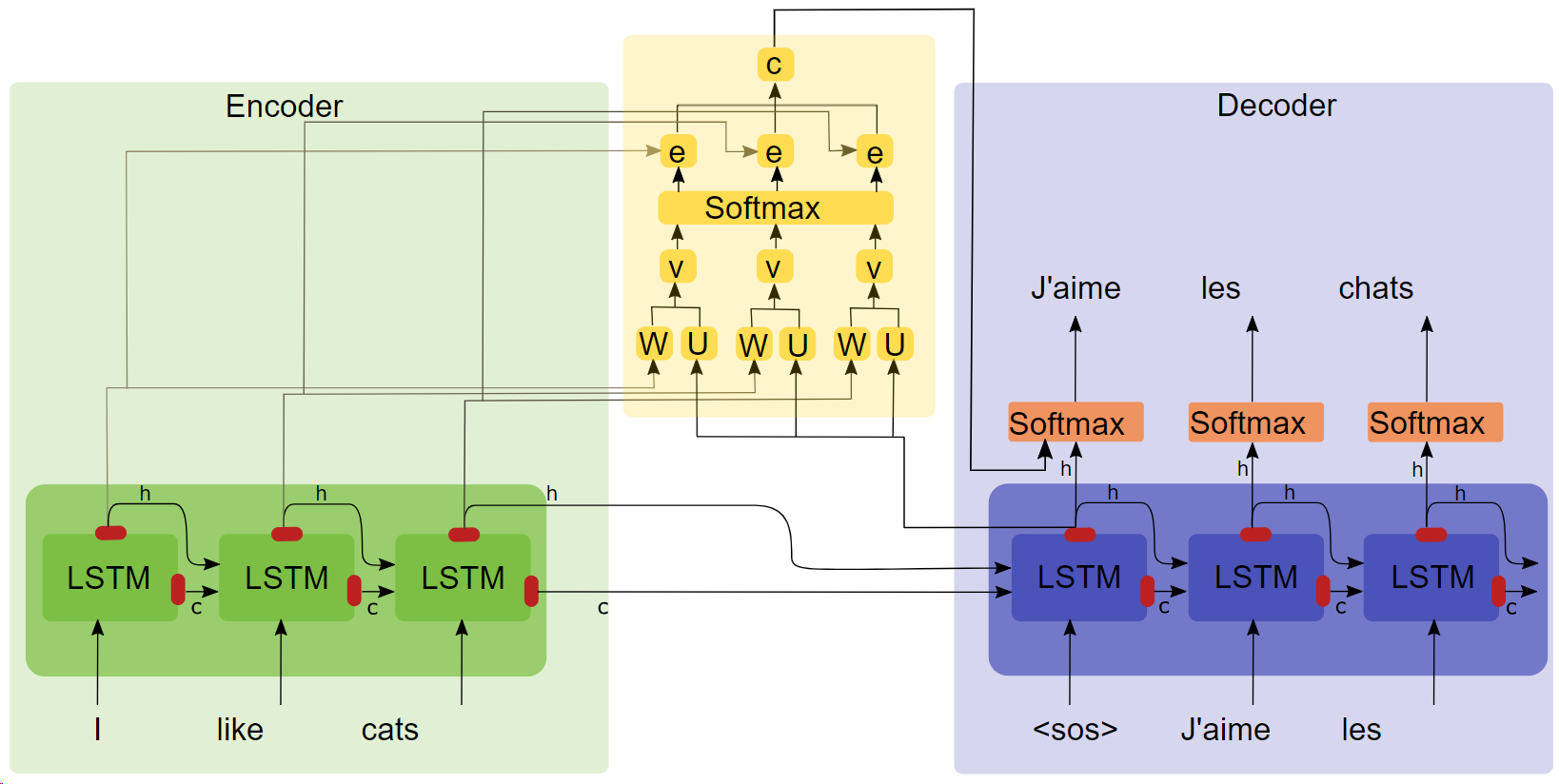
3.1 Encode
Encode 1 câu độ dài bằng LSTM hoặc GRU, ta thu được encode_states: H =
3.2 Decode
Tại decode, để predict ra , ta cần tính context_vector tương ứng. Attention dùng khái niệm query, key, value:
- , . Thông thường, = = (là encode_states)
- = , với m là độ dài chuỗi được sinh ra. Đặc biệt , còn là các decode_states
- Context vector () là tổng hợp có trọng số các phần tử thuộc values. Trong công thức dưới đây, = là hàm tính trọng số. Mình sẽ nói chi tiết ở phần 3.
.
Kết hợp với từ liền trước (tại step 1, = "<START>"), thu được concat_vector_j = + .
Đưa concat_vector vào GRU/LSTM, thu được output = "Rahul" và . Quá trình được lặp lại tương tự cho từng lần predict các từ kế tiếp (cho đến khi sinh ra kí tự <END>).
3.3 Tính trọng số
Trở lại bước tính trong số
- Tại step thứ j, ta cần tính . Trong đó =
- Trong đó Dense() là chính là fullly-connect layer, Tanh là activate function (theo cách viết của Keras và Tf ).
- Trọng số = Softmax() . Nhìn hình minh hoạ bên trên và code để dễ hiểu hơn.
4. Code
Github: trungthanhnguyen0502/pet-translate
Dataset: gồm 2 file train.en.txt và train.vi.txt gồm 100.000 câu song ngữ Anh-Việt. Lấy dataset trong github mình luôn nhé.
Import thư viện, tiền xử lí dữ liệu
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import random
import os
import io
import string
import re
from sklearn.model_selection import train_test_split
# dùng eager mode trong tensor
tf.enable_eager_execution()
def preprocess(sentence):
sent = sentence.lower()
sent = sent.strip()
sent = re.sub("'", " ", sent)
sent = re.sub("\s+", " ", sent)
sent = ''.join([char for char in sent if char not in exclude])
sent = "<start> " + sent + " <end>"
return sent
# load data
en_filename = "./dataset/train.en.txt"
vi_filename = "./dataset/train.vi.txt"
raw_en_lines = open(en_filename, encoding='utf-8').read().strip().split("\n")
raw_vi_lines = open(vi_filename, encoding='utf-8').read().strip().split("\n")
exclude = list(string.punctuation) + list(string.digits)
en_lines = []
vi_lines = []
min_len, max_len = 10, 14
# với mục đích demo, mình sẽ không xử lí những câu quá dài,
# loại bỏ những câu có độ dài không nằm trong khoảng (min_len, max_len)
for eline, vline in zip(raw_en_lines, raw_vi_lines):
eline = preprocess(eline)
vline = preprocess(vline)
if min_len < len(eline.split(" ")) < max_len
and min_len < len(vline.split(" ")) < max_len:
en_lines.append(eline)
vi_lines.append(vline)
Xử lí ngôn ngữ với class Language
class Language():
def __init__(self, lines):
self.lines = lines
self.word2id = {}
self.id2word = {}
self.vocab = set()
self.max_len = 0
self.min_len = 0
self.vocab_size = 0
self.init_language_params()
def init_language_params(self):
self.word2id['<pad>'] = 0
for line in self.lines:
self.vocab.update(line.split(" "))
for id, word in enumerate(self.vocab):
self.word2id[word] = id + 1
for word, id in self.word2id.items():
self.id2word[id] = word
self.max_len = max([len(line.split(" ")) for line in self.lines])
self.min_len = min([len(line.split(" ")) for line in self.lines])
self.vocab_size = len(self.vocab) + 1
def sentence_to_vector(self, sent):
return np.array([self.word2id[word] for word in sent.split(" ")])
def vector_to_sentence(self, vector):
return " ".join([self.id2word[id] for id in vector])
Tạo dữ liệu cho train, validate
inp_lang = Language(en_lines)
tar_lang = Language(vi_lines)
inp_vector = [inp_lang.sentence_to_vector(line) for line in inp_lang.lines]
tar_vector = [tar_lang.sentence_to_vector(line) for line in tar_lang.lines]
# add padding vào câu để tất cả các câu có độ dài bằng nhau
inp_tensor = tf.keras.preprocessing.sequence.pad_sequences(inp_vector, inp_lang.max_len, padding='post')
tar_tensor = tf.keras.preprocessing.sequence.pad_sequences(tar_vector, tar_lang.max_len, padding='post')
x_train, x_val, y_train, y_val = train_test_split(inp_tensor, tar_tensor, test_size=0.1)
BATCH_SIZE = 32
BUFFER_SIZE = x_train.shape[0]
N_BATCH = BUFFER_SIZE//BATCH_SIZE
hidden_unit = 1024
embedding_size = 256
dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
dataset = dataset.batch(BATCH_SIZE)
Okie, xong mấy phần linh tinh rồi, giờ là tới bước chính: xây dựng model
Encode
class Encode(tf.keras.Model):
def __init__(self, embedding_size, vocab_size, hidden_units):
super(Encode, self).__init__()
self.Embedding = tf.keras.layers.Embedding(vocab_size,embedding_size)
self.GRU = tf.keras.layers.GRU(
hidden_units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
self.hidden_units = hidden_units
def call(self, x, hidden_state):
x = self.Embedding(x)
outputs, last_state = self.GRU(x, hidden_state)
return outputs, last_state
def init_hidden_state(self, batch_size):
return tf.zeros([batch_size, self.hidden_units])
Attention
class Attention(tf.keras.Model):
def __init__(self, hidden_units):
super(Attention, self).__init__()
self.W_out_encode = tf.keras.layers.Dense(hidden_unit)
self.W_state = tf.keras.layers.Dense(hidden_unit)
self.V = tf.keras.layers.Dense(1)
def call(self, encode_outs, pre_state):
pre_state = tf.expand_dims(pre_state, axis=1)
pre_state = self.W_state(pre_state)
encode_outs = self.W_out_encode(encode_outs)
score = self.V(
tf.nn.tanh(
pre_state + encode_outs)
)
score = tf.nn.softmax(score, axis=1)
context_vector = score*encode_outs
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector, score
Decode
class Decode(tf.keras.Model):
def __init__(self, vocab_size, embedding_size, hidden_units):
super(Decode, self).__init__()
self.hidden_units = hidden_units
self.Embedding = tf.keras.layers.Embedding(vocab_size,embedding_size)
self.Attention = Attention(hidden_units)
self.GRU = tf.keras.layers.GRU(
hidden_units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform'
)
self.Fc = tf.keras.layers.Dense(vocab_size)
def call(self, x, encode_outs, pre_state):
x = tf.expand_dims(x, axis=1)
x = self.Embedding(x)
context_vector, attention_weight = self.Attention(encode_outs, pre_state)
context_vector = tf.expand_dims(context_vector, axis=1)
gru_inp = tf.concat([x, context_vector], axis=-1)
out_gru, state = self.GRU(gru_inp)
out_gru = tf.reshape(out_gru, (-1, out_gru.shape[2]))
return self.Fc(out_gru), state
Loss function
def loss_function(real, pred):
mask = 1 - np.equal(real, 0)
loss_ = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=real, logits=pred) * mask
return tf.reduce_mean(loss_)
Tiến hành train model nào 
EPOCHS = 20
optimizer = tf.train.AdamOptimizer()
encoder = Encode(embedding_size, vocab_size=inp_lang.vocab_size, hidden_units=hidden_unit)
decoder = Decode(vocab_size=tar_lang.vocab_size, embedding_size=embedding_size, hidden_units=hidden_unit)
for epoch in range(EPOCHS):
total_loss = 0
for batch_id, (x, y) in enumerate(dataset.take(N_BATCH)):
loss = 0
with tf.GradientTape() as tape:
first_state = encoder.init_hidden_state(batch_size=BATCH_SIZE)
encode_outs, last_state = encoder(x, first_state)
decode_state = last_state
decode_input = [tar_lang.word2id["<start>"]]*BATCH_SIZE
for i in range(1, y.shape[1]):
decode_out, decode_state = decoder(
decode_input, encode_outs, decode_state
)
loss += loss_function(y[:, i], decode_out)
decode_input = y[:, i]
train_vars = encoder.trainable_variables
+ decoder.trainable_variables
grads = tape.gradient(loss, train_vars)
optimizer.apply_gradients(zip(grads, train_vars))
total_loss += loss
print(total_loss.numpy())
Với mục đích demo, mình chỉ train khoảng 20 epochs thôi, dĩ nhiên là với 20 epochs này chất lượng không cao, vậy nên mình sẽ test trên chính tập train. Việc test trên tập train nghe qua có vẻ buồn cười  , tuy nhiên đó là 1 mẹo để kiểm tra thuật toán và model có hoạt động hiệu quả hay không. Với 1 tập dữ liệu nhỏ, sau vài Epoch mà khi test trên tập train, model trả về kết quả không đúng thì có nghĩa bạn đã code sai chỗ nào đó rồi.
, tuy nhiên đó là 1 mẹo để kiểm tra thuật toán và model có hoạt động hiệu quả hay không. Với 1 tập dữ liệu nhỏ, sau vài Epoch mà khi test trên tập train, model trả về kết quả không đúng thì có nghĩa bạn đã code sai chỗ nào đó rồi.
Test model
def translate(inputs):
result = ''
hidden = encoder.init_hidden_state(batch_size=1)
enc_out, enc_hidden = encoder(inputs, hidden)
dec_hidden = enc_hidden
dec_input = [tar_lang.word2id['<start>']]
for t in range(tar_lang.max_len):
predictions, dec_hidden = decoder(dec_input, enc_out, dec_hidden)
predicted_id = tf.argmax(predictions[0]).numpy()
result += tar_lang.id2word[predicted_id] + ' '
dec_input = [predicted_id]
return result
for inp, tar in dataset.take(N_BATCH):
print(translate(inp[1:2,:]))
break
Kết qủa trả về 

Nhìn kết quả thế này có nghĩa là mình đã code đúng, muốn chính xác hơn chỉ cần thêm dữ liệu và thời gian train.
All rights reserved
