
Làm chủ Stacking Ensemble Learning
Bài đăng này đã không được cập nhật trong 4 năm
Chào mọi người, trong quá trình viết về AdaBoost của, mình có tìm được 2 bài về Ensemble Learning Ensemble learning và các biến thể (P1) và Gradient Boosting - Tất tần tật về thuật toán mạnh mẽ nhất trong Machine Learning của các anh. Hai bài đã giải thích rất rõ để mọi người hiểu thế nào là mô hình học yếu, cách để kết hợp chúng lại với nhau thông qua Bagging và Boosting, nhưng chưa có bài viết nào làm rõ chi tiết về Stacking. Mình thấy không viết tiếp một bài về Stacking thì bất công quá!(sad) Vậy nên trong bài viết này mình giới thiệu đến mọi người thuật toán tiếp theo trong series '''Ensemble learning và các biến thể ''' - Stacking.
Let's go!
I. Tổng quan về Stacking
Stacking hay tên đầy đủ là Stacked Generalization là một thuật toán học máy thuộc Ensemble Learning. Tương tự như Bagging và Boosting, Stacking cũng kết hợp các dự đoán từ nhiều mô hình học máy trên cùng một tập dữ liệu.
Như chúng ta đã biết, việc kết hợp thật nhiều mô hình giống nhau giúp cải thiện kết quả dự đoán. Nhưng với nhiều mô hình học máy, mỗi mô hình có những điểm lợi và hại, và có những cách riêng để đưa ra dự đoán, vậy làm sao để có thể chọn ra mô hình nào tốt nhất, hay làm sao để có thể kết hợp các đặc tính tốt của các mô hình lại với nhau? Câu trả lời là Stacking. Stacking mang đến góc nhìn mới về cách kết hợp các mô hình học máy lại với nhau.
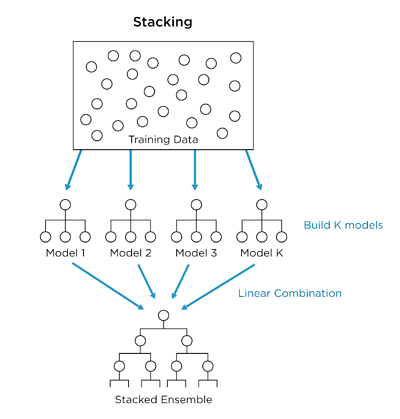
- Khác với Bagging, Stacking sử dụng nhiều mô hình học máy khác nhau (ko chỉ là Decision Tree) và học trên cùng một tập dữ liệu (thay vì các samples của tập huấn luyện )
- Khác với Boosting, sử dụng chuỗi mô hình để tự sửa chữa những sai lầm của mô hình trước, Stacking sử dụng duy nhất một mô hình để đưa ra dự đoán tốt nhất từ các dự đoán của các mô hình khác
Mô hình Stacking cơ bản thường được phân thành 2 cấp là level-0 modes và level-1 model:
- Level-0 Models (Base-Models): Mô hình cơ sở học trực tiếp từ bộ dữ liệu và đưa ra dự đoán cho mô hình level-1
- Level-1 Model (Meta-Model): Mô hình học từ các dự đoán của mô hình cơ sở (level-0)
Có nghĩa Meta-model được huấn luyện dựa trên đầu ra dự đoán của các base-modes, các outputs này kết hợp với nhãn của bài toán tạo thành cặp dữ liệu đầu vào - đầu ra trong quá trình huấn luyện Meta-model. Có thể thấy Meta-model không học trực tiếp từ tập dữ liệu huấn luyện, tuy nhiên, việc dùng dữ liệu bàn đầu thêm vào outputs của base-models vẫn hoàn toàn hợp lý, sẽ cấp thêm cho meta-model nhiều thông tin hơn về dữ liệu.
Các base-models có những cách học khác nhau trên bộ dữ liệu, cho nên outputs hay errors của các base-models là không tương quan (uncorrelated) hay có độ tương quan thấp (low correlation).
Đầu ra của base-models có thể là giá trị thực (cho bài toán Hồi quy) hoặc là các xác suất của nhãn trong bài toán phân loại.
Base-models thường phức tạp và đa dạng, mỗi mô hình có cách học và giải quyết vấn đề khác nhau với cùng một bài toán như: Decision Tree, SVM, Neural Network,... và kể cả là các thuật toán ensemble khác như GBM, Random Forest,...
Trái ngược với đó, Meta-model thường đơn giản hơn, dự đoán kết quả từ các kết quả dự đoán của base-models ( ), và thường là:
), và thường là:
- Linear Regression cho bài toán Regression -> Trả về số thực
- Logistic Regression cho bài toán Classification -> Trả về xác suất các label
Hmmm, tổng kết lại: Giả sử sắp tới bạn phải ôn thi, mà bạn lại có vài đứa bạn, đứa nào cũng giỏi nhưng ai cũng có môn lại giỏi hơn những người khác . Mà bạn lại lười phải học từ đầu, nên bạn tĩnh tâm đợi bạn bè học xong, rồi nhờ bạn bè dạy lại (lmao), bạn sẽ học được nhiều nhất từ mọi người (vì ai cũng học rồi, đều học được những điều hay, kiến thức đã được chắt lọc), (maybe) bạn giỏi toàn diện và điểm sẽ cao hơn (sure kèo) =))
Ví dụ trên có vẻ hơi ảo nhưng đấy cũng là cách về cơ bản Stacking hoạt động, bây giờ mình sẽ đi vào chi tiết hơn về thuật toán.
II. Stacking Algorithm
Pseudo code của Stacking được đưa ra lần đầu (mình không chắc lắm) bởi David H trong "Stacked generalization" năm 1992 (wow) và cũng là mô hình cơ bản nhất của Stacking.

Được chia thành 3 bước chính:
- Bước thứ 1: Sử dụng các base-models để học trên toàn bộ dữ liệu và đưa ra kết quả dự đoán ban đầu
- Bước thứ 2: Xây dựng bộ dữ liệu mới dựa trên outputs của các base-models
- Bước thứ 3: Huấn luyện Meta-model với bộ dữ liệu mới và đưa ra kết quả cuối cùng
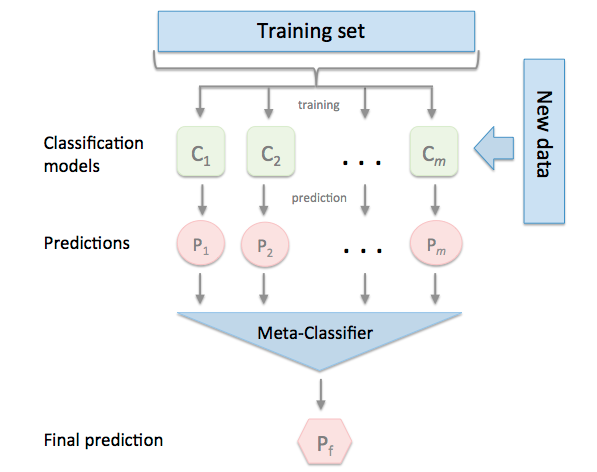
Ý tưởng mô hình là rất tốt nhưng nó lại tồn tại 1 vấn đề khá nghiêm trọng. Đó là rất dễ bị overfitting. Tại sao?
Việc học từ kết quả của các mô hình trước dẫn đến việc, nếu giả sử là Depth Decision Tree, và kết quả của bị overfitting trên bộ dữ liệu, (và chỉ một) bị overffiting, thì Meta-model sẽ bị phụ thuộc khá nhiều vào kết quả của dẫn đến việc toàn bộ cấu trúc bị overfitting theo. Và đó cũng là lý do khiến mô hình Stacking cơ bản này dễ bị overfitting.
Để giải quyết vấn đề này, có rất nhiều phương pháp được đưa ra, về cơ bản, mặc dù có thể không hoàn toàn tránh được overfitting nhưng ít nhất cũng làm giảm đc hiện tượng đó, các phương pháp đó là
2.1 Stacking với Cross-Validation
Nhắc lại 1 chút về hold-out và cross-validation
Về phương pháp hold-out
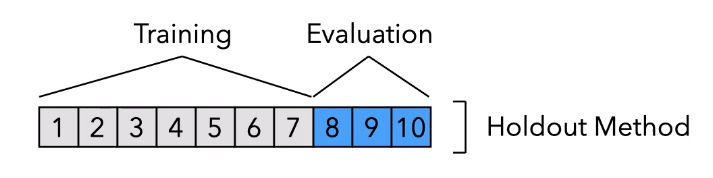
Sẽ chia bộ dữ liệu ra làm 2 phần là training và validation (testing) một cách ngẫu nhiên, khi đó từ một bộ dữ liệu, ta đã có 2 bộ có thể dùng để kiểm thử hiệu năng mô hình của mình. Tuy nhiên khi số lượng dữ liệu để xây dựng mô hình là rất hạn chế, việc lấy nhiều dữ liệu làm validation sẽ dẫn đến việc số lượng dữ liệu còn lại trong training set là không đủ để xây dựng mô hình. Lúc này, số lượng dữ liệu trong validation set phải đủ nhỏ để dữ liệu còn lại đủ lớn để training, nhưng khi đó lại có 1 vấn đề khác xảy ra, là hiện tượng overfitting rất dễ xảy ra. Để giải quyết vấn đề này k-fold cross-validation
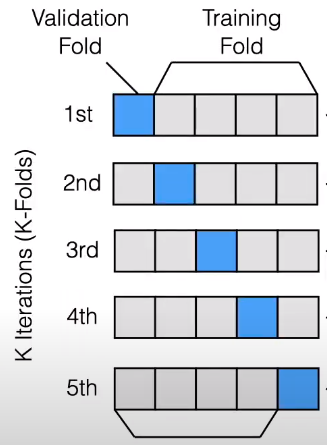
cũng chia bộ dữ liệu ra thành 2 phần chính training và validation, tuy nhiên là một tập các validation set khác nhau được xây dựng từ bộ dataset ban đầu. k-fold nghĩa là bộ dữ liệu sẽ được chia ra làm k phần bằng nhau từ bộ dữ liệu, và mô hình sẽ được huấn luyện k-lần, mỗi lần huấn luyện đc gọi là 1 run. Trong mỗi run, (k-1) phần sẽ được dùng để xây dựng mô hình huấn luyện và phần còn lại sẽ được dùng làm validation set. Kết quả cuối cùng là trung bình các kết quả thu được. Để hiểu rõ hơn về các chiến lược đánh giá này, các bạn có thể xem 2 bài giảng rất hay của thầy Khoát trường Đại học Bách Khoa Hà Nội: Đánh giá hiệu quả của một mô hình học máy (p1) và Đánh giá hiệu quả của một mô hình học máy (p2)
Áp dụng k-fold cross-validation với Stacking ta thu được mô hình

Để dễ hiểu hơn mình xin phép được trích dẫn ví dụ từ bài viết Advanced Ensemble Learning technique – Stacking and its Variants để giải thích pseudo code trên
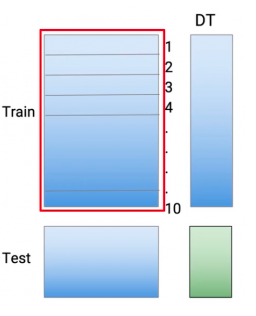
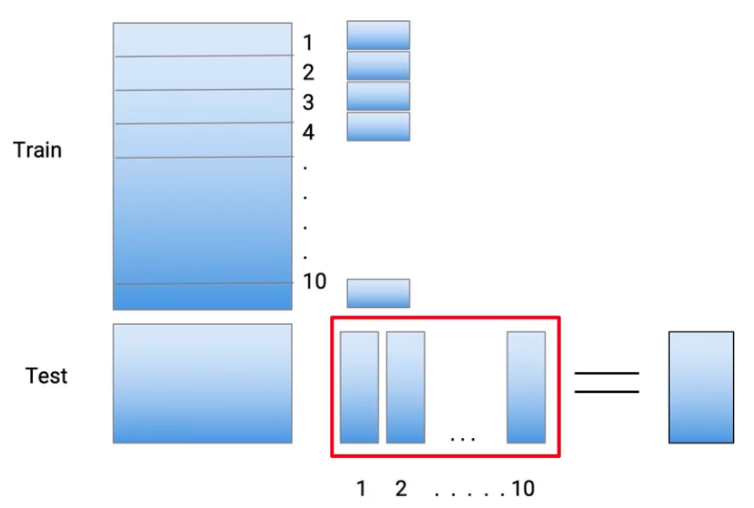
Giả sử ban đầu chúng ta có tập train set và test set như sau
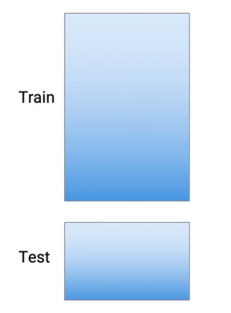
Đây là input của thuật toán.
Áp dụng k-fold, ta chia train set thành 10 phần
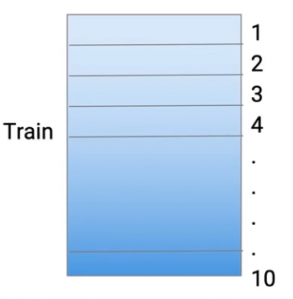
Tại đây, 9 phần sẽ được sử dụng để huấn luyện base-models và predicted trên phần còn lại, ở đây, base-model đầu tiên được sử dụng là Decision Tree. Đầu tiên từ phần 2-10 sẽ được huấn luyện với Decision Tree và predicted trên phần thứ 1
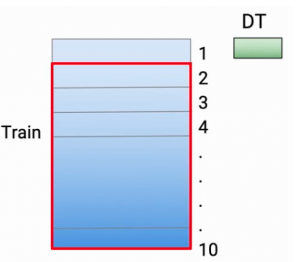
Tiếp theo phần 1,3-10 được huấn luyện với Decision Tree và predicted trên phần thứ 2
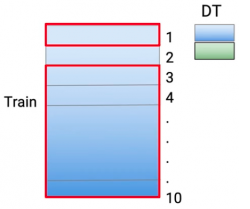
Tiếp tục như vậy cho đến phần thứ 10, ta sẽ thu được toàn bộ predicted của Decision Tree trên train set. Sau đấy, huấn luyện Decision Tree trên toàn bộ train set và predict trên test set
Lặp lại tương tự với các base-models khác, ta thu được
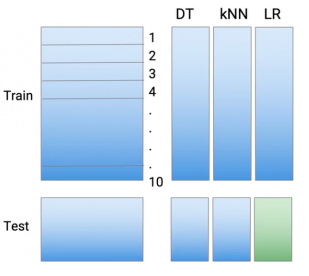
Như vậy sau quá trình trên, ta thu được bộ train set và test set mới. Ta sử dụng kết quả trên để training Meta-model
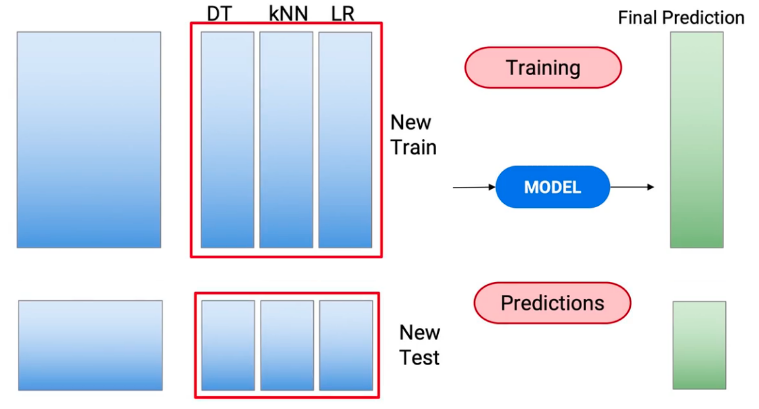
Ta sẽ huấn luyện meta-model với train set mới, và predict trên bộ test set mới
Ví dụ trên có chút thay đổi thứ tự với pseudo code, nhưng bản chất vẫn vậy. Và kết quả ta cần là predicted của meta-models trên tập test set mới
Tóm tắt đơn giản thuật toán lại, ta được mô hình sau
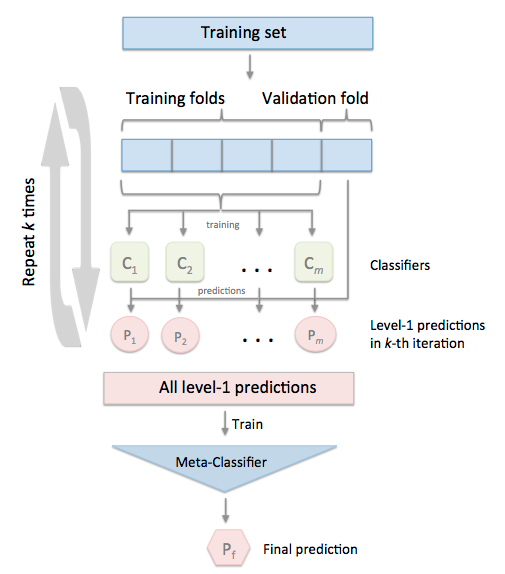
Như trên ví dụ có thể thấy, với phương pháp này thì meta-model hoàn toàn không sử dụng đến các features trong bô dữ liệu ban đầu, mà chỉ huấn luyện dựa trên các label được tạo ra từ các base-models. Tuy nhiên đây là cách hầu hết sử dụng với Stacking, mang lại hiệu quả ổn định nhất. Tiếp theo mình sẽ giới thiệu một số biến thể khác của Stacking
2.2 Sử dụng training set ban đầu kèm với các labels được tạo ra
Như đã đề cập ở trên, mô hình Stacking chỉ sử dụng các labels được tạo ra để huấn luyện Meta-model. Ở phương pháp này, các predictions sẽ được coi như là features mới, và kết hợp với các features cũ để huấn luyện Meta-model
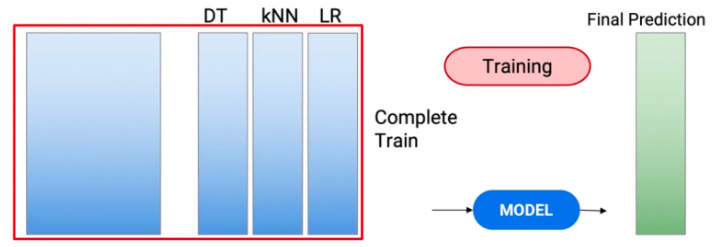
Và Meta-model cũng đưa ra dự đoán trên toàn bộ features ban đầu và predictions của test set

2.3 Tạo ra nhiều dự đoán cho test set và kết hợp chúng lại
Quay trở lại quá tình huấn luyện trên, với mỗi base-model, ở mỗi run, mô hình sẽ được training trên (k-1) phần và đưa ra dự đoán trên phần còn lại và trên cả test set. Như vậy sau k run, ta thu được k kết quả của test set. Phương pháp này khác 2.1 ở chỗ, thay vì huấn luyện mô hình với toàn bộ train set để đưa ra dự đoán trên test set, thì mô hình sẽ predict k lần với test set trong mỗi run. Tiếp theo để tổng hợp các kết quả thu được từ các run, nếu bài toán cần giải quyết thuộc Regression, ta sẽ tính mean các kết quả thu được, còn trong bài toán Classification, ta sẽ sử dụng voting để đưa ra duy nhất 1 predictions cho test set với mỗi base-model
Như vậy, giả sử, có k-fold và có m base-models, số lần predict trên test set trong quá trình huấn luyện là k*m lần (Mỗi base-model predict trên test set k lần). Phương pháp này giúp mô hình tăng accurracy và giảm overfitting nhưng nếu bộ dữ liệu lớn thì tốc độ xử lý của phương pháp này là vấn đề khá nghiêm trọng
Và phương pháp cuối cùng mình giới thiệu đến mọi người là
2.4 Multi-levels Stacking
Sau khi huấn luyện base-models ở level-0, thay vì huấn luyện với duy nhất 1 Meta-model, ta sử dụng một lớp các Meta-models, và cuối cùng là huấn luyện với Meta-model cuối cùng. Khi đó mô hình của ta sẽ bao gồm 3 tầng, phương pháp sử dụng nhiều tầng huấn luyện như vậy được gọi là Multi-levels Stacking
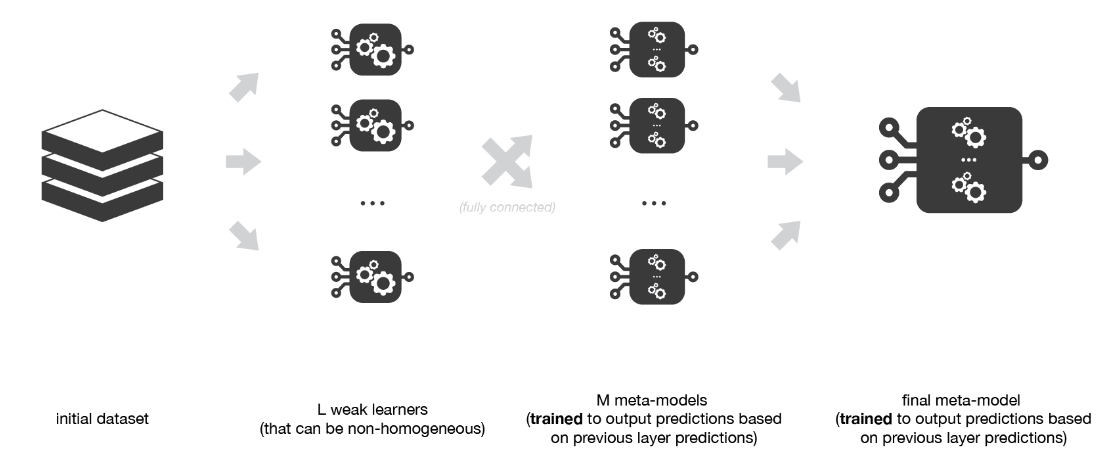
Vấn đề gặp phái với mô hình này, là nếu
- Không sử dụng k-fold, thì số lượng dữ liệu cần dùng là rất nhiều, vì hiện tượng overfitting rất dễ xảy ra
- Nếu sử dụng k-fold, thì thời gian huấn luyện là cực kì tốn kém
Với mỗi phương pháp đều có lợi-hại riêng, việc biến tấu và sử dụng Stacking như thế nào tùy thuộc vào bài toán mà ta cần giải quyết, nhưng tối quan trọng nhất mỗi phương pháp cần là:
- Tăng độ chính xác (Hiển nhiên)
- Độ phức tạp là có thể chấp nhận được
- Tránh và giảm hiện tượng overfitting
Trên đây là toàn bộ các phương pháp sử dụng Stacking, tiếp theo mình sẽ nói qua về
III. Stacking Ensemble Family
Trong các phương pháp ensemble learning, có rất nhiều là tiền thân và hậu duệ của Stacking
Mỗi phương pháp có cách nhìn nhận vấn đề khác nhau về cách đào tạo mô hình. Vậy, bắt đầu với
3.1 Voting Ensemble
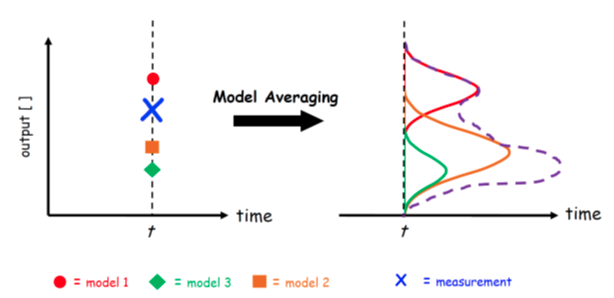
Voting ensemble là phương pháp ensemble learning đơn giản nhất. Tương tự như Stacking, Voting là tập hợp các mô hình khác nhau đưa ra dự đoán trên cùng tập dữ liệu, nhưng thay vì sử dụng meta-model để học cách kết hợp các dự đoán, Voting sử dụng phương pháp thống kê đơn giản.
- Trong bài toán Regression, Voting đưa ra mean hoặc median của các predictions từ các base-models
- Trong bài toán Classification, Voting sẽ sử dụng Hard-voting (Class được predicted nhiều nhất) hoặc Soft-voting (Class có tổng xác suất được predicted là cao nhất)
Trong Voting, tất cả các base-models được giả định có cùng độ quan trọng như nhau, cùng hiệu năng như nhau
3.2 Weighted Average Ensemble
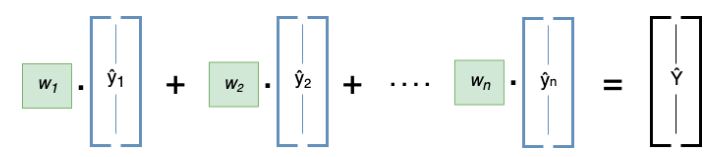
Tương tự như Stacking và Voting, Weighted Average Ensemble cũng sử dụng một tập hợp các base-models để đưa ra dự đoán
Nhưng khác với Voting, Weighted Average Ensemble sẽ đánh trọng số cho các base-models, ví dụ dựa trên accuracy, performance,.. của base-models trên bộ dữ liệu. Hoặc trọng số sẽ được optimize trong quá trình huấn luyện để đưa ra kết quả tốt nhất.
Đầu ra của mô hình sẽ là tổng trọng số của từng mô hình nhân với predictions của nó
3.3 Blending Ensemble
Với Stacking, vì chính việc sử dụng k-fold cross-validation khiến cho việc lần đầu tiếp cận với thuật toán khá là khó khăn, cho nên, Blending sử dụng hold-out để chia training set làm 2 phần là subset-1 và subset-2
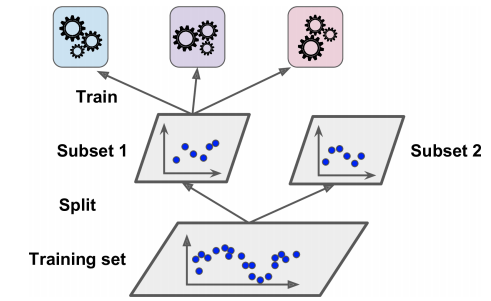
n-base-models sẽ được huấn luyện trên tập subset-1, sau đấy các mô hình sẽ đưa dự đoán trên tập subset-2
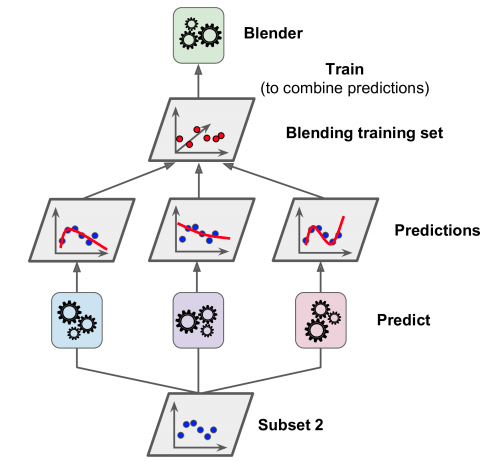
subset-2 cùng với predictions của các base-models được sử dụng như các features để huấn luyện Meta-model. Và thuật toán cuối cùng là
3.4 Super Learner Ensemble
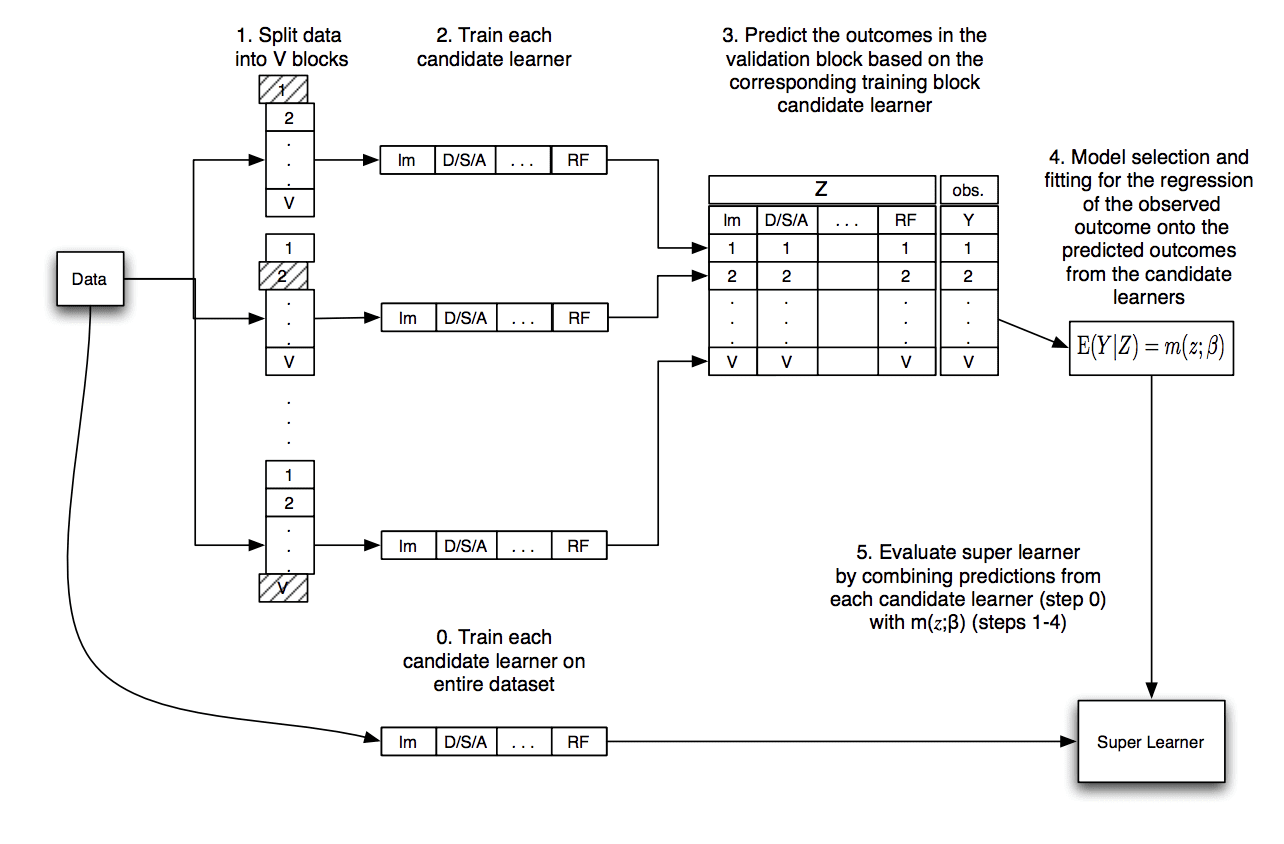
Đây là mô hình hóa thuật toán Super Learner. Về cơ bản mình thấy nó tương tự Stacking
IV. Lời kết
Trên đây là toàn bộ những gì mình biết và muốn giới thiệu với các bạn về Stacking. Mong giúp ích cho các bạn trong việc tìm hiểu thuật toán này. Nếu bài viết có sai sót, hoặc nếu các bạn thấy hay, hãy comment và upvote để mình biết và có động lực viết tiếp nhé. Vậy thôi, cảm ơn các bạn đã dành thời gian đọc bài viết của mình. Hẹn gặp lại các bạn trong bài viết tiếp theo. See ya!! (KxSS)
P/s: Về phần code, thì mình thấy trên google cũng nhiều bài viết hướng dẫn, nên mình sẽ không nêu ra ở bài viết này (thực ra là mình lười rồi  ). Hoặc nếu cần các bạn hãy để lại trong comment để mình viết tiếp code trong bài sau nhé
). Hoặc nếu cần các bạn hãy để lại trong comment để mình viết tiếp code trong bài sau nhé 
Tài liệu tham khảo
All rights reserved
