
Job Counting: Bài Toán Hóc Búa Mà Uber Giải Quyết "Trong Tích Tắc"
Bài đăng này đã không được cập nhật trong 2 năm
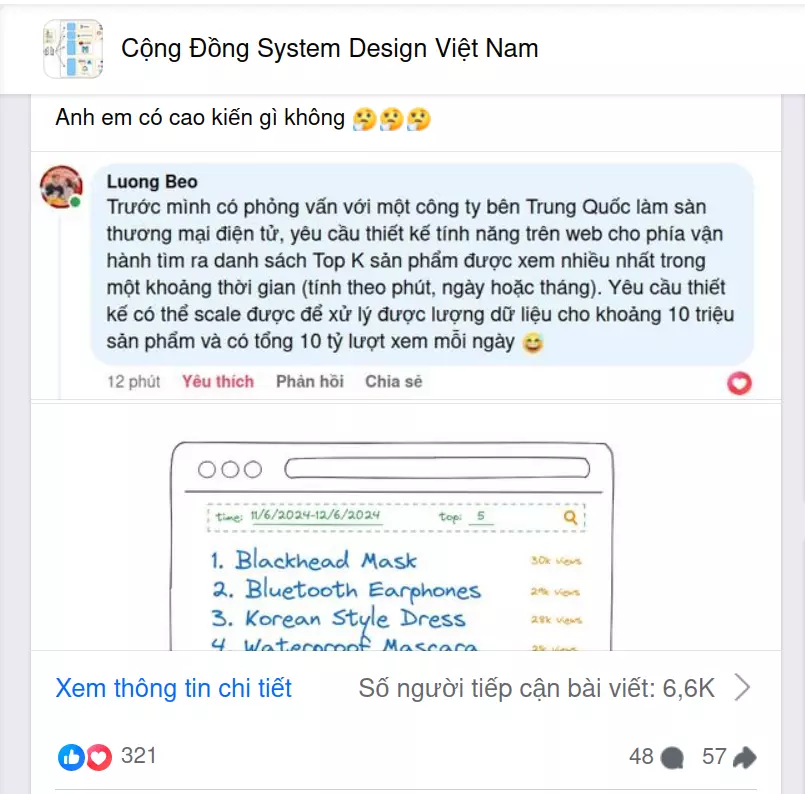
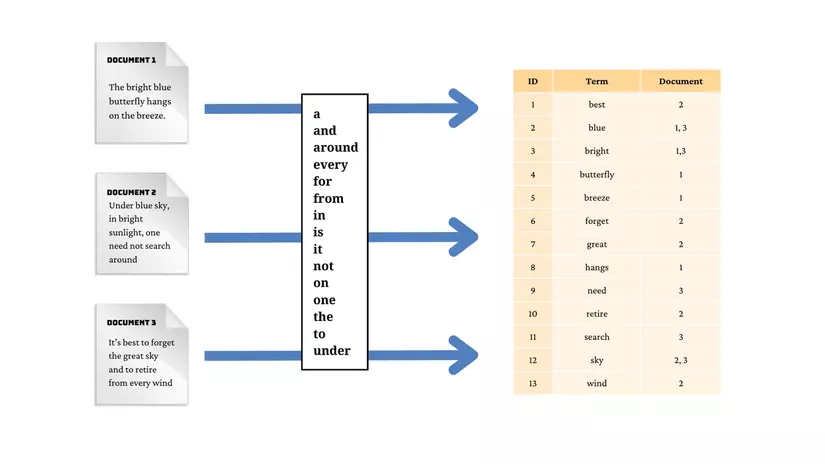
Trên là một câu hỏi rất hay về việc xử lý lượng dữ liệu vô cùng lớn và có nhiều giải pháp được các bạn trong cộng đồng đưa ra. Chung bài toán gần như vậy, nay chúng ta cùng tìm hiểu bài toán tại Uber, và xem cách họ xử lý với lượng dữ liệu khổng lồ như nào nha!!
Chúng mình có tạo Group cho các bạn cùng chia sẻ và học hỏi về thiết kế hệ thống nha 😄😄😄
Các bạn tham gia để gây dựng cộng đồng System Design Việt Nam thật lớn mạnh nhé 😍😍😍
Cộng Đồng System Design Việt Nam: https://www.facebook.com/groups/sydexa
Kênh TikTok: https://www.tiktok.com/@sydexa.com
Uber là một trong những công ty hàng đầu về ứng dụng đặt xe trực tuyến với hơn 150 triệu người dùng và gần 10 tỷ chuyến đi được hoàn thành trong năm 2023. Với quy mô lớn như vậy, dữ liệu liên tục được tạo ra từ mỗi chuyến đi, mỗi tài xế, và mỗi tương tác trên nền tảng là không hề nhỏ.
Uber xử lý hàng triệu chuyến đi mỗi ngày trên toàn cầu. Dữ liệu này bao gồm nhiều thông tin chi tiết về mỗi chuyến đi như thời gian bắt đầu và kết thúc, vị trí, tài xế liên quan, khách hàng liên quan, và nhiều yếu tố khác.
Một bài toán tưởng chừng đơn giản mà Uber cần làm đó là đếm số lượng các chuyến đi của từng tài xế trong các khoảng thời gian khác nhau (ngày, tuần, tháng) để đánh giá hiệu suất của tài xế, xác định số tiền mà tài xế cần được trả dựa trên số lượng chuyến đi hoàn thành.
Nhưng với lượng dữ liệu khổng lồ như trên thì đây là một bài toán khá khoai. Uber cần truy vấn và phân tích dữ liệu trong thời gian thực để đưa ra các quyết định nhanh chóng. Điều này bao gồm việc cập nhật số lượng chuyến đi một tài xế hoàn thành trong các khoảng thời gian khác nhau (ngày, tuần, tháng). Việc này đòi hỏi hệ thống phải có khả năng xử lý và truy xuất dữ liệu với độ trễ thấp. Hơn nữa dữ liệu của Uber còn được lưu trữ trên các máy chủ khác nhau. Điều này càng làm tăng độ phức tạp của bài toán.
Vậy Uber đã giải quyết bài toán này như nào nhỉ 🤔🤔
Câu trả lời đó chính là Apache Pinot, Uber đã giải quyết bài toán này bằng cách sử dụng Apache Pinot, một hệ thống phân tích dữ liệu thời gian thực. Apache Pinot giúp giảm độ trễ trong truy vấn và xử lý dữ liệu, cung cấp thông tin gần như ngay lập tức cho các quyết định kinh doanh. Điều này giúp Uber duy trì hiệu suất cao và đáp ứng nhu cầu phân tích dữ liệu của mình. Cùng Sydexa.com đi dạo một vòng tìm hiểu nha
1. Giới thiệu về Apache Pinot
Apache Pinot là một cơ sở dữ liệu phân tán mã nguồn mở được tạo ra tại LinkedIn vào giữa năm 2010. Nó đã được open-source vào năm 2015 và được tặng cho Apache Foundation vào năm 2019.
Với khả năng xử lý dữ liệu lớn theo thời gian thực, Pinot đã trở thành một giải pháp lý tưởng cho các doanh nghiệp cần phân tích dữ liệu một cách nhanh chóng và hiệu quả, và trở thành một trong những công cụ hàng đầu trong việc xử lý phân tích trực tuyến (OLAP).
Uber cần theo dõi số lượng công việc của tài xế – một bài toán OLAP điển hình đòi hỏi khả năng xử lý dữ liệu lớn. Pinot đáp ứng yêu cầu này nhờ ba tính năng nổi bật:
- Khả năng mở rộng: Pinot được thiết kế để mở rộng theo chiều ngang bằng cách chia nhỏ dữ liệu thành các phân vùng và phân phối chúng trên nhiều nút (node). Điều này cho phép Pinot xử lý lượng dữ liệu khổng lồ và đáp ứng nhu cầu truy vấn ngày càng tăng mà không gặp phải nút thắt cổ chai) bottle-neck về hiệu suất.
- Truy vấn nhanh: Pinot sử dụng định dạng lưu trữ dạng cột, điều này cho phép Pinot chỉ cần đọc các cột liên quan đến truy vấn, giảm thiểu lượng dữ liệu cần xử lý và tăng tốc độ truy vấn đáng kể.
- Làm mới dữ liệu: Pinot không chỉ xử lý dữ liệu theo batch mà còn có khả năng nhập dữ liệu từ các luồng dữ liệu thời gian thực như Kafka. Điều này đồng nghĩa với việc dữ liệu mới được cập nhật liên tục và sẵn sàng cho việc truy vấn chỉ trong vài giây.
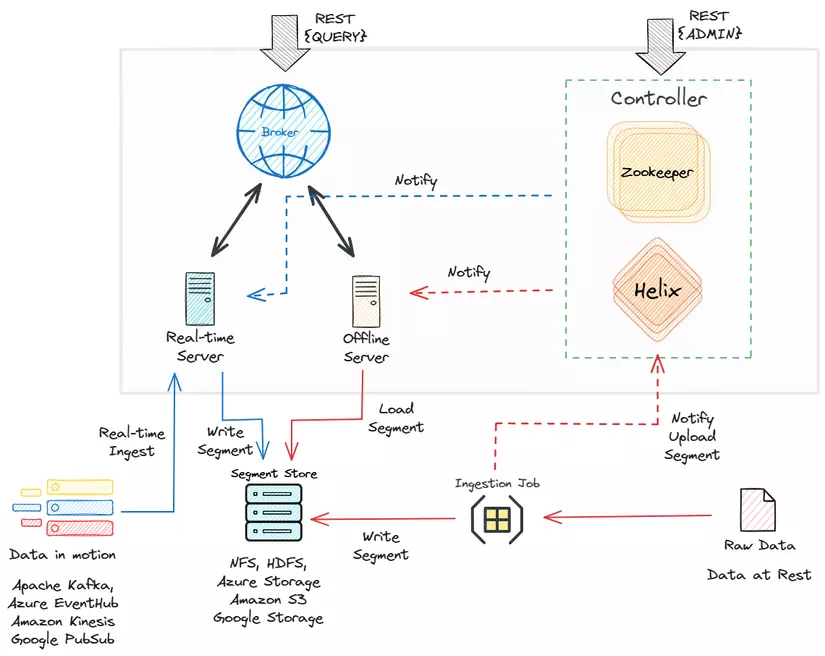
- Raw Data: Dữ liệu ban đầu, chưa qua xử lý được nhập vào hệ thống.
- Ingestion Job: Xử lý dữ liệu thô và chuyển đổi chúng thành định dạng phù hợp để lưu trữ trong Pinot.
- Segment Store: Nơi lưu trữ các đoạn dữ liệu đã qua xử lý. Các đoạn này là đơn vị lưu trữ cơ bản trong Pinot.
- Realtime Server: Xử lý việc nhập dữ liệu thời gian thực.
- Offline Server: Quản lý việc nhập dữ liệu theo từng batch.
- Broker: Hoạt động như một cầu nối giữa các máy chủ và các máy khách. Nó nhận truy vấn từ các máy khách và chuyển chúng đến các máy chủ thích hợp (thời gian thực hoặc ngoại tuyến) để truy xuất dữ liệu.
- Zookeeper (ZK): Điều phối và quản lý hệ thống phân tán. Nó giúp duy trì trạng thái cụm và quản lý cấu hình.
- Helix: Một khung quản lý cụm tự động, giúp quản lý tài nguyên phân vùng, sao chép và phân tán.
- Controller: Giám sát hoạt động tổng thể và điều phối cụm Pinot. Nó sử dụng Zookeeper và Helix để quản lý cụm và lưu trữ metadata.
Pinot lưu trữ dữ liệu trong các tệp phân đoạn, thường có kích thước từ 100-500 MB. Các tệp phân đoạn được lưu trữ trên các nút máy chủ Pinot và sao lưu trên AWS S3/HDFS/Google Cloud/v.v.
Dữ liệu thời gian thực có thể được nạp từ Kafka, EventHub, Google PubSub, v.v. và dữ liệu hàng loạt có thể được nạp bởi một máy chủ khác.
2. Những vấn đề mà Uber gặp phải
2.1 Ước tính dung lượng
Apache Pinot, công cụ cốt lõi trong hệ thống đếm số lượng công việc của Uber, sử dụng nhiều kỹ thuật nén dữ liệu khác nhau nhằm tối ưu hóa không gian lưu trữ. Tuy nhiên, điều này cũng gây ra khó khăn trong việc ước tính chính xác dung lượng lưu trữ cần thiết.
Các Kỹ Thuật Nén Dữ liệu trong Pinot:
- Dictionary Encoding: Thay thế các giá trị lặp lại (ví dụ: ID tài xế, thành phố) bằng các ID tương ứng trong một Dictionary, giúp giảm đáng kể kích thước dữ liệu.
- Fixed Bit Compression: Sử dụng số bit tối thiểu cần thiết để biểu diễn các số nguyên. Ví dụ, một số nhỏ như 5 có thể được biểu diễn bằng 3 bit thay vì 8 bit thông thường.
- Inverted Index: Không hẳn là một kỹ thuật nén dữ liệu, nhưng Inverted Index giúp tăng tốc độ truy vấn bằng cách tạo ra một chỉ mục ánh xạ các giá trị tới vị trí của chúng trong dữ liệu.
Sự Khó Khăn trong Ước Tính:
Mức độ nén đạt được phụ thuộc vào tính chất của dữ liệu. Các cột có nhiều giá trị duy nhất sẽ nén kém hơn so với các cột có ít giá trị duy nhất. Do đó, việc ước tính dung lượng lưu trữ trở nên phức tạp, đặc biệt khi dữ liệu có sự thay đổi theo thời gian và không thể dự đoán trước được mức độ phân phối của các giá trị.
Sử Dụng Tập Dữ Liệu Mẫu và Thử Nghiệm Tải
Để giải quyết vấn đề này, Uber đã áp dụng một quy trình gồm hai giai đoạn:
- Sử Dụng Tập Dữ Liệu Mẫu:
- Uber đã chọn một tập dữ liệu mẫu có tính đại diện cao, chứa khoảng 10% tổng số dữ liệu thực tế. Tập dữ liệu này cần bao gồm đủ các loại giá trị và phân phối tương tự như dữ liệu thực tế.
- Tập dữ liệu mẫu được tải lên Pinot và nhóm kỹ sư đã đo lường dung lượng lưu trữ thực tế sau khi nén.
- Dựa trên kết quả này, họ ước tính dung lượng lưu trữ cần thiết cho toàn bộ dữ liệu, đồng thời xem xét thêm một khoảng dự phòng để đảm bảo hệ thống không bị quá tải khi dữ liệu tăng lên.
- Thử Nghiệm Tải:
- Sau khi triển khai hệ thống với toàn bộ dữ liệu, Uber tiến hành thử nghiệm tải để đánh giá hiệu suất truy vấn trong điều kiện thực tế.
- Họ mô phỏng các truy vấn điển hình với tần suất và lưu lượng truy cập tương đương hoặc cao hơn dự kiến.
- Các thông số như thời gian phản hồi truy vấn, mức sử dụng CPU và tốc độ đọc ghi đọc được theo dõi chặt chẽ để xác định các nút thắt cổ chai và điểm cần tối ưu hóa.
2.2 Hiệu suất truy vấn
Để theo dõi số lượng công việc của tài xế, Uber thường xuyên thực hiện các truy vấn trên dữ liệu chuyến đi với cấu trúc tương tự như sau:
SELECT *
FROM pinot_hybrid_table
WHERE
provider_id = "..."
AND requester_id = "..."
AND timestamp >= .... AND timestamp <= ...
- Provider_id: ID của tài xế hoặc nhà cung cấp dịch vụ.
- Requester_id: ID của khách hàng hoặc người yêu cầu dịch vụ.
- Timestamp: Thời điểm xảy ra sự kiện, thường được sử dụng để lọc dữ liệu trong một khoảng thời gian cụ thể.
Câu lệnh này cho phép truy vấn tất cả các dữ liệu liên quan đến một tài xế cụ thể (provider_id), một khách hàng cụ thể (requester_id) và trong một khoảng thời gian nhất định (timestamp).
Truy vấn này tìm kiếm tất cả các chuyến đi của một tài xế cụ thể trong một khoảng thời gian xác định. Với lượng dữ liệu khổng lồ của Uber, việc thực hiện truy vấn này trên toàn bộ tập dữ liệu có thể mất rất nhiều thời gian.
Inverted Index và Bloom Filter.
Để tăng tốc độ truy vấn, Uber đã áp dụng inverted index và bộ lọc Bloom (bloom filter).
- Inverted index: là một cấu trúc dữ liệu giúp tìm kiếm nhanh hơn. Nó giống như phần "mục lục" ở cuối sách giáo khoa, nơi bạn có thể tìm thấy các từ khóa và trang tương ứng chứa chúng. Để cải thiện hiệu suất truy vấn, Uber đã sử dụng inverted index cho các cột
provider_idvàrequester_id. Nhờ đó, hệ thống có thể nhanh chóng xác định tệp phân đoạn và hàng chứa dữ liệu cho từngprovider_idhoặcrequester_id, giúp tăng tốc độ truy vấn đáng kể.
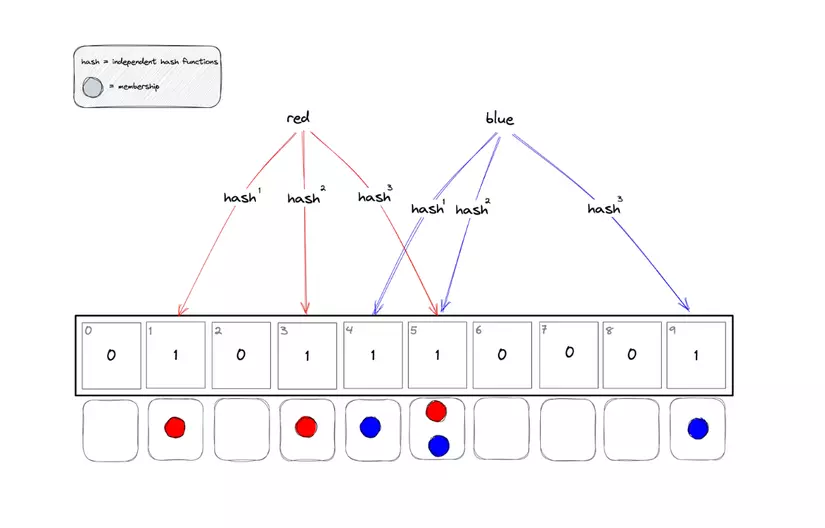
- Bộ lọc Bloom:
Bộ lọc Bloom là một công cụ mạnh mẽ giúp Pinot tăng tốc độ tìm kiếm dữ liệu. Nó hoạt động bằng cách kiểm tra nhanh xem một phần tử cụ thể có khả năng nằm trong một tập hợp dữ liệu hay không.
Uber đã bật bộ lọc Bloom cho từng tệp phân đoạn dựa trên provider_id và requester_id. Điều này có nghĩa là trước khi tìm kiếm chi tiết trong một tệp phân đoạn, Pinot sẽ sử dụng bộ lọc Bloom để kiểm tra xem liệu provider_id hoặc requester_id có tồn tại trong tệp đó hay không. Nếu không, Pinot sẽ bỏ qua tệp đó, giúp tiết kiệm thời gian và tài nguyên đáng kể trong quá trình truy vấn.
- Nhóm các cuốc xe theo tài xế: Uber đã sắp xếp dữ liệu theo cột
provider_id, nghĩa là các cuốc xe của cùng một tài xế trong cùng một ngày sẽ được đặt trong cùng một tệp phân đoạn. Vì tài xế Uber thường có thể xử lý hơn 5 công việc trong một ngày, việc sắp xếp này giúp giảm thiểu số lượng tệp phân đoạn được truy cập mỗi khi có truy vấn, từ đó tăng hiệu suất hệ thống.
2.2 Đối phó với lượng request đột biến
Hệ thống đếm số lượng công việc của Uber, giống như nhiều ứng dụng đặt xe khác, phải đối mặt với tình trạng quá tải vào những giờ cao điểm, đặc biệt là giờ tan tầm hay các dịp lễ tết. Để giải quyết vấn đề này, Uber đã áp dụng một kỹ thuật thông minh gọi là "jitter" (độ nhiễu).
Hãy hình dung jitter như việc điều chỉnh đèn giao thông để tránh ùn tắc. Thay vì tất cả các xe đều cùng dừng và cùng đi, đèn giao thông sẽ điều chỉnh thời gian một cách ngẫu nhiên, giúp các xe di chuyển đều đặn hơn. Tương tự, jitter sẽ thêm một khoảng thời gian ngẫu nhiên vào thời gian chờ giữa các lần thử lại của một yêu cầu khi gặp lỗi. Điều này giúp các yêu cầu không dồn dập cùng lúc, giảm tải cho hệ thống và đảm bảo hoạt động ổn định.
Và đó là cách mà Uber xử lý một bài toán tưởng chừng đơn giản, nhưng với quy mô của mình thì bài toán này trở lên vô cùng phức tạp
Lời nhắn:
Chúng mình có tạo Group cho các bạn cùng chia sẻ và học hỏi về thiết kế hệ thống nha 😄😄😄
Các bạn tham gia để gây dựng cộng đồng System Design Việt Nam thật lớn mạnh nhé 😍😍😍
Cộng Đồng System Design Việt Nam: https://www.facebook.com/groups/sydexa
Kênh TikTok: https://www.tiktok.com/@sydexa.com
Đọc thêm:
Bài viết chia sẻ từ Uber: https://www.uber.com/en-VN/blog/job-counting-at-scale/
All rights reserved
