Introduction Backpropagation RNN and LSTM(Series 3)
Bài đăng này đã không được cập nhật trong 3 năm
Phần 1: BPTT(Backpropgtation in Time)
Trong bài viết này chúng ta sẽ tìm hiểu về Backpropagation in RNN từ đó hiểu lý do tại sao chúng bị vaninshing gradient . Mọi con số khi đạo hàm để tìm ra weight tiến đến 0. Khi weight mà tiến đến 0 thì mọi thứ chúng sẽ không thể nào tối ưu hóa được tức mạng nơ-ron dù train bao nhiêu đi chăng nữa chúng vẫn không có một chút tác động nào.
Đây thuộc phàn series thứ 3 trong bài viết này . Hãy cùng bắt đầu nào.

Trong hình ảnh trên bạn có thể nhìn thấy chúng có 3 đầu vào, được gọi là các state input . Tuy nhiên RNN lưu trữ bộ nhớ đầu vào thông qua các . Có thể hiểu lưu trữ thông tin của và . Đó trình là quá trình lưu trữ thời gian trước đó để tính thời gian tiếp theo nên mới có tên gọi backprogation in time.Đầu tiên chúng ta sẽ tính các state lưu trữ bộ nhớ dựa trên và và dự đoán đầu ra tùy theo mục đích ứng dụng. Tiếp tục tương tự với và . Ứng dụng ở đây có thể là dự đoán từ tiếp theo( token tiếp theo), phân loại văn bản,..vv

Đầu tiên ta sẽ tính các weight output y tức là các y kết nối với a(hidden state at time t). Vì có 3 bước time t nên ta sẽ tính kết hợp dựa trên cả 3. Có một số bước ghi tắt chúng vẫn ở các ta tính loss multiclass crossentropy dựa trên series 1.

Sau khi đã hoàn thành xong bước 1 chúng ta sẽ bước tiếp sang thứ 2 đó là tính weight hiddent state tức state lưu trữ bộ nhớ a kết nối với x và hidden state thời gian trước đó.Bước đầu là sẽ tính .

Đoạn này sẽ nêu rõ các ta tính đạo hàm với activation function tanh

Do hiddent state dựa trên hidden state trước đó và đầu vào . Nên trong đây ta sẽ phải tính từng .

Ta nhận biết được rằng mỗi đều sẽ có 2 trường hợp dự trên các hidden state time trước đó tùy thuộc vào giá trị time trước đó nên có 2 trường hợp. Nếu bất cứ thời gian trước đó là giá trị 0 hoặc 1 tức không tác động đến hiddent state này và ngược lại tức thông tin hidden state trước đó có tác động trực tiếp đến hidden state này.

Từ ta nhận ra rằng chúng có rất nhiều phép nhân nối tiếp với nhau. Thời gian càng dài càng nhiều phép nhan nối tiếp với nhau giống như bộ não của chúng ta ký ức càng lâu khả năng nhớ càng kém theo thời gian . Tuy nhiên bộ não của chúng ta biết chọn lọc ký ức một cách rất ấn tượng có những thứ dù chúng đi xa thế nào đi chăng nữa chúng ta vẫn nhớ được chúng.

đã chỉ ra rõ ràng chúng ta rằng chúng tương tự như a2 đều có 2 trường hợp được thực hiện phân biệt chúng bằng phép tính cộng . Nhưng ở có 2 trường hợp và trường hợp 2 lại phân ra làm 2 trường hợp nữa, kết hợp tất cả với nhau ta nhạn thấy được kỳ tích giữa chúng.

Ta sẽ cố gắng tính toàn bộ dựa trên . Có lẽ hình vẽ cách tính rất phức tạp nhưng đừng lo về chúng chỉ cần bặn nhớ các series trước là ta sẽ hiểu cách hoạt động của chúng rất dễ dàng. Và khi kết hợp lại với nhau ta sẽ được matrix đường chéo diag.
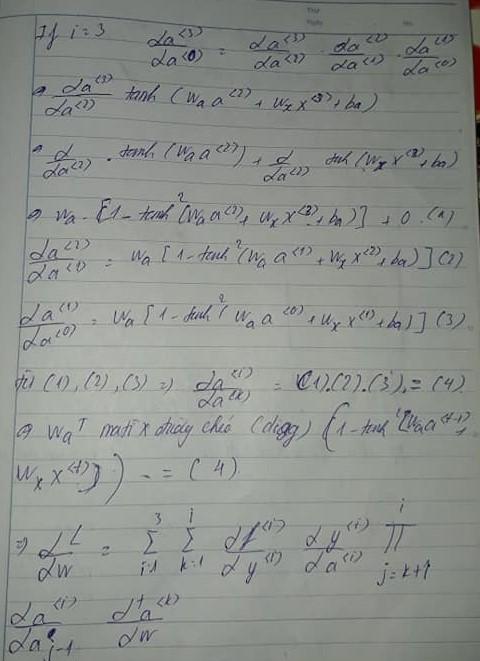
Tổng hợp lại tất cả cách thức trên ta có thể tính ra weight của toàn bộ hidden state được thực hiện như thế nào . Mặc dù chúng không dễ dàng gì

Tiếp tục tính với weight input

Để có cái nhìn rõ hơn về triệt tiêu gradient tức weight tiệm cận 0 . Ta có thể hiểu cái quan trong nhất chính là các matrix đường chéo. Vân đề cái với hay với do chúng không có ánh xạ f(x). Không có giá trị liên quan đến nhau nên tất cả đều bằng 0. Tương tự như vậy.
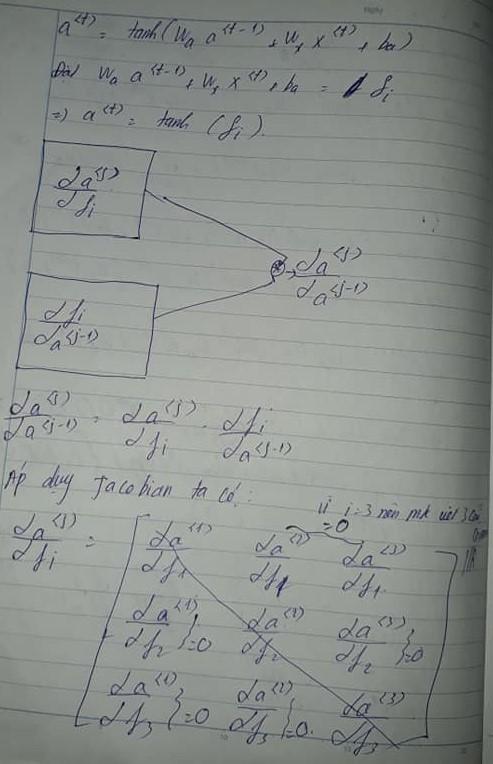

Bạn phải hiểu rõ 1-tanh(x^2) vì chúng là nguyên nhân trực tiếp dẫn đến triệt tiêu gradient. Vì hàm tanh này có bình phương nên luôn là số dương và nếu 1 trừ đi số dương luôn nằm trong khoảng từ 0-1 thì sẽ liên tục nhân như vậy nối tiếp nhau sẽ gần bằng 0. Do đó các số bé nhân với các số bé liên tục kéo dài theo thời gian sẽ tiến gần đến 0 . Hoặc bất kể ban đầu là số lớn rồi nhân với số bé liên tục cũng tiến đến 0. Cái quan trọng ban đầu weight output là một số rất ổn định tuy nhiên sau khi thông qua các hidden state at time ( lưu trữ bộ nhớ) thì chúng lại nối tiếp nhau thành các số bé hơn . Nên bạn biết rằng càng nhiều t(time) thì chúng càng nối tiếp nhau , có 2 nguyên nhân dẫn đến triệt tiêu 1 là bộ nhớ thời gian t giữa trên thời gian trước đó . Mà nếu càng dài lại càn phải dựa trên thời gian trước đó( trong thời gian đó nữa) , 2 là do activation bị giới hạn. Cái quan trọng lại chính là activation tanh khi đạo hàm tạo ra một giá trị bị thu hẹp lại.

Phần 2: Backward LSTM(Backpropgtation in LSTM)
Một cách để khắc phục vấn đề ở RNN(vaninshing gradient) là sử dụng các cổng kết nối . Trong đó có hai biến thể chính của RNN là GRU và LSTM , trong phần này chúng ta sẽ đào sâu vào backward LSTM . Tại sao chúng lại khắc phục vấn đề vaninshing gradient. Hãy cùng bắt đầu nào
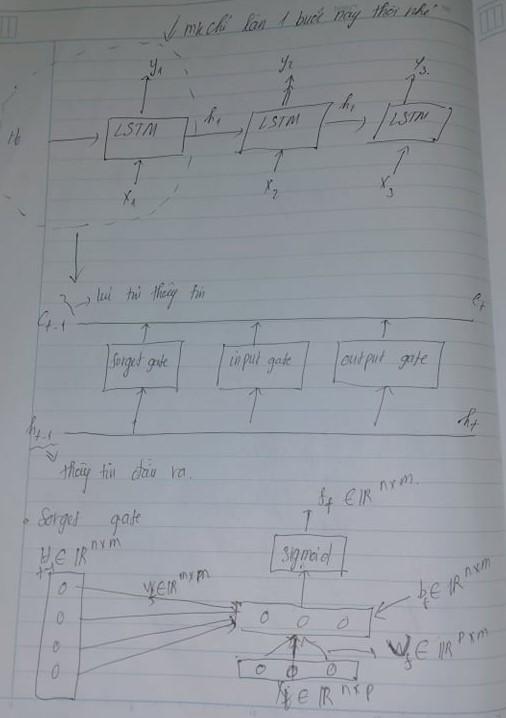
Chúng ta biết rằng khi một vấn đề với thời gian quá dài RNN sẽ không thể lưu trữ bộ nhớ state được nhưng đó là lúc LSTM thành công bằng việc sử dụng các cổng(gate) chúng thường thành công trong các lĩnh vực khi dịch máy , nhận dạng giọng nói, dự báo chuỗi thời gian.LSTm hoạt động như bộ não chúng ta những kiến thức quan trọng thì chúng ta sẽ cần ghi nhớ chúng , còn đâu thì ta sẽ loại bor3 . Hãy khám phá thêm về 3 cấp cổng đầu vào của chúng.
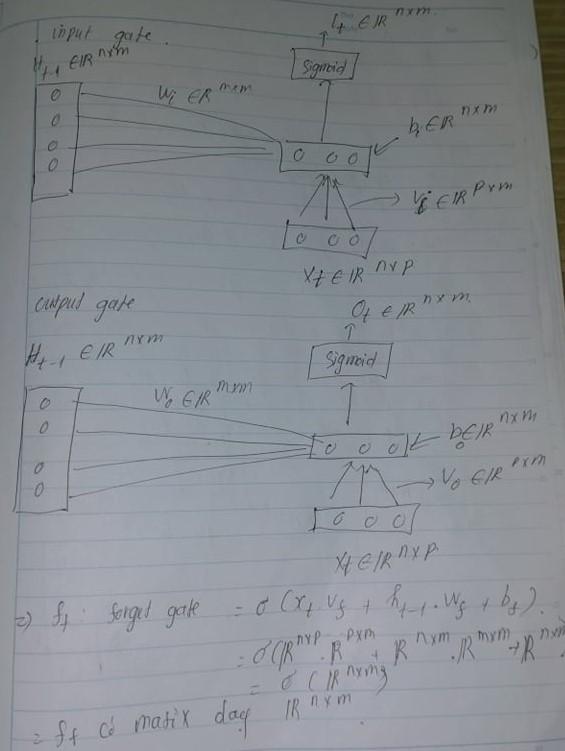
- Forget gate (Cổng quên kiểm soát thông tin nào được xóa khỏi ô nhớ).Thông tin không còn hữu ích trong trạng thái ô sẽ bị xóa bằng cổng quên. Hai đầu vào (đầu vào tại thời điểm cụ thể) và (đầu ra của ô trước đó) được đưa đến cổng và nhân với ma trận weight, sau đó cộng thêm bias. Kết quả được chuyển qua một activation function sigmoid. Nếu đầu ra là 0, phần thông tin sẽ bị quên và đối với đầu ra 1, thông tin được giữ lại để sử dụng trong tương lai.
- Input gate (Cổng đầu vào kiểm soát thông tin nào được thêm vào ô nhớ).Việc bổ sung thông tin hữu ích vào trạng thái ô được thực hiện bởi cổng vào. Đầu tiên, thông tin được điều chỉnh bằng activation function sigmoid và lọc các giá trị cần nhớ tương tự như cổng quên sử dụng đầu vào và . Sau đó, một vectơ được tạo bằng cách sử dụng activation tanh cung cấp đầu ra từ -1 đến +1, chứa tất cả các giá trị có thể có từ và . Cuối cùng, các giá trị của vectơ và các giá trị quy định được nhân lên để thu được thông tin hữu ích.
- Output gate (cổng đầu ra kiểm soát thông tin nào được xuất ra từ ô nhớ.)Nhiệm vụ trích xuất thông tin hữu ích từ trạng thái ô hiện tại để được trình bày dưới dạng đầu ra được thực hiện bởi cổng đầu ra.Đầu tiên, một vectơ được tạo bằng cách áp dụng hàm tanh trên ô. Sau đó, thông tin được điều chỉnh bằng cách sử dụng hàm sigmoid và lọc theo các giá trị cần nhớ bằng đầu vào và . Cuối cùng, các giá trị của vectơ và các giá trị quy định được nhân lên để gửi dưới dạng đầu ra và đầu vào cho ô tiếp theo.

Bây giờ chúng ta sẽ tính các weight của lần lượt input gate, forget gate và output gate. Nhưng trước đó ta sẽ tổng hợp sơ đồ LSTM như sau:
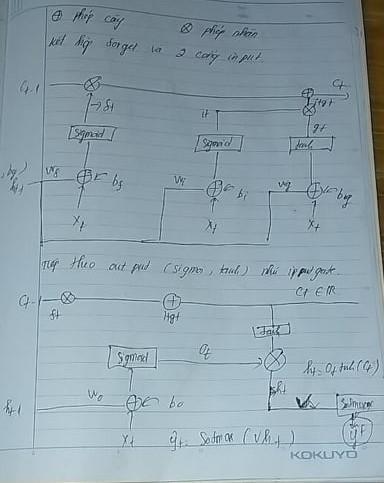
Tổng kết lại từ sơ đồ trên ta viết forward của LSTM.
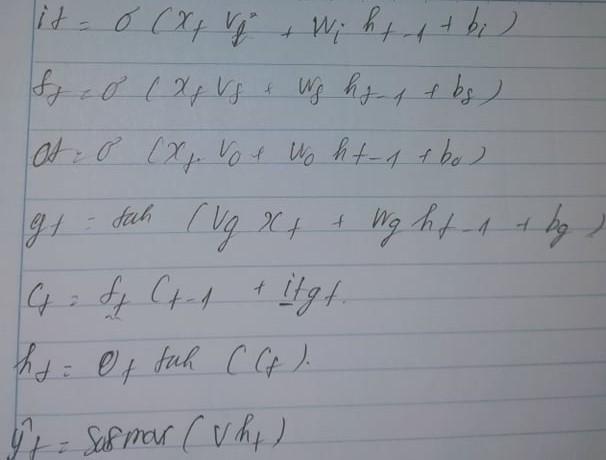
Ở đây vt,vi,vo tương ứng với weight của theo sau lần lượt là weight forge gate, weight input gate, weight output gate. Tương tự như vậy wt,wi,wo tướng ứng với weight của theo sau lần lượt là weight forge gate, weight input gate, weight output gate. Lưu ý rằng vg,wg cũng tương tự như vi,wi do input gate có 2 bước là điều chỉnh dựa trên activation sigmoid để lọc giá trị quan tâm và activation tanh.
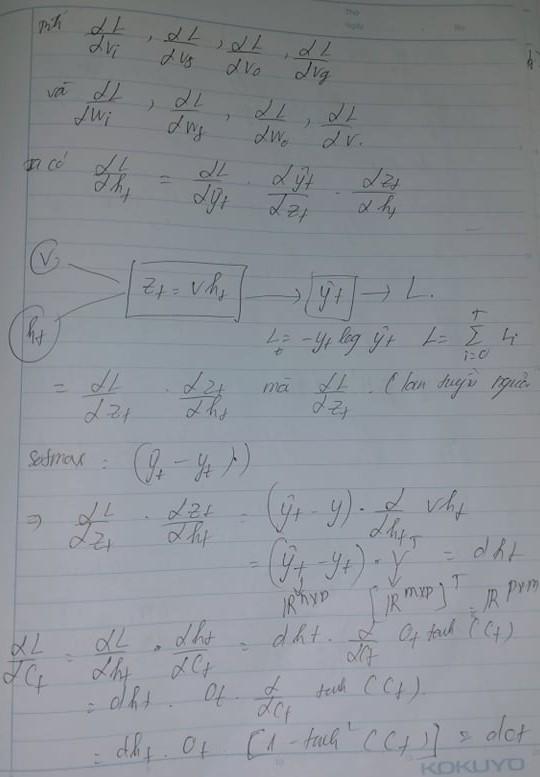
Ta sẽ tính toán dựa trên ngược lại sơ đồ forward . Dựa vào chúng ta tính đạo hàm trạng thái tiếp theo sau đó tính . Tất cả đã được tính toán dựa trên hình vẽ

Tiếp tục ta tính toán chúng dựa trên sơ đồ forward đã cho là gt,ot,ft,it lần lượt
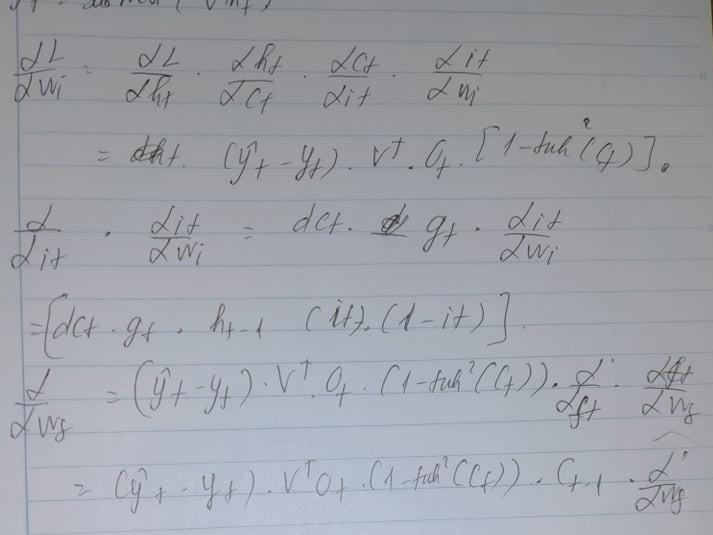
Từ đó ta có thể suy luận ra các wt,wi,wo
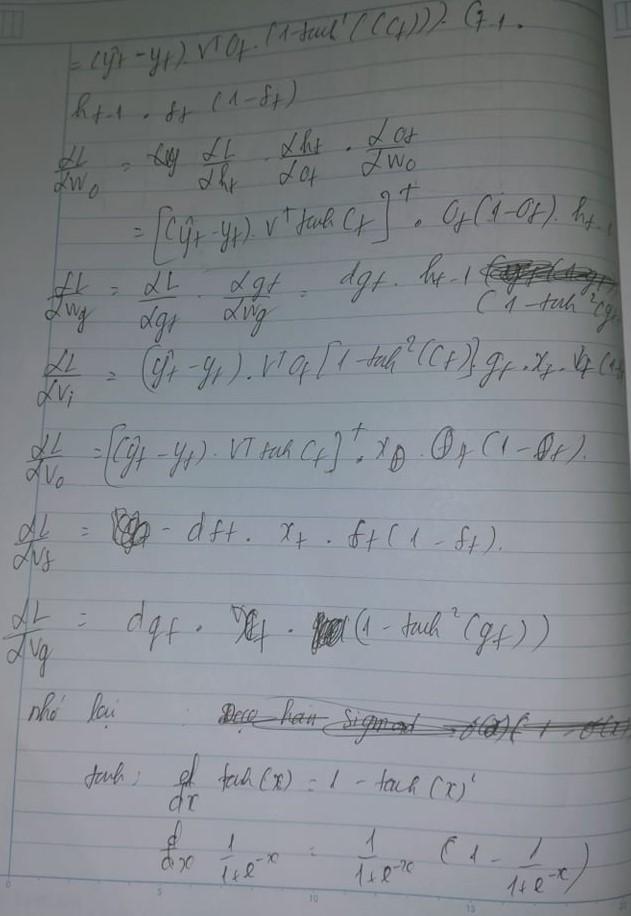
Cuối cùng sẽ là các vt,vi,vo. Kết luạn lại rằng do chúng sử dụng quá nhiều các cổng để thay đổi liên tục các giá trị nên chúng tránh các vấn đề bị triệt tiêu gradient . Lúc thiwf ta sử dụng activation kia lúc lại thay đổi khiến chúng không bị nhỏ dần theo thời gian . Tuy nhiên chúng vẫn sẽ bị nhưng vấn sẽ hướng đến tối ưu hóa
Phần 3: Kết luận
Trên đây là phần về NLP các model quan trọng khi backward . Bài viết này mặc dù đã đằng được từ 2 năm trước từ nick của bản thân. Tuy nhiên mặc dù hiện tại transformers gần như đã hoàn toàn thống trị NLP nên chúng ta đã dàn dần quên lãng các model cũ ngày xưa
Tham khảo
https://www.facebook.com/groups/511510259620251/?multi_permalinks=951965328908073(Phần 1) https://www.facebook.com/groups/511510259620251/?multi_permalinks=967018490736090(Phần 2)
All rights reserved
