Image Cationing đơn giản với Tensorflow/Keras
Bài đăng này đã không được cập nhật trong 5 năm
I. Introduction
Xin chào các bạn và đến hẹn mình lại ngóc lên đây  , sau khi google search với key word image captioning viblo thì hiện mình chưa thấy bài viết nào chia sẻ về chủ đề trên nên mình sau một hồi cân nhắc và suy xét thì mình quyết định chọn chủ đề này để chia sẻ tới các bạn và cũng một phần để sau này mình quên thì sẽ có cái để đọc lại. Bài viết xuất phát từ cuộc thi VLSP năm nay trong đó có 1 task thực hiện phân tích câu positive và negative với data được cho từ ban tổ chức đưa ra bao gồm: 1 câu post, các lượt thống kê về comment, like.. và 1 folder bao gồm các ảnh có liên quan tới nội dung post thì mình có nảy ra suy nghĩ rằng không biết liệu mình có thể chuyển hình ảnh đầu vào thành 1 câu text được không. Thôi không lung tung luyên thuyên nữa mình cùng vào bài viết nhé, à nếu các bạn thấy bài viết hay và hữu ích thì đừng tiếc cho mình xin 1 lượt upvote để mình có thêm động lực ra các bài viết mới chất lượng hơn nhé.
, sau khi google search với key word image captioning viblo thì hiện mình chưa thấy bài viết nào chia sẻ về chủ đề trên nên mình sau một hồi cân nhắc và suy xét thì mình quyết định chọn chủ đề này để chia sẻ tới các bạn và cũng một phần để sau này mình quên thì sẽ có cái để đọc lại. Bài viết xuất phát từ cuộc thi VLSP năm nay trong đó có 1 task thực hiện phân tích câu positive và negative với data được cho từ ban tổ chức đưa ra bao gồm: 1 câu post, các lượt thống kê về comment, like.. và 1 folder bao gồm các ảnh có liên quan tới nội dung post thì mình có nảy ra suy nghĩ rằng không biết liệu mình có thể chuyển hình ảnh đầu vào thành 1 câu text được không. Thôi không lung tung luyên thuyên nữa mình cùng vào bài viết nhé, à nếu các bạn thấy bài viết hay và hữu ích thì đừng tiếc cho mình xin 1 lượt upvote để mình có thêm động lực ra các bài viết mới chất lượng hơn nhé.

Các bạn nhìn thấy gì từ hình ảnh trên? Một chú chó màu trắng trong một vùng cỏ. Hay chú chó trắng với những đốm vàng. Và một số người khác lại cho rằng đó là chú cho trắng với những đốm vàng đứng trên bãi cỏ và một số bông hoa màu hồng.
Vâng và tất cả những bình luận trên hoàn toàn hợp lý vì chúng đều có liên quan tới nội dung của hình ảnh, nó rất dễ dàng đối với chúng ta vì chúng chỉ cần lướt qua được hình ảnh với một vài từ ngữ mô tả chúng ta đề có thể mô tả bằng một ngôn từ thích hợp. Tuy nhiên cái mà hôm nay mình muốn giới thiệu tới các bạn đó là liệu chúng ta có thể viết được ra một chương trình mà với đầu vào là một hình ảnh thì đầu ra của chương trình là những chú thích được hay không? Với khoảng thời gian trước đây khi Deep Learning chưa phát triển thì điều này là một việc không tưởng, tuy nhiên với sự ra đời của deep leaning thì nó là một việc không quá khó khăn nếu chúng ta có một bộ dữ liệu phù hợp. Vậy deep learning được sử dụng như thế nào để tạo ra một phụ đề hay một mô tả cho một hình ảnh, mình cùng bước vào chi tiết hơn của bài viết nhé.
II. Application
Trước tiên chúng ta sẽ dành một chút thời gian để nói qua về các ứng dụng của image captioning quan trọng như thế nào để giải quyết các bài toán trong thực tế. Chúng ta cùng nhau điểm qua một vài ứng dụng mà nếu chúng ta giải quyết tốt bài toán trên thì sẽ rất có ích.
- Xe tự lái ( self driving cars): chắc hẳn các bạn chả xa lạ gì với từ khóa trên phải không nào, lái xe tự động là một bài toán lớn với rất nhiều những thử thách mà được các ông lớn về công nghệ luôn tìm hướng cải tiến, giải quyết các bài toán trong đó và nếu chúng ta chú thích được đúng cảnh xung quanh ô tô thì thật tuyệt với, nó sẽ thúc đẩy hệ thống sẽ tự lái với những thông tin được cung cấp rất có giả trị.
- Hỗ trợ người mù ( aid to the blind): chúng ta có thể tạo ra một sản phẩm hỗ trợ người mù hướng dẫn họ khi họ di chuyển qua đường, đi lại mà không cần sự hỗ trợ của người khác. Trước tiên chúng ta có thể chuyển hình ảnh xung quanh họ thành đoạn text sau đó từ text sẽ chuyển thành lời nói để họ có thể chủ động trong việc xử lý các tình huống với những thông tin được cung cấp.
- Camera giám sát: ngày nay trên các hệ thống đường đi lại, tòa nhà công.. của các quốc gia đã triển khai các hệ thống camera giám sát, nếu chúng ta cũng tạo được những phụ đề phù hợp thì thì có thể báo động ngay những hành động không tốt đang diễn ra như cảnh báo nguy cơ tai nạn, trộm cướp, cháy nổ...
vâng và còn rát nhiều ứng dụng khác nữa....
III. Data Collection
Có rất nhiều bộ dataset có sẵn và bạn có thể lấy ra để thực hành như Flickr 8k (gồm 8k images), Flickr 30k (gồm 30k images), MS COCO (gồm 180k images)... Trong bài viết này mình sẽ sử dụng bộ Flickr 8k, bạn cứ google search là ra ngay. Bộ dataset bao gồm 8000 images với mỗi ảnh bao gồm 5 captions.
- Training Set — 6000 images
- Dev Set — 1000 images
- Test Set — 1000 images
IV. Building model
Trong bài viết này mình sẽ hướng dẫn các bạn thực hiện xây dựng mô hình để nhận dạng các đặc trưng của ảnh và sử dụng caption để mô tả hình ảnh thông qua mạng CNN và LSTM. Trong bài viết này mình xin đưa ra 1 pipeline các bạn có thể thay đổi các kiến trúc mô hình cho phù hợp cũng như áp dụng thêm các kĩ thuật nâng cao hơn. Pileline được mình tham khảo trong quá trình tìm hiểu về chủ đề này mình sẽ để ở phần dưới bài viết.
Step 1: Import the required libraries
import numpy as np
import pandas as pd
import os
import tensorflow as tf
from keras.preprocessing.sequence import pad_sequences
from keras.preprocessing.text import Tokenizer
from keras.models import Model
from keras.layers import Flatten, Dense, LSTM, Dropout, Embedding, Activation
from keras.layers import concatenate, BatchNormalization, Input
from keras.layers.merge import add
from keras.utils import to_categorical, plot_model
from keras.applications.inception_v3 import InceptionV3, preprocess_input
import matplotlib.pyplot as plt # for plotting data
import cv2
Step 2: Load the descriptions
Mình có sử dụng luôn bộ dữ liệu này trên kaggle nên các bạn có thể thực hiện theo nhé
# Load data
images_dir = os.listdir("../input/flickr8k/Flickr_Data/Flickr_Data")
print(images_dir)
images_path = '../input/flickr8k/Flickr_Data/Flickr_Data/Images'
captions_path = '../input/flickr8k/Flickr_Data/Flickr_Data/Flickr_TextData/Flickr8k.token.txt'
train_path = '../input/flickr8k/Flickr_Data/Flickr_Data/Flickr_TextData/Flickr_8k.trainImages.txt'
val_path = '../input/flickr8k/Flickr_Data/Flickr_Data/Flickr_TextData/Flickr_8k.devImages.txt'
test_path = '../input/flickr8k/Flickr_Data/Flickr_Data/Flickr_TextData/Flickr_8k.testImages.txt'
MÌnh có thể thử load 1 vis dụ để các bạn có thể hiểu rõ hơn nhé
def load_doc(filename):
file = open(captions_path, 'r')
text = file.read()
file.close()
return text
doc = load_doc(captions_path)
print(doc[:300])

Sau đó ta cần load các mô tả hay caption cho từng hình ảnh với output sẽ là 1 dict với key là tên các hình ảnh và value là một mảng bao gồm các caption
def load_descriptions(doc):
mapping = dict()
for line in doc.split("\n"):
token = line.split()
if len(line)<2:
continue
image_id, image_desc = token[0], token[1:]
image_id = image_id.split(".")[0]
image_desc = ' '.join(image_desc)
if image_id not in mapping:
mapping[image_id] = list()
mapping[image_id].append(image_desc)
return mapping
descriptions = load_descriptions(doc)
Ta có output như sau:
{'1000268201_693b08cb0e': ['A child in a pink dress is climbing up a set of stairs in an entry way .', 'A girl going into a wooden building .', 'A little girl climbing into a wooden playhouse .', 'A little girl climbing the stairs to her playhouse .', 'A little girl in a pink dress going into a wooden cabin .'], '1001773457_577c3a7d70': ['A black dog and a spotted dog are fighting', 'A black dog and a tri-colored dog playing with each other on the road .', 'A black dog and a white dog with brown spots are staring at each other in the street .', 'Two dogs of different breeds looking at each other on the road .', 'Two dogs on pavement moving toward each other .']
Step 3: Cleaning the text
Việc tiếp theo là phần xử lý text để xóa bỏ các nhiễu trong nội dung text giúp cho mô hình có thể học dễ dàng hơn. Các nhiễu thường gặp như các kí tự # , v.v việc áp dụng xử lý dữ liệu này như thế nào là tùy thuộc ở phần dữ liệu các bạn xử lý do đó với mỗi dữ liệu bạn có thể sử dụng những phương pháp sao cho phù hợp.
import string
def clean_descriptions(descriptions):
table = str.maketrans('','',string.punctuation)
for key, desc_list in descriptions.items():
for i in range(len(desc_list)):
desc = desc_list[i]
desc = desc.split()
desc = [word.lower() for word in desc]
desc = [w.translate(table) for w in desc]
desc = [word for word in desc if len(word)>1]
desc_list[i] = ' '.join(desc)
clean_descriptions(descriptions)
Step 4: Generate the Vocabulary
Tạo ra vocabulary là một phần rất quan trọng tùy thuộc vào các bạn có thể sử dụng các thư viện có sẵn hoặc tự xây dựng đều được.
def to_vocab(desc):
words = set()
for key in desc.keys():
for line in desc[key]:
words.update(line.split())
return words
vocab = to_vocab(descriptions)
Step 5: Load the images
Ở đây, chúng ta cần ánh xạ các hình ảnh trong tập huấn luyện với các mô tả tương ứng của chúng có trong biến mô tả. Tạo một danh sách tên của tất cả các hình ảnh chúng ta sẽ training, sau đó tạo một từ điển trống và ánh xạ các hình ảnh với mô tả của chúng bằng cách sử dụng tên hình ảnh làm khóa và danh sách các mô tả làm giá trị của nó. Trong khi ánh xạ các mô tả thêm các từ ở đầu và cuối để xác định vị trí bắt đầu và kết thúc của câu.
import glob
images = '/kaggle/input/flickr8k/flickr_data/Flickr_Data/Images/'
# Create a list of all image names in the directory
img = glob.glob(images + '*.jpg')
train_path = '/kaggle/input/flickr8k/flickr_data/Flickr_Data/Flickr_TextData/Flickr_8k.trainImages.txt'
train_images = open(train_path, 'r', encoding = 'utf-8').read().split("\n")
train_img = [] # list of all images in training set
for im in img:
if(im[len(images):] in train_images):
train_img.append(im)
# load descriptions of training set in a dictionary. Name of the image will act as ey
def load_clean_descriptions(des, dataset):
dataset_des = dict()
for key, des_list in des.items():
if key+'.jpg' in dataset:
if key not in dataset_des:
dataset_des[key] = list()
for line in des_list:
desc = 'startseq ' + line + ' endseq'
dataset_des[key].append(desc)
return dataset_des
train_descriptions = load_clean_descriptions(descriptions, train_images)
print(train_descriptions['1000268201_693b08cb0e'])
Ta có output đầu ra
['startseq child in pink dress is climbing up set of stairs in an entry way endseq', 'startseq girl going into wooden building endseq', 'startseq little girl climbing into wooden playhouse endseq', 'startseq little girl climbing the stairs to her playhouse endseq', 'startseq little girl in pink dress going into wooden cabin endseq']
Step 6: Extract the feature vector from all images
Bây giờ chúng ta sẽ cung cấp một hình ảnh làm đầu vào cho mô hình của mình nhưng không giống như con người, máy móc không thể hiểu hình ảnh bằng cách nhìn thấy chúng. Vì vậy chúng ta cần chuyển hình ảnh thành một bảng mã để máy có thể hiểu được các mẫu trong đó. Mình sử dụng mô hình InceptionV3 đã được trainining về tập dữ liệu Imagenet có 1000 lớp khác nhau để phân loại. Bạn hoàn toàn có thể sử dụng các backbond khác nhé. Chúng ta cần loại bỏ lớp phân loại cuối cùng để lấy vector đặc trưng chiều (2048,) từ mô hình InceptionV3.
from keras.preprocessing.image import load_img, img_to_array
def preprocess_img(img_path):
# inception v3 excepts img in 299 * 299 * 3
img = load_img(img_path, target_size = (299, 299))
x = img_to_array(img)
# Add one more dimension
x = np.expand_dims(x, axis = 0)
x = preprocess_input(x)
return x
def encode(image):
image = preprocess_img(image)
vec = model.predict(image)
vec = np.reshape(vec, (vec.shape[1]))
return vec
base_model = InceptionV3(weights = 'imagenet')
model = Model(base_model.input, base_model.layers[-2].output)
# run the encode function on all train images and store the feature vectors in a list
encoding_train = {}
for img in train_img:
encoding_train[img[len(images):]] = encode(img)
Step 7: Tokenizing the vocabulary
all_train_captions = []
for key, val in train_descriptions.items():
for caption in val:
all_train_captions.append(caption)
# consider only words which occur atleast 10 times
vocabulary = vocab
threshold = 10 # you can change this value according to your need
word_counts = {}
for cap in all_train_captions:
for word in cap.split(' '):
word_counts[word] = word_counts.get(word, 0) + 1
vocab = [word for word in word_counts if word_counts[word] >= threshold]
# word mapping to integers
ixtoword = {}
wordtoix = {}
ix = 1
for word in vocab:
wordtoix[word] = ix
ixtoword[ix] = word
ix += 1
# find the maximum length of a description in a dataset
max_length = max(len(des.split()) for des in all_train_captions)
max_length
Step 8: Glove vector embeddings
all_train_captions = []
for key, val in train_descriptions.items():
for caption in val:
all_train_captions.append(caption)
vocabulary = vocab
threshold = 10
word_counts = {}
for cap in all_train_captions:
for word in cap.split(' '):
word_counts[word] = word_counts.get(word, 0) + 1
vocab = [word for word in word_counts if word_counts[word] >= threshold]
ixtoword = {}
wordtoix = {}
ix = 1
for word in vocab:
wordtoix[word] = ix
ixtoword[ix] = word
ix += 1
# find the maximum length of a description in a dataset
max_length = max(len(des.split()) for des in all_train_captions)
max_length
Step 9: Define the model
# define the model
ip1 = Input(shape = (2048, ))
fe1 = Dropout(0.2)(ip1)
fe2 = Dense(256, activation = 'relu')(fe1)
ip2 = Input(shape = (max_length, ))
se1 = Embedding(vocab_size, emb_dim, mask_zero = True)(ip2)
se2 = Dropout(0.2)(se1)
se3 = LSTM(256)(se2)
decoder1 = add([fe2, se3])
decoder2 = Dense(256, activation = 'relu')(decoder1)
outputs = Dense(vocab_size, activation = 'softmax')(decoder2)
model = Model(inputs = [ip1, ip2], outputs = outputs)
Mô hình bao gồm 2 đầu vào 1 cho text, 1 cho image sau đó sẽ được concate lại
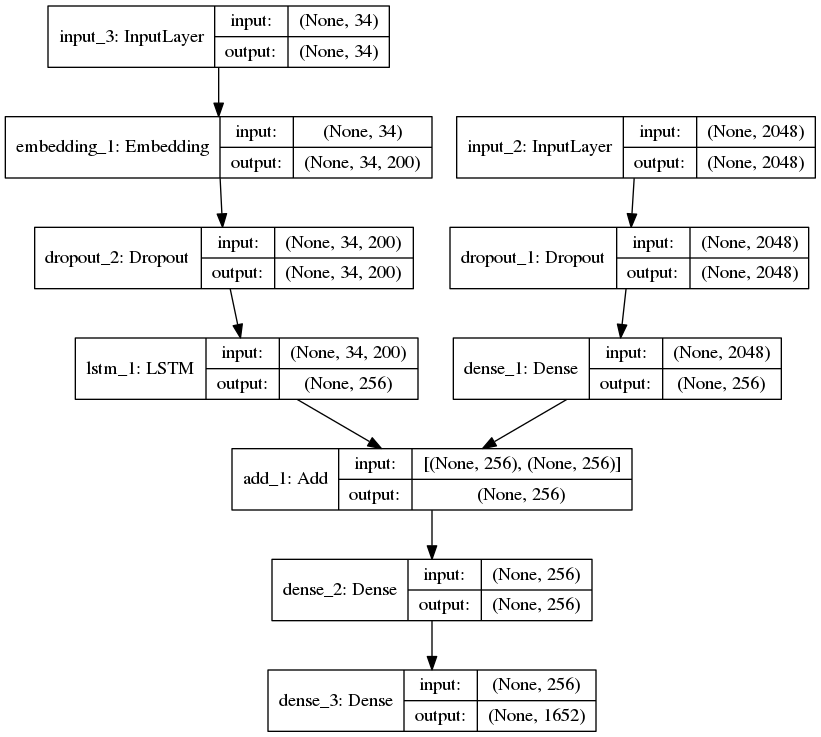
Step 10: Training model
model.layers[2].set_weights([emb_matrix])
model.layers[2].trainable = False
model.compile(loss = 'categorical_crossentropy', optimizer = 'adam')
model.fit([X1, X2], y, epochs = 50, batch_size = 256)
Step 11: Predicting the output
def greedy_search(pic):
start = 'startseq'
for i in range(max_length):
seq = [wordtoix[word] for word in start.split() if word in wordtoix]
seq = pad_sequences([seq], maxlen = max_length)
yhat = model.predict([pic, seq])
yhat = np.argmax(yhat)
word = ixtoword[yhat]
start += ' ' + word
if word == 'endseq':
break
final = start.split()
final = final[1:-1]
final = ' '.join(final)
return final

V . Conclusion
Bài viết của mình tới đây là kết thúc. Cảm ơn các bạn đã theo dõi bài viết của mình. Hi vọng qua bài viết sẽ giúp các bạn có thể tiếp cận với chủ đề dễ dàng hơn và từ đó có thể cải thiện và áp dụng trong công việc. Nếu thấy bài viết hay xin để lại cho mình xin 1 upvote nhé. Cảm ơn các bạn.
VI. Tài liệu tham khảo
All rights reserved
