[GPU in AI] Bài 11: Mixed Precision Phần 2
Ở phần này mình sẽ dùng mixed precision bằng Lightning Fabric cũng như 1 số lưu ý khi dùng Fabric
Mixed Precision Phần 2
Đối với Pytorch truyền thống thì để dùng mixed precision phải thay đổi 1 số thứ:
from torch.amp import autocast, GradScaler
scaler = GradScaler()
with autocast("cuda"):
output = model(x)
loss = criterion(output,y)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
Còn đối với Fabric thì sẽ được tự động xử lý mà chúng ta gần như không cần thay đổi code trong quá trình forward của model.
fabric = Fabric(accelerator="cuda", precision="16-mixed") # 16-true
fabric.launch()
with fabric.init_module():
model = MyModel()
model = fabric.setup(model)
...
# Forward sẽ tự động dùng mixed precision
output = model.forward(input)
# Lưu ý là loss ở đây sẽ không dùng mixed precision
loss = loss_function(output, target)
Đoạn code này ở bài 8 mà mình đã đề cập trước nên ở đây mình sẽ bỏ qua phần giải thích. Ở đây chúng ta chỉ thay đổi từ 16-true thành 16-mixed là xong.
Vì trong PyTorch đã có cơ chế loss scaling để đảm bảo quá trình chuyển đổi giữa float16 và float32 luôn ổn định, nên việc tính loss bằng mixed precision hay không gần như không ảnh hưởng kết quả. Tuy nhiên nếu các bạn vẫn muốn dùng float16 cho loss thì đây là code
with fabric.autocast():
loss = loss_function(output, target)
Đây là các precision khác có thể dùng ở Fabric
# Đây là mặc định
fabric = Fabric(precision="32-true")
# Cũng là FP32
fabric = Fabric(precision=32)
# Cũng là FP32
fabric = Fabric(precision="32")
# Mixed precision Float16
fabric = Fabric(precision="16-mixed")
# Float16 hoàn toàn
fabric = Fabric(precision="16-true")
# Mixed precision BFloat16 (GPU Volta trở lên)
fabric = Fabric(precision="bf16-mixed")
# BFloat16 hoàn toàn (GPU Volta trở lên)
fabric = Fabric(precision="bf16-true")
# Mixed precision 8-bit qua TransformerEngine (GPU Hopper trở lên)
fabric = Fabric(precision="transformer-engine")
# Double precision
fabric = Fabric(precision="64-true")
# Cũng là Double precision
fabric = Fabric(precision="64")
# Cũng là Double precision
fabric = Fabric(precision=64)
Lưu ý: bfloat16 và transformer-engine đòi hỏi GPU đời mới nên nếu các bạn ép dùng nhưng GPU không đáp ứng sẽ dẫn tới performance chậm hơn hoặc bị lỗi
===== 16-mixed =====
Seed set to 42
Train Acc: 38.87%
Test Acc : 46.15%
Time : 987.84s
Memory : 5603.31 MB
===== bf16-mixed =====
Seed set to 42
Train Acc: 42.05%
Test Acc : 46.14%
Time : 4992.44s
Memory : 7415.20 MB
===== 32-true =====
Train Acc: 40.74%
Test Acc : 47.37%
Time : 3692.28s
Memory : 8805.79 MB
Như các bạn có thể thấy ở đây mình dùng GPU T4 trên Kaggle và kết quả của bfloat16 thua xa so với float32 về time và memory gần như bằng lun. Lý do là vì GPU T4 của Kaggle không hỗ trợ cho bfloat16.
Lưu ý là dù các bạn có test bằng code như sau thì vẫn chưa đáng tin nha.
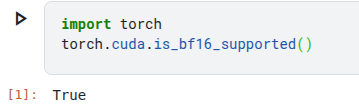
Làm sao để biết GPU phù hợp hay không thì mình sẽ làm 1 bài riêng để nói
All rights reserved
