[GPU in AI] Bài 8: Khởi tạo model 1 cách tối ưu
Ở bài viết này mình sẽ cho các bạn thấy sức mạnh của Lightning Fabric thông qua việc khởi tạo model so với Pytorch theo cách phổ thông
Khởi tạo model 1 cách tối ưu
Với cách khởi tạo model 1 cách thông thường bằng Pytorch sẽ như vây;
model = MyModel()
model.to(torch.device("cuda")).to(torch.float16)
Ở đây sẽ có 2 vấn đề:
- Tốc độ: vì model sẽ được khởi tạo ở CPU nên model càng nặng thì việc copy từ CPU sang GPU sẽ càng lâu ( do vấn đề bottleneck ) - ở đây khi khởi tạo model trên CPU thì pytorch sẽ dùng float32 ( default ) nên khi cast về float16 sẽ tốn thêm thời gian
- Bộ nhớ: vì model ban đầu được khởi tạo là float32 nên khi copy qua GPU thì peak GPU memory sẽ là float32 ==> model càng lớn thì có khả năng OOM ( out of memory )
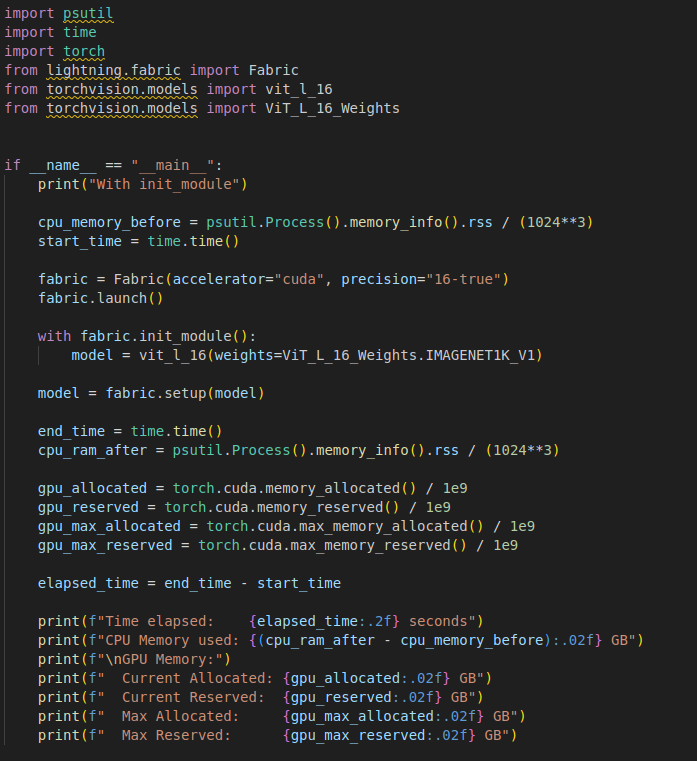
còn đây là khi dùng Lightning Fabric:
fabric = Fabric(accelerator="cuda", precision="16-true")
fabric.launch()
with fabric.init_module():
model = MyModel()
model = fabric.setup(model)
Ở đây đoạn code của chúng ta đã giải quyết 2 vấn đề:
- Tốc độ: model sẽ được khởi tạo trực tiếp trên GPU ( mà không cần phải copy từ CPU sang ) - Model sẽ sử dụng sẵn half-precision mà không cần phải tốn thời gian cast về
- Bộ nhớ: vì model được khởi tạo là half-precision nên peak GPU memory sẽ là half-precision
Demo
Ở đây mình sẽ demo bằng model vit_l_16 với các benchmark là:
- time: thời gian từ lúc khởi tạo model cho tới khi copy qua GPU
- memory: ở đây mình sẽ đo 4 chỉ số: Current Allocated - Current Reserved - Max Allocated - Max Reserved
Hiện tại bạn chỉ cần quan tâm đến current là đủ rồi, còn cụ thể 4 chỉ số này là gì mình sẽ giải thích cụ thể hơn ở bài: GPU memory hoạt động trong PyTorch.
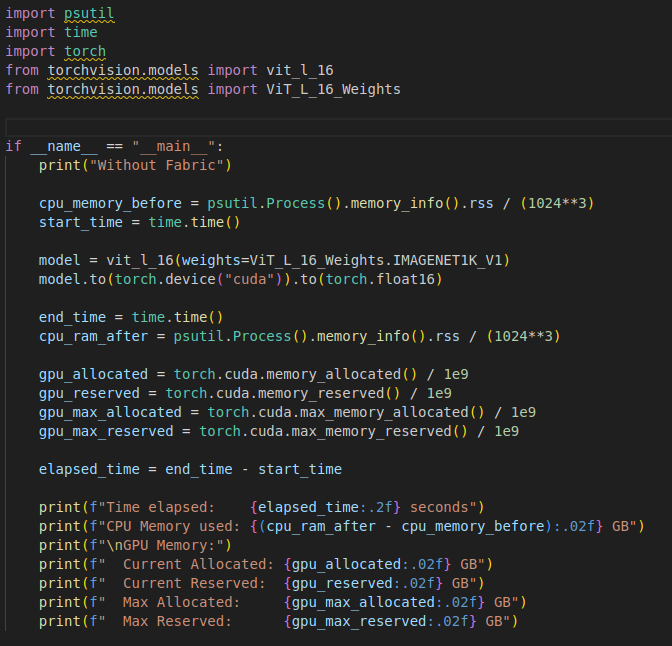
Pytorch
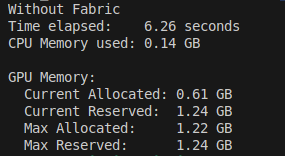
Lightning Fabric

All rights reserved
