Góc nhìn tổng quan về bài toán Blind Image Super-Resolution
Bài đăng này đã không được cập nhật trong 2 năm
Blind image super-resolution (hay siêu phân giải mù), là bài toán nhằm siêu phân giải hình ảnh chất lượng thấp với degradation chưa biết, đã thu hút sự chú ý do tầm quan trọng trong việc phát triển các ứng dụng trong thế giới thực. Nhiều giải pháp mới và hiệu quả đã được đề xuất gần đây, đặc biệt là với các kỹ thuật sử dụng deeplearning như Transformer, GAN, Diffusion model, .... Tuy nhiên, bất chấp nhiều năm nỗ lực, nó vẫn là một vấn đề nghiên cứu đầy thách thức khi áp dụng vào trong các tình huống thực tế.
Vì vậy, để dễ hình dung, mình sẽ đưa ra bức tranh toàn cảnh về các tiến bộ gần đây trong blind image SR, các hướng nghiên cứu hiện có cũng như những khó khăn mà nó gặp phải và cả những nghiên cứu mới đáng để khám phá trong tương lai. Phân loại các phương pháp hiện nay thành ba loại khác nhau theo degradation modelling và dữ liệu được sử dụng. Từ đó, khi áp dụng vào một bài toán thực tế, ta sẽ biết mình cần làm gì và đi theo hướng tiếp cận nào?
Trước khi đi vào các phần chính, ta cần giải thích một số thuật ngữ được sử dụng:
-
HR: high resolution (hình ảnh chất lượng cao)
-
LR: low resolution (hình ảnh chất lượng thấp)
-
Quá trình degradation : là quá trình biến đổi từ hình ảnh HR thành hình ảnh LR. (Ví dụ, một quá trình là khi bạn chụp ảnh, sau đó gửi qua facebook, sau đó bạn lưu về dưới file .jpg, ... )
-
Degradation modelling : Hầu hết các mô hình hiện nay đều theo hướng tiếp cận học có giám sát, yêu cầu sử dụng thông tin cơ bản (tức là cần cặp HR-LR tương ứng). Tuy nhiên, trong thực tế sẽ khá khó để thu thập được cặp ảnh như vậy với số lượng lớn, hoặc nếu có thì cũng khá khó để mô hình học được phân phối của tập dữ liệu do hình ảnh LR có độ da dạng rất lớn. Vì thế, người ta đã áp dụng mô hình degradation để sinh hình ảnh LR từ hình ảnh HR, mô hình như thế cần đảm bảo có phân phối gần giống với phân phối trong dữ liệu thực tế nhất mà vẫn đảm bảo được độ chính xác.
-
Classic Degradation modelling: Mô hình degradation "cổ điển" được sử dụng phổ biến nhất, xem xét việc lấy mẫu xuống (down-sampling), mờ (blurring) và nhiễu (noise). Công thức tổng quát sẽ là . Trong đó, biểu thị phép toán tích chập, là kernel (thường là gaussian blurring kernel), biểu thị nhiễu (noise) và là phép toán lấy mẫu xuống với hệ số tỷ lệ
-
Non-Blind image super-resolution : khi bạn biết được cụ thể quá trình degradation.
-
Blind image super-resolution : là bài toán khi bạn không thể xác định được quá trình degradation.
1. KHÓ KHĂN KHI ÁP DỤNG TRONG HÌNH ẢNH THỰC TẾ

Hình 1: Hình ảnh trong thế giới thực (hoặc khung hình video) được chụp bằng các thiết bị khác nhau. Hình ảnh được lấy từ bộ dữ liệu DPED, VIRAT, UCFCrime.
Với sự phát triển của các thiết bị hình ảnh hiện đại, chúng ta hiện đang đón nhận với sự gia tăng dữ liệu hình ảnh. Nhiều nguồn hình ảnh như vậy cũng đặt ra nhiều thách thức hơn, đặc biệt là về các quy trình degradation. Tuy nhiên, có ba yếu tố chính gây ra degradations khác nhau:
- Thiết bị hình ảnh khác nhau: Thời đại công nghệ này đã cho ra đời hàng loạt máy ảnh kỹ thuật số, chưa kể đến vô vàn chiếc điện thoại thông minh với hệ thống camera tiên tiến. Tuy nhiên, các thiết bị này khác nhau rất nhiều về đặc điểm của các bức ảnh được chụp. Ví dụ: máy ảnh DSLR (digital single-lens reflex) có thể chụp ảnh chất lượng cao với điều chỉnh độ dài tiêu cự của nó, trong khi máy ảnh trên điện thoại thông minh không đạt chất lượng bằng máy ảnh DSLR, có máy lại tạo ra hình ảnh nhiễu do những hạn chế vật lý về kích thước cảm biến và ống kính. Một số khác cũng sinh hình ảnh chất lượng thấp như video giám sát, thường bị mất nét rất nhiều. Độc giả có thể xem Hình 4 để biết một số ví dụ về hình ảnh. Do đó, hình ảnh được chụp bằng các thiết bị khác nhau có thể có quá trình degradation khác nhau.
- Các thuật toán xử lý ảnh: Vấn đề này chủ yếu liên quan đến máy ảnh kỹ thuật số và điện thoại thông minh. Quy trình xử lý thường bao gồm nhiều bước, chẳng hạn như hiệu chỉnh pixel, hiệu chỉnh cân bằng trắng, khử nhiễu và làm sắc nét. Trong quá trình này, có thể xảy ra hiện tượng degradation phức tạp, không thể đoán trước và có sự khác nhau giữa các thiết bị khác nhau.
- Degradations lên từ lưu trữ. Để giảm mức tiêu thụ tài nguyên cho việc truyền và lưu trữ dữ liệu, hình ảnh và video luôn được nén. Hình ảnh nén đi kèm với các artifact nén, điều này sẽ dẫn đến degradations như hiệu ứng mờ và khối. Ngoài ra, bản thân thời gian có thể làm xấu dần hình ảnh, đặc biệt là đối với ảnh cũ và phim được ghi trên phim. Degradations như vậy chủ yếu là do thiết bị chụp ảnh kém chất lượng hoặc sự oxi hóa trong không khí. Loại suy giảm này khó có thể được biểu thị bằng các phép toán rõ ràng hoặc được tìm thấy bởi một số bộ dữ liệu bên ngoài, do đó đòi hỏi nhiều nỗ lực hơn trong việc thiết kế các degradation modelling.
Tất cả các hình ảnh trong thế giới thực được thảo luận ở trên đều có những degradation và thách thức riêng. Tuy nhiên, công việc trước đây thường tập trung vào một loại hình ảnh thực duy nhất, chẳng hạn như hình ảnh được chụp bởi điện thoại thông minh, điều này hạn chế đáng kể hiệu suất của chúng trong các cảnh đa dạng.
2. PHÂN LOẠI
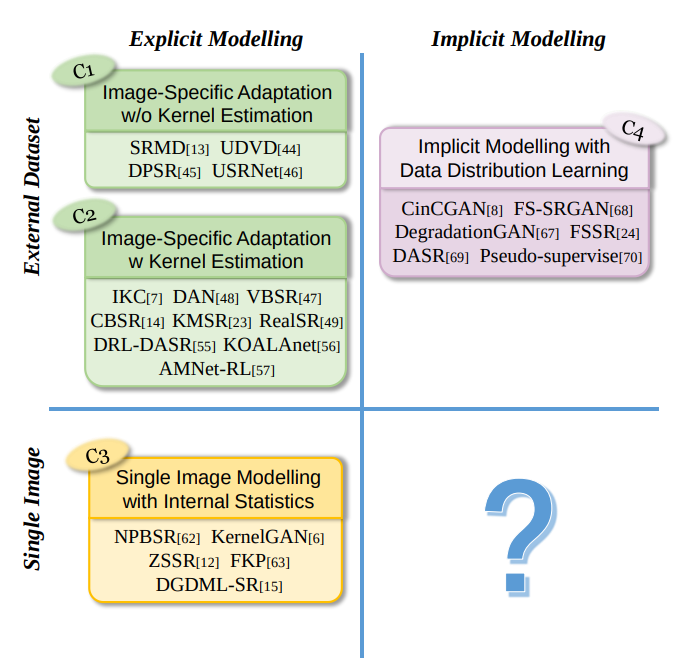
Hình 2: Phân loại các mô hình được đề xuất.
Trong phần này, mình sẽ giải thích chi tiết về phân loại được đề xuất để làm kim chỉ nam cho việc xem xét và phân tích sau này. Theo hình 2, đã có hai cách để mô hình hóa quá trình degradation liên quan đến blind SR: explicit modelling dựa trên mô hình degradation cổ điển hoặc các biến thể của nó và implicit modelling bằng cách sử dụng phân phối dữ liệu giữa các tập dữ liệu bên ngoài.
- Ý tưởng cơ bản của explicit modelling là tìm hiểu một mô hình SR với dữ liệu đào tạo bao gồm HR-LR với hình ảnh LR được sinh ra từ degradation modelling, thường được tham số hóa bằng các giá trị trong nhiễu, noise và mờ. Các phương pháp đại diện bao gồm KMSR, IKC và KMSR. Một nhóm phương pháp khác đề xuất khai thác số liệu thống kê nội bộ về lặp lại bản vá, như KernelGAN và ZSSR, có thể hoạt động trực tiếp trên một hình ảnh đầu vào duy nhất.
- Mặt khác, implicit modelling không phụ thuộc vào bất kỳ tham số hóa rõ ràng nào và chúng thường tìm hiểu mô hình SR thông qua phân phối dữ liệu. Trong số các phương pháp đó có CinCGAN và FSSR.
Như vậy, để phân loại hiệu quả các phương pháp tiếp cận hiện có là dựa theo mô hình degradation và dữ liệu được sử dụng để giải mô hình SR: explicit modelling hoặc implicit modelling, tập dữ liệu ngoài hoặc một hình ảnh đầu vào duy nhất, như trong Hình 2.
Ba lý do để áp dụng cách phân loại này: thứ nhất, việc phân biệt giữa explicit và implicit modelling giúp ta hiểu được giả định của một phương pháp nhất định, nghĩa là phương pháp này nhằm giải quyết loại degradation nào; thứ hai, cho dù sử dụng toàn bộ tập dữ liệu hay một hình ảnh đầu vào duy nhất cho biết thực tế có thể dùng loại nào, ta thu thập được đến đâu; cuối cùng, sau khi phân loại các cách tiếp cận hiện có thành các lớp này, một lỗ hổng nghiên cứu còn lại tự nhiên lộ ra - implicit modelling với một hình ảnh duy nhất. Đây là hướng có triển vọng trong việc giải quyết các hình ảnh chung của thế giới thực với nội dung đa dạng.
2.1 EXPLICIT DEGRADATION MODELLING
2.1.1 Explicit Degradation Model with External Dataset
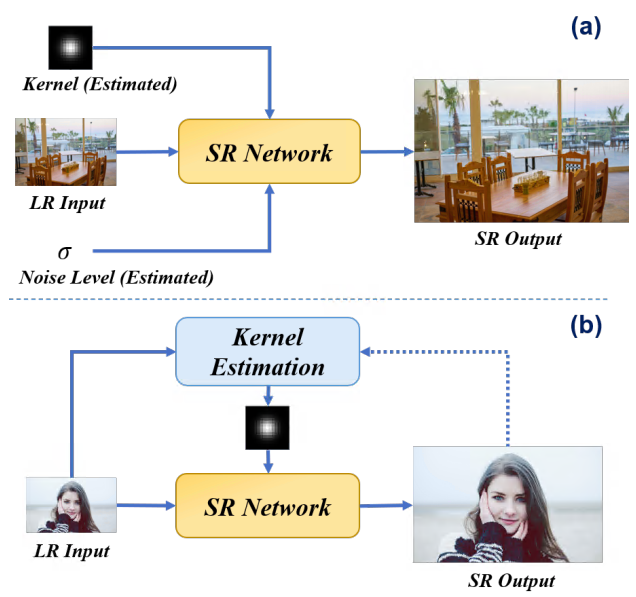
Hình 3: Khái quát hóa về mô hình hiện với toàn bộ tập dữ liệu.
Mô hình hiện với toàn bộ tập dữ liệu: Loại phương pháp tiếp cận này sử dụng tập dữ liệu training để đào tạo một mô hình SR thích nghi tốt với blur kernels và nhiễu . Thông thường, mô hình SR được tham số hóa bằng mạng thần kinh tích chập (CNN) và ước tính trên và cho một hình ảnh LR cụ thể được sử dụng làm đầu vào có điều kiện. Sau quá trình đào tạo, mô hình có thể tạo ra kết quả khả quan cho các đầu vào LR với các loại degradation được bao gồm trong tập dữ liệu đào tạo. Một minh họa về khung tổng thể của chúng được trình bày trong Hình.3.
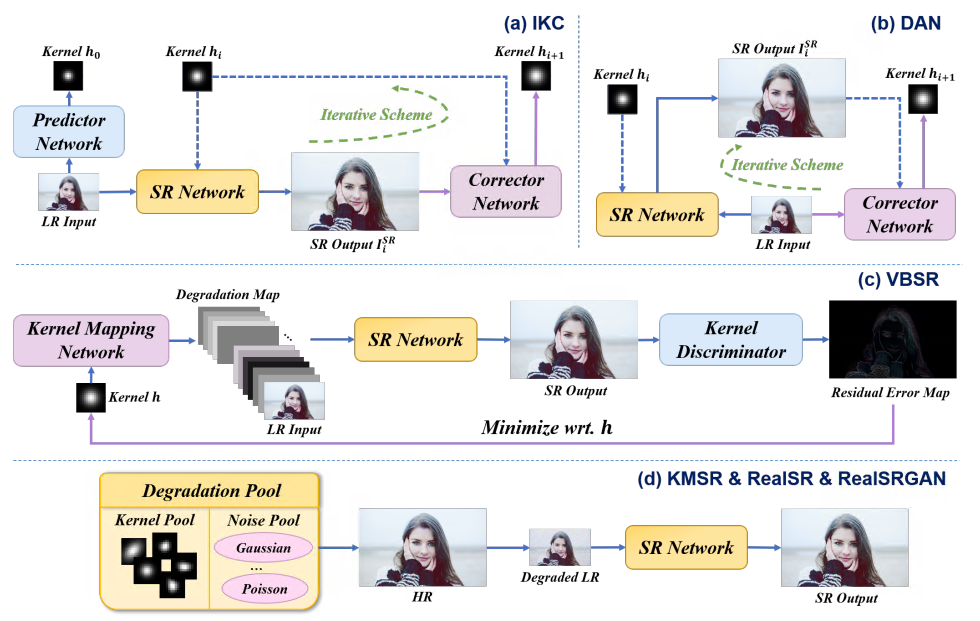
Hình 4: Ví dụ khung chi tiết của các phương pháp từ Image-Specific Adaptation with Kernel Estimation. (a) IKC; (b) ĐAN; (c) VBSR; (d) KMSR, RealSR và RealSRGAN.
Hạn chế: Bất chấp những tiến bộ gần đây, loại phương pháp này có một nhược điểm rõ ràng: tất cả chúng đều dựa vào đầu vào bổ sung là mô hình degradation. Tuy nhiên, việc ước tính và chính xác từ một ảnh LR tùy ý không phải là một bài toán dễ dàng và đầu vào ước tính không chính xác sẽ làm giảm đáng kể hiệu suất SR. Tuy nhiên, đây vẫn là dạng phổ biến và áp dụng trong thực tế nhiều nhất bởi sự dễ dàng tiếp cận của nó.
2.1.2 Explicit Degradation Model with Single Image
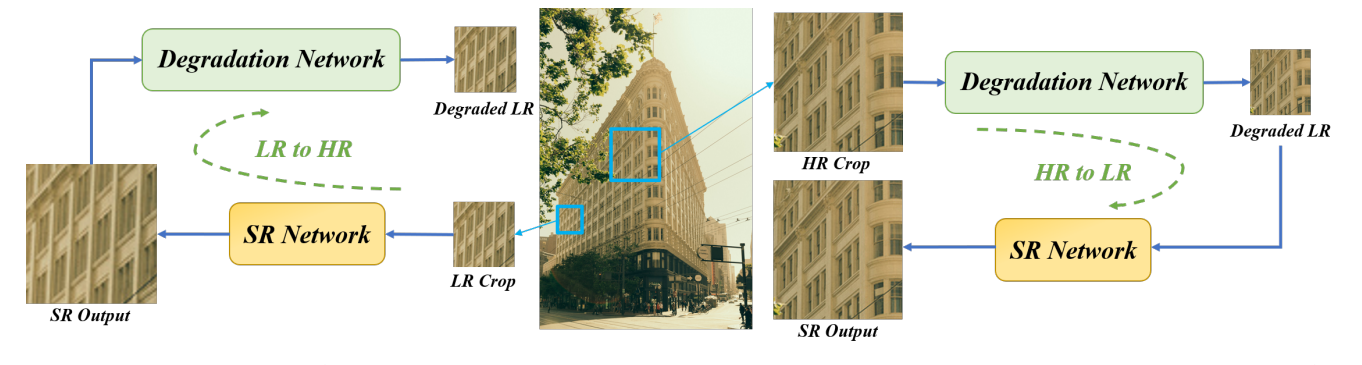
Hình 5: Kiến trúc mô hình của DGDML-SR. Hai đường dẫn training được bao gồm, tương ứng dựa trên HR và LR crops từ các thành phần của hình ảnh.
Mô hình SR với một hình ảnh duy nhất dựa trên chi tiết nội bộ của hình ảnh đó. Dạng này dựa trên một ý tưởng đó là: các thành phần của một hình ảnh có xu hướng lặp lại và trên các tỷ lệ khác nhau của chính hình ảnh đó. Điều này cũng đã được chứng minh trong [2].
Hạn chế: Ý tưởng tự học với chi tiết nội bộ của bức ảnh có vẻ hấp dẫn để giải quyết các ảnh SR từ LR với các loại degradation, vì nó không cần thu thập một tập dữ liệu đào tạo lớn. Tuy nhiên, ý tưởng giả định của nó có thể dễ dàng thất bại, đặc biệt là đối với các hình ảnh tự nhiên có nội dung đa dạng (ví dụ: động vật) hoặc các cảnh đơn điệu (ví dụ: bầu trời), vì khó khai thác thông tin định kỳ trên các tỷ lệ . Do đó, phương pháp này chỉ có thể tạo ra các hình ảnh HR xịn xò cho một tập hình ảnh rất hạn chế với nội dung trên ảnh lặp lại với các tỷ lệ.
Cho đến nay, ta đã có một cái nhìn tổng quan về phương pháp với explicit degradation modelling. Tổng kết lại thì phương pháp này sẽ cố gắng xây dựng một mô hình degradation từ nhiễu, mờ và down-sampling. Tuy những năm gần đây, việc cải thiên mô hình này đã đạt được những kết quả ấn tượng. Tuy nhiên, vẫn khá khó để biểu diễn cho những degradation phức tạp hơn ngoài 3 loại trên, ví dụ như degradation từ cảm biến máy ảnh. Trên thực tế, các hình ảnh trong thế giới thực thường bao gồm nhiều degradation và chúng ta khó có thể biểu thị các yếu tố này bằng một hàm được xác định rõ ràng. Do đó, một nhóm phương pháp khác đề xuất mô hình hóa học thông qua phân phối dữ liệu. Theo hiểu biết mình, cho đến nay chỉ có các cách tiếp cận dựa trên toàn bộ tập dữ liệu để lập mô hình và mình sẽ nói trong phần sau.
2.2 IMPLICIT DEGRADATION MODELLING
2.2.1 Implicit Degradation Model with External Dataset (Learning Data Distribution)
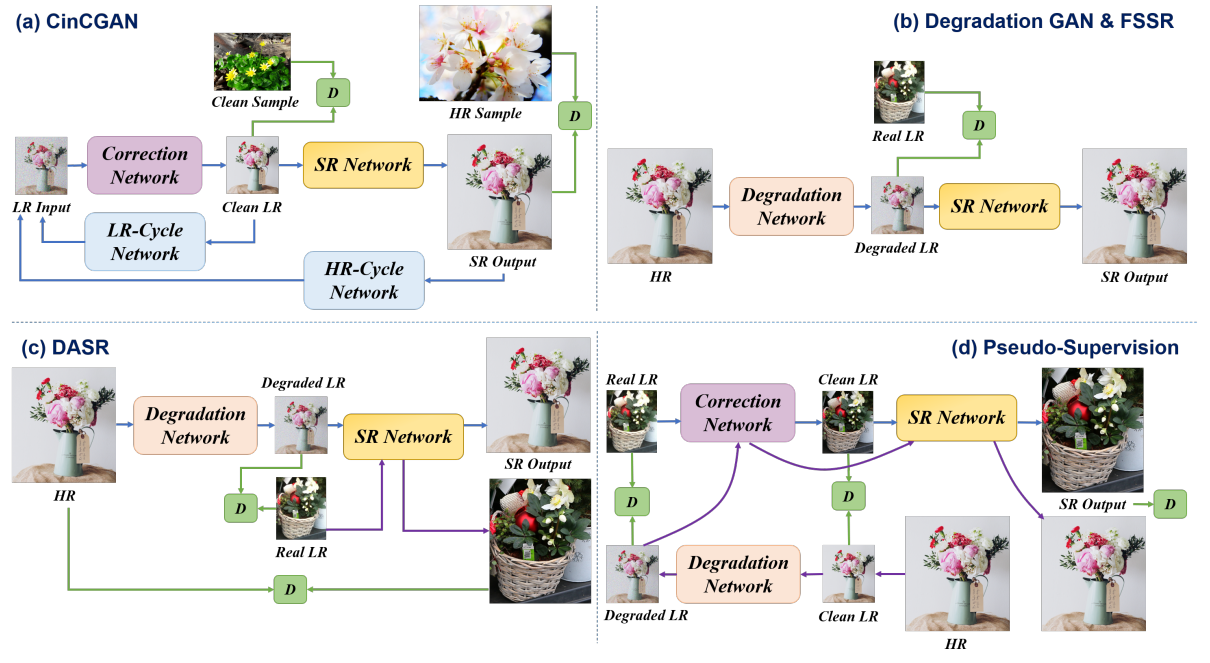
Hình 5: Kiến trúc tổng thể của các mô hình với implicit modelling để học phân phối dữ liệu. (a)CinCGAN; (b)Degradation GAN và FSSR, FS-SRGAN; (c)DASR; (d) pseudo-supervision
Loại phương pháp tiếp cận này nhằm mục đích nắm bắt hoàn toàn mô hình degradation thông qua việc học với phân phối dữ liệu training. Đối với tập dữ liệu có cặp hình ảnh HR-LR tương ứng, mô hình có thể đã đủ để đạt được kết quả khả quan. Tuy nhiên, một kiểu khó khăn hơn là tìm hiểu phân phối với dữ liệu không có cặp, nơi không có thông tin cơ bản về hình ảnh LR với degradations. Các phương pháp để giải quyết vấn đề này hiện tại thường khai thác việc học phân phối dữ liệu với khung GAN.
Hạn chế: Mặc dù có vẻ linh hoạt và mạnh mẽ, nhưng loại phương pháp này vẫn còn lâu mới là cứu cánh cho blind SR. Một mặt, các phương pháp này phải dựa vào các bộ dữ liệu lớn training để tìm hiểu mô hình SR thông qua học phân phối dữ liệu, nhưng cách thức ngốn dữ liệu này không phù hợp với một số bài toán nhất định, bao gồm cả khôi phục ảnh cũ. Mặt khác, hầu hết thực tế các bài toán đều khai thác khung GAN học phân phối dữ liệu không giám sát. Nên kết quả cho cũng không thực sự tốt.
2.2.2 Implicit Modelling with a Single Image: a Future Direction
Ý tưởng về implicit modelling dường như đầy hứa hẹn với các degradation phức tạp trong thế giới thực, miễn là cặp dữ liệu LR và HR được cung cấp đủ lớn. Tuy nhiên, vẫn còn một chặng đường dài phía trước vì các phương pháp hiện nay chủ yếu dựa vào khung GAN để học phân phối dữ liệu và artifacts do GAN gây ra có hại cho nhiều ứng dụng trong thế giới thực.
Như đã nêu trong các phần trước, tất cả các phương pháp tiếp cận hiện tại đều có những ưu điểm và hạn chế riêng, đặc biệt là đối với các trường hợp của phần 2.2.1. Các ví dụ về loại này bao gồm video giám sát, ảnh và phim cũ, ...Những hình ảnh này thường được nhìn thấy trong cuộc sống hàng ngày của chúng ta và chúng đặt ra những thách thức lớn đối với các phương pháp hiện có.
Vì vậy, ta có thể thấy rằng một hướng nghiên cứu mới đó là dựa trên implicit modelling với một hình ảnh đầu vào duy nhất. Cho đến nay, chưa có công trình nào liên quan đến lĩnh vực này, nhưng chúng tôi tin rằng đây là một hướng nghiên cứu đáng giá trong tương lai.
3. KẾT LUẬN
Trong bài viết này, mình đã trình bày về những tiến bộ gần đây trong blind image SR. Để phân loại và tóm tắt các phương pháp hiện có một cách hiệu quả, ta có thể chia theo degradation modelling và dữ liệu được sử dụng để giải mô hình SR: explicit or implicit modelling, toàn bộ dữ liệu hoặc một hình ảnh duy nhất. Ngoại trừ implicit modelling với một hình ảnh duy nhất, ba loại còn lại đều có các cách tiếp cận hiện có và ta có thể kết luận về chúng như sau:
- Explicit modelling with external dataset: đại diện là mô hình SRMD và IKC, sử dụng Classic Degradation modelling hoặc các biến thể của nó để điều chỉnh hình ảnh cụ thể dựa trên thông tin degradation. Các phương pháp này hoạt động tốt trên các loại degradation được bao hàm trong mô hình của nó, nhưng hiệu suất của chúng sẽ giảm sút nghiêm trọng đối với các loại degradation khác.
- Explicit modelling with a single LR image: đại diện là mô hình NPBSR và KernelGAN, ZSSR và DGDML-SR. Nó tận dụng thống kê nội bộ của chính hình ảnh đó. Tuy nhiên, các phương pháp này có thể cho kết quả kém đối với các hình ảnh có chi tiết đa dạng hoặc đơn điệu.
- Implicit modelling with external dataset: đại diện là mô hình CinCGAN, FSSR và DASR. Các phương pháp này giả định rằng các degradation trong thế giới thực quá phức tạp để được mô hình hóa một cách rõ ràng, nhưng có thể được học hoàn toàn với việc học phân phối dữ liệu trong khung GAN. Tuy nhiên, học phân phối là một nhiệm vụ không hề nhỏ do không gian rộng lớn của miền ảnh tự nhiên, khó huấn luyện một mô hình dựa trên GAN với hiệu năng tốt và khả năng tổng quát hóa cao.
Theo như những gì mình hiểu, implicit modelling with a single image, chưa được đề xuất, là một hướng đáng để khám phá trong nghiên cứu trong tương lai.
4. Tài liệu tham khảo
- Anran Liu, Yihao Liu, Jinjin Gu, Yu Qiao, Chao Dong. “Blind Image Super-Resolution: A Survey and Beyond”. 2021.
- M. Zontak and M. Irani, “Internal statistics of a single natural image,” in CVPR, 2011, pp. 977–984.
All rights reserved
