
GLiT: Neural Architecture Search for Global and Local Image Transformer
Bài đăng này đã không được cập nhật trong 3 năm
Mở đầu
Trong thời gian qua, các kiến trúc dựa trên Convolutional Neural Networks (CNN) đã và đang có những thành công đáng kể trong các tác vụ học sâu. Tiếp đó, được lấy cảm hứng từ thành công vượt trội của Transformer trong các tác vụ xử lý tự nhiên, một lượng lớn nghiên cứu được công bố trong thời gian qua đã và đang tập trung việc phát triển các kiến trúc hiệu quả hơn dựa trên Transformer mà một trong số đó có thể kể đến một đại diện tiêu biểu là Vision Transformer (ViT) vì nó không dựa vào các CNN-backbone để trích xuất các đặc trưng mà chỉ dựa vào các module self-attention của transformer để thiết lập mối tương quan toàn cục giữa các patch hình ảnh đầu vào. Trong khi đạt được hiệu suất ấn tượng, ViT vẫn có độ chính xác thấp hơn so với các mô hình CNN được thiết kế tốt như ResNet-101. Để khai thêm tiền năng của Transformer, mô hình DeiT sử dụng một số chiến lược chuyên sâu nhằm chắt lọc thông tin cho các transformer token. Tuy vậy, theo như nhóm tác giả nhận định, hai phương pháp này dựa trên kiến trúc Transformer ban đầu nhưng lại bỏ qua khoảng cách tiềm ẩn giữa các tác vụ xử lý ngôn ngữ và các tác vụ nhận dạng ảnh trong kiến trúc. Với vấn đề này, nhóm tác giả cho rằng có những điểm khác nhau khó xác định giữa các loại phương thức dữ liệu khác nhau (ví dụ: hình ảnh và văn bản), dẫn đến sự không đồng nhất giữa các tác vụ. Do đó việc áp dụng trực tiếp kiến trúc Transformer vào các tác vụ khác có thể chưa phải là phương pháp tối ưu nhất và có thể có những kiến trúc Transformer khác tốt hơn có thể sử dụng cho tác vụ nhận dạng ảnh. Tuy nhiên, việc tự tay thiết kế một công trình kiến trúc như vậy tốn nhiều thời gian vì có quá nhiều yếu tố ảnh hưởng cần được xem xét vậy nên ta cần xem xét đến một số các phương pháp khác tối ưu hơn mà một trong số đó là Neural Architecture Search.
Neural Architecture Search đã đạt được những tiến bộ vượt bậc trong các tác vụ thị giác máy tính dựa vào một số công bố như Neural optimizer search with reinforcement learning, Single Path One-Shot Neural Architecture Search with Uniform Sampling, DARTS: Differentiable Architecture Search khi nó có thể tự động khám phá một kiến trúc mạng tối ưu mà không cần thử thủ công. Tiếp đó, việc áp dụng NAS cho Transformer chưa được thử nghiệm và công bố ở trong các nghiên cứu trước đó và điều đó đã thúc đẩy nhóm tác giả đã thực hiện các thí nghiệm về việc ứng dụng NAS cho các mô hình Transformer. Chi tiết việc thí nghiệm và kết quả thu được sẽ được trình bày trong các phần dưới đây.
Phương pháp
Như mọi bài toán NAS khác, để đảm bảo việc sử dụng NAS với các mô hình Transformer diễn ra hiệu quả, ta cần có hai thứ bao gồm không gian tìm kiếm được thiết kế tốt chứa các ứng cử viên có hiệu suất tốt và thuật toán tìm kiếm hiệu quả để khám phá không gian tìm kiếm. Tuy vậy khi xem xét không gian tìm kiếm có sẵn chỉ chứa các tham số kiến trúc của mô hình Transformer chẳng hạn như số chiều của các vector query và value hay số head trong Mutli-Head Attention hoặc là số block Mutli-Head Attention, không gian này không xem xét đến hai yếu tố bao gồm: cơ chế self-attention tiêu tốn bộ nhớ bậc hai và gánh nặng tính toán với số lượng token đầu vào trong giai đoạn inference và thứ hai, các mô hình dựa trên Transformer khó tái diễn thông tin cục bộ trong hệ thống thị giác của con người khi mặc dù về mặt lý thuyết là có thể, nhưng khá khó có thể mô hình hóa các mối tương quan cục bộ thưa thớt bằng cơ chế self-attention gốc. Để giải quyết hai vấn đề đó, nhóm đã trình bày về một thiết kế mô hình mới được đặt tên là GLiT và phương pháp tìm kiếm mới được gọi là hierarchical neural architecture search. Chi tiết về chúng sẽ được trình bày trong các phần dưới đây.
Mô hình cơ sở
Khi xem xét các vấn đề được trình bày ở trên nhóm tác giả mở rộng không gian tìm kiếm của Transformer gốc bằng cách định nghĩa một local module cho Mutli-Head Attention với local modulechỉ hoạt động trên các token xung quanh, từ đó yêu cầu ít tham số và tính toán hơn. Nhằm phục vụ cho mục đích tìm kiếm, các local module và các self-attention module được thiết kế để có thể thay thế cho nhau và cách xây dựng mô hình từ chúng được NAS tìm kiếm để quyết định cái nào được sử dụng. Tiếp đó, nhóm tác giả đổi tên Mutli-Head Attention thành các global-local block vì chúng có thể nắm bắt cả mối tương quan toàn cục và cục bộ giữa các token đầu vào và sử dụng chúng để tìm kiếm kiến trúc mô hình tối ưu cho Global-Local (GL) transformer (GLiT) như được thể hiện ở hình dưới đây.

Tương tự như các mô hình dựa trên Transformer được sử dụng cho các tác vụ thị giác máy khác, GLiT nhận vào một chuỗi 1 chiều token embeddings. Vậy nên để có thể xử lý ảnh 2 chiều, ảnh đầu vào sẽ được chia thành nhiều patch và làm phẳng flatten từng patch thành token một chiều. Các đặc trưng của hình ảnh được biểu diễn bằng , trong đó c, w và h là số channel, chiều rộng và chiều cao của hình ảnh. Ta chia các đặc trưng F thành các mảng có kích thước m × m và làm phẳng mỗi mảng thành một biến một chiều và sau đó, được định dạng lại thành , bao gồm các input token. Cuối cùng, token (bao gồm token ở phần trước và một learnable class token - được thể hiện là token màu xanh lá ở ảnh dưới đây) sẽ được đưa vào mô hình và lớp đầu ra từ khối cuối cùng được gửi đến một classification head để có được kết quả cuối cùng. Để hình dung rõ hơn về cấu trúc của mô hình, ta sẽ cùng tìm hiểu về thành phần chính cấu tạo lên chúng - global-local block.
Global-local block
Dựa vào hình minh họa ở trên, ta có thể thấy các global-local block được cấu thành từ các global-local module (được thể hiện trong các box có viền xanh lá dạng dotted) và các Feed Forward Module. Phần này sẽ trình bày về hai thành phần chính trên, cũng như việc kết hợp chúng để được mô hình hoàn thiện.
Global-local module
global-local module được giới thiệu ở trên lại được cấu thành từ hai thành phần global sub-module và local sub-module như trong hình dưới đây:
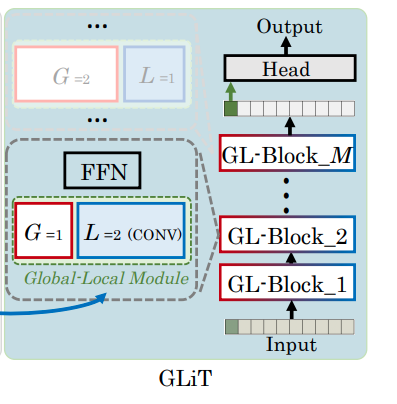
Trong đó, self-attention được sử dụng làm global sub-module: tất cả token sẽ được chuyển đổi tuyến tính thành các query , key và value với và là số chiều của vector đăc trưng của mỗi token trong query-key và value. Khi đó global attention được tính toán bằng cách:
Module này được sử dụng để tính toán các kết quả về attention bằng cách xem xét mối quan hệ giữa tất cả các mã thông báo đầu vào, vì vậy self-attention head này được đặt trên là global sub-module trong bài báo.
Và tất nhiên vì khi chỉ sử dụng các global sub-module, global-local module sẽ là Multi-Head Attention nên global sub-module sẽ tương đương với các head được tạo khi chia nhỏ các query, key and value thành N part. Kết quả tính toán của chúng theo công thức được đề cập ở trên sẽ được concat lại với nhau để trở thành kết quả cuối cùng.
TLDR: dùng head của Multi-Head Attention làm global sub-module.
Tiếp đó, convolution heads được sử dụng làm local sub-module: như được thể hiện trong hình dưới đây, một convolution head bao gồm ba convolutional layer, bao gồm hai point-wise convolutional layers với một 1D depth-wise convolutional layer giữa chúng và tất cả đều được theo sau bởi các lớp normalization, activation và các lớp dropout. Cụ thể hơn thì:
- Output của
point-wise convolutional layersẽ được chuyển vào lớpGlu activationcó tỷ lệexpandđểexpandkích thước đặc trưng lên lần. - Sau đó,
1D depth-wise convolutional layervới kích thướckernelkhông thay đổi kích thước đặc trưng. - Cuối cùng,
point-wise convolutional layercuối cùngprojectfeature dimensiontrở lạifeature dimensionđầu vào.
Để giải thích cho việc sử dụng lớp tích chập 1D thay vì lớp tích chập 2D trong các local sub-module, các tác giả cho rằng nó phù hợp hơn với chuỗi token đầu vào chỉ có 1 chìều. Bên cạnh đó, input token trong GLiT không thể được reshape thành mảng 2D.
TLDR: stack 3 convolutional layer lại làm local sub-module.
Cuối cùng, tạo Multi-head Global-Local Module: Với các global sub-module và local sub-module, câu hỏi tiếp theo là làm thế nào để kết hợp chúng. Phương pháp của nhóm tác giả là cách thay thế một số head trong Multi-Head Attention bằng các local sub-module. Để hình dung rõ hơn, ta có một số ví dụ như sau:
- Ví dụ: nếu có N = 3
headtrongMulti-Head Attention, chúng ta có thể giữ nguyên một đầuMulti-Head Attentionvà thay thế hai đầu bằnglocal sub-module. - Nếu tất cả các đầu trong
Multi-Head Attentionlàglobal sub-module, thìglobal sub-modulesẽ suy biến thànhtransformer blockđược sử dụng trongViTvàDeiT.
Trong global-local module, các key, query và value chỉ được tính cho các head là global sub-module. Đối với các head được thực hiện bởi local sub-module, các input được gửi trực tiếp đến các convolution layers.
TLDR: Thay thế các head thành các chuỗi convolution layers có chi phí tính toán nhỏ hơn trong quá trình tìm kiếm kiến trúc tối ưu.
Feed Forward Module
Ngoài global-local module, các đơn vị cấu thành mô hình còn có Feed Forward Module đuợc tạo nên từ một lớp Layer Normalization và hai fully-connected layer với lớp Swish activation và dropout layer được đặt giữa chúng. Với input , ta có Feed Forward Module được mô hình hóa bằng hàm như sau:
Trong đó:
- biểu thị
Layer Normalization - là hàm
Swish activation - và là trọng số của các
fully-connected layers, và $ b2 ∈ R^{d}$ là cácbias, và tương ứng là kích thước đặc trưng của đầu vào cho lớp đầu tiên và lớp lớp FC thứ hai.
Từ công thức trên, ta định nghĩa như một expansion ratio của FFN và sử dụng trong quá trình tìm kiếm.
Thuật toán tìm kiếm
Không gian tìm kiếm cho global-local block
Không gian tìm kiếm của global-local block được đề xuất bao gồm phân phối cấp cao của global-local sub-module và kiến trúc chi tiết cấp thấp của mỗi h sub-module. Ở cấp độ cao, ta hướng đến việc tìm kiếm sự phân bố của các convolution head (local sub-module) và các self-attention head (global sub-module) trên tất cả các global-local block. Ở cấp thấp, ta sẽ tập trung vào việc tìm kiếm kiến trúc chi tiết của tất cả các sub-module. Chi tiết về các giá trị sẽ cần tìm kiếm bao gồm:
- Cấp cao: số lượng
local sub-modulevàglobal sub-moduletrong mỗiblock, ký hiệu lần lượt làGvàL - Cấp thấp:
- Đối với
local sub-module:kernel sizeKvàexpansion ratioE - Đối với
global sub-module: số chiều của đặc trưng, được ký hiệu làd_k - Đối với
FFN:expansion ratiod_z
- Đối với
Với việc xác định không gian tìm kiếm như trên và với việc mỗi khối sẽ có các phân bố cấp cao khác nhau và kiến trúc chi tiết nên với một mô hình có M block thì số lượng kiến trúc trong không gian tìm kiếm sẽ là và nếu như số block là 12 cùng với mỗi tiêu chí tìm kiếm có 3 ứng cử viên thì số trường hợp cần xét sẽ xấp xỉ , gấp khoảng 1012 lần không gian tìm kiếm của DARTS và 1018 lần không gian tìm kiếm của SPOS. Để giải quyết vấn đề tìm kiếm trên không gian tìm kiếm khổng lồ này, nhóm tác giả đề xuất phương pháp Hierarchical Neural Architecture Search để có được kiến trúc mạng tối ưu với yêu cầu bộ nhớ phù hợp.
Hierarchical Neural Architecture Search
Được đề xuất trong bài báo, Hierarchical Neural Architecture Search hay Phương pháp Tìm kiếm kiến trúc thần kinh phân cấp bao gồm hai giai đoạn chính bao gồm: tìm kiếm phân phối tối ưu của các global sub-modules và local sub-module trong mỗi block và sau đó tìm kiếm kiến trúc chi tiết của cả mô-đun con toàn cục và cục bộ với phân phối đã được cố định.
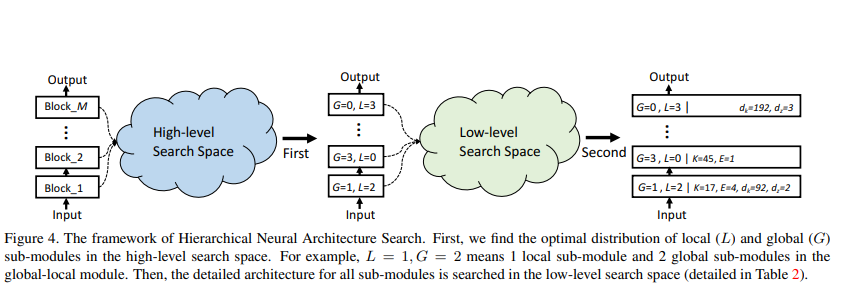
Giai đoạn 1: Tìm kiếm phân phối tối ưu : Ở giai đoạn đầu tiên, nhóm tác giả cố định các tham số cấu trúc chi tiết cấp thấp , , and và áp dụng phương pháp one-shot NAS có tên SPOSg để tìm kiếm sự phân phối tối ưu của các global sub-module và local sub-module từ không gian tìm kiếm . Việc áp dụng phương pháp này bao gồm 3 bước như sau:
- supernet training: Với mỗi lần lặp của
supernet training, ta thực hiện các bước như sau:- Chọn ngẫu nhiên một bộ indices
- Sử dụng indices đã chọn để sample ra một mạng nhỏ hơn, gọi là
subnet, trong đó số lượngglobal sub-modulevàlocal sub-moduletrong khốiMlà . - Huấn luyện
subnet
- subnet searching: sử dụng
Evolutionary Algorithmở bước tìm kiếm mạng con để tìm 5 kiến trúc tối ưu hàng đầu theo độ chính xác (Chi tiết về thuật toán này mọi người có thể đọc tại Single Path One-Shot Neural Architecture Search with Uniform Sampling). - subnet retraining: cuối cùng, ở bước
subnet retraining, ta train lại năm mạng và chọn kiến trúc có độ chính xác xác thực cao nhất làm mô hình đầu ra, nơi phân phối cácglobal sub-modulevàlocal sub-modulelà .
Giai đoạn 2: Tìm kiếm kiến trúc chi tiết : Sau khi có được sự phân phối tối ưu của các global-local module trong tất cả các block ở giai đoạn đầu, nhóm tác giả cải thiện phân phối này và tìm kiếm kiến trúc chi tiết của tất cả các module. Tương tự như giai đoạn đầu, nhóm tác giả áp dụng SPOS để tìm kiến trúc tối ưu trong không gian tìm kiếm. Sự khác biệt chính là không gian tìm kiếm được thay đổi và tương ứng chỉ mục ngẫu nhiên của một khối là một mảng có bốn phần tử là tương ứng với chỉ số của thay vì một số .
Về cơ bản, ta có thể thấy rằng phương pháp được đề xuất có hai ưu điểm chính:
- Đầu tiên, phương pháp được đề xuất chia không gian tìm kiếm ban đầu thành hai không gian tìm kiếm nhỏ hơn.
- Tiếp đó, kích thước của không gian tìm kiếm cấp thấp có thể được giảm thêm với phân phối cho các
global-local modulecố định.
Tuy vậy, khó có thể đảm bảo rằng phương pháp tìm kiếm trên hiệu quả nên nhóm tác giả đã thực hiện một số thí nghiệm và có kết quả thu được như phần dưới đây.
Kết quả thí nghiệm
Chuẩn bị
Với bộ dữ liệu ImageNet bao gồm 1.2 triệu ảnh train và 50 nghìn ảnh test, nhóm tác giả lấy 50 nghìn ảnh ra tạo tập train là thực hiện các thí nghiệm với GLiT trên GPU GTX 1080Ti với framework Pytorch (chắc có dụng ý gì đó chứ sao researcher này lại nghèo thế được :v). Quá trình thí nghiệm sample 1000 subnet dưới ràng buộc FLOPs. Với việc train lại các subnet, nhóm tác giả sử dụng cách cấu hình của DeiT.
Kết quả
Quá trình thử nghiệm cho ra kết quả là các mô hình đích được so sánh với hai kiến trúc CNN (ResNet và ResNeXt) và state-of-the-art vision transformer - DeiT.
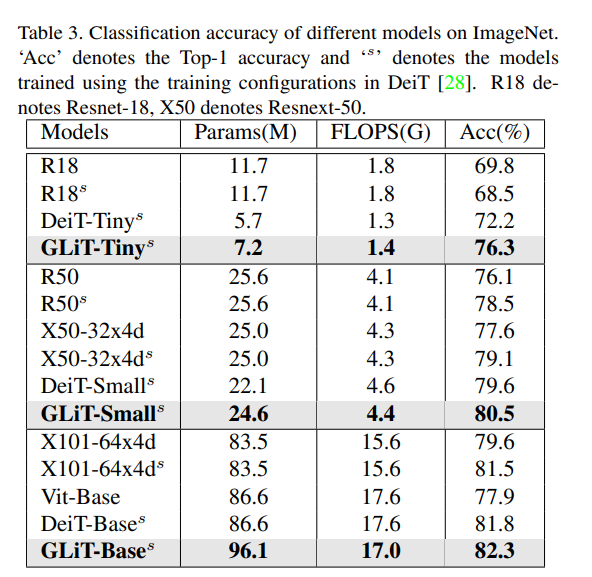
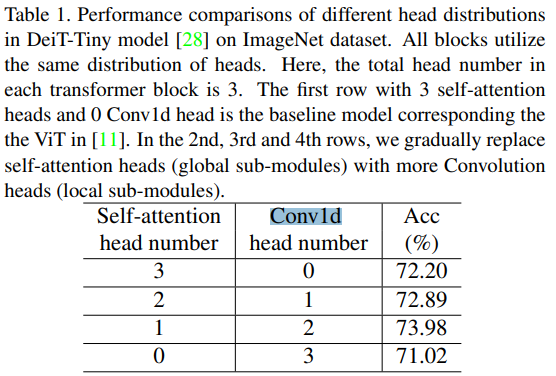
Kết quả cho thấy các mô hình của nhóm tác giả đạt được độ chính xác tốt hơn tất cả các mạng có mức FLOPS tương tự. Ví dụ: mô hình được tìm kiếm với giới hạn 1,3G FLOPS đạt được điểm chính xác 76,3%, cao hơn cả DeiT-Tiny và ResNet18. Việc xác định một cách hợp lý số các self-attention head và Conv1d head giúp làm tăng độ chính xác. Điều đó được thể hiện trong bảng dưới đây.
Một số các kết quả khác
Bên cạnh kết quả chính được trình bày ở trên, bài báo còn nói thêm về một số kết quả bổ sung có thể tóm tắt như sau:
- Áp dụng tìm kiếm cấp cao đã được trình bày ở trên với mô hình
DeiT-Tinyvà kết quả thu được cho thấy việc này có thể cải thiện được độ chính xác của mô hình này. Chi tiết có thể đọc tại Experiments > Ablation study > Searching Space. - So sánh phương pháp tìm kiếm được đề xuất với phương pháp NAS baseline (SPOS) và random search baseline với cùng không gian tìm kiếm đã được đề xuất. Kết quả cho thấy phương pháp được đề xuất hoạt động tốt hơn nhiều so với phương pháp SPOS và random search baseline. Chi tiết có thể đọc tại Experiments > Ablation study > Searching Method.
- So sánh việc sử dụng Conv1D để đưa thông tin cục bộ vào Vision Transformer với các phương pháp khác như
Local-areavàConv2d. Kết quả cho thấy Conv1D giải quyết vấn đề do thiếu sự tương tác giữa các khu vực cục bộ khác nhau tốt hơn nên có độ chính xác thu được cao hơn. Chi tiết có thể đọc tại Experiments > Ablation study > Methods to introduce locality.
Một số điểm cần chú ý
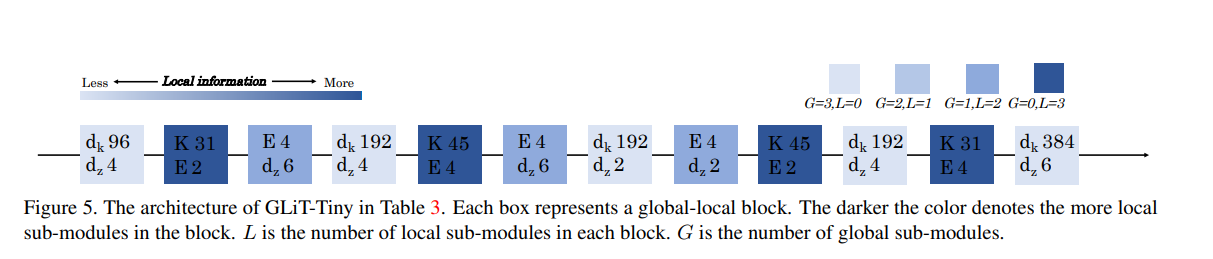
Dựa trên kết quả được thể hiện trong quá trình nghiên cứu và thí nghiệm, nhóm tác giả có các nhận định như sau:
- Chỉ có 25% khối bao gồm cả
global sub-modulevàlocal sub-module. Hầu hết cácblockđều chỉ chứaglobal sub-modulehoặclocal sub-module. - Không có lớp tích chập 1D với kích thước kernel 17 trong kiến trúc đã tìm kiếm trong khi đó 17 lại là giá trị nhỏ nhất của kích thước kernel trong không gian tìm kiếm. Nó cho thấy rằng kích thước kernel quá nhỏ không phù hợp với các
local sub-moduletrong các mô hình vision transformer. - Kiến trúc được tìm kiếm có xu hướng
global, đến hỗn hợplocal-global, và sau đó quay trở lại các khốilocal. Điều này giúp các đặc trưnglocalvàglobaltương tác thông qua các transformer block. Kiến trúc này trông giống như một cơ chế tương tự như đồng hồ cát xếp chồng trong Stacked Hourglass Networks for Human Pose Estimation, có các stack CNNlocal-global, trong đó thông tinlocaltương ứng với CNN với các đặc trưng có độ phân giải cao và tích chập 3 × 3 có cácreceptive fieldnhỏ hơn, trong khiglobaltương ứng với các đặc trưng của CNN với độ phân giải thấp hơn và tích chập 3 × 3 nhìn vào khu vực toàn cục hơn của cùng một hình ảnh.
Kết luận
Bài viết này trình bày về phương pháp khai thác kiến trúc tốt hơn cho các mô hình vision transformer được trình bày trong bài báo GLiT: Neural Architecture Search for Global and Local Image Transformer bằng cách định nghĩa một không gian tìm kiếm mới kèm một phương pháp tìm kiếm phân cấp nhằm giảm thiểu chi phí tính toán cũng như lưu trữ trong quá trình tìm kiếm (mặc dù ta chưa biết rõ rằng việc chia đôi đó có hiệu quả một cách tổng quát hay không khi có thể kết quả tối ưu cục bộ của từng bước có thể không mang lại kết quả tối ưu toàn cục - phần này vẫn không được nhóm tác giả đề cập đến trong bài báo - hoặc là tôi đọc thiếu). Tuy vậy, về cơ bản đây vẫn là một bài báo đáng đọc khi việc ứng Neural Architecture Search cho các mô hình transformer chưa có nhiều cho lắm các nghiên cứu có liên quan cũng như bản thân bài báo được trình bày một cách rõ ràng và đi kèm với kết quả khá ấn tượng. Như các bạn có thể thấy ở hình ảnh dưới đây, để hoàn thành bài viết này tôi đã phải google dịch gãy tay gõ đến mức bật cả keycap vậy nên còn đợi gì nữa mà không để lại một like và subscribe vì nó miễn phí.

Tài liệu tham khảo
- An Introduction to Neural Architecture Search for Convolutional Networks
- Neural Architecture Search
- The Transformer Family
- GLiT: Neural Architecture Search for Global and Local Image Transformer
- The Illustrated Transformer
- Single path one-shot neural architecture search with uniform sampling
- DARTS: Differentiable Architecture Search
All rights reserved
