Giới thiệu PyTorch: Có bột mới gột nên hồ

Trong loạt bài viết xây dựng mô hình ngôn ngữ lớn, PyTorch chính là công cụ quan trọng nhất được sử dụng. Tuy nhiên, chúng ta mới chỉ dừng ở mức sử dụng mà chưa có thời gian tìm hiểu kỹ hơn. Bài viết hôm nay bổ sung thiếu sót đó.
1. Làm quen với PyTorch
PyTorch là một thư viện deep learning nguồn mở dành cho Python. Được phát triển bởi Meta của anh Mark Xoăn.
Đối trọng lớn của PyTorch trên thị trường là Tensorflow phát triển bởi Google.
Đây được xem là 2 thư viện phổ biến nhất cho các nhà nghiên cứu và phát triển trí tuệ nhân tạo.
1.1. Các thành phần tạo nên PyTorch
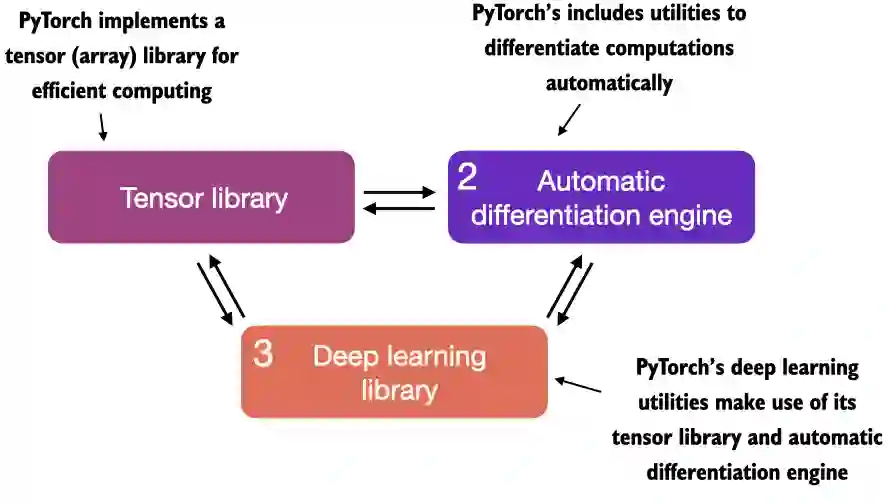
Có thể chia PyTorch ra làm 3 phần:
-
- Tensor libary: Có nhiệm vụ biểu diễn và xử lý dữ liệu. Với tensor library, dữ liệu sẽ được xử lý rất nhanh trên GPU.
-
- Automatic differentiation engine hay còn gọi là autograd: Chưa logic có nhiệm vụ tính toán, tối ưu trong quá trình huấn luyện.
-
- Deep learning libary: Chứa sẵn các mô-đun, công cụ về học sâu. Giúp người dùng gọi ra sử dụng 1 cách tiện lợi.
1.2 Cài đặt
Truy cập https://pytorch.org/get-started/locally/ để xem cách cài đặt PyTorch theo từng nền tảng.

Tôi thì chọn cách cài trên môi trường ảo với Anaconda cho đỡ rác máy.
# Linux x86
curl -O https://repo.anaconda.com/archive/Anaconda3-2024.10-1-Linux-x86_64.sh
chmod +x Anaconda3-2024.10-1-Linux-x86_64.sh
./Anaconda3-2024.10-1-Linux-x86_64.sh
conda init [bash/zsh/fish]
# Instal python
conda create -n myenv python=3.12
conda activate myenv
conda install pytorch::pytorch
Sau khi cài đặt xong, kiểm tra phiên bản trên console python
import torch
torch.__version__

PyTorch với Apple Silicon
Nếu bạn sở hữu máy Mac dùng chip Apple Silicon (như các mẫu M1, M2, M3 ...), thì có thể tăng tốc độ thực thi mã PyTorch thông qua Metal Performance Shaders - MPS.
Để kiểm tra xem máy Mac của bạn có hỗ trợ MPS không, dùng lệnh.
print(torch.backends.mps.is_available())
2. Tìm hiểu tensors
Tensors là một dạng biểu diễn Toán học tổng quát, được đặc trưng bởi rank (số chiều). Chúng là khái niệm mở rộng của scalars (vô hướng), vectors (vectơ), và matrices (ma trận).
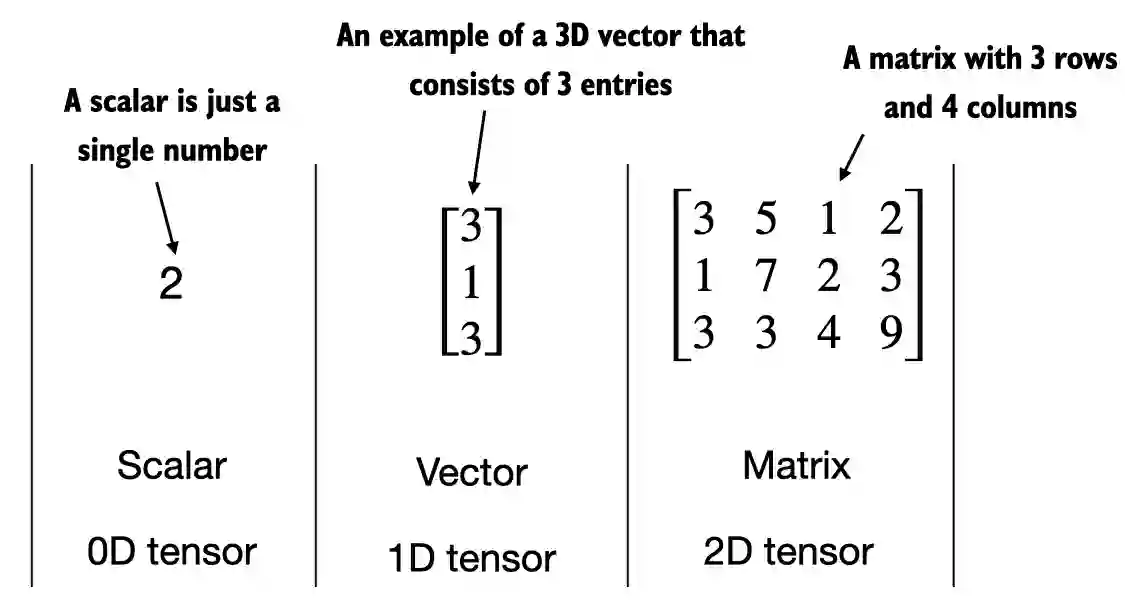
Trên ảnh:
- Số 2 là tensor 0 chiều
- Vectơ là tensor 1 chiều
- Ma trận là tensort 2 chiều.
Khi tính toán, tensor đóng vai trò chứa dữ liệu. Tựu chung lại thì tensor tương tự như mảng ở các ngôn ngữ lập trình.
Khởi tạo các tensor
import torch
import numpy as np
# 0D tensor
tensor0d = torch.tensor(1)
# 1D tensor
tensor1d = torch.tensor([1, 2, 3])
# 2D tensor
tensor2d = torch.tensor([[1, 2],
[3, 4]])
# 3D tensor
tensor3d_1 = torch.tensor([[[1, 2], [3, 4]],
[[5, 6], [7, 8]]])
# tạo 1 3D tensor from NumPy array
ary3d = np.array([[[1, 2], [3, 4]],
[[5, 6], [7, 8]]])
tensor3d_2 = torch.tensor(ary3d) # Copy từ numpy
Tensor PyTorch tương tự như các mảng NumPy nhưng có một số tính năng bổ sung như tăng tốc tính toán trên GPU ....
Các kiểu dữ liệu
Các kiểu dữ liệu của tensor cũng không khác so với các kiểu dữ liệu trong 1 ngôn ngữ lập trình. Xem tất cả các kiểu dữ liệu tại đây
int64 và float32 là 2 kiểu dữ liệu mặc định cho số nguyên và số thập phân.
tensor1d = torch.tensor([1, 2, 3])
print(tensor1d.dtype) # torch.int64
floatvec = torch.tensor([1.0, 2.0, 3.0])
print(floatvec.dtype) # torch.float32
Có thể thay đổi kiểu dữ liệu bằng cách
floatvec = tensor1d.to(torch.float32)
print(floatvec.dtype) # torch.float32
print(floatvec) # tensor([1., 2., 3.])
Các lệnh cơ bản thường dùng với tensor
- Lệnh tạo mới tensor
tensor2d = torch.tensor([[1, 2, 3],
[4, 5, 6]])
- Truy cập shape (kích thước) của tensor
tensor0d = torch.tensor(1)
# 1D tensor
tensor1d = torch.tensor([1, 2, 3])
# 2D tensor
tensor2d = torch.tensor([[1, 2, 3, 4, 5],
[6, 7, 8, 9, 10]])
# 3D tensor
tensor3d_1 = torch.tensor(
[
[
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]
],
[
[4, 3, 2, 1],
[8, 7, 6, 5],
[12, 11, 10, 9]
]
])
print(tensor0d.shape) # In ra: torch.Size([])
print(tensor1d.shape) # In ra: torch.Size([3])
print(tensor2d.shape) # In ra: torch.Size([2, 5])
print(tensor3d_1.shape) # In ra: torch.Size([2, 3, 4])
- Tensor 0D thì không có
shape - Tensor 1D thì thông số
shapebằng số phần tử - Tensor 2D thì có
shapebằng (số hàng, số cột) - Tensor 3D thì có 2 phần tử, mỗi phần từ có 3 hàng x 4 cột =>
torch.Size([2, 3, 4])
- Lệnh
reshape: Đổi thích kích tensor
tensor2d = torch.tensor([[1, 2, 3],
[4, 5, 6]])
print(tensor2d.reshape(3, 2))
"""
tensor([[1, 2],
[3, 4],
[5, 6]])
"""
Lệnh view cũng tương tự reshape. Chỉ khác nhau về cách chúng xử lý bộ nhớ:
viewyêu cần dữ liệu phải liên tục trên bộ nhớ, nếu ko sẽ trả về lỗireshapethì không cần
- Chuyển vị của tensor (transpose)
print(tensor2d.T)
"""
tensor([[1, 4],
[2, 5],
[3, 6]])
"""
< br />
- Nhân 2 tensor với nhau
print(tensor2d.matmul(tensor2d.T))
"""
tensor([[14, 32],
[32, 77]])
"""
Hoặc
print(tensor2d @ tensor2d.T)
3. Triển khai mạng nơ-ron đa lớp với PyTorch
Lý thuyết đủ rồi, giờ bắt tay vào code thôi. Phần này ta sẽ dùng PyTorch triển khai một mạng nơ-ron đa lớp gồm 2 lớp ẩn (hidden layer).
3.1 Khởi tạo mạng nơ-ron
Trước tiên cùng xem qua mạng nơ-ron có hình thù như thế nào qua hình minh hoạ dưới đây.
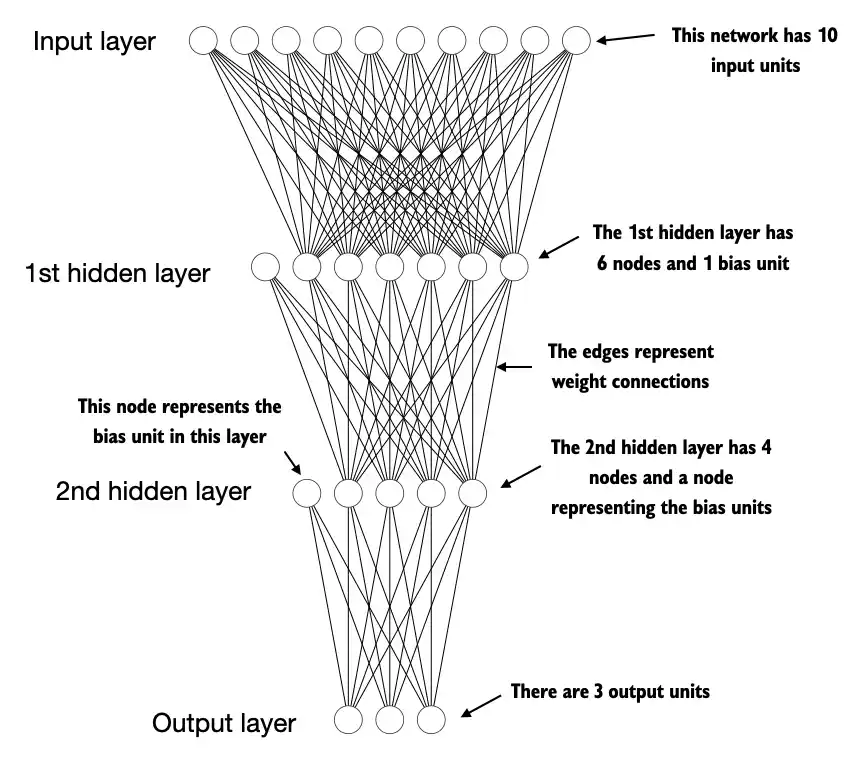
Mạng nơ-ron trên có thông số như sau:
- Đầu vào gồm 10 đơn vị (units).
- Lớp ẩn thứ nhất có 6 nodes và 1 bias unit. bias là một node đặc biệt luôn có giá trị 1.
- Lớp ẩn thứ hai có 4 node và 1 bias.
- Đầu ra co lại chỉ còn 3 đơn vị.
class NeuralNetwork(torch.nn.Module):
def __init__(self, num_inputs, num_outputs):
super().__init__()
# Sequential là một container cho phép bạn "xếp chồng" các lớp lại với nhau theo một cách tuần tự
self.layers = torch.nn.Sequential(
# hidden layer thứ nhất
# Một lớp có cả Linear và ReLU để học được các các đặc trưng tuyến tính và phi tuyến
torch.nn.Linear(num_inputs, 30),
torch.nn.ReLU(),
# hidden layer thứ hai
torch.nn.Linear(30, 20),
torch.nn.ReLU(),
# lớp đầu ra
torch.nn.Linear(20, num_outputs),
)
def forward(self, x):
logits = self.layers(x)
return logits
- Tạo mạng nơ-ron từ
class NeuralNetwork
# Đầu vào 50, nhiều gấp 5 lần hình minh hoạ
model = NeuralNetwork(50, 3)
print(model) # In ra thông số các lớp của mạng nơ-ron
"""
NeuralNetwork(
(layers): Sequential(
(0): Linear(in_features=50, out_features=30, bias=True)
(1): ReLU()
(2): Linear(in_features=30, out_features=20, bias=True)
(3): ReLU()
(4): Linear(in_features=20, out_features=3, bias=True)
)
)
"""
- Xem tổng số tham số của mạng là bao nhiêu ?
num_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print("Total number of trainable model parameters:", num_params)
# Total number of trainable model parameters: 2213
- Truyền đầu vào và xem đầu ra của mạng nơ-ron
# Dùng seed random giúp mô hình khi khởi tạo ở mỗi lần chạy đều có bộ tham số như nhau
torch.manual_seed(123)
X = torch.rand((1, 50))
# Đang ko huấn luyện nên dùng tuỳ chọn `no_grad` để code chạy nhanh hơn
with torch.no_grad():
out = model(X)
print(out)
# tensor([[-0.1262, 0.1080, -0.1792]], grad_fn=<AddmmBackward0>)
- Có thể chuẩn hoá thêm với
softmax
with torch.no_grad():
out = torch.softmax(model(X), dim=1)
print(out)
# tensor([[0.3113, 0.3934, 0.2952]])
3.2 DataLoader
PyTorch định nghĩa sẵn 2 class Dataset và DataLoader.
- Dataset được dùng để định nghĩa cách dữ liệu được nạp.
- DataLoader xử lý việc trộn dữ liệu (shuffle) và chia chúng thành các batch.
Ví dụ với Dataset:
# Giả dụ có 2 tập train và test như sau:
X_train = torch.tensor([
[-1.2, 3.1],
[-0.9, 2.9],
[-0.5, 2.6],
[2.3, -1.1],
[2.7, -1.5]
])
y_train = torch.tensor([0, 0, 0, 1, 1])
X_test = torch.tensor([
[-0.8, 2.8],
[2.6, -1.6],
])
y_test = torch.tensor([0, 1])
# Định nghĩa class ToyDataset nạp dữ liệu
# Một custom Dataset class phải triển khai 3 hàm: __init__, __len__, and __getitem__
class ToyDataset(Dataset):
def __init__(self, X, y):
self.features = X
self.labels = y
def __getitem__(self, index):
one_x = self.features[index]
one_y = self.labels[index]
return one_x, one_y
def __len__(self):
return self.labels.shape[0]
train_ds = ToyDataset(X_train, y_train)
test_ds = ToyDataset(X_test, y_test)
Thử in ra một số thuộc tính
print(train_ds.labels)
print(train_ds.__getitem__(0))
"""
tensor([0, 0, 0, 1, 1])
(tensor([-1.2000, 3.1000]), tensor(0))
"""
Ví dụ với DataLoader
Load dữ liệu xong với Dataset, tiến hành dùng DataLoader để chia dữ liệu thành các batch trước khi huấn luyện.
from torch.utils.data import DataLoader
torch.manual_seed(123)
train_loader = DataLoader(
dataset=train_ds,
batch_size=2, # Một batch có 2 dữ liệu đầu vào
shuffle=True, # Có xáo dữ liệu không ? Mặc định shuffle=false
num_workers=0 # sử dụng bao nhiêu tiến trình con để load dữ liệu
)
test_ds = ToyDataset(X_test, y_test)
test_loader = DataLoader(
dataset=test_ds,
batch_size=2,
shuffle=False,
num_workers=0
)
In thử ra train_loader
for idx, (x, y) in enumerate(train_loader):
print(f"Batch {idx+1}:", x, y)
"""
Batch 1: tensor([[-1.2000, 3.1000],
[-0.9000, 2.9000]]) tensor([0, 0])
Batch 2: tensor([[-0.5000, 2.6000],
[ 2.3000, -1.1000]]) tensor([0, 1])
Batch 3: tensor([[ 2.7000, -1.5000]]) tensor([1])
"""
3.3 Tiến hành huấn luyện
Mục đích là sau mỗi lần huấn luyện, giá trị mất mát giảm dần => tức là mô hình đang dự đoán đúng nhiều hơn.
import torch.nn.functional as F
torch.manual_seed(123)
model = NeuralNetwork(num_inputs=2, num_outputs=2) # 2 đầu vào và 2 đầu ra
optimizer = torch.optim.SGD(model.parameters(), lr=0.5)
num_epochs = 3 # Huấn luyện 3 chu kỳ
for epoch in range(num_epochs):
model.train()
for batch_idx, (features, labels) in enumerate(train_loader):
logits = model(features)
loss = F.cross_entropy(logits, labels) # Tính hàm mất mát (Loss function)
optimizer.zero_grad()
loss.backward()
optimizer.step()
### LOGGING
print(f"Epoch: {epoch+1:03d}/{num_epochs:03d}"
f" | Batch {batch_idx:03d}/{len(train_loader):03d}"
f" | Train/Val Loss: {loss:.2f}")
model.eval()
# Optional model evaluation
"""
Epoch: 001/003 | Batch 000/002 | Train/Val Loss: 0.75
Epoch: 001/003 | Batch 001/002 | Train/Val Loss: 0.65
Epoch: 002/003 | Batch 000/002 | Train/Val Loss: 0.44
Epoch: 002/003 | Batch 001/002 | Train/Val Loss: 0.13
Epoch: 003/003 | Batch 000/002 | Train/Val Loss: 0.03
Epoch: 003/003 | Batch 001/002 | Train/Val Loss: 0.00
"""
Lưu ý: Do dữ liệu mẫu của chúng ta đơn giản nên quá trình huấn luyện diễn ra nhanh và đạt kết quả tối ưu. Đạt kết quả Loss = 0 trong các bài toán thực tế là rất hiếm và thường không phải mục đích vì có thể xảy ra tình trạng overfit.
Xem độ chính xác của mô hình trên 2 tập train và val.
def compute_accuracy(model, dataloader):
model = model.eval()
correct = 0.0
total_examples = 0
for idx, (features, labels) in enumerate(dataloader):
with torch.no_grad():
logits = model(features)
predictions = torch.argmax(logits, dim=1)
compare = labels == predictions
correct += torch.sum(compare)
total_examples += len(compare)
return (correct / total_examples).item()
compute_accuracy(model, train_loader) # In ra: 1.0
compute_accuracy(model, test_loader) # In ra: 1.0
Đều đúng 100 % 😀
3.4 Lưu lại và load lại mô hình
Lưu lại mô hình
- Lưu vào file có đuôi
.pth
torch.save(model.state_dict(), "model.pth")
Load mô hình đã lưu
model = NeuralNetwork(2, 2) # Thông số phải khớp với mô hình đã lưu, nếu không báo lỗi
model.load_state_dict(torch.load("model.pth", weights_only=True))
4. Tối ưu hóa hiệu suất với GPU
4.1 PyTorch và vấn đề device
- Mặc định, các tensor được xử lý trên CPU
tensor_1 = torch.tensor([1., 2., 3.])
tensor_2 = torch.tensor([4., 5., 6.])
print(tensor_1 + tensor_2) # tensor([5., 7., 9.])
- Hàm
tođể chuyển tensor sang thiết bị khác (cụ thể ở đây là GPU)
tensor_1 = tensor_1.to("cuda")
tensor_2 = tensor_2.to("cuda")
print(tensor_1 + tensor_2) # tensor([5., 7., 9.], device='cuda:0')
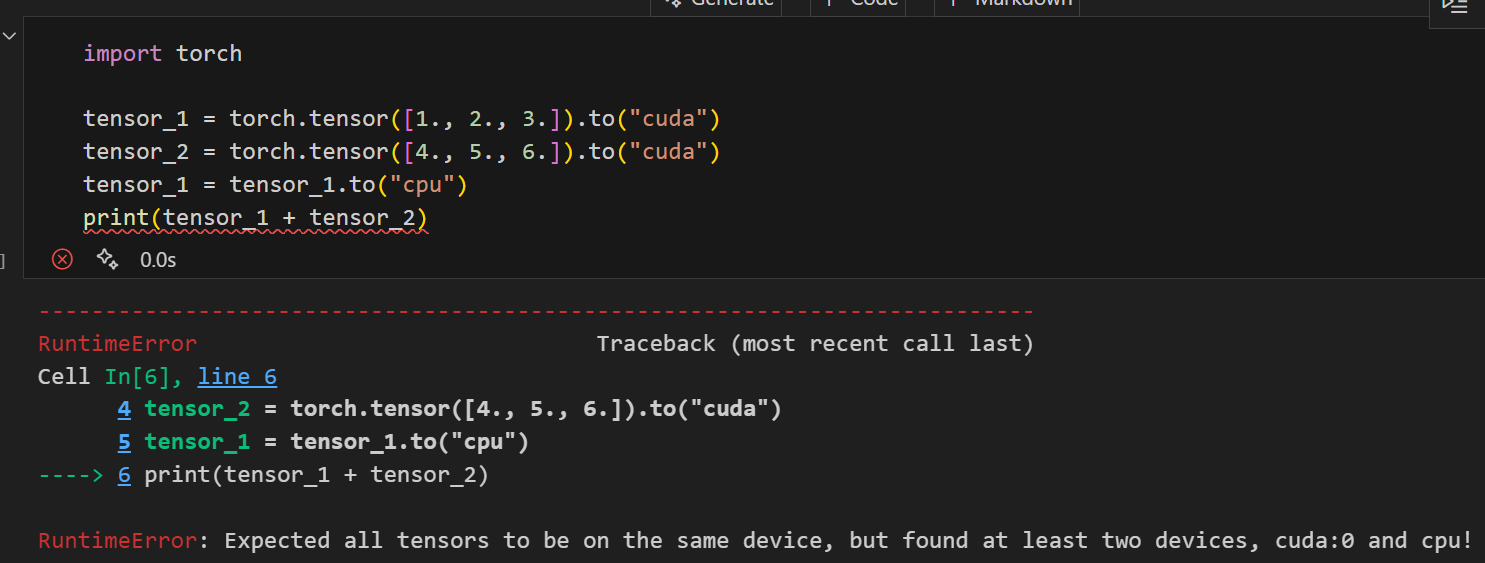
Chú ý: Tất cả tensor đều phải nằm trên một thiết bị duy nhất, nếu không sẽ báo lỗi.
Ví dụ:
# tensor_1 trên CPU
# tensor_2 trên GPU
tensor_1 = tensor_1.to("cpu")
print(tensor_1 + tensor_2)
4.2 GPU đơn
Tốc độ huấn luyện trên GPU là nhanh hơn so với CPU. Do đó, khi huấn luyện ưu tiên dùng GPU. Nếu máy tính không có GPU thì đành chấp nhận dùng CPU.
# Kiểm tra nếu máy có GPU thì xài, ko thì dùng CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
Trên máy Mac dùng Apple Silicon chip (M1, M2, M3 ...) thì dùng câu lệnh sau để chọn device
device = torch.device(
"mps" if torch.backends.mps.is_available() else "cpu"
)
4.3 Huấn luyện trên nhiều GPU (Distributed training)
Distributed training có ý tưởng chính là chia việc huấn luyện một khối lượng lớn dữ liệu ra trên nhiều thiết bị thay vì một. Điều này giúp giảm đáng kể thời gian huấn luyện (tất nhiên là phải có nhiều tiền để mua nhiều GPU 😆).
Distributed training có nhiều cách tiếp cận. Ở đây ta sẽ xem qua chiến lược DistributedDataParallel (DDP) của PyTorch.
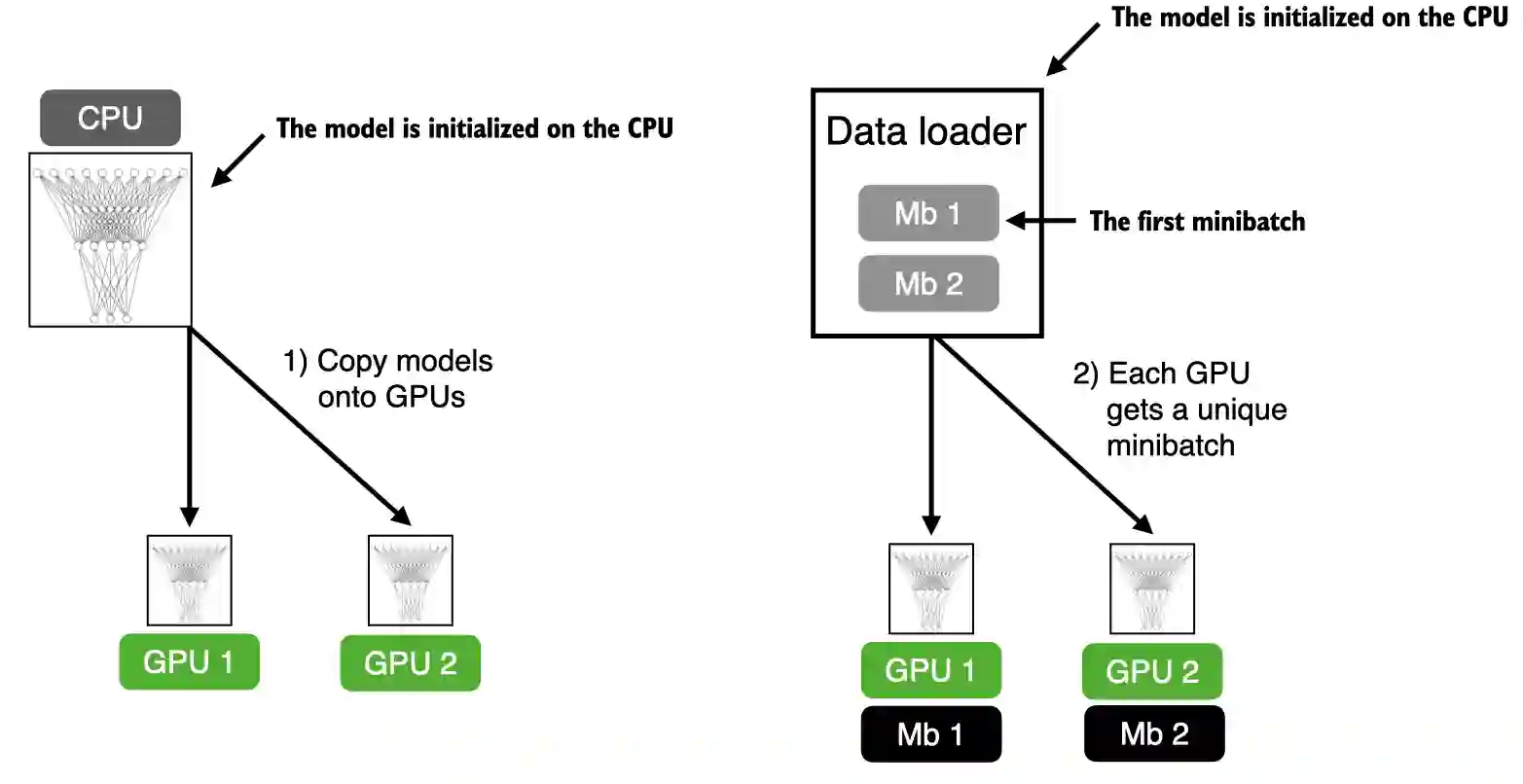
-
- PyTorch khởi chạy mỗi tiến trình trên mỗi GPU sau đó nhận và lưu một bản sao của mô hình.
-
- Trong mỗi chu kỳ huấn luyện, mỗi GPU sẽ nhận một mini-batch (Mb) khác nhau từ
DataLoader.
- Trong mỗi chu kỳ huấn luyện, mỗi GPU sẽ nhận một mini-batch (Mb) khác nhau từ
-
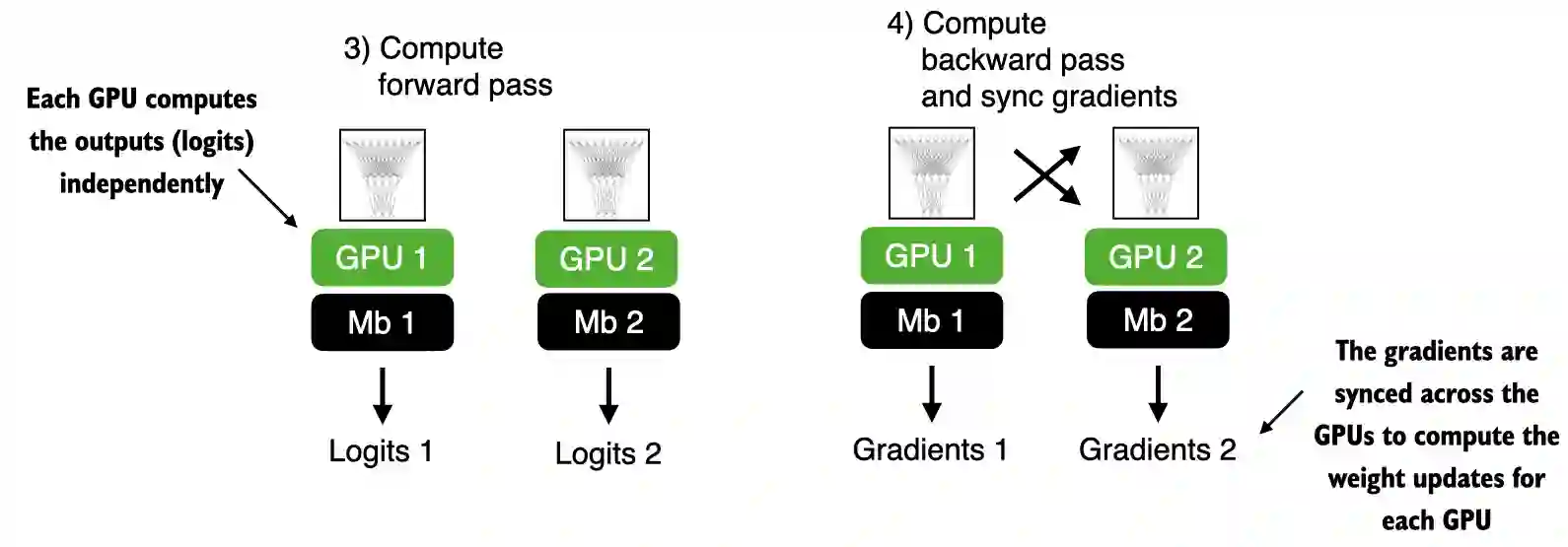
- GPU tính toán trên mỗi Mb.
-
- Sau khi tính gradient trên từng GPU. PyTorch sẽ tổng hợp kết quả, tính trung bình và đồng bộ kết quả với các GPU.
Tài liệu tham khảo
https://github.com/rasbt/LLMs-from-scratch/tree/main/appendix-A
All rights reserved
